您现在的位置是:首页 >其他 >Mysql 学习(十)基于成本的优化 一网站首页其他
Mysql 学习(十)基于成本的优化 一
简介Mysql 学习(十)基于成本的优化 一
什么是成本
- 执行一个查询可以有不同的执行方案,优化器会选择一个成本比较低的方案去执行,但是现在有个疑问,MySQL的查询执行成本是哪些呢?
- 主要有两方面组成:
- I/O成本:myisam和innodb存储引擎将数据和索引存储到磁盘上,所以当我们想查询数据的时候就需要要把数据从磁盘加载到内存中操作,而这一个过程损耗的时间就是I/O成本
- CPU成本:读取以及检测记录是否满足对应的搜索条件、对结果集进行排序等这些操作损耗的时间称之为CPU成本。
- 对于Innodb存储引擎来说,页是磁盘和内存之间的交互单位,所以我们计算成本,通常是以页为单位的,并且规定读取一个页花费的成本默认是1.0,读取和检测一条记录是否符合搜索条件的成本默认是0.2
窥探单表查询的成本
- 为了更好理解,我们肯定需要一张表
CREATE TABLE index_value_table (
id INT NOT NULL AUTO_INCREMENT,
value1 VARCHAR(100),
value2 INT,
value3 VARCHAR(100),
value_part1 VARCHAR(100),
value_part2 VARCHAR(100),
value_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (value1),
UNIQUE KEY idx_key2 (value2),
KEY idx_key3 (value3),
KEY idx_key_part(value_part1, value_part2, value_part3)
) Engine=InnoDB CHARSET=utf8;
优化步骤
- 在一条语句真正执行之前,我们的mysql优化器都会先把该语句的所有执行方案找出来,然后判断出成本最低的方案,然后再继续执行,详细的过程如下:
- 根据搜索条件找出所有可能使用的索引
- 计算全表的代价
- 计算使用不同索引的代价
- 找出代价最小的方案
- 下面我们通过一条语句来讲解这些过程:
SELECT * FROM index_value_table WHERE value1 IN ('a', 'b', 'c') AND value2 > 10 AND value2 < 1000 AND value3 > value2 AND value_part1 LIKE '%hello%' AND common_field = '123';- 注意计算成本的时候,设计师都会在代码上加入一些微调的数值,这些数值的意义不知道
根据搜索条件找出所有可能的索引
- 先来看查询条件:
- value1 IN (‘a’, ‘b’, ‘c’),这个搜索条件可以使用二级索引idx_key1。
- value2 > 10 AND value2 < 1000,这个搜索条件可以使用二级索引idx_key2。
- value3 > value2,这个搜索条件的索引列由于没有和常数比较,所以并不能使用到索引。
- value_part1 LIKE ‘%hello%’,value_part1通过LIKE操作符和以通配符开头的字符串做比较,不可以适用索引。
- common_field = ‘123’,由于该列上压根儿没有索引,所以不会用到索引。
- 所以可能用到的索引:idx_key1 和 idx_key2
计算全表的代价
- 对于Innodb而言,全表扫描的意义就是把聚簇索引的记录都依次和搜索条件做一下比较,把符合搜索条件的记录加入到结果集,所以需要将聚簇索引对应的页面加载到内存中,然后再检测记录是否符合搜索条件。由于查询成本=I/O成本+CPU成本,所以计算全表扫描的代价需要两个信息:
- 聚簇索引占用的页面数
- 该表中的记录数
- 而这两个信息从哪来呢?
- 答案是底层每个表维护了一系列的统计信息,优化器可以通过这些信息知道,而我i们用户怎么看呢?
- 通过sql
SHOW TABLE STATUS LIKE 'index_value_table'获取
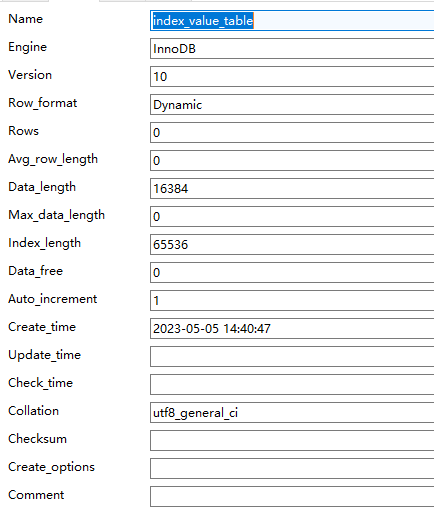
- 其中有两个字段我们是需要的:
- Rows:表示本表有多少记录
- 对于使用MyISAM存储引擎的表来说,该值是准确的
- 对于使用InnoDB存储引擎的表来说,该值是一个估计值
- Data_length:表示本表占用多少存储空间字节数
- Data_length = 聚簇索引的页面数量 x 每个页面的大小
- Rows:表示本表有多少记录
- 拿到这两个值以后我们就可以计算了,假设我们这两个值分别是 Rows = 9693 和 Data_length = 1589248
- 计算一下 I/0 成本:
- 聚簇索引的页数:
1589248 / 16 / 1024 = 97 - 成本 :
97 x 1.0 + 1.1(微调数值 = 98.1
- 聚簇索引的页数:
- 计算一下CPU 成本:
- 成本:
9693 x 0.2 + 1.0 = 1939.6
- 成本:
- 总的成本:
1939.6 + 98.1 = 2037.7 - 所以得出全表扫描的成本是 2037.7
计算使用不同索引的代价
计算 idx_key1 的代价
- idx_key1 对应的搜索条件是
value1 in ('a','b','c'),明显是是3个单点区间,所以需要访问3次,找出对应范围的二级索引记录,大概是118条,然后进行回表 - I/O 成本:
- 搜索二级索引 I/0成本:
3 x 1.0 = .3.0- 不论某个范围区间的二级索引到底占用了多少页面,查询优化器粗暴的认为读取索引的一个范围区间的I/O成本和读取一个页面是相同的。
- 回表成本:
118 x 1.0 = 118.0 - 总成本:
3.0 + 118.0 = 121.0
- 搜索二级索引 I/0成本:
- CPU 成本
- 搜索二级索引成本:
118 x 0.2 + 0.01 = 23.61 - 回表成本:
118 x 0.2 = 23.6 - 总成本:
23.61 + 23.6 = 47.21
- 搜索二级索引成本:
- 总成本:
47.21 + 121.0 = 168.21
计算 idx_key2 的代价
- idx_key2 是唯一二级索引,所以通过搜索条件
value2 > 10 AND value2 < 1000,找出对应范围的二级索引记录,大概是95条,然后进行回表 - I/O 成本:
- 搜索二级索引 I/0成本:
1 x 1.0 = .1.0- 不论某个范围区间的二级索引到底占用了多少页面,查询优化器粗暴的认为读取索引的一个范围区间的I/O成本和读取一个页面是相同的。
- 回表成本:
95 x 1.0 = 95.0 - 总成本:
1.0 + 95.0 = 96.0
- 搜索二级索引 I/0成本:
- CPU 成本
- 搜索二级索引成本:
95 x 0.2 + 0.01 = 19.01 - 回表成本:
95 x 0.2 = 19.0 - 总成本:
19.01 + 19 = 38.01
- 搜索二级索引成本:
- 总成本:
38.01 + 96.0 = 134.01
找出代价最小的方案
- 通过上面的计算代价,找出成本最低的那个:
- 全表扫描的成本:2037.7
- 使用idx_key2的成本:134.01
- 使用idx_key1的成本:168.21
- 由于 idx_key2 成本最低,所以我们就会选择 idx_key2 来执行查询方案
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结