您现在的位置是:首页 >技术教程 >【数据结构】哈希表网站首页技术教程
【数据结构】哈希表
这是之前的数据结构的内容,前面这个专栏的内容还没有写完,现在把这些给补上
1.概念
官方的解释是根据键(Key)而直接访问在内存存储位置的数据结构,这句话不太好理解,我们来翻译一下
其实哈希表底层依旧是数组,但不同的是哈希表里面的数据是键值对,而且使用哈希表进行随机查询时间复杂度可以做到O(1),因为哈希表里面数据和位置之间是有联系的,数据是通过哈希函数映射到表中的某个位置的
一般实现哈希表有两种方式:
- 数组+链表
- 数组+二叉树
至于为什么会用到链表或者二叉树会在下面的内容解释的
2.哈希冲突
哈希冲突指的是不同的数据经过哈希函数映射之后得到了哈希表中相同的位置,一般数据越多发生哈希冲突的可能性就越大,解决哈希冲突的办法有很多,这里只介绍两种主要的,分别为开放寻址法和拉链法
2.1 开放寻址法
开放寻址法就是在数组上面重新再找一个新的空位,如何寻找空位也有很多方法,最常见的就是看看该位置后一个位置是否能使用,比如5位置被占了,那就去看看6位置能不能用,如果6位置也被占了,那就去7位置,以此类推直到找到一个空位
2.2 拉链法
这里就是上面说的数组+链表的实现方式了,当发生哈希冲突的时候,处理方式如下
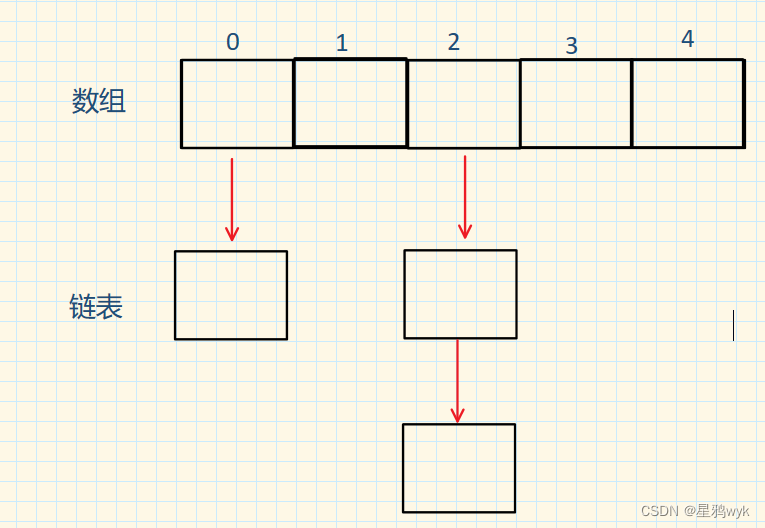
当发生哈希冲突的时候,使用链表将新数据挂在原数据后面,这时数组里面的原数据除了键值对外还有一个next指向新数据的地址
Java集合类里面的HashMap所采用的就是这种方法,但是如果链表过长的话也是会影响性能的,所以在HashMap中当链表的长度大于等于8的时候,链表会转换成树结构,之后如果长度小于等于6的话,就会还原链表
3.哈希表的扩容机制
当数组被占用的位置比较多的时候出现哈希冲突的概率会增加,所以这时需要对数组进行扩容,以Java的HashMap为例
HashMap的扩容和当前数组的长度以及负载因子有关,负载因子默认为0.75,即占用的位置大于数组长度的3/4就进行扩容
扩容主要分两步:
- 新建一个数组,一般数组长度是原数组的两倍
- 遍历原数组,将里面的数据再一次通过哈希函数进行映射放到新数组里面,因为位置可能会发生变化,所以不能直接复制粘贴
另外,HashMap数组初始大小为16,一般建议HashMap数组大小为2n,因为这样发生哈希冲突的概率最小
这主要和哈希函数有关,HashMap中的哈希函数为求模运算:index=key的哈希值%数组长度
当然这种运算效率是比较低的,所以讲求模运算替换为了位运算:index=key的哈希值&(数组长度-1)
二者的效果是一样的,但后者效率更高
现在来看看为什么说数组大小为2n发生哈希冲突的概率最小,假设两个数组一个大小为16,另一个为10,我们选几个值按照上面的位运算来算下
首先是数组大小为16的,16-1后的二进制为1 1 1 1
| 1111 | 1111 | 1111 |
|---|---|---|
| & | & | & |
| 1111 | 1110 | 1100 |
| =1111 | =1110 | =1100 |
然后是数组大小为10的,10-1后二进制为1 0 0 1
| 1001 | 1001 | 1001 |
|---|---|---|
| & | & | & |
| 1111 | 1110 | 1100 |
| =1001 | =1000 | =1000 |
可以很明显的看到大小为10的数组已经发生了哈希冲突
4.HashMap
Java中的HashMap底层是基于数组+链表实现的,HashMap实现的是Map接口,Map不继承Collection
关于如何解决哈希冲突以及扩容机制在上面已经讲了,这里我们来看看HashMap的put和get方法
put是添加数据,get是查询数据,这也是HashMap中使用频率最高的两个方法
4.1 put
初始的时候HashMap中所有的位置都为null,然后我们使用put插入一个数据,插入的时候会依据key的hash去计算一个位置然后进行添加,如果有出现哈希冲突就会形成链表,链表插入采用的方法为尾插法(Java8之前是头插法)
之所以有这样的改变是因为HashMap的扩容机制在多线程下是不安全的
现在有一个HashMap如下:
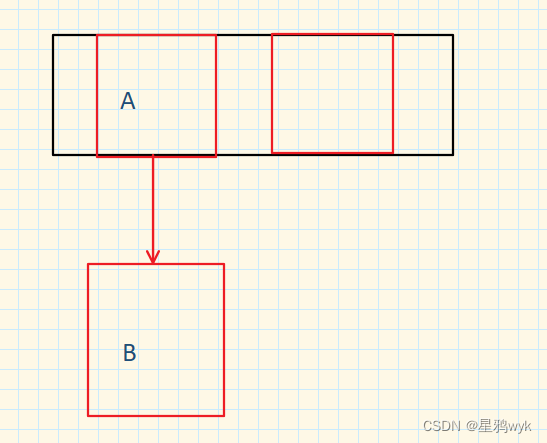
现在HashMap要进行扩容,如果是多线程下进行头插,那么就会发生下面的情况
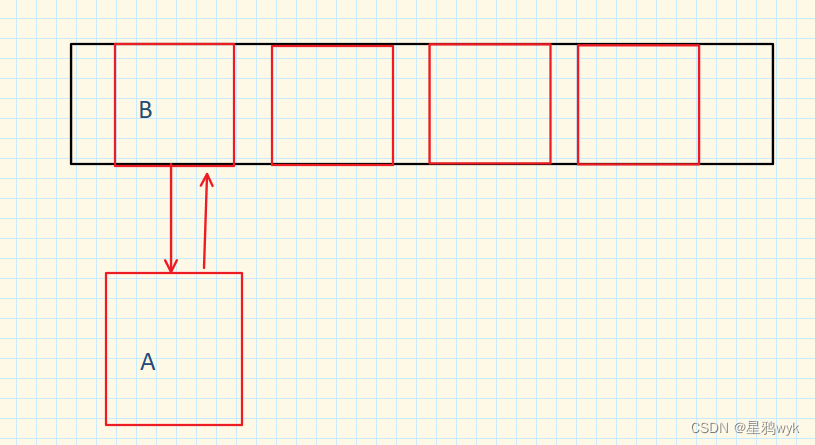
节点A比节点B先完成插入,但因为是头插法,所以B在数组里面,但A原本就是指向B的,所以此时链表成环了
而尾插法则不会有这样的问题
但是HashMap仍然是线程不安全的数据结构
4.2 get
HashMap的查找是依据key来查询value,所依靠的依旧是哈希函数,输入key值后通过哈希函数映射到数组中的具体位置,这个位置没有的话,如果此位置后面有链表就去遍历链表,如果没有链表后者是遍历链表后也没有的话就是没找到返回null
Java中底层为哈希表的除了HashMap外还有一个HashSet,二者之间的区别是:
- HashSet实现的是Set接口,Set继承自Collection,HashMap实现的Map接口不继承Collection
- HashMap存储的是键值对,HashSet中存储的只有key
- HashSet中的值不允许重复,HashMap可以,所以HashSet一般拿来对集合的元素进行去重
- HashSet不允许key值为null,HashMap可以
由于HashMap不是线程安全的,所以在多线程的情况下提供了ConcurrentHashMap
ConcurrentHashMap 底层也是基于数组+链表组成的,JDK1.8采用CAS+synchronized来保证线程安全
但是关于ConcurrentHashMap由于目前还不了解所以就先放着,后面理解之后再进行介绍
关于哈希表的内容到这结束,完






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结