您现在的位置是:首页 >其他 >Flume系列:Flume Sink使用网站首页其他
Flume系列:Flume Sink使用
简介Flume系列:Flume Sink使用
目录
3:写入Kafka - 可以使用kafka channel代替
Apache Hadoop生态-目录汇总-持续更新
系统环境:centos7
Java环境:Java8
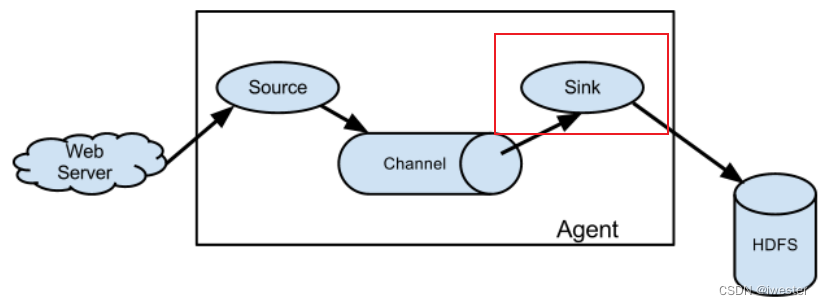
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件目的地包括 hdfs、logger(常用语测试)、avro、thrift、ipc、file、HBase、solr、自定义。
1:HDFS Sink
# 1:定义组件
kafka_flume_hdfs.sources = r1
kafka_flume_hdfs.channels = c1
kafka_flume_hdfs.sinks = k1
# 2:定义source
这里主要介绍Channel顾这里省略,到source模块查看写法
# 3:定义channel
这里主要介绍sources顾这里省略,到channel模块查看写法
# 4:定义sink
kafka_flume_hdfs.sinks.k1.type = hdfs
kafka_flume_hdfs.sinks.k1.hdfs.path = hdfs://hadoop322ha/project/v4/log/topic_log/%Y-%m-%d
# 上传文件的前缀
kafka_flume_hdfs.sinks.k1.hdfs.filePrefix = logs-
# 设置是否需要滚动生成文件,比如1小时一个, 如果设置为true需要设置对应的,roundValue,roundUnit
kafka_flume_hdfs.sinks.k1.hdfs.round = false
## 控制生成的小文件
# 控制多久滚动一次文件,防止凑不够rollSize卡住, 正常设置3600,这里测试为了快速写出
kafka_flume_hdfs.sinks.k1.hdfs.rollInterval = 20
# 控制文件多大后,滚动文件,128M滚动文件
kafka_flume_hdfs.sinks.k1.hdfs.rollSize = 134217728
# 多少个events滚动文件,一般不指定写0
kafka_flume_hdfs.sinks.k1.hdfs.rollCount = 0
## 配置输出类型CompressedStream(压缩流),DataStream(原样输出),与压缩
# 压缩流
kafka_flume_hdfs.sinks.k1.hdfs.fileType = CompressedStream
# 压缩类型
kafka_flume_hdfs.sinks.k1.hdfs.codeC = lzop
# 5:定义关联关系
kafka_flume_hdfs.sources.r1.channels = c1
kafka_flume_hdfs.sinks.k1.channel = c1sink到hdfs注意timestamp,默认是从Flume event headers里取的,如果header里没有不配useLocalTimeStamp 会直接报错
2022-12-06 11:47:33,481 ERROR hdfs.HDFSEventSink: process failed
java.lang.NullPointerException: Expected timestamp in the Flume event headers, but it was nullHDFS小文件的处理
HDFS存入大量小文件的影响:
元数据层面:每个小文件都有一份元数据,小文件过多会占用Namenode服务器大量内存,影响Namenode性能和使用寿命。
计算层面:默认情况下MR会对每个小文件启用一个Map任务计算(默认1G内存),非常影响计算性能。同时也影响磁盘寻址时间。
HDFS小文件处理:
通过调整:hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount 这三个参数,控制小文件的生成
①文件在达到128M时会滚动生成新文件
②文件创建超3600秒时会滚动生成新文件
hdfs.rollInterval=3600
hdfs.rollSize=134217728 #128M滚动文件
hdfs.rollCount =0
## 对hdfs进行压缩
a1.sinks.k1.hdfs.fileType = CompressedStream # 压缩流
a1.sinks.k1.hdfs.codeC = lzop
注意:hdfs要开启对应的压缩格式2:logger Sink
# 1:定义组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2:定义source
这里主要介绍Channel顾这里省略,到source模块查看写法
# 3:定义channel
这里主要介绍sources顾这里省略,到channel模块查看写法
# 4:定义sink
a1.sinks.k1.type = logger # 表示a1的输出目的地是控制台logger类型
# 5:定义关联关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动方式:flume-ng agent --name a1 --conf-file flume-netcat-logger.conf -Dflume.root.logger=INFO,console
3:写入Kafka - 可以使用kafka channel代替
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结