您现在的位置是:首页 >学无止境 >数据包守恒 & TCP 拥塞控制网站首页学无止境
数据包守恒 & TCP 拥塞控制
数据包守恒是包括拥塞控制在内的合理利用带宽的方法之基石,它维持了有效网络传输的稳定,过去 40 年是,未来还是。数据包守恒可以描述为:
- 当带宽恰好满载时,receiver 收到 1 个数据包后 sender 才能发送 1 个数据包。
- 当带宽尚未满载时,receiver 收到 1 个数据包后 sender 可以发送大于 1 个数据包。
- 当带宽过载但未丢包时,receiver 收到 1 个数据包后 sender 可以发送 a(a < 1) 个数据包。
- 当带宽过载且丢包时,receiver 收到 1 个数据包后 sender 可以发送 a - loss (a 为第 3 点的 a,loss 为丢包量平摊到 1 个数据包的份额)
解释一下第 4 点,因为拥塞导致了丢包,所以丢掉的这部分需要排除在正常容量之外,先减掉丢掉的这部分,获得满载容量,再以小于 1 的兑换比缓解拥塞,至于如何统计丢包数量,请信任拥塞控制算法。
其它的描述非常容易理解,不再解释。但 sender 如何获知 receiver 已经收到了数据包呢?
以 TCP 为例,receiver 主动告诉 sender 的方式类似于中断,ACK(可携带 SACK) 告知 sender 已经有数据包被接收并触发 sender 发送新的数据包,因此 ACK 也叫 ACK 时钟。
最终,数据的发送需要 ACK 触发,而 ACK 则需要发送新数据触发,形成了一个先有鸡还是先有蛋的环。对于 TCP 而言,上述 4 点就在这个环上做文章:
- 作为 application-limited 的 TCP,如果应用速率恰好填满带宽,TCP 则按照等于 1 的兑换比执行数据包守恒。
- 作为 capacity-seeking 的 TCP,AIMD 确保公平收敛,在 AI 阶段数据包守恒兑换比大于 1,在 MD 阶段执行 PRR(RFC6937) 过程,兑换比小于 1。
- 作为 half-rate-based(后面解释)的 TCP BBR,检测到丢包后,从 inflight 扣掉 loss 数量后以兑换比 1 执行数据包守恒。
其中 AIMD PRR 和 BBR 需要额外解释。
AI 是一个兑换比大于 1 的过程,目的是 probe,当出现丢包时需要收敛,MD 过程的兑换比显然小于 1,PRR算法体现了这个过程:以 CUBIC 为例,当 receiver 收到了 delivered 这么多数据时,发送 0.7*delivered。
关于 PRR 的过程,这又是一道中学生几何习题,见下图:
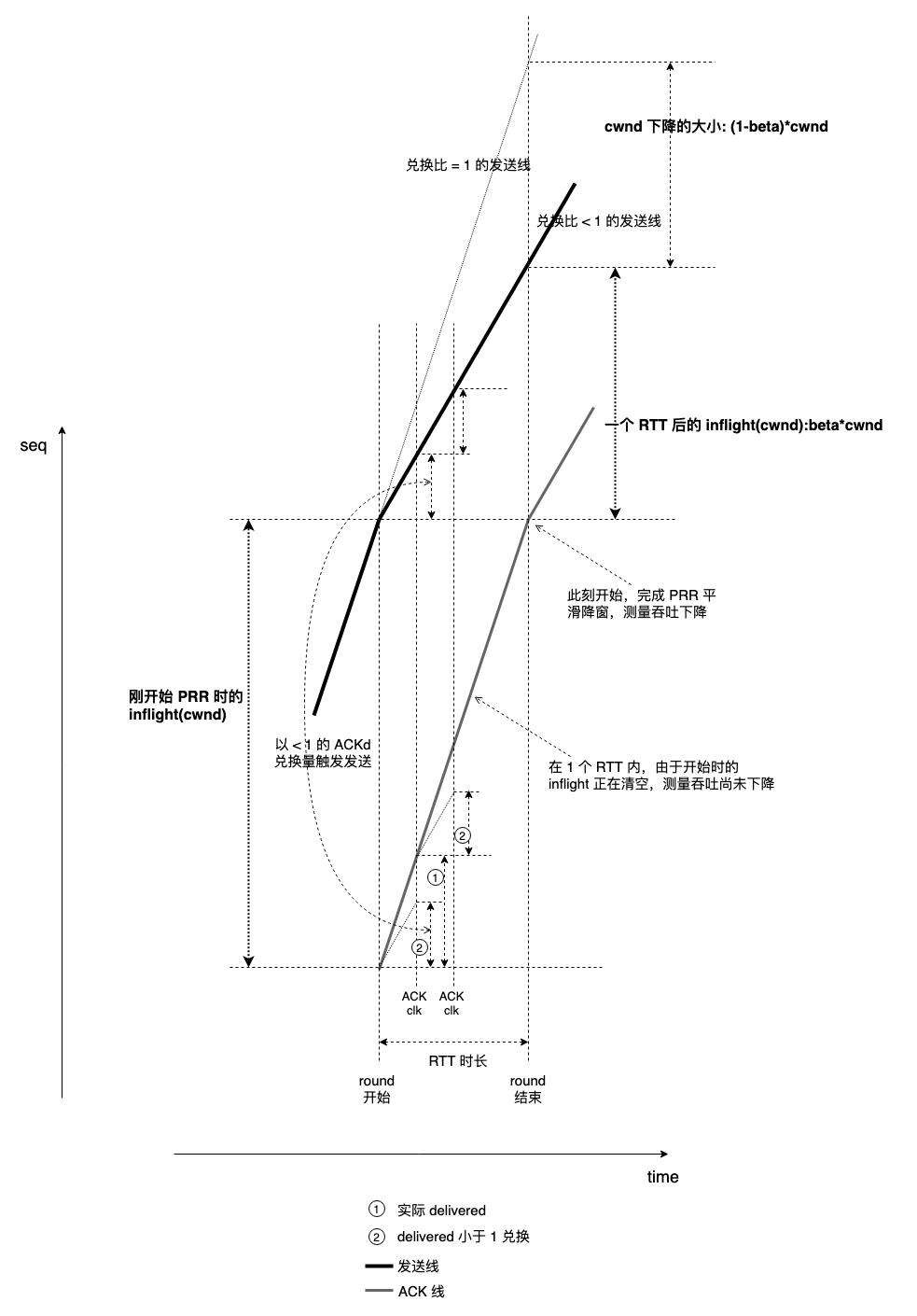
可清晰观测到 cwnd 下降到 beta * cwnd 是多么平滑。可用下面的脚本具体观测数据:
"trace.bt" 29L, 752C
#!/usr/local/bin/bpftrace
#include <linux/tcp.h>
k:tcp_cwnd_reduction
{
$tp = (struct tcp_sock *)arg0;
printf("ssthresh:%llu pcwnd:%llu delivered:%llu this:%llu total:%llu ",
$tp->snd_ssthresh,
$tp->prior_cwnd,
$tp->prr_delivered,
arg1,
$tp->prr_delivered + arg1);
printf(" prr_out:%llu cwnd:%llu delta:%llu inflt:%llu
",
$tp->prr_out,
$tp->snd_cwnd,
$tp->snd_ssthresh*($tp->prr_delivered + arg1)/$tp->prior_cwnd - $tp->prr_out,
$tp->packets_out - $tp->sacked_out - $tp->lost_out + $tp->retrans_out);
}
作为一个极端的对比,看一下在进入 fast retransmit 当时将 cwnd *= beta 会是什么样子:
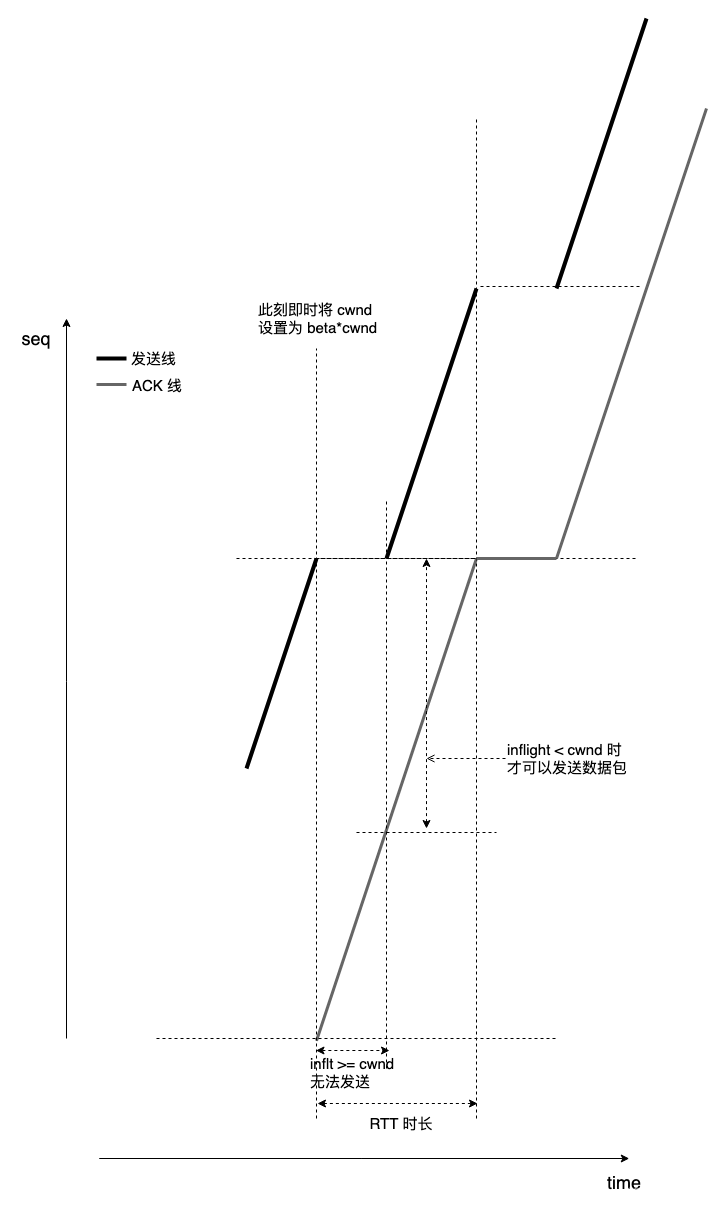
可以看出来,非常糟糕。
下面主要看 BBR 的问题。
BBR 是一个半 rate-based 算法,“半 rate-based” 是因为目前 BBR 仅凭 rate-based 机制无法确保数据包守恒,换句话说,rate-based 机制无法精确控制自己发送的数据包对网络负载造成的影响。
完全的 rate-based 算法不依赖 ACK 时钟,全凭测量吞吐控制发送速率,至于测量方式,ACK 只是一种方式。完全的 rate-based 算法甚至根本无法信任 ACK 时钟,因为 ACK 时钟是事后的,按数据包守恒,收到 ACK 才触发发送。
对 rate-based 而言,拥塞不能提前预知,而反馈测量信号总是滞后(只能测量过去的事件),它需要按一定rate 持续发送,直到收到 “需要变化” 的信号,在发生拥塞情况下收到下一次测量信号前已经发送了过多数据,这部分数据可能恶化拥塞。
总之,ACK 时钟机制下,收到信号在先,触发发送在后,rate-based 则相反,发送在前,测量反馈在后,rate-based 算法没什么好方法执行数据包守恒。而不执行数据包守恒将使连接脱离拥塞控制。
因此,BBR 至少在检测到丢包时强制切换到数据包守恒模式,背后的依据是 “丢包大概率是发生了拥塞导致”,而这个时候是必须格外谨慎的,绝不能再多发送额外的数据而恶化拥塞。
但 BBR 在此处的数据包守恒也为自身带来了副作用。如果丢包是随机丢包,失去了 cwnd gain,数据包守恒的 BBR 没有足量的 inflight 进行 probe,而抗随机丢包恰恰就是 BBR 的承诺,显然,这里的数据包守恒违背了承诺。
不过这也是没有办法的事,BBR 的作者在实现这部分逻辑时写下了无奈的 TODO:
/* An optimization in BBR to reduce losses: On the first round of recovery, we
* follow the packet conservation principle: send P packets per P packets acked.
* ...
* TODO(ycheng/ncardwell): implement a rate-based approach.
*/
static bool bbr_set_cwnd_to_recover_or_restore(...
数据包守恒一直都在,可是当我们想进一步了解时,网上的资料几乎全部指向范雅各布森的经典论文,连解释引申一下都没有,可数据包守恒覆盖的范围不仅仅是个解释。
浙江温州皮鞋湿,下雨进水不会胖。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结