您现在的位置是:首页 >学无止境 >基于yolov5的NEU-NET产品缺陷目标检测网站首页学无止境
基于yolov5的NEU-NET产品缺陷目标检测
........第一次写,没啥经验,内容的话就讲诉大概怎么实现吧!具体分析没写,遇到问题和需要源码的小伙伴可后台私信,有看到的话就发....
- yolov5的使用
1.1 YOLOv5的介绍与特点
YOLOv5 是一种轻量级、高效的目标检测算法,是 YOLO 系列最新的版本。与 YOLOv4 相比,YOLOv5 在速度和精度方面都有所提升,尤其是采用了新的网络结构,使得模型大小更小、速度更快。YOLOv5 基于 PyTorch 框架实现,并支持多种主流数据集(如 COCO、VOC 等)。通过使用汽车、行人、动物等相关的数据进行训练,使得 YOLOv5 在自动驾驶、智能安防、生命科学、医疗装备等领域中有着广泛的应用。YOLOv5 的核心思想是将目标检测问题转化为回归问题,即预测目标框的坐标和形状。在训练过程中,YOLOv5 将图片分割成网格,每个网格负责检测该区域内是否存在对象,并预测出对象的类别和位置。然后将所有的框按照置信度(confidence)排序,根据设定的阈值筛选出有效的框。
相较于传统的目标检测方法,YOLOv5 具有以下特点:
1. 高速度:由于 YOLOv5 采用了轻量级的网络结构,因此处理速度较快。
2. 高精度:YOLOv5 通过网络的优化,提高了模型的检测精度。
3. 支持不同尺寸的输入图像:YOLOv5 可以适应不同尺寸的输入图像。
总之,YOLOv5 是一种高效、准确的目标检测算法,可以应用于多种领域,具有广泛的应用前景。
1.2 YOLOv5的基本使用
data 文件夹用于存储相关的数据和配置文件,models 文件夹用于存储预训练模型,runs 文件夹用于存储运行时输出的相关信息,utils 文件夹则包含一些辅助工具函数。除此之外,针对不同的应用情况,还可以增加其他的代码文件进行适当的扩展。
1.3目录结构树
yolov5
├── data
│ ├── coco.yaml # COCO 数据集的配置文件
│ ├── custom.yaml # 自定义数据集的配置文件
│ ├── images # 存储测试图像的目录
│ ├── labels # 存储标签的目录(如果你使用 COCO 数据集,则该目录不需要)
│ ├── test # 存储测试数据的目录
│ ├── train # 存储训练数据的目录
│ └── val # 存储验证数据的目录
├── models # 可以自己预训练模型存放的目录,也可以下载其他官方实现的模型
├── runs # 运行时输出的跟踪结果、调试信息等信息存储的文件夹
├── utils # 存储与 YOLOv5 相关的辅助工具函数、类和库
├── detect.py # 检测器的实现代码
├── export.py # 模型导出的实现代码
├── hubconf.py # Hub Model API 的实现代码
├── test.py # 测试模型的实现代码
├── train.py # 训练模型的实现代码
└── val.py # 验证模型的实现代码
使用 YOLOv5 进行图片目标检测的步骤如下:
第一步:准备数据集和相关文件。将数据集(包括训练集、验证集和测试集等)放在指定的目录中,并准备好数据集的配置文件(如 data/custom.yaml),确定模型的参数设置(如输入尺寸、学习率等)以及其他必要的文件。
第二步:确定使用的检测器。对于不同的应用场景,可以选择不同的预训练模型或者自己训练一个新模型。模型通常存储在 models 文件夹中,可以调整模型的大小、深度等参数来适应不同的需求。
第三步: 编写检测代码。通过调用 detect.py 脚本来实现图片目标检测功能,具体流程如下:
加载模型:通过 torch.hub.load('ultralytics/yolov5', 'yolov5s') 或者其他方式载入需 要使用的模型。
读取图像:使用 OpenCV 或 Pillow 库载入待识别的图像,并对图像进行相应的预处理(如缩放、归一化等)。
进行目标检测:将预处理后的图像作为输入,通过模型进行目标检测,并得到检测结果(如目标的位置、置信度等)。
可视化结果:将检测结果可视化,例如在图像上直接绘制框出目标的矩形框、类别等信息。
输出结果:将结果保存到指定的文件夹中。
第四步:运行代码并进行调试。执行检测代码,并根据实际需求进行参数优化和模型调整等操作,以达到更好的检测结果。
以上就是使用 YOLOv5 进行图片目标检测的基本步骤。需要注意的是,在实际应用中,还需要考虑如何优化检测精度、提高算法效率等问题,通过综合考量各种因素来得到最优的解决方案。
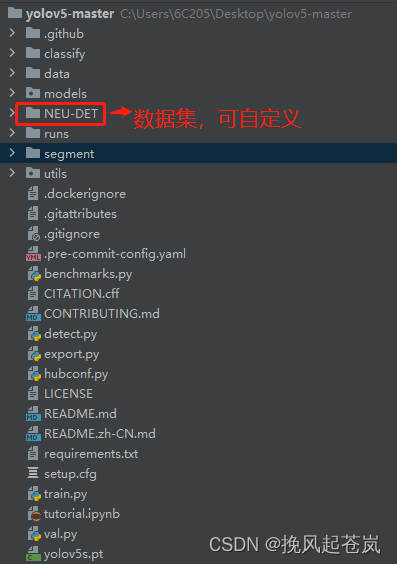
2.1 NET-NET数据集
NEU-NET 数据集是一种检测金属缺陷的数据集,其中包括 1800 个来自六个不同类别的 200x200 像素图像,每个类别分别为:脆性(C),夹杂(I),气孔(P),网状(R),沙眼(S)和弯曲(W)。该数据集旨在帮助钢铁工业、机器视觉等领域的研究人员和工程师开发出高效而准确的目标检测算法。
NEU-NET 数据集基于真实的金属表面缺陷图像生成,涵盖了许多真实场景中可能遇到的不同类型的缺陷。同时,与其他缺陷检测数据集相比,NEU-NET 数据集的图片分辨率相对较低,可以更快地训练模型。此外,该数据集还配备了丰富的参考文献和测试报告,方便研究人员进行进一步的研究和评估。
NEU-NET 数据集是一个开源数据集,可以免费下载使用。由于其简单而有效的设计,该数据集已经成为了许多金属缺陷检测算法的基准数据集之一。
xml文件转txt文件
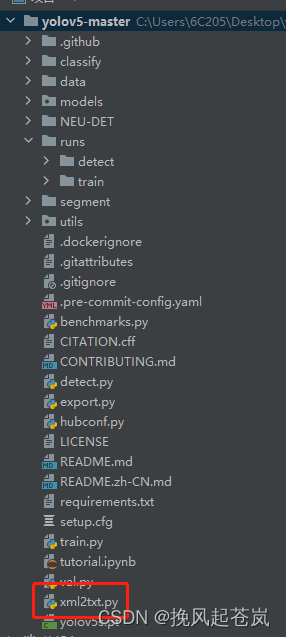

划分测试集与训练集

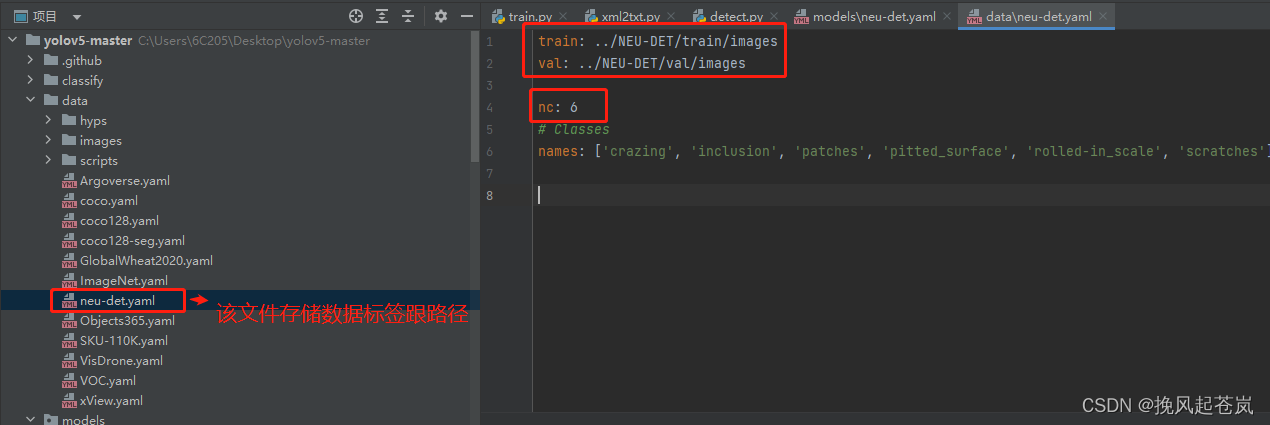
编辑存储数据的类别和路径的yaml文件(文件名可以自定义)
编辑训练模型文件(文件名可以自定义)

编写训练文件train.py文件(这里是用pycharm编译运行,还可以cmd指定参数运行,或者修改py文件配置运行)
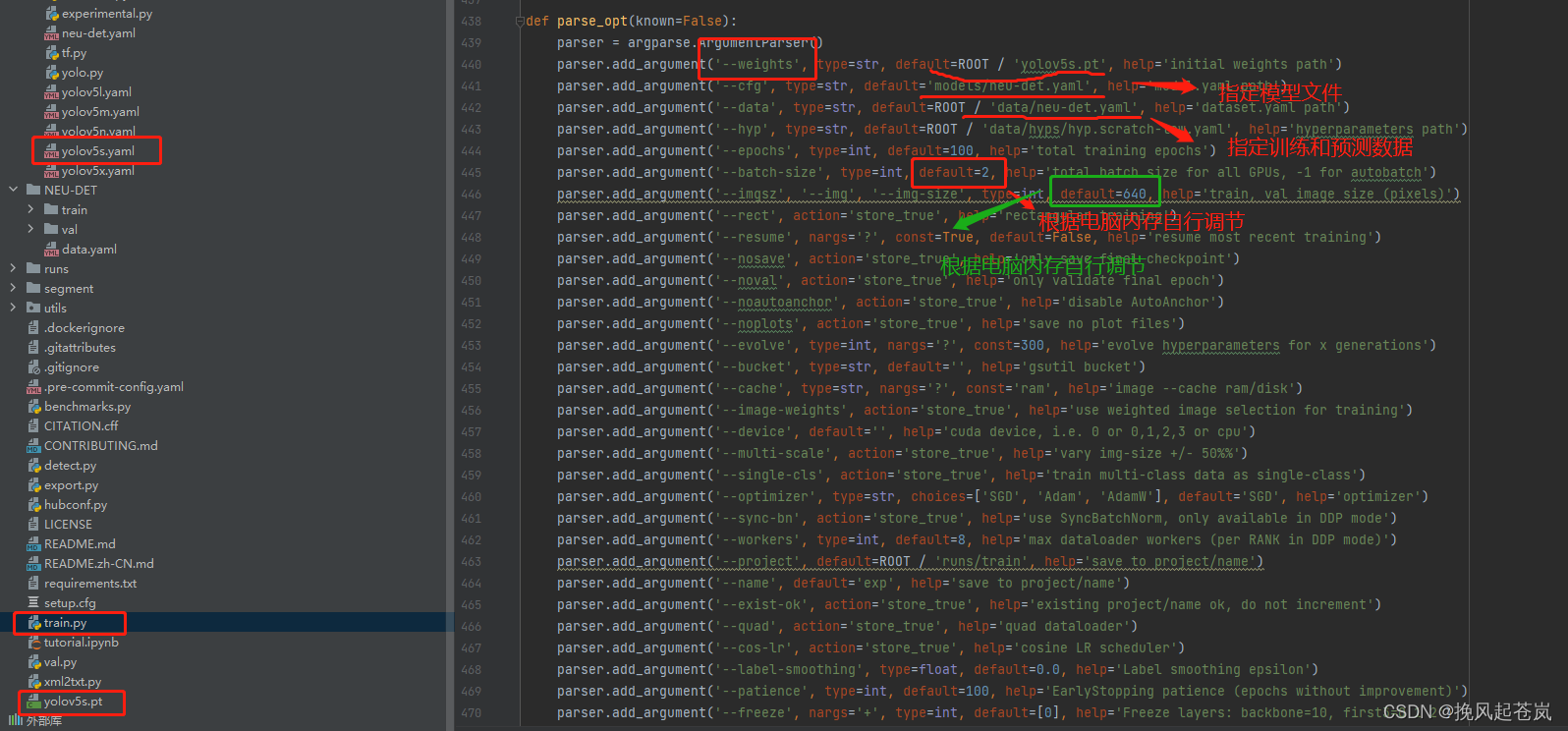
改写好训练文件参数后,即可右键一键训练(前提条件,安装好环境配置)
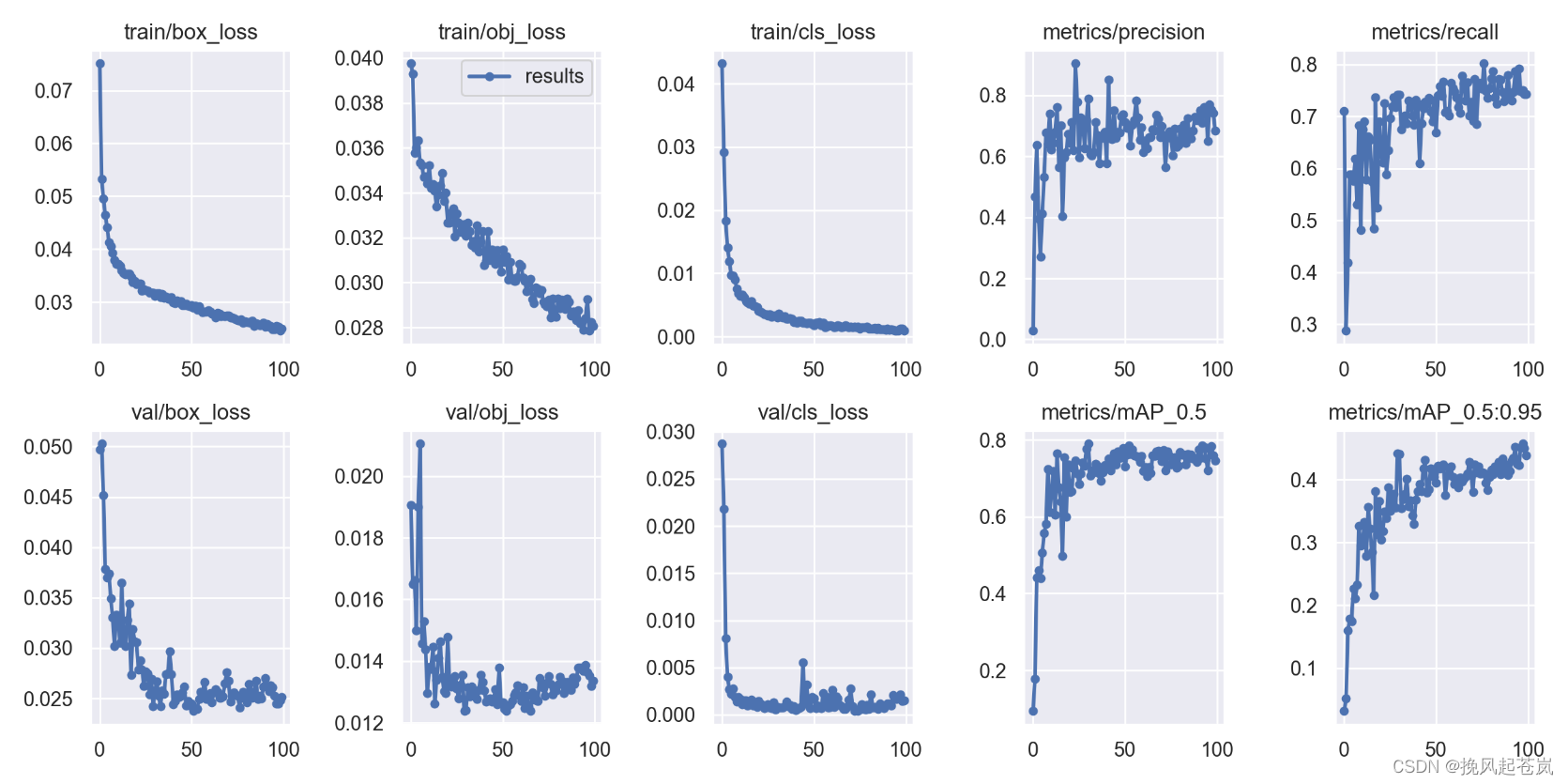
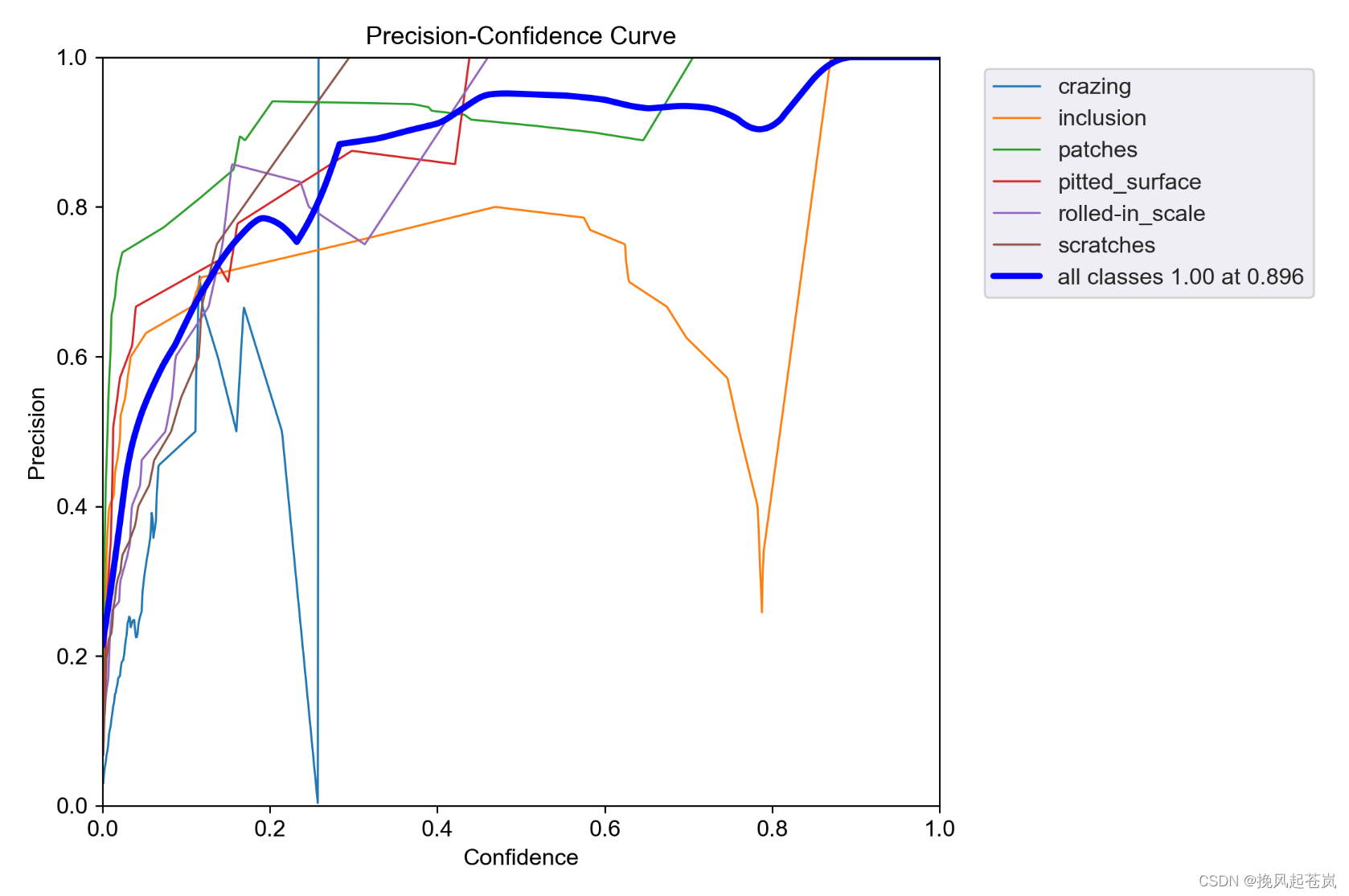
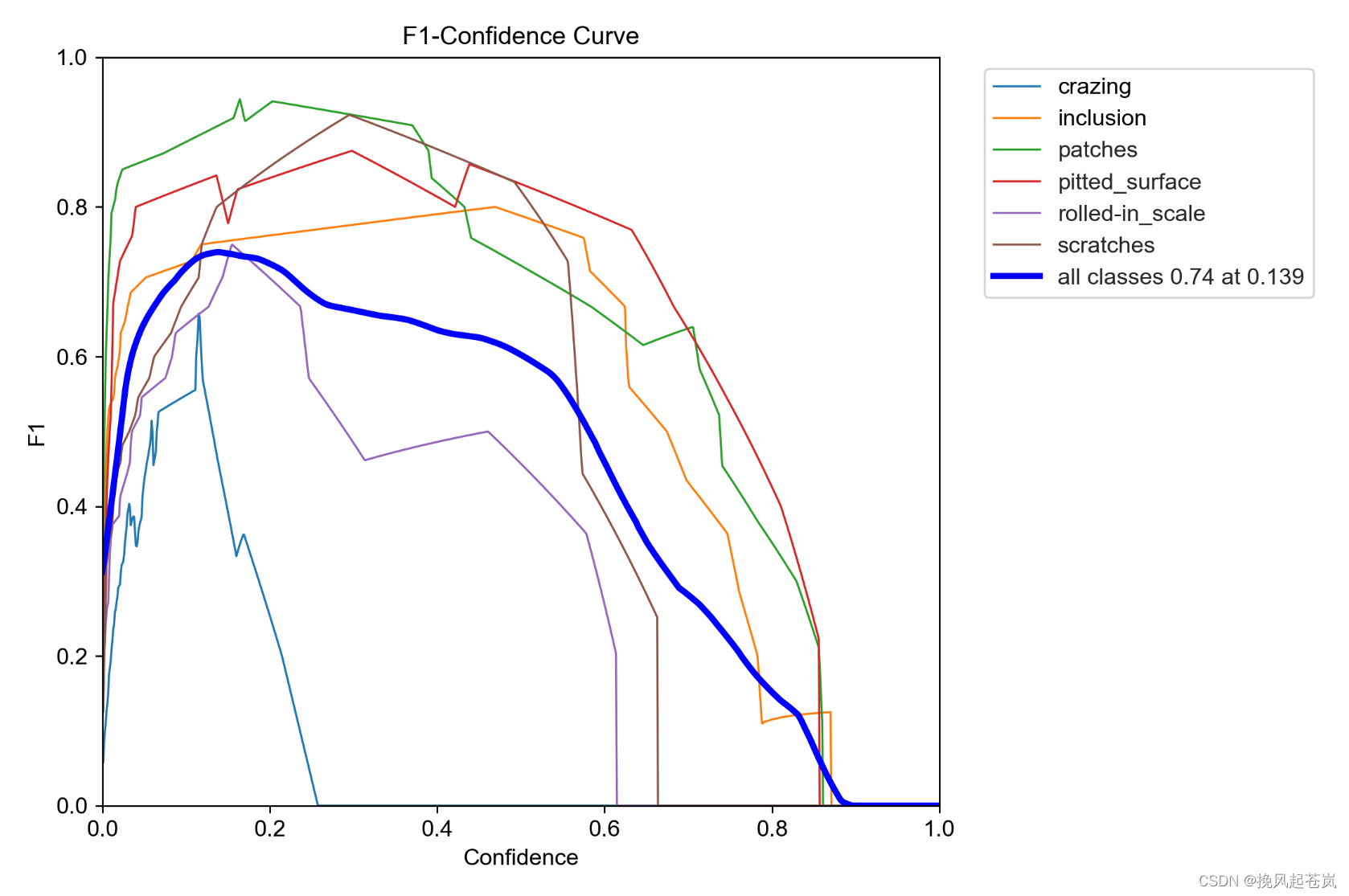
以下是迭代100次后的训练结果
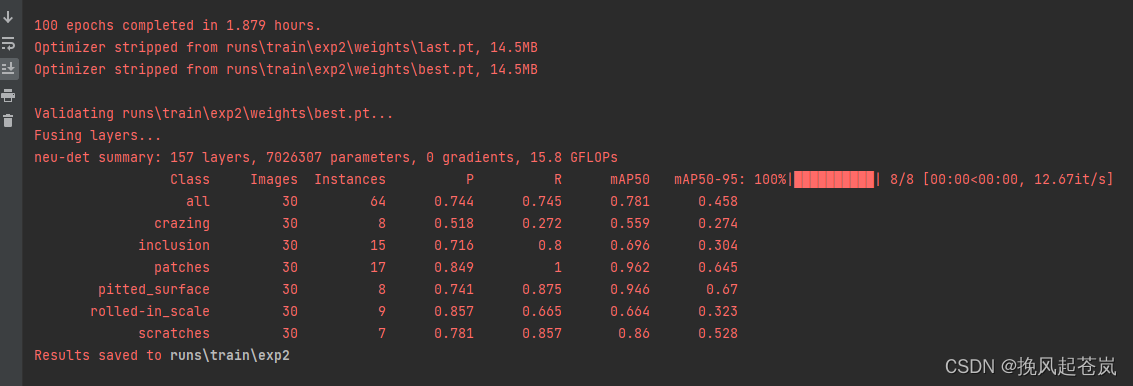
训练结束之后模型为best.pt和last.pt,存储的都是模型权重信息, best.pt为在验证集上表现最佳的模型参数文件,而last.pt为训练结束时的参数文件
对detect.py文件进行调参,用训练出来的模型对选定的图像做目标检测
预测图像一般存储位置
预测之后生成图像位置(文件夹对应模型文件训练)
参数调整后即可右键一键训练,同理也可以cmd窗口指定参数执行
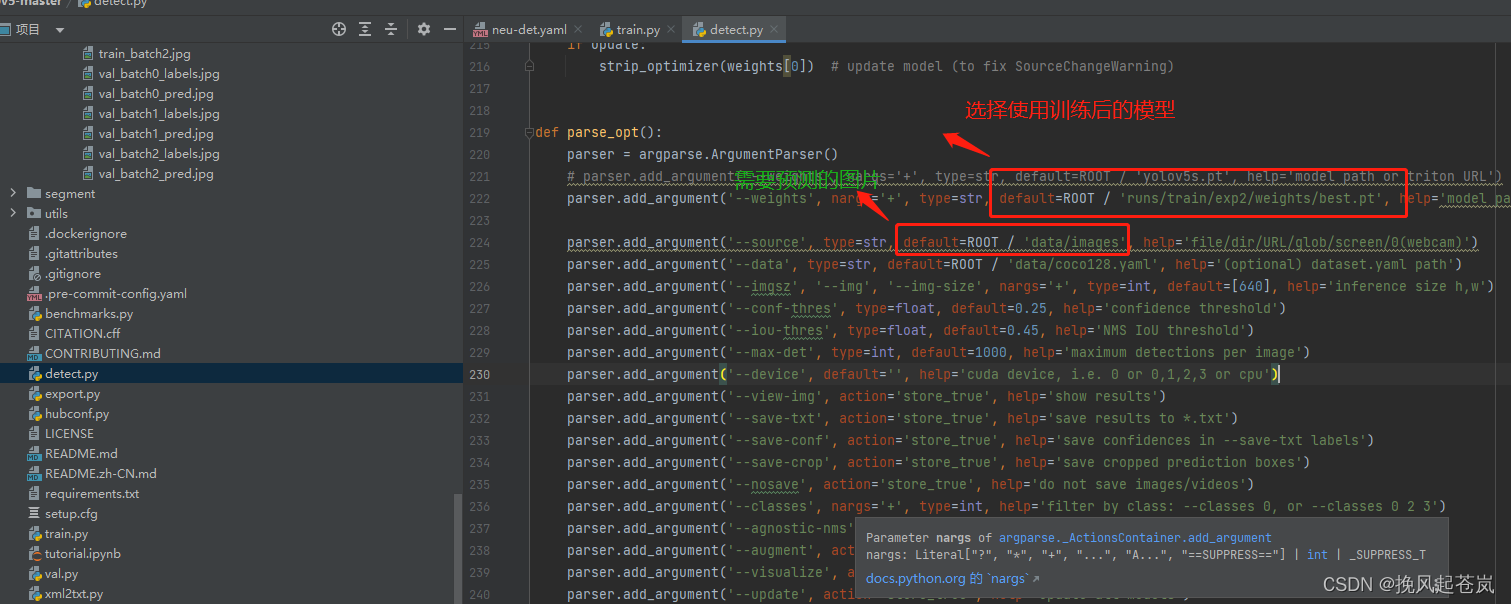
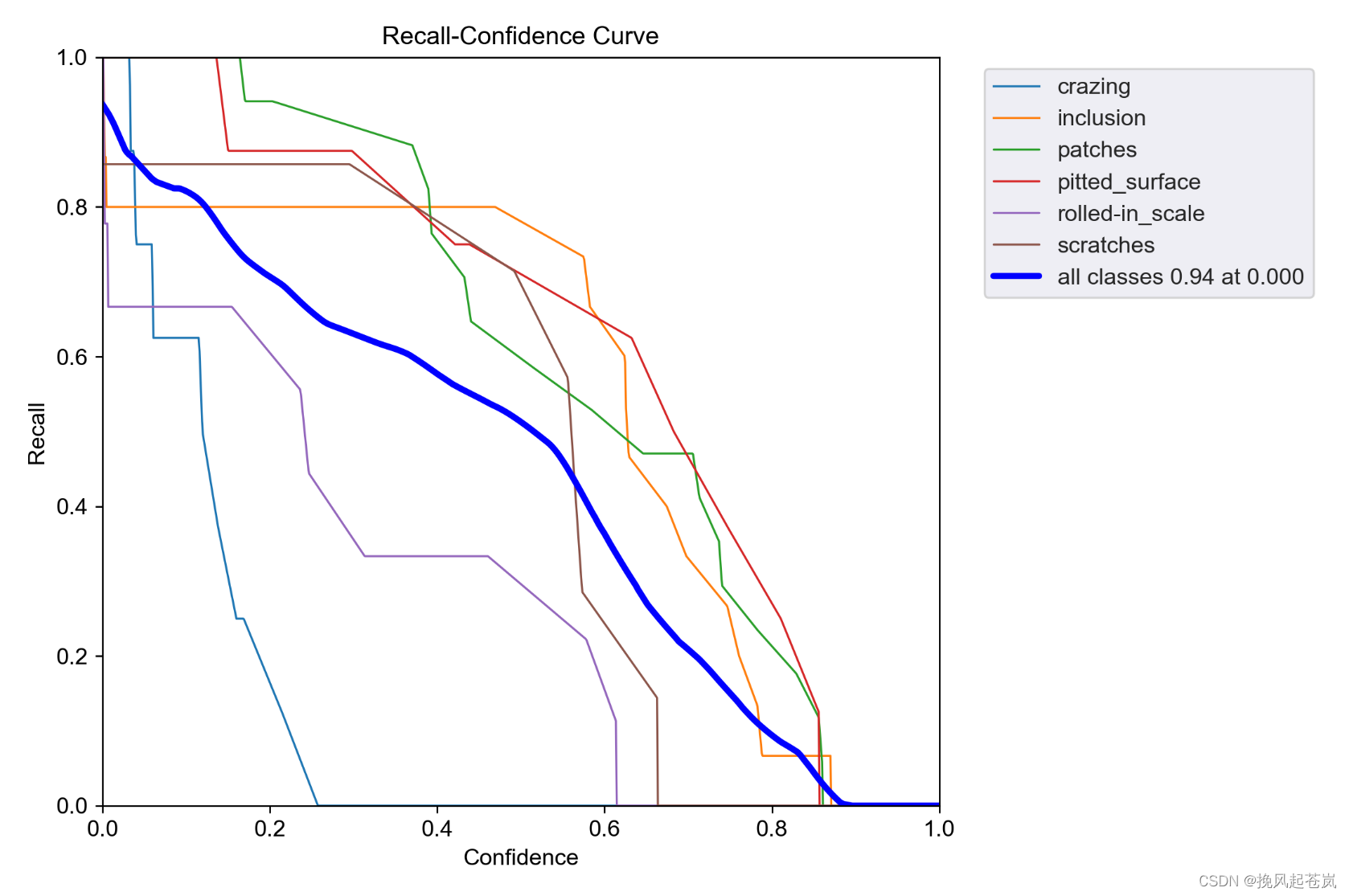
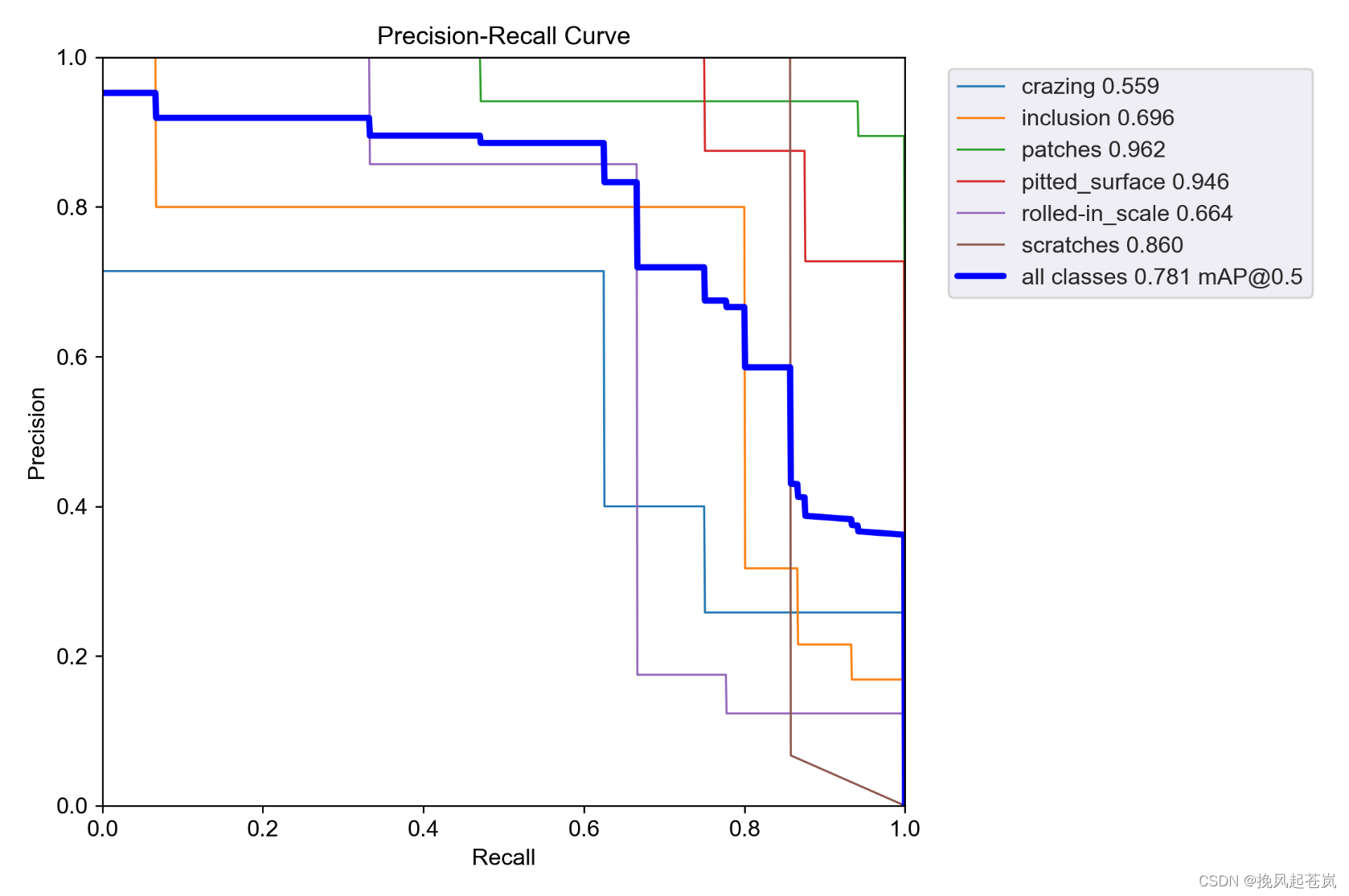
预测结果如下
训练结果
| Class | Images | Instances | Precision | Recall | mAP50 | mAP50-95 |
| all | 30 | 64 | 0.744 | 0.745 | 0.781 | 0.458 |
| crazing | 30 | 8 | 0.518 | 0.272 | 0.559 | 0.274 |
| inclusion | 30 | 15 | 0.716 | 0.8 | 0.696 | 0.304 |
| patches | 30 | 17 | 0.849 | 1 | 0.962 | 0.645 |
| pitted_surface | 30 | 8 | 0.741 | 0.875 | 0.946 | 0.67 |
| rolled-in_scale | 30 | 9 | 0.857 | 0.665 | 0.664 | 0.323 |
| scratches | 30 | 7 | 0.781 | 0.857 | 0.86 | 0.528 |
- Class:目标检测模型中所检测的目标类别名称,本例中涉及6种不同的类别(包括全部类别)
- Images:测试集中包含该目标类别的图像数量
- Instances:测试集中该目标类别的实例总数
- Precision(P):表示在所有识别结果中被正确识别出来目标数量与模型预测的目标总数量的比例。(P=TP/TP+FP)
- Recall(R):代表目标在测试集中总共出现的次数中,能够被模型正确找到的次数与目标在测试集中总共出现的次数之比。(R=TP/TP+FN)
- mAP50:平均精度指标(mean Average Precision at IoU 0.5),其中IoU是交并比,0.5是评价窗口的大小。它是用来衡量模型的整体表现好坏的重要指标。
- mAP50-95:平均精度中统计IoU区间为[0.5, 0.95]之间的分类准确率。由于该区间范围更广,因此更具备评价模型整体表现的参考意义。
评价:
模型的整体性能表现看起来不错,全部目标类别的平均准确率(Precision, P)与召回率(Recall, R)分别为0.744和0.745。此外,平均精度(mAP50)达到了0.781,表明在预测过程中可以获得良好的目标定位和分类能力。
从单个目标类别的表现来看,patches类别的准确率最高(0.849),rolled-in_scale则相对较低(0.857)。同时,可以看出crazing、inclusion和rolled-in_scale三个类别的表现相对较差,它们的mAP50值都在0.6以下。
gpt评价:
根据上述参数表格信息,可以通过对各个指标的分析和对比来进行目标检测模型的性能评估。
首先,可以发现该模型性能评价指标表现不错。全部目标类别的平均准确率(Precision, P)为0.744,召回率(Recall, R)为0.745,表示模型在测试过程中比较好地完成了目标识别和分类任务。同时,各个类别的表现差异也较为明显,其中patches类别的准确率最高(0.849),rolled-in_scale则相对较低(0.857)。
其次,mAP50是用于全面检验模型性能的重要指标之一。在本例中,模型整体的mAP50达到了0.781,在IoU=0.5时模型对待检测对象的匹配效果良好。但是mAP50-95则相对较低,只有0.458,这说明通过IoU扩大范围后,模型性能相较于窄范围较差。
基于以上结果,该模型整体表现不错,但如何优化模型并进一步提高性能则需要针对具体问题具体分析。比如,在场景复杂度高的环境下,获得更多数据示例、调节学习率等方式可能会有所帮助。同时,根据各个目标类别之间的差异性,采取“适合其材”的策略去进行模型优化也能起到一定的改进作用。
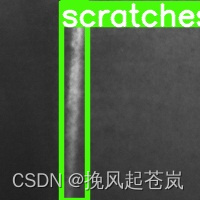
以下是使用训练后的模型生成的标注图片










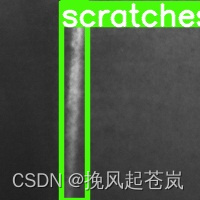





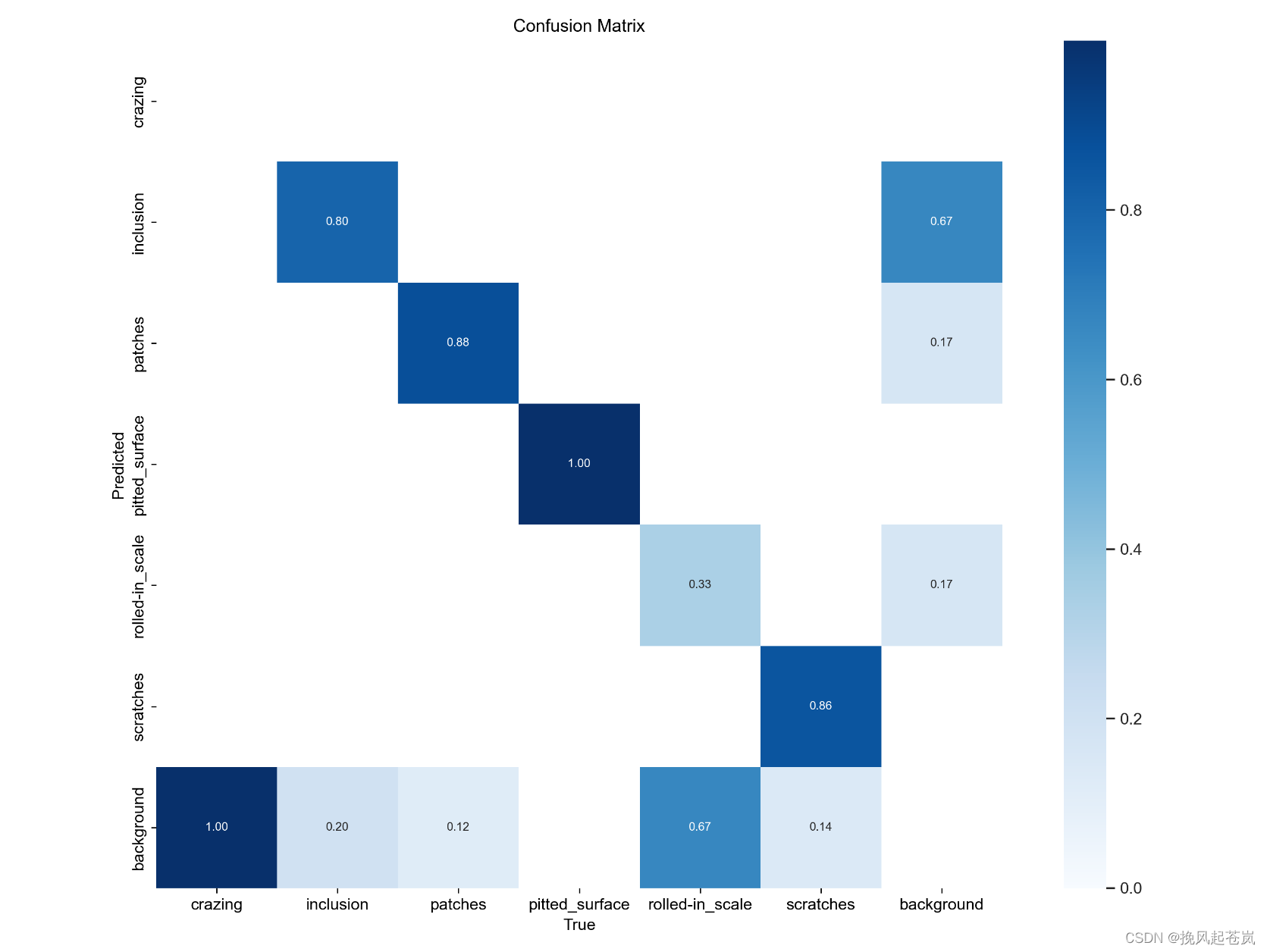
模型评估
根据表格所提供的信息,可以看出该模型在测试集上经过较好的训练。模型结构为neu-det,有157层,参数量为7026307,计算速度约为每秒15.8亿次浮点运算(GFLOPs)。
同时,针对该模型的性能指标,通过查看Precision、Recall和mAP50等参数,可以发现模型在多个指标上表现不错。整体来看,模型的Precision与Recall比较均衡,而mAP50表现达到了0.781,说明该模型具备良好的目标定位和分类能力。
虽然从各个目标类别中可以看到差异明显,但是实验结果并未说明模型存在明显的问题。究其原因,可能是因为该模型使用了先进的神经网络算法,并且训练数据质量较高。
但是需要指出的是,仅凭一个测试集的性能表现结果无法完全代表模型的真实性能,只有在更加广泛的实际应用场景下反复验证模型的鲁棒性和稳定性,才能更好地评估该模型的性能。
还有训练过程中生成的训练信息图片,图片太多,请自行阅览。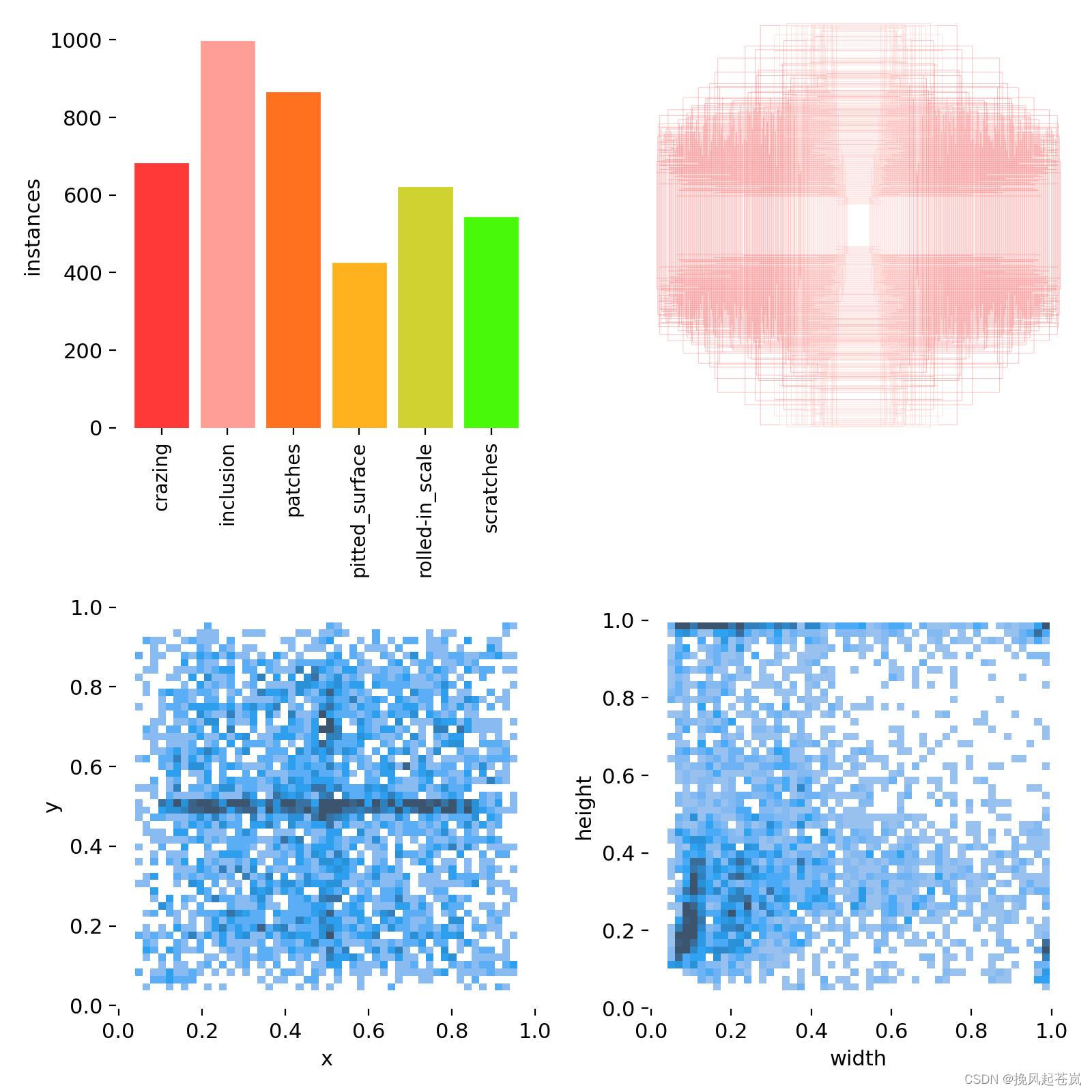











站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结