您现在的位置是:首页 >学无止境 >如何使用自定义知识库构建自定义ChatGPT机器人网站首页学无止境
如何使用自定义知识库构建自定义ChatGPT机器人
目录 隐藏
2. 使用 LlamaIndex(GPT 索引)扩展 ChatGPT
使用自定义数据源为您的 ChatGPT 机器人提供数据

ChatGPT 已成为许多人日常用来自动执行各种任务的不可或缺的工具。如果您已经使用 ChatGPT 一段时间,您就会意识到它可能会提供错误的答案。这就提出了一个问题,即我们如何利用 chatGPT 来弥合差距并允许 ChatGPT 拥有更多自定义数据。
丰富的知识分布在我们每天接触的各种平台上,即通过工作中的 confluence wiki 页面、Slack组、公司知识库、Reddit、Stack Overflow、书籍、时事通讯和同事共享的 google 文档。跟上所有这些信息源本身就是一项全职工作。
如果您可以有选择地选择您的数据源并将该信息轻松地输入到 ChatGPT 对话中与您的数据,那不是很好吗?
1. 通过Prompt提示工程提供数据
在我们开始讨论如何扩展 ChatGPT 之前,让我们看看如何手动扩展 ChatGPT 以及存在哪些问题。扩展 ChatGPT 的传统方法是通过即时工程。
这很容易做到,因为 ChatGPT 是上下文感知的。首先,我们需要通过在实际问题之前附加原始文档内容来与 ChatGPT 进行交互。
我会根据以下内容向您提问: - 内容开始- 您提供 ChatGPT 上下文的很长的文本 - 内容结束-
这种方法的问题是模型的上下文有限;它只能接受大约 4,097 个 GPT-3 代码。您很快就会遇到这种方法的障碍,因为它也是一个相当手动、乏味的过程,总是必须粘贴内容。
想象一下,您想将数百个 PDF 文档注入 ChatGPT。您很快就会遇到付费问题。您可能认为 GPT-4 是 GPT-3 的继任者。它刚刚于 2023 年 3 月 14 日推出,可以处理 25,000 个单词——大约是 GPT-3 处理图像的八倍——并且可以处理比 GPT-3.5 更细微的指令。这仍然具有相同的数据输入限制的基本问题。我们如何绕过其中一些限制?我们可以利用一个名为 LlamaIndex 的 Python 库。
2. 使用 LlamaIndex(GPT 索引)扩展 ChatGPT
LlamaIndex,也称为 GPT 索引,是一个提供中央接口以将您的 LLM 与外部数据连接起来的项目。是的,你没有看错。使用 LlamaIndex,我们可以构建如下图所示的内容:

自定义数据源输入 CHATGPT
LlamaIndex 将您现有的数据源和类型与可用的数据连接器连接起来,例如(API、PDF、文档、SQL 等)。它使您能够通过为结构化和非结构化数据提供索引来使用 LLM。这些索引通过消除典型的样板和痛点来促进上下文学习:以可访问的方式保留上下文以便快速插入。
处理提示限制——GPT-3 Davinci 的 4,096 个令牌限制和 GPT-4 的 8,000 个令牌限制——当上下文太大时变得更容易访问并通过为用户提供一种交互方式来解决文本拆分问题索引。LlamaInde 还抽象了从文档中提取相关部分并将其提供给提示的过程。
如何添加自定义数据源
在本节中,我们将使用 GPT“text-davinci-003”和 LlamaIndex 基于预先存在的文档创建一个问答聊天机器人。
先决条件
在我们开始之前,请确保您可以访问以下内容:
- Python ≥ 3.7 安装在你的机器上
- OpenAI API 密钥,可在OpenAI 网站上找到。您可以使用您的 Gmail 帐户进行单点登录。

- 一些 Word 文档已上传到您的 Google 文档。LlamaIndex 支持许多不同的数据源。在本教程中,我们将演示 Google Docs。
怎么运行的
- 使用 LlamaIndex 创建文档数据索引。
- 使用自然语言搜索索引。
- 相关片段将由 LlamaIndex 检索并传递给 GPT 提示。LlamaIndex 会将您的原始文档数据转换为查询友好的矢量化索引。它将利用该索引根据查询和数据的匹配程度找到最相关的部分。然后,这些信息将被加载到提示中,提示将被发送到 GPT,以便 GPT 具有必要的背景来回答您的问题。
- 之后,您可以根据上下文中的提要询问 ChatGPT。
为你的Python项目创建一个新的文件夹,你可以调用mychatbot,最好使用虚拟环境或conda环境。
我们需要先安装依赖库。就是这样:
pip install openai pip install llama-index pip install google-auth-oauthlib
接下来,我们将导入 Python 中的库并在新文件中设置您的 OpenAI API 密钥main.py。
import os import pickle
from
google.auth.transport.requests import Request
from
google_auth_oauthlib.flow import InstalledAppFlow from llama_index import GPTSimpleVectorIndex, download_loader
os.environ['OPENAI_API_KEY'] = 'SET-YOUR-OPEN-AI-API-KEY'
在上面的代码片段中,为清楚起见,我们明确设置了环境变量,因为 LlamaIndex 包隐含地需要访问 OpenAI。在典型的生产环境中,您可以将密钥放在环境变量、保险库或您的基础设施可以访问的任何机密管理服务中。
让我们构造一个函数来帮助我们对我们的 Google 帐户进行身份验证以发现 Google 文档。
def authorize_gdocs ():
google_oauth2_scopes = [
"https://www.googleapis.com/auth/documents.readonly"
]
cred = None
if os.path.exists( "token.pickle" ):
with open ( "token.pickle " , 'rb' ) as token:
cred = pickle.load(token)
if not cred or not cred.valid:
if cred and cred.expired and cred.refresh_token:
cred.refresh(Request())
else :
flow = InstalledAppFlow.from_client_secrets_file( "credentials.json" , google_oauth2_scopes)
cred = flow.run_local_server(port= 0 )
with open ( "token.pickle" , 'wb' )作为令牌:
pickle.dump(cred, token)
要启用 Google Docs API 并在 Google 控制台中获取凭据,您可以按照以下步骤操作:
- 转到 Google Cloud Console 网站 (console.cloud.google.com)。
- 如果您还没有,请创建一个新项目。您可以通过单击顶部导航栏中的“选择项目”下拉菜单并选择“新建项目”来完成此操作。按照提示为您的项目命名并选择您要与之关联的组织。
- 创建项目后,请从顶部导航栏的下拉菜单中选择它。
- 从左侧菜单转到“API 和服务”部分,然后单击页面顶部的“+ 启用 API 和服务”按钮。
- 在搜索栏中搜索“Google Docs API”,然后从结果列表中选择它。
- 单击“启用”按钮为您的项目启用 API。
- 单击 OAuth 同意屏幕菜单并创建并为您的应用程序命名,例如“mychatbot”,然后输入支持电子邮件、保存并添加范围。

您还必须添加测试用户,因为此 Google 应用尚未获得批准。这可以是您自己的电子邮件。

然后,您需要为您的项目设置凭据才能使用 API。为此,请转到左侧菜单中的“凭据”部分,然后单击“创建凭据”。选择“OAuth 客户端 ID”并按照提示设置您的凭据。

设置凭据后,您可以下载 JSON 文件并将其存储在应用程序的根目录中,如下所示:

根目录中带有 GOOGLE 凭据的示例文件夹结构
设置凭据后,您可以从 Python 项目访问 Google Docs API。
转到您的 Google 文档,打开其中的一些文档,并获取可以在浏览器 URL 栏中看到的唯一 ID,如下图所示:

文档编号
复制 gdoc ID 并将它们粘贴到下面的代码中。您可以拥有 N 个可以编制索引的 gdoc,以便 ChatGPT 具有对您的自定义知识库的上下文访问权限。我们将使用 LlamaIndex 库中的 GoogleDocsReader 插件加载您的文档。
authorize_gdocs() GoogleDocsReader = download_loader('GoogleDocsReader') gdoc_ids = ['1ofZ96nWEZYCJsteRfqik_xNQTGFHtnc-7cYrf0dMPKQ'] loader = GoogleDocsReader() documents = loader.load_data(document_ids=gdoc_ids)
index = GPTSimpleVectorIndex(documents)
LlamaIndex 有多种数据连接器,涵盖 Notion、Obsidian、Reddit、Slack 等服务。您可以在此处找到可用数据连接器的压缩列表。
如果您希望即时保存和加载索引,可以使用以下函数调用。这将加快从预先保存的索引中获取的过程,而不是对外部源进行 API 调用。
index.save_to_disk( 'index.json' ) = GPTSimpleVectorIndex.load_from_disk( 'index.json' )
查询索引并获得响应可以通过运行下面的代码来实现。代码可以轻松扩展到连接到 UI 的 rest API,您可以在 UI 中通过 GPT 界面与自定义数据源进行交互。
while True :
prompt = input ( "Type prompt..." )
response = index.query(prompt)
print (response)
鉴于我们有一个包含我详细信息的 Google 文档,如果您在 google 上公开搜索,这些信息很容易获得。

我们将首先直接与 vanilla ChatGPT 交互,以查看它在不注入自定义数据源的情况下生成的输出。
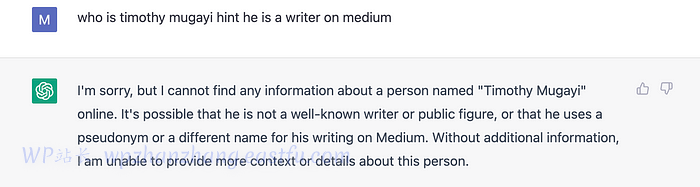
那有点令人失望!让我们再试一次。
INFO:google_auth_oauthlib.flow: "GET /?state=oz9XY8CE3LaLLsTxIz4sDgrHha4fEJ&code=4/0AWtgzh4LlIfmCMEa0t36dse_xoS0fXFeEWKHFiouzTvz4Qwr7T2Pj6anb-GiZ__Wg-hBBg&scope=https://www.googleapis.com/auth/documents.readonly HTTP/1.1" 200 65 INFO:googleapiclient.discovery_cache:file_cache仅支持 oauth2client<4.0.0 INFO:root:> [build_index_from_documents] LLM 令牌总使用量:0 个令牌 INFO:root:> [build_index_from_documents] 嵌入令牌总使用量:175 个令牌 类型提示...谁是 timothy mugayi 提示他是媒体上的作者INFO:root:> [query] LLM 令牌总使用量:300 个令牌 INFO:root:> [query] 嵌入令牌总使用量:14 个令牌 Timothy Mugayi 是 GRAB 子公司 OVO (PT Visionet Internasional) 的工程经理。他还是 medium.com 上的一位狂热作家,他撰写的技术主题涵盖 python 和程序员的自由职业。Timothy 从事编码工作超过15 年,为大型合作构建企业解决方案。在空闲时间,他喜欢指导和指导。 last_token_usage=300 键入提示...键入提示...假设您知道timothy mugayi 是谁,请写一篇关于他的有趣介绍Timothy Mugayi 是一位经验丰富且成就卓著的专业人士,在工程、编码和指导。他目前是 GRAB 子公司 OVO 的工程经理,从事编码工作超过15 年,为大型合作构建企业解决方案。在空闲时间,Timothy 喜欢撰写技术主题,例如 Python 和在 medium.com 上为程序员提供自由职业的副业,以及指导和辅导。凭借令人印象深刻的背景和专业知识,Timothy 是任何组织的宝贵资产。 last_token_usage=330
它现在可以使用新的自定义数据源推断答案,准确地生成以下输出。
我们可以更进一步。
输入提示...为timothy mugayi写一封求职信,用于一个 upwork python 项目,以构建一个可以访问外部数据源的自定义 ChatGPT 机器人 INFO:root:> [query] LLM 令牌总使用量:436 个令牌 INFO:root:> [查询] 嵌入令牌总使用量:30 个令牌亲爱的 [招聘经理],我写信申请Python项目,以构建一个可以访问外部数据源的自定义 ChatGPT 机器人。凭借超过 15 年的编码和为大型公司构建企业解决方案的经验,我相信我是这个职位的理想人选。我目前是 GRAB 子公司 OVO (PT Visionet Internasional) 的工程经理。我在Python 方面拥有丰富的经验,并且一直在 medium.com 上为程序员撰写涵盖 Python 和自由职业方面的技术主题。我也是一位热心的导师和教练,我相信我的经验和技能使我成为这个项目的完美人选。我有信心可以交付满足项目要求的高质量产品。我也可以进一步讨论该项目并回答您的任何问题。感谢您的时间和考虑。此致, Timothy Mugayi last_token_usage=436 输入提示...
LlamaIndex 将在内部接受您的提示,在索引中搜索相关块,然后将您的提示和相关块传递给 ChatGPT 模型。上述过程展示了 LlamaIndex 和 GPT 用于回答问题的基本首次使用。然而,您可以做的还有很多。在将 LlamaIndex 配置为使用不同的大型语言模型 (LLM)、为各种活动使用不同类型的索引或以编程方式使用新索引更新旧索引时,您的创造力只会受到限制。
这是一个显式更改 LLM 模型的示例。这次我们使用另一个与 LlamaIndex 捆绑在一起的 Python 包,称为 langchain。
from langchain import OpenAI from llama_index import LLMPredictor, GPTSimpleVectorIndex, PromptHelper ... llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name= "text-davinci-003" )) max_input_size = 4096 # 设置输出 num_output = 256 max_chunk_overlap = 20
如果您想密切关注您的 OpenAI 免费或付费积分,您可以导航到 OpenAI仪表板并检查剩余的积分。
创建索引、插入索引和查询索引都将使用令牌。因此,在构建自定义机器人时确保输出令牌使用情况以用于跟踪目的始终很重要。
last_token_usage = index.llm_predictor.last_token_usage
打印
( f"last_token_usage= {last_token_usage} " )
最后的总结
ChatGPT 结合 LlamaIndex 可以帮助构建一个定制的 ChatGPT 聊天机器人,它可以根据自己的文档来源推断知识。虽然 ChatGPT 和其他 LLM 非常强大,但扩展 LLM 模型提供了更精致的体验,并开启了构建对话式聊天机器人的可能性,该聊天机器人可用于构建真实的业务用例,例如客户支持协助甚至垃圾邮件分类器。鉴于我们可以提供实时数据,我们可以评估在特定时期内训练的 ChatGPT 模型的一些局限性。
点击阅读 如何使用自定义知识库构建自定义ChatGPT机器人 原文






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结