您现在的位置是:首页 >其他 >MySQL与Hadoop数据同步方案:Sqoop与Flume的应用探究【上进小菜猪大数据系列】网站首页其他
MySQL与Hadoop数据同步方案:Sqoop与Flume的应用探究【上进小菜猪大数据系列】
??我是上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货,欢迎关注。
MySQL与Hadoop数据同步
随着大数据技术的发展,越来越多的企业开始采用分布式系统和云计算技术来处理和存储海量数据。Hadoop是一种开源的分布式系统,可用于存储和处理大规模数据集。MySQL则是最受欢迎的关系型数据库之一,它被广泛应用于企业级应用中。
在实际的业务场景中,经常需要将MySQL中的数据导入到Hadoop中进行分析和处理。为了实现这一目的,我们可以使用多种方法来同步MySQL和Hadoop之间的数据。本文将介绍如何使用Sqoop和Flume这两个工具实现MySQL与Hadoop数据同步的方案。
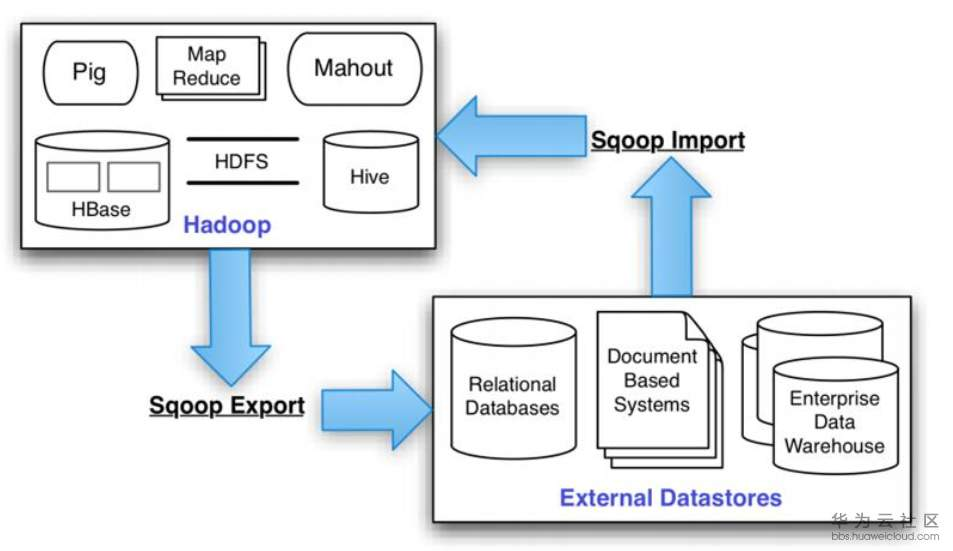
一、Sqoop实现MySQL与Hadoop数据同步
Sqoop是一个用于在Hadoop和关系型数据库之间传输数据的开源工具。它提供了一个简单的命令行接口,可以轻松地将关系型数据库中的数据导入到Hadoop中,也可以将Hadoop中的数据导出到关系型数据库中。Sqoop支持多种关系型数据库,包括MySQL、Oracle、PostgreSQL等。
以下是使用Sqoop将MySQL中的数据导入到Hadoop中的步骤:
- 安装Sqoop 在使用Sqoop之前,需要先安装它。可以从Sqoop的官方网站下载最新版本的二进制文件,并将其解压到本地目录中。解压后,需要配置Sqoop的环境变量,使其能够在命令行中运行。
- 创建MySQL数据表 在MySQL数据库中创建一个数据表,并插入一些数据。以下是一个示例数据表:
CREATE TABLE `employees` (
`id` int(11) NOT NULL,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL,
`salary` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
3.导入数据到Hadoop 使用Sqoop将MySQL中的数据导入到Hadoop中。以下是一个导入命令的示例:
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password password --table employees --target-dir /user/hadoop/employees
上述命令中,–connect选项指定了MySQL数据库的连接字符串,–username和–password选项指定了MySQL数据库的用户名和密码,–table选项指定了要导入的数据表,–target-dir选项指定了导入的目标目录。执行上述命令后,Sqoop会自动创建一个与MySQL数据表对应的Hadoop数据表,并将MySQL中的数据导入到该Hadoop数据表中。
二、Flume实现MySQL与Hadoop数据同步
Flume是一个可靠的、分布式的、可扩展的系统,用于收集、聚合和移动大规模数据。它
可以将Flume与MySQL结合使用,实现将MySQL中的数据实时地导入到Hadoop中。
以下是使用Flume将MySQL中的数据导入到Hadoop中的步骤:
- 安装Flume 在使用Flume之前,需要先安装它。可以从Flume的官方网站下载最新版本的二进制文件,并将其解压到本地目录中。解压后,需要配置Flume的环境变量,使其能够在命令行中运行。
- 创建Flume配置文件 在Flume中,使用配置文件来定义数据流的来源、目的地和传输方式。以下是一个Flume配置文件的示例:
#定义数据源为MySQL
agent.sources = mysql-source
agent.sources.mysql-source.type = org.apache.flume.source.jdbc.JdbcSource
agent.sources.mysql-source.jdbc.driver = com.mysql.jdbc.Driver
agent.sources.mysql-source.jdbc.url = jdbc:mysql://localhost:3306/test
agent.sources.mysql-source.jdbc.user = root
agent.sources.mysql-source.jdbc.password = password
agent.sources.mysql-source.jdbc.sql = select * from employees
#定义数据目的地为Hadoop
agent.sinks = hadoop-sink
agent.sinks.hadoop-sink.type = hdfs
agent.sinks.hadoop-sink.hdfs.path = /user/hadoop/employees
agent.sinks.hadoop-sink.hdfs.fileType = DataStream
#定义数据传输方式为内存
agent.channels = memory-channel
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 1000
agent.channels.memory-channel.transactionCapacity = 100
#将数据源和数据目的地连接起来
agent.sources.mysql-source.channels = memory-channel
agent.sinks.hadoop-sink.channel = memory-channel
上述配置文件中,定义了一个数据源为MySQL,使用JdbcSource来读取MySQL中的数据,并将数据传输到内存中的一个Channel中。然后定义了一个数据目的地为Hadoop,使用HdfsSink将数据从Channel中传输到Hadoop中的一个目录中。最后将数据源和数据目的地连接起来。
4.启动Flume 在命令行中使用以下命令启动Flume:
flume-ng agent --conf-file /path/to/flume.conf --name agent
上述命令中,–conf-file选项指定了Flume的配置文件路径,–name选项指定了Flume的名称。执行上述命令后,Flume会开始读取MySQL中的数据,并将其实时地导入到Hadoop中。
代码实例
以下是一个使用Sqoop将MySQL中的数据导入到Hadoop中的Java代码示例:
import org.apache.sqoop.Sqoop;
import org.apache.sqoop.tool.ExportTool;
public class MySQLToHadoop {
public static void main(String[] args) {
String[] sqoopArgs = new String[]{
"--connect", "jdbc:mysql://localhost/test",
"--username", "root",
"--password", "password",
"--table", "employees",
"--target-dir", "/user/hadoop/employees",
"--fields-terminated-by", ","
};
Sqoop.runTool(sqoopArgs, new ExportTool());
}
}
上述代码中,使用Sqoop将MySQL中的employees表导入到Hadoop中的/user/hadoop/employees目录中。其中–connect选项指定了MySQL的连接字符串,–username和–password选项指定了MySQL的用户名和密码,–table选项指定了要导入的表名,–target-dir选项指定了导入到Hadoop中的目录,–fields-terminated-by选项指定了字段之间的分隔符。
以下是一个使用Flume将MySQL中的数据导入到Hadoop中的Java代码示例:
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.api.RpcClientConfigurationConstants;
import org.apache.flume.event.EventBuilder;
import org.apache.flume.event.EventBuilder;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import java.util.Properties;
public class MySQLToHadoop {
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty(RpcClientConfigurationConstants.CONFIG_CLIENT_TYPE, "THRIFT");
props.setProperty(RpcClientConfigurationConstants.CONFIG_HOSTS, "hadoop01:41414");
RpcClient client = RpcClientFactory.getInstance(props);
String sql = "select * from employees";
Connection con = DriverManager.getConnection("jdbc:mysql://localhost/test", "root", "password");
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) {
String name = rs.getString("name");
String age = rs.getString("age");
Event event = EventBuilder.with
上述代码中,使用Flume将MySQL中的employees表导入到Hadoop中。其中配置了Flume客户端的主机和端口,使用JDBC连接MySQL数据库并读取employees表中的数据。然后将数据封装成Flume的Event对象,并通过RpcClient将数据传输到Hadoop中。
总结
本文介绍了如何使用Sqoop和Flume这两个工具实现MySQL与Hadoop数据同步的方案。Sqoop可以将MySQL中的数据批量地导入到Hadoop中,适用于需要定期导入数据的场景。而Flume可以实时地将MySQL中的数据导入到Hadoop中,适用于需要实时处理数据的场景。这两种方案各有优劣,需要根据具体的业务需求来选择合适的方案。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结