您现在的位置是:首页 >技术教程 >算法性能分析网站首页技术教程
算法性能分析
一、时间复杂度分析
1.什么是时间复杂度
时间复杂度是一个函数,它定性描述该算法的运行时间。我们在软件开发中,时间复杂度就是用来方便开发者估算出程序运行的答题时间。
那么该如何估计程序运行时间呢,通常会估算算法的操作单元数量来代表程序消耗的时间,这里默认CPU的每个单元运行消耗的时间都是相同的。假设算法的问题规模为n,那么操作单元数量便用函数f(n)来表示,随着数据规模n的增大,算法执行时间的增长率和f(n)的增长率相同,这称作为算法的渐近时间复杂度,简称时间复杂度,记为 O(f(n))。
2.什么是大O
算法导论给出的解释:大O用来表示上界的,当用它作为算法的最坏情况运行时间的上界,就是对任意数据输入的运行时间的上界。
同样算法导论给出了例子:拿插入排序来说,插入排序的时间复杂度我们都说是O(n^2) 。输入数据的形式对程序运算时间是有很大影响的,在数据本来有序的情况下时间复杂度是O(n),但如果数据是逆序的话,插入排序的时间复杂度就是O(n2),也就对于所有输入情况来说,最坏是O(n2) 的时间复杂度,所以称插入排序的时间复杂度为O(n2)。同样的同理再看一下快速排序,都知道快速排序是O(nlogn),但是当数据已经有序情况下,快速排序的时间复杂度是O(n2) 的,所以严格从大O的定义来讲,快速排序的时间复杂度应该是O(n^2)。

3.不同数据规模的差异
如下图中可以看出不同算法的时间复杂度在不同数据输入规模下的差异。

在决定使用哪些算法的时候,不是时间复杂越低的越好(因为简化后的时间复杂度忽略了常数项等等),要考虑数据规模,如果数据规模很小甚至可以用O(n^2)的算法比O(n)的更合适(在有常数项的时候)。
就像上图中 O(5n^2) 和 O(100n) 在n为20之前 很明显 O(5n^2)是更优的,所花费的时间也是最少的。那为什么在计算时间复杂度的时候要忽略常数项系数呢,也就说O(100n) 就是O(n)的时间复杂度,O(5n^2) 就是O(n^2)的时间复杂度,而且要默认O(n) 优于O(n^2) 呢 ?
这里就又涉及到大O的定义,因为大O就是数据量级突破一个点且数据量级非常大的情况下所表现出的时间复杂度,这个数据量也就是常数项系数已经不起决定性作用的数据量。例如上图中20就是那个点,n只要大于20 常数项系数已经不起决定性作用了。
所以我们说的时间复杂度都是省略常数项系数的,是因为一般情况下都是默认数据规模足够的大,基于这样的事实,给出的算法时间复杂的的一个排行如下所示:

4.复杂表达式的化简
有时候我们去计算时间复杂度的时候发现不是一个简单的O(n) 或者O(n^2), 而是一个复杂的表达式,例如:
O(2*n^2 + 10*n + 1000)
去掉运行时间中的加法常数项 (因为常数项并不会因为n的增大而增加计算机的操作次数)。
O(2*n^2 + 10*n)
去掉常数系数
O(n^2 + n)
只保留保留最高项,去掉数量级小一级的n (因为n^2 的数据规模远大于n),最终简化为:
O(n^2)
所以最后我们说:这个算法的算法时间复杂度是O(n^2) 。
5.O(logn)中的log是以什么为底
平时说这个算法的时间复杂度是logn的,那么一定是log 以2为底n的对数么?其实不然,也可以是以10为底n的对数,也可以是以20为底n的对数,但我们统一说 logn,也就是忽略底数的描述。

二、空间复杂度分析
1.定义
空间复杂度是对一个算法在运行过程中占用内存空间大小的量度,记做S(n)=O(f(n)。空间复杂度(Space Complexity)记作S(n) 依然使用大O来表示。利用程序的空间复杂度,可以对程序运行中需要多少内存有个预先估计。
2.关注空间复杂度有两个常见的相关问题
(1)空间复杂度是考虑程序(可执行文件)的大小么?
很多同学都会混淆程序运行时内存大小和程序本身的大小。这里强调一下空间复杂度是考虑程序运行时占用内存的大小,而不是可执行文件的大小。
(2)空间复杂度是准确算出程序运行时所占用的内存么?
不要以为空间复杂度就已经精准的掌握了程序的内存使用大小,很多因素会影响程序真正内存使用大小,例如编译器的内存对齐,编程语言容器的底层实现等等这些都会影响到程序内存的开销。所以空间复杂度是预先大体评估程序内存使用的大小。
三、代码中的内存消耗
1.内存管理

固定部分的内存消耗 是不会随着代码运行产生变化的, 可变部分则是会产生变化的。更具体一些,一个由C/C++编译的程序占用的内存分为以下几个部分:
(1)栈区(Stack) :由编译器自动分配释放,存放函数的参数值,局部变量的值等,其操作方式类似于数据结构中的栈。
(2)堆区(Heap) :一般由程序员分配释放,若程序员不释放,程序结束时可能由OS收回。
(3)未初始化数据区(Uninitialized Data): 存放未初始化的全局变量和静态变量。
(4)初始化数据区(Initialized Data):存放已经初始化的全局变量和静态变量
(5)程序代码区(Text):存放函数体的二进制代码
代码区和数据区所占空间都是固定的,而且占用的空间非常小,那么看运行时消耗的内存主要看可变部分。
在可变部分中,栈区间的数据在代码块执行结束之后,系统会自动回收,而堆区间数据是需要程序员自己回收,所以也就是造成内存泄漏的发源地.
2.如何计算程序占用多大内存

注意图中有两个不一样的地方,为什么64位的指针就占用了8个字节,而32位的指针占用4个字节呢?
1个字节占8个比特,那么4个字节就是32个比特,可存放数据的大小2^32,也就是4G空间的大小,即:可以寻找4G空间大小的内存地址。大家现在使用的计算机一般都是64位了,所以编译器也都是64位的。安装64位的操作系统的计算机内存都已经超过了4G,也就是指针大小如果还是4个字节的话,就已经不能寻址全部的内存地址,所以64位编译器使用8个字节的指针才能寻找所有的内存地址。
3.内存对齐
为什么会有内存对齐?
(1)平台原因:不是所有的硬件平台都能访问任意内存地址上的任意数据,某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。为了同一个程序可以在多平台运行,需要内存对齐。
(2)硬件原因:经过内存对齐后,CPU访问内存的速度大大提升。
CPU读取内存不是一次读取单个字节,而是一块一块的来读取内存,块的大小可以是2,4,8,16个字节,具体取多少个字节取决于硬件。假设CPU把内存划分为4字节大小的块,要读取一个4字节大小的int型数据,来看一下这两种情况下CPU的工作量:
(1)第一种就是内存对齐的情况

一字节的char占用了四个字节,空了三个字节的内存地址,int数据从地址4开始。此时,直接将地址4,5,6,7处的四个字节数据读取到即可。
(2)第二种是没有内存对齐的情况
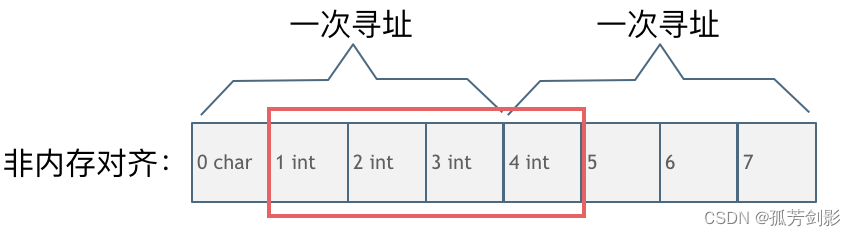
char型的数据和int型的数据挨在一起,该int数据从地址1开始,那么CPU想要读这个数据的话来看看需要几步操作:
1.因为CPU是四个字节四个字节来寻址,首先CPU读取0,1,2,3处的四个字节数据。
2.CPU读取4,5,6,7处的四个字节数据。
3.合并地址1,2,3,4处四个字节的数据才是本次操作需要的int数据
此时一共需要两次寻址,一次合并的操作。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结