您现在的位置是:首页 >学无止境 >pix2pix网站首页学无止境
pix2pix
Image-to-Image Translation Using Conditional Adversarial Networks
1:
pix2pix也是CGAN的一种,pix2pix可以学习输入到输出的映射,同时也学习了损害函数去训练这个映射。这是一个大一统的方法去实现从标签合成图像,从边界图重建物体,给图片上色等。
传统的方法对每一个上述任务都有一个特定的模型设计,损失函数设计等。本文设计的commom framwork可以实现所有的从像素预测像素的问题。
模型设计也借助了CNN这个工具,并且希望CNN可以按我们希望的那样来做,本文使用CGAN的思想,给输入添加条件,产生一个相应的输出。pix2pix生成器采用U-Net,辨别器采用PatchGAN。
2:
CGAN的目标函数:

将辨别器D的条件去掉后,目标函数就变为:
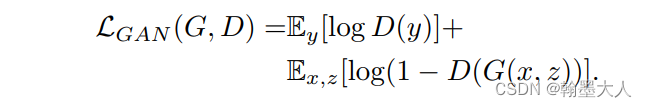
之前方法发现GAN和一个传统的损失结合效果更好,比如L2,辨别器的作用不变,生成器不仅要骗过辨别器还要尽可能接近GT。L1损失相比于L2损失可以产生更少的模糊:
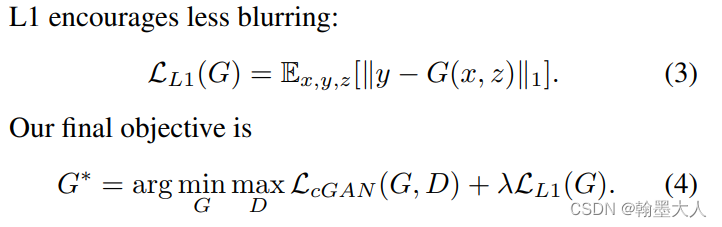
如果没有z,那么网络就会产生确定的输出,就不能匹配数据的任意分布了。CGAN使用的噪声z输入到G中,但是在作者实验中发现这种策略并不是很有效。生成器会忽略这个噪声,因此作者使用dropout在训练和测试应用于生成器的前几层。
3:
网络结构:
3.1:带有跳跃连接生成器
输入和输出尽管在表面不相同但是他们都共享内在的结构,因此输入结构和和输出结构大致是对齐的。多数方法采用的encoder-decoder结构使信息流过所有的层,作者还添加了跳连接,可以将encoder的细节等信息引入到decoder中。
3.2:PatchGAN:
L2损失和L1损失在图像生成时产生模糊的结果,尽管这些损失不能够恢复高频细节,但是却能够捕捉低频细节。

因此需要限制GAN辨别器不仅可以建模高频结构,而且需要依赖L1矫正低频。为了建模高频,我们需要将注意力放在局部图像块,因此我们设计了辨别器PatchGAN,辨别器尝试分类每一个NXN的块是否是真或假。平均每一个patch的结果产生最终的输出。
4:
优化和推理:
在推理阶段使用和训练一样的方法,使用batchnorm,如果batchsize为1,那么bn就变为instancenorm。测试/推理设置在测试时候不能使用model.eval,因为那样会固定所有神经元就无法随机dropout来增加随即性。
5:
实验:

5.1评价指标:
AMT
FCN-score:用于lable-photo映射,将映射的图片输入到FCN中,产生的labelmap和真实的GT进行计算。

5.2:目标函数分析:







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结