您现在的位置是:首页 >学无止境 >软件自动化测试网站首页学无止境
软件自动化测试
测试的目的:
保证软件质量
第一章 JMock测试框架
1.1 简介
Mock测试是一种常见的测试方法,通常在执行测试的时候,测试代码往往需要与一些真实对象进行交互,又或者被测代码的执行需要依赖真实对象的功能。此时,我们可以使用一个轻量级的、可控制的Mock对象来取代真实对象,模拟真实对象的行为和功能,从而方便我们测试。jMock便是这种方法的一种实现。
jMock是一个利用Mock对象来测试Java代码的轻量级测试工具。
(代码在很多情况下需要与真实对象进行交互,涉及到数据库,测试前端。但数据库未搞定。用一个轻量级的可控制的来取代真实对象。模拟真实对象的增删改查。Jmock,利用mock对象来进行java代码的轻量级测试工具。是JUnit家族的。
jmock方法,当我们使用jmock编程只需要完成mock对象。对mock对象进行描述
JMock是一款流行的Java Mock框架,它能够帮助开发者在测试过程中替换掉真实对象并指定特定的行为,以便在不依赖于外部环境的情况下对被测试代码进行单元测试。)
1.2 功能和特点
jMock允许以一种十分灵活的方式来精确定义对象之间彼此交互的约束,从而更好地模拟和刻画对象间的调用关系。jMock的这种对象间调用关系的约束表达十分简洁和紧凑,这使得测试代码的编写变得十分简洁,同时又能很好地利用jMock对象来达成测试意图。
1.3 JMock
1.3.1 快速上手教程
import org.jmock.Mockery;
import org.jmock.Expectations;
class PublisherTest extends TestCase{
Mockery context = new Mockery();
public void testOneSubscriberReceivesAMessage(){
// set up
final Subscriber subscriber = context.mock(Subscriber.class); //利用Mockery实例构造一个模拟的Subsciber对象
Publisher publisher=new Publisher();
publisher.add(subscriber);
final String message="message";
// expectations
context.checking(new Expectations(){{ // 定义"Expectations"——指定Publisher和Subscriber的交互规则。Expectations是一组约束条件,它用于定义在测试运行期间,我们期望Mock对象接受调用的方式。例如在本例中,我们期望Publisher会调用Subscriber的receive方法一次,并且receive方法会接收到一个String类型的message独享。
one(subscriber).receive(message);
}});
// execute
publisher.publish(message);
// verify
context.assertIsSatisfied();
}
}
通过上面的示例,我们可以归纳出利用jMock进行Mock测试的一般过程,用伪代码整理如下:
// 创建Mockery对象
public void testSomeAction(){
// 一些set up的工作
context.checking(new Expectations(){{
// 此处定义Expectations
}});
// 调用被测逻辑
context.assertIsSatisfied();
// 执行其他断言
}
1.4 Expectations 用法简介
jMock的Expectations具有如下结构:
invocation-count(mock-object).method(argumentconstraints);
inSequence(sequence-name);
when(state-machine.is(state-name));
will(action);
then(state-machine.is(new-state-name));
说明:
invocation-count
代表期望的方法调用次数,jMock提供了表达方法调用次数的多种手段
| 方法 | 含义 |
|---|---|
| One | 期望调用执行一次且仅一次 |
| Exactly(n).of | 期望调用执行n次。注意:one其实是exactly(1)的一种简写 |
| atLeast(n).of | 期望调用执行至少n次 |
| atMost(n).of | 期望调用执行至多n次 |
| between(min,max).of | 期望调用执行至少min次,至多max次 |
| allowing | 期望调用执行任意多次,包括0次 |
| Ignoring | 实际效果与allowing相同,两者只是意图表达上的差异 |
| never | 不期望被执行 |
argument-constraints
代表方法调用传入参数的约束条件,可以是精确匹配的条件,如下例所示,calculator的add方法只期望接受两个整数1作为参数:
one(calculator).add(1,1);
也可以利用with子句定义模糊匹配条件,同样是calculator的add方法,在下例则期望接受任意int类型的参数:
allowing(calculator).add(with(any(int.class)),with(any(int.class)));
除any外,jMock还提供了各种其他形式的参数约束子句
| 参数约束子句 | 含义 |
|---|---|
| equal(n) | 参数的取值等于n |
| Same(0) | 参数与0是一个对象 |
| any(Class<T> type) | 参数允许任意值,但必须是指定类型的 |
| a(Class<T< type) 或 an(Class<T< type) | 参数必须是指定类型的实例,或指定类型子类型的实例 |
| aNull(Class<T>type) | 参数为空,但必须是指定类型的 |
| aNonNull(Class<T>type | 参数为非空,且必须是指定类型的 |
| not(m) | 由m所代表的约束条件取反,可与其他约束条件组合使用 |
| anyOf( m 1 m_1 m1, m 2 m_2 m2,…, m n m_n mn) | 参数满足由从 m 1 m_1 m1到 m n m_n mn所代表的所有约束条件中的任何一个 |
| allOf( m 1 m_1 m1, m 2 m_2 m2,…, m n m_n mn) | 参数满足由从 m 1 m_1 m1到 m n m_n mn所代表的所有约束条件 |
will
代表方法调用返回情况的约束条件
| 返回情况的约束条件 | 含义 |
|---|---|
| will(returnValue(v)) | 期望返回值为v |
| will(returnIterator© | 每次调用时返回容器c的一个迭代子 |
| will(returnIterator( v 1 v_1 v1, v 2 v_2 v2,…, v n v_n vn)) | 每次调用时返回从元素 v 1 v_1 v1到 v n v_n vn的一个迭代子 |
| will(returnException(e) | 抛出一个异常e |
| will(doAll( a 1 a_1 a1, a 2 a_2 a2,…, a n a_n an | 可与其他will子句组合使用,代表每次调用时执行从 a 1 a_1 a1到 a n a_n an的若干动作 |
inSequence
用于定义多个方法调用的执行顺序,inSequence子句可以定义多个,其在测试代码中出现的次序,便是方法调用的执行顺序。为了定义一个新的顺序,首先需要定义一个Sequence对象,如下所示:
final Sequence sequence-name=context.sequence("sequencename");
而后,为了定义方法调用的执行顺序,可以在依序写好的每个Expectation后面添加一个inSequence子句,如下所示:
one(turtle).forward(10);inSequence(drawing);
one(turtle).turn(45);inSequence(drawing);
one(turtle).forward(10);inSequence(drawing);
when和then
用于定义方法仅当某些条件为true的时候才调用执行,从而进一步对Mock对象的调用情况进行约束。在jMock中,这种约束是通过状态机的形式来达成的。首先,我们需要定义一个状态机实例,其中的初始状态(initial-state)是可选的:
final States state-machine-name=context.states("state-machine-name").startsAs("initialstate");
然后,我们可以利用when子句来定义当处于某状态时方法被调用执行,利用then来定义当某方法被调用执行时,状态的迁移情况。
final States pen=context.states("pen").startAs("up");
one(turtle).penDown();then(pen.is("down"));
one(turtle).forward(10);when(pen.is("down"));
one(turtle).turn(90);when(pen.is("down"));
one(turtle).forward(10);when(pen.is("down"));
one(turtle).penUp();then(pen.is("up"));
1. 在项目中引入JMock库
在Eclipse中,在项目的Build Path中添加JMock库:
- 打开项目的Build Path设置
- 右键右击项目-》Build Path-》Configure Build Path
- 添加JMock及其依赖库
- 点击"Add JARs…"或者“Add External JARs…”
- 选择jmock.jar和hamcrest-core.jar文件
- 点击“OK”
2.创建单元测试类
创建一个单元测试类,比如说TestCalculator.java。
3.导入相关库并创建Mock对象
import org.jmock.Mockery;
import org.jmock.Expectations;
public class TestCalculator{
public void testAddition(){
Mockery context=new Mockery();
final CalculatorService service=context.mock(CalculatorService.class);
}
}
以上代码:
- 导入JMock框架相关的库。
- 创建了一个Mockery对象,用于管理所有Mock对象
- 使用context.mock()方法创建了一个CalculatorService接口的Mock对象,可以用来代替真实的CalculatorService对象进行测试。
4.指定Mock对象的行为
在测试代码中,我们可以使用Expectations类和其相应的静态方法来指定Mock对象的行为。例如:
public void testAddition(){
//...
context.checking(new Expectations(){{
oneOf(service).add(1,2);will(returnValue(3));
}});
//...
}
以上代码:
- 使用Expectations的匿名内部类实例来描述Mock对象的行为。
- 可以使用oneOf()方法指定只调用一次add()方法。
- 当调用add()方法时,将会返回3
5.执行测试
测试代码编写完成后,可以执行测试用例来查看是否符合预期,在Eclipse中,可以右键点击TestCalculator.java并选择"Run As"->"JUnit Test"来执行单元测试。对于真实世界的应用场景,需要根据具体需求进行相应的调整和扩展。
第二章 Appium简明教程
2.1 appium概述
appium是一个自动化测试开源工具,支持iOS平台和Android平台上的原生应用,web应用和混合应用。
appium类库封装了标准Selenium客户端类库,为用户提供所有常见的JSON格式selenium命令以及额外的移动设备控制相关的命令,比如多点触控手势和屏幕朝向。
appium选择了Client/Server的设计模式。只要client能够发送http请求给server,那么的话client用什么语言实现都是可以的,这就是appium及selenium(WebDriver)如何做到支持多语言的原因;
appium扩展了WebDriver的协议,没有自己重新去实现一套。这样的好处是以前的WebDriver API能够直接被继承过来,以前的Selenium(WebDriver)各种语言的binding都可以拿来就用,省去了为每种语言开发一个client的工作量。
2.2 appium工作原理
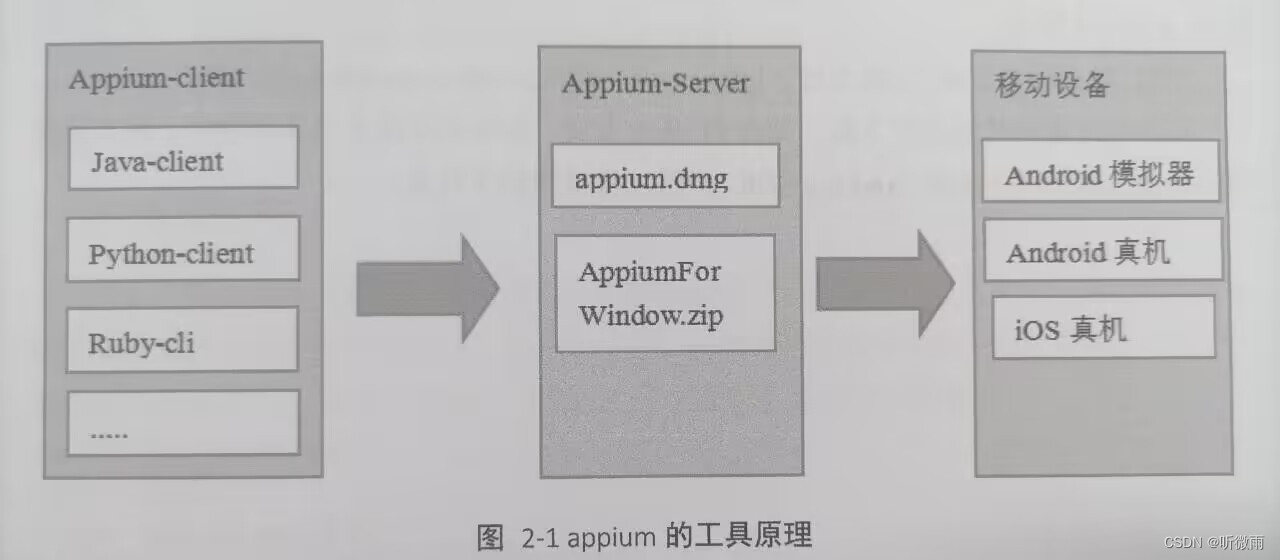
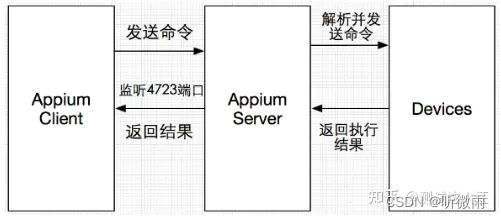
比如通过Python(python-client)编写了一个appium自动化脚本并执行,请求会首先到appium.dum(MAC下的appium-Server),appium-Server通过解析,驱动iOS设备来执行appium自动化脚本
或者,在Windowsp平台上,通过java(java-client)编写了一个appium自动化脚本并执行,请求会首先到appiumForWindow.zip(Window下的appium-Server),appium-Server通过解析,驱动Android虚拟机或真机来执行appium脚本。
2.3 Desired Capabilities
Desired Capabilities在启动session的时候是必须提供的。
Desired Capabilities本质上是以key value字典的方式存放,客户端将这些键值对发给服务端,告诉服务端我们想要怎么测试。它告诉appium Server这样一些事情:
- deviceName:启动哪种设备,是真机还是模拟器?iPhone Simulator, iPad Simulator, iPhone Retina 4-inch, Android Emulator, Galaxy S4…
- automationName: 使用哪种自动化引擎。appium(默认)还是Selendroid。
- platformName: 使用哪种移动平台。iOS, Android, orFirefoxOS。
- platformVersion: 指定平台的系统版本。例如指的Android平台,版本为5.1。
- appActivity: 待测试的app的Activity名字。比如MainActivity,.Settings。注意,原生app的话要在activity前加个"."。
- appPackage: 待测试app的java package。比如com.example.android.myApp,com.android.settings。
2.4 定位控件
id定位
python版本
driver.find_element(By.ID,'id'))
java版本
driver.findElement(By.id("id"));
name定位
python版本
driver.find_element(By.NAME,'name'))
java版本
driver.findElement(By.name("name"));
class name定位
python版本
driver.find_element(By.CLASS_NAME,'class name'))
java版本
driver.findElement(By.className("class name"));
XPath定位
python版本
driver.find_element(By.XPATH,'xpath'))
java版本
driver.findElement(By.xpath("xpath"));
2.5 appium API之应用操作
安装应用:installApp()
安装应用到设备中去
driver.installApp("D:\android\apk\ContactManager.apk");
卸载应用:removeApp()
从设备中删除一个应用
driver.removeApp("com.example.android.apis");
关闭应用:closeApp()
关闭打开的应用,默认关闭当前打开的应用,所以不需要入参。这个方法并非真正的关闭应用,相当于按home键将应用置于后台,可以通过launchApp()再次启动。
启动应用:launchApp()
重新启动应用也是一个测试点,该方法需要配合closeApp()使用。
driver.closeApp();
driver.launchApp();
第三章 jmeter
性能测试用例
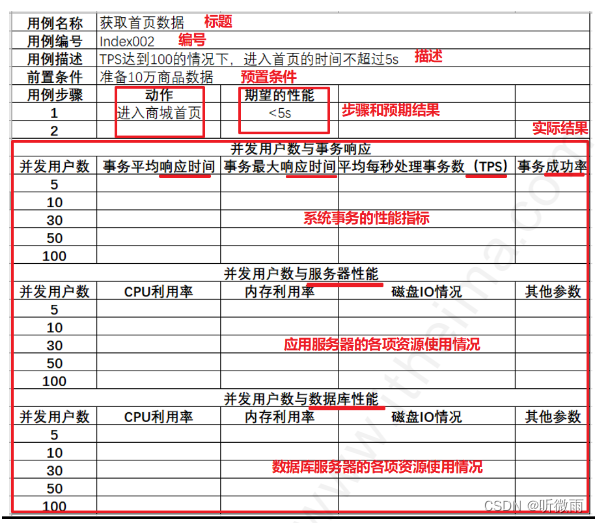
基准测试:
- 狭义上:单用户测试,记录性能指标
- 广义上:设置基准线,后续软硬件条件发生变化时,再进行同样基准测试对比观察性的变化
负载测试: 逐步增加系统负载,找到满足系统需求情况下的最大负载量的测试
稳定性测试: 在用户正常的业务负载下,长时间(1天-7天)测试,观察系统是否能稳定运行
并发测试: 极短时间内,发送大量请求,观察系统是否能并发执行
压力测试: 在高负载的情况下,观察系统是否有好的容错能力和可恢复能力。包括:高负载下的长时间稳定性压力测试和极限负载下的破坏力压力测试
性能测试的指标:
响应时间:客户端发起请求开始,到收到响应的总时间,包含:服务器处理时间+网络传输时间
并发(用户)数:同一段时间往服务器发送请求的用户数
吞吐量:单位时间内,服务器处理的客户端请求的数量。QPS和TPS
点击数:访问页面时,加载页面的各种元素(文本,图片,css,js等)的请求数量
错误率:在用户负载情况下,失败业务的概率。主义:与功能的随机bug区分
资源使用率:使用系统时,资源占用的比例。常见:CPU、内存、磁盘、网络
什么是参数化?
把测试数据组织起来,用不同的测试数据调用相同的测试方法。
4种参数化方式有何不同?如何选择适当的方式?
用户定义的变量:
- 作用:定义全局变量
- 局限性:每次取值(无论是否相同的用户)都是固定值
用户参数:
- 作用:保证不同的用户针对同一组参数,可以取到不同的值
- 局限性:同一个用户在多次循环时,取到相同的值
CSV数据文件设置:
- 作用:保证不同的用户及同一用户多次循环时,都可以取到不同的值
- 局限性:需要手动进行测试数据的设置
函数:
- 作用:保证不同的用户及多次循环时,都可以取到不同的值,不需要提前设置
- 局限性:输入数据有特定的业务要求时无法使用(如:登录时的用户名密码)
3.1 基础介绍
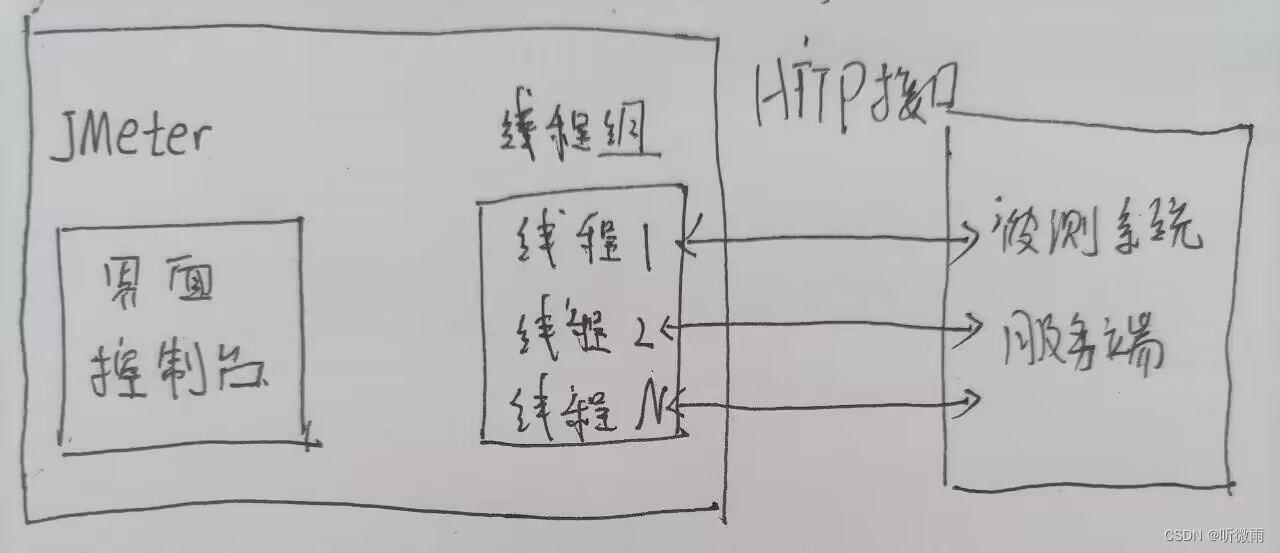
1. 组成部分
1)负载发生器:产生负载,多进程或多线程模拟用户行为
2)用户运行器:脚本运行引擎,用户运行器附加在进程或线程上,根据脚本模拟指定的用户行为
3)资源生成器:生成测试过程中的服务器、负载机的资源数据
4)报表生成器:根据测试中获得的数据生成报表,提供可视化的数据显示方式。
2.测试计划
测试计划:描述一个性能测试,包含本次测试所有相关功能。
threads(users)线程:
- Setup thread group: 一种特殊类型的线程,可用于执行预测试操作。即执行测试前进行定期线程组的执行。
- Teardown thread group:一种特殊类型的线程,可用于执行测试后动作。即执行测试结束后执行定期的线程组。
- 以上两个线程组,举个例子:loadrunner的脚本除了action里是真正的脚本核心内容,还有初始化“环境”的初始化脚本和测试完毕后对应的清除信息的脚本块,与其对应。
- Thread group:通常添加使用的线程,一般一个线程组可看做一个虚拟用户组,其中每个线程为一个虚拟用户。
测试片段:一种特殊的线程组,在测试树上与线程组一个层级,但是它不被执行,除非它是一个模块控制器或者被控制器所引用时才会被执行
控制器:Jmeter有2种控制器,取样器(sampler)和逻辑控制器(Logic Controller);作用:用这些原件驱动处理一个测试
- 取样器(Sampler):是性能测试中向服务器发送请求,记录响应信息,记录响应时间的最小单元,JMeter原生支持多种不同的sampler。如 HTTP Request Sampler、FTP Request Sampler、TCP Request Sampler等。每一种不同类型的sampler可以根据设置的参数向服务器发出不同类型的请求。Java Request Sampler和Beanshell Request Sampler是两种特殊的可定制的Sampler。
- 逻辑控制器(Logic Controller):包含两类原件:一类是控制Test Plan中Sampler节点发送请求的逻辑顺序控制器,常用的有:If Controller、Swith Controller、Loop Controller、Random Controller等。另一类是用来组织和控制Sampler节点的,如Transaction Controller、Throughput Controller等。
监听器:对测试结果进行处理和可视化展示的一系列组件,常用的有图形结果、查看结果树、聚合报告等。
配置原件:用来提供对静态数据的支持。CSV Date Set Config 可以将本地数据文件形成数据池(Date Pool),而对应于HTTP Request Configuration和TCP Request Sample等类型的Configuration元件则可以修改这些Sample的默认数据等。
定时器:用于操作之间设置等待时间,等待时间是性能测试中常用的控制客户端QPS的手段,jmeter定义了Constant Times、Constant Throughput Times、Guass Ramdon Times等不同类型的Times。
断言:用于检查测试中得到的响应数据等是否符合预期,Assertions一般用来设置检查点,用来保证性能测试过程中的数据交互与预期一致。
前置处理器:用于在实际请求发出之前对即将发出的请求进行特殊处理。例如:Count处理器可以实现自增操作,自增后生成的数据可以被将要发出的请求使用,而HTTP URL Re-Writing Modifier处理器则可以实现URL重写,当URL中有sessionID一类的session信息时,可以通过该处理器填充发出请求实际的sessionID。
后置处理器:
用于对Sampler发出请求后得到的服务器响应进行处理。一般用来提取响应中的特定数据(类似loadrunner中的关联)。例如:Regular Expression Extractor用于提取响应数据中匹配某正则表达式的数据段,并将其填充在参数中,Xpath Extractor则可以用于提取响应数据中通过给定Xpath值获得的数据。
简单来说:
取样器-》发送请求
逻辑控制器-》控制语句的执行顺序
前置处理器-》对请求参数进行预处理
后置处理器-》对响应结果进行提取
断言-》检查接口的返回结果是否与预期结果一直
定时器-》设置等待
测试片段-》封装一段代码,供其他脚本调用
配置元件-》测试数据的初始化配置
监听器-》查看Jmeter脚本的运行结果
3.2 元件的作用域及执行顺序
jmeter主要依靠test plan中元件的相对位置,父子关系以及元件本身的类型来决定test plan中各元件的执行顺序;元件在test plan中的位置不同,可能导致该元件的行为有很大差异
1、元件的作用域
jmeter中共有8类可被执行的元件(test plan和thread group不属于元件),其中,sampler(取样器)是不与其他元件发生交互的作用的元件,Logic Controller(逻辑控制器)只对其子节点的sampler有效,而其他元件需要与sampler等元件交互。
Config Elements(配置元件):影响其范围内的元件
Pre-processors(前置处理器):在其作用范围内的每一个sampler元件之前执行
Timer(定时器):对其作用范围内的每一个sampler有效
Post-porcessors(后置处理器):在其作用范围内的每一个sampler元件之后执行
Assirtions(断言):对其作用范围内的每一个sampler元件执行后的结果进行校验
Listener(监听器):收集其作用范围内的每一个sampler元件的信息并且呈现出来
在jmeter中,元件的作用域是靠test plan的树形结构中元件的父子关系来确定的,其原则如下:
1)sampler不与其他元件相互作用,因此不存在作用域问题
2)Logic Controller只对其子节点中的sampler和Logic Controller作用
3)除sampler和Logic Controller外的其他元件,如果是某个sampler的子节点,则该元件仅对其父节点作用。
4)除sampler和Logic Controller外的其他元件,如果其父节点不是sampler,则其作用域是该元件父节点下的其他所有后带节点(包括子节点,子节点的子节点等)
提示:所有的组件都是以取样器为核心来运行的,组件添加的位置不同,生效的取样器也不同
2、元件的执行顺序
在同一作用域范围内,test plan中的元件按照以下顺序执行:
1) Config Elements
2)Pre-porcessors
3)Timer
4)Sampler
5)Post-porcessors(除非Sampler得到的返回结果为空)
6)Assirtions(除非Sampler得到的返回结果为空)
7)Listener(除非Sampler得到的返回结果为空)
注意:Pre-porcessors、Post-porcessors和Assirtions等元件仅对Sampler作用,如在它们作用域内没有任何Sampler,则不会被执行
如果在同一作用域范围内用多个同一类型的元件,这些元件按照它们在test plan中的上下顺序依次执行。
3.3 组件的介绍
组件:实现独立的某个功能(类似于方法)
3.4 Sampler之SOAP/XML-RPC Request
SOAP(Simple Object Access Protocol)简单对象访问协议是在分散或分布式的环境中交换信息的简单的协议,是一个基于XML的协议;
SOAP/XML-RPC Request适用于xml文件请求,常见的就是对微信H5页面的请求。
一个取样器通常进行三部分的工作:向服务器发送请求,记录服务器的响应数据和记录相应时间信息
xml和json的区别:
xml:是一种可扩展标记语言,提供描述结构化数据的方法,用于定义数据本身结构和数据类型,简单讲,xml就是一个文件
json:常见的报文大多是json类型,json本身是一种数据类型,特点是键值对:即每个键对应一个值,其键值对数据由逗号分隔,花括号{}保存对象,方括号[]保存数组
线程执行完成后,根据结果树中的请求和响应结果(成功或者失败)就可以分析我们的测试是否成功,以及根据聚合报告来确认我们这次确认是否达成了预期结果。
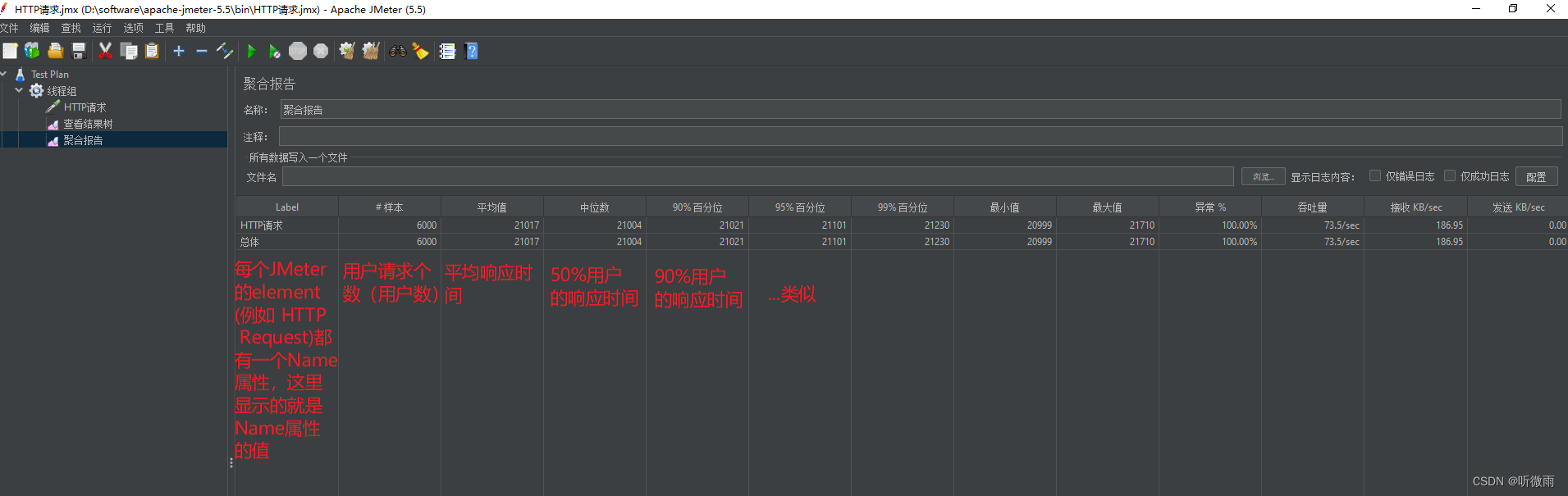
参数介绍
- Label:每个请求的名称
- 样本:各样本发出的数量
- 平均值:平均响应时间(单位:毫秒)
- 中位数:中位数,50%<=时间
- 90%百分比:90%<=时间
- 95%百分比:95%<=时间
- 99%百分比:99%<=时间
- 最小值:最小响应时间
- 最大值:最大响应时间
- 异常%:请求的错误率
- 吞吐量:吞吐量。默认情况下表示每秒完成的请求数,一般认为它为TPS
- 接收KB/sec:每秒接收到的千字节数
- 发送KB/sec:每秒发送的千字节数
为什么要使用分布式?
在使用JMeter进行性能测试时,如果项目需要支持10000用户并发,但是单台电脑只能支持1000个用户并发,这个时候就需要用到JMeter分布式了
JMeter分布式执行原理:
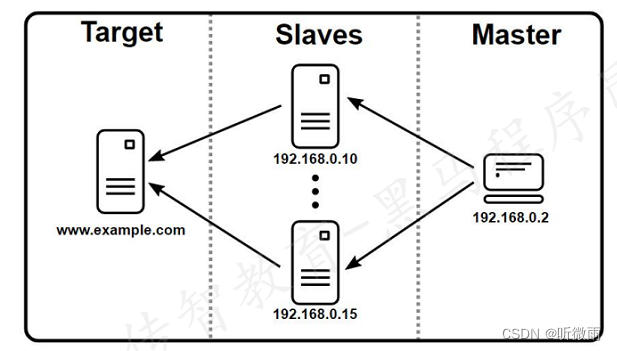
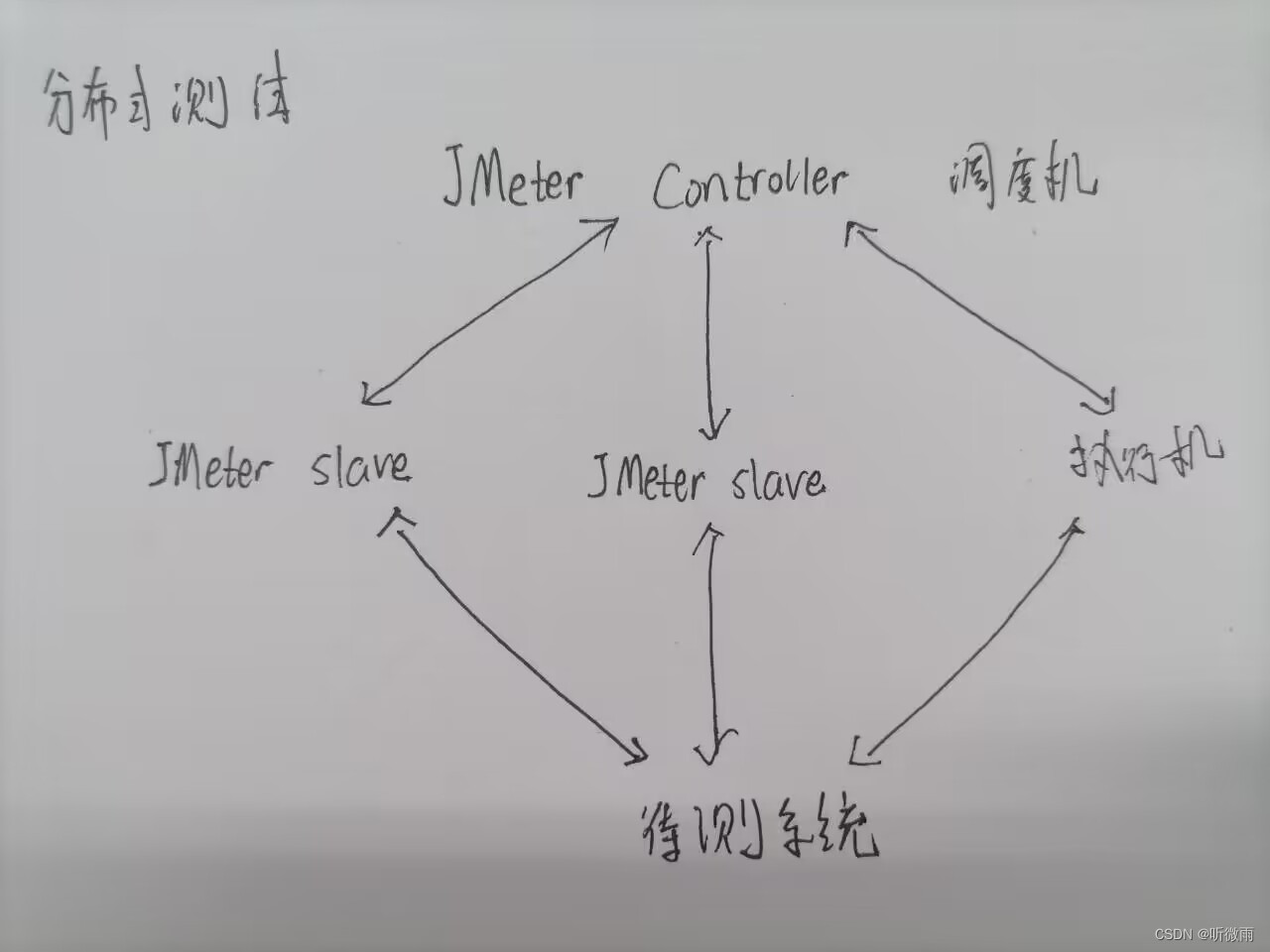
JMeter分布式测试时,选择其中一台作为控制机,其它机器作为代理机
- 执行时,控制机会把脚本发送到每台代理机上
- 代理机拿到脚本后就开始执行,代理机执行时不需要启动JMeter界面,可以理解它是通过命令行模式执行的
- 执行完成后,代理机会把结果回传给控制机,控制机会收集搜索代理机的信息并汇总
分布式压力测试:时间不够,单个电脑能力有限。性能测试负载是非常大的,所以要用分布式。jmeter是java开发的工具,虚拟用户以线程的形式实现,在大量的并发是很容易出现cpu消耗过大的。笔记本内存溢出,一般一个电脑上百个线程就差不多得了,测试需要先保证自己的电脑不崩溃,模拟足够多的线程去测试服务端,使用分布式测试,一个能调度所有执行的机器,又有一个jmetercontroller。调动机器启动后会自动拷贝,如果使用csv参数化每一台需要设置一模一样的。调度机控制所有执行机,测试过程中需要监控cpu、内存等等,线程数*循环的次数*执行机的数量
JMeter的两种使用方法和他们的适用场景:
1.GUI模式:GUI模式即图形用户界面模式,通过JMeter自带的GUI界面来进行测试脚本的编写和执行。在此模式下,用户可以通过拖拽操作来添加各种测试元素,并进行各种配置。此模式的适用场景是:初学者或没有深入了解JMeter的人可以使用该模式快速上手,且可以直观的看到测试结果
2.Non-GUI模式:Non-GUI模式即非图形用户界面模式,通过命令行执行测试脚本,在此模式下,用户需要先通过GUI模式编写好测试脚本,并保存为.jmx文件,然后再命令行中执行该文件。此模式的优点是:节约系统资源,可以更好的模拟真实的测试环境,适用于大规模测试。
对于性能测试设计用例,可以使用JMeter创建和配置测试计划,具体步骤如下:
- 创建测试计划:在JMeter中创建一个测试计划(Test Plan)
- 添加线程组:为了模拟用户并发访问,在测试计划中添加至少一个线程组(Thread Group),并设置线程数、请求间隔时间和持续时间等参数。
- 添加取样器:选择需要测试的协议(例如HTTP),并添加相应的取样器(Sampler)。配置取样器的参数,例如URL地址、请求方法、请求头、请求体等。
- 添加断言:为了验证测试结果是否符合预期,可以添加断言(Assertion),例如响应代码、响应时间
- 添加监听器:用于记录测试结果。常见的监听器有查看结果树(View Results Tree)、聚合报告(Aggregate Report)等。
- 运行测试:单击“运行”按钮即可开始测试,并可以监控测试进度和结果。
第四章 selenium自动化
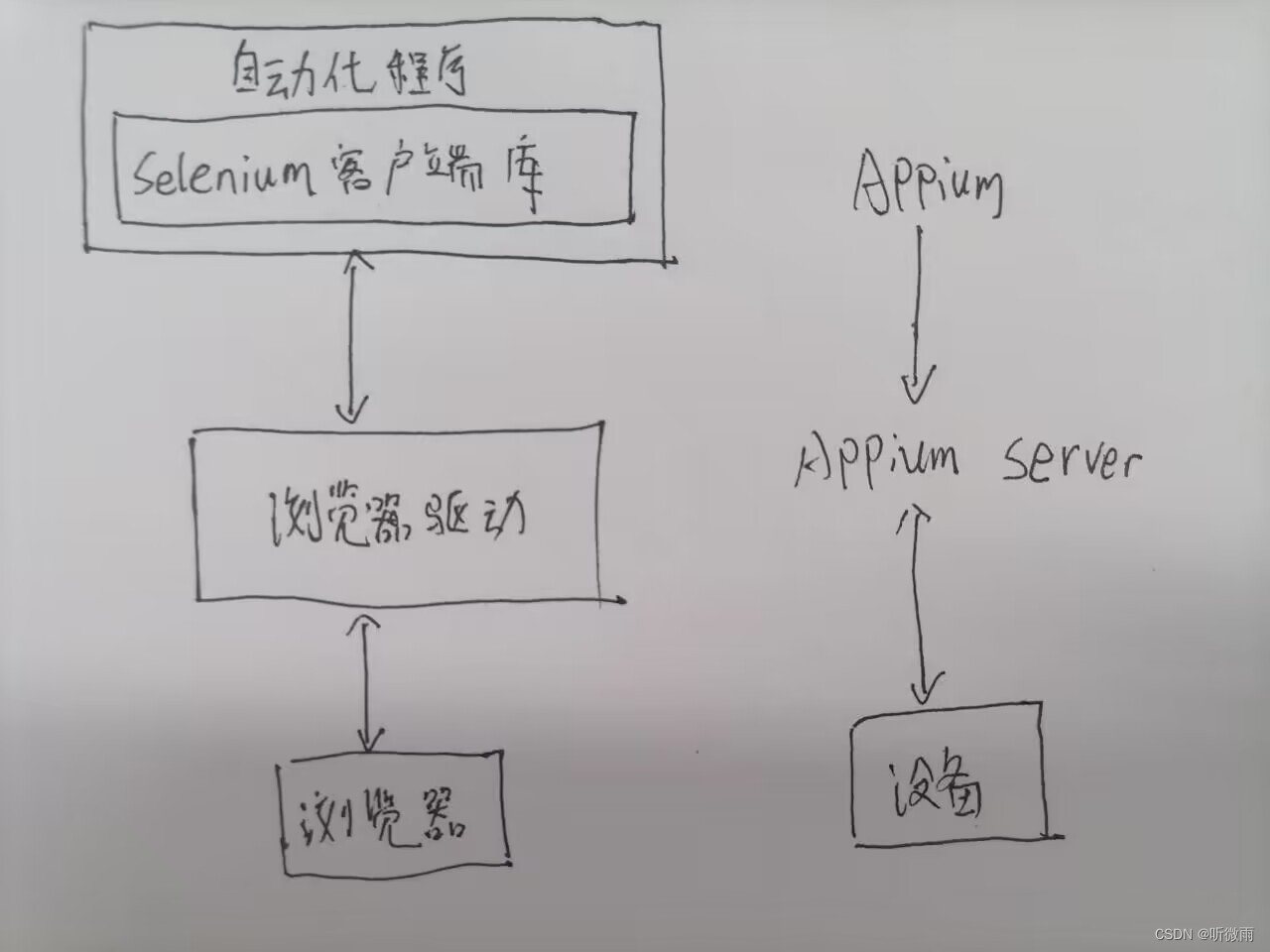
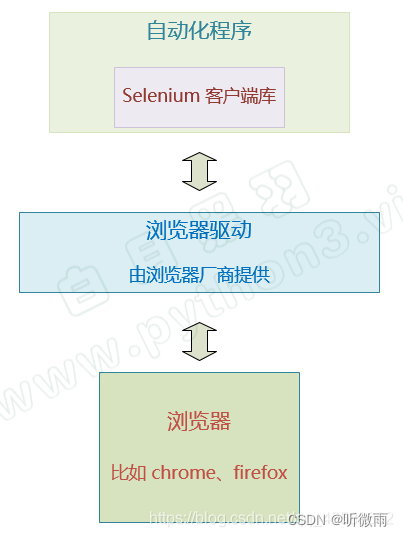
selenium自动化流程如下:
自动化程序调用selenium客户端库函数(比如点击按钮元素)
客户端库会发送selenium命令给浏览器的驱动程序
浏览器驱动程序接收到命令后,驱动浏览器去执行命令
浏览器执行命令
浏览器驱动程序获取命令执行的结果,返回给我们自动化程序
自动化程序对返回结果进行处理
第五章 RQM
RQM执行步骤
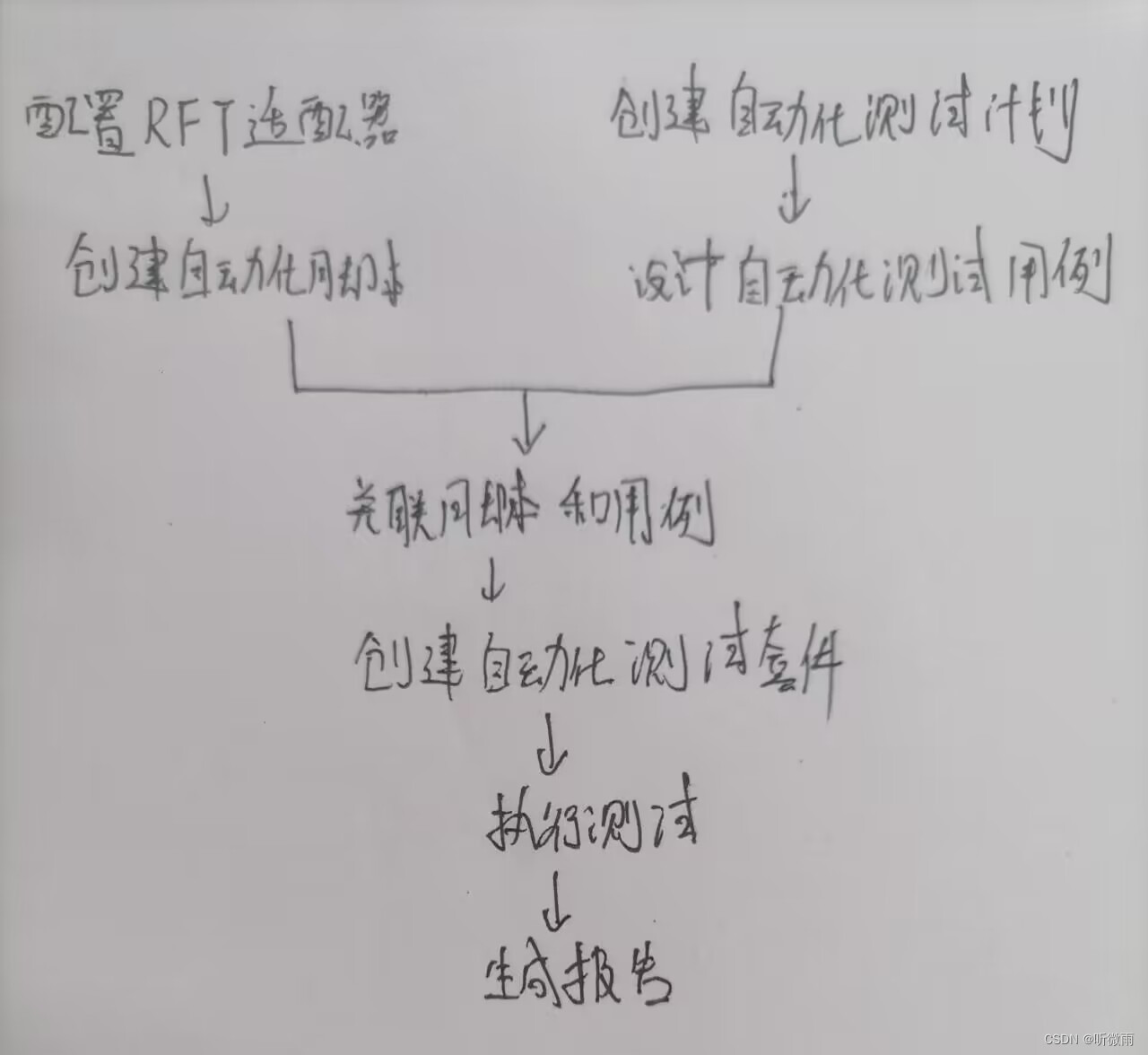
RQM和RTF不是同一个产品,RQM更加关注整体的测试流程,而RTF更关注自动化测试,这里是将两个产品结合实现的非常完整的测试流程。套件就理解为一套一套的,可以一次性执行很多个测试用例(批量运行)






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结