您现在的位置是:首页 >学无止境 >视频文本检索之CLIP4Clip网站首页学无止境
视频文本检索之CLIP4Clip
论文:CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
GitHub:https://github.com/ArrowLuo/CLIP4Clip
论文基于图片-文本检索模型CLIP (Contrastive Language-Image Pretraining)提出了视频-文本检索模型CLIP4Clip (CLIP For video Clip retrieval)。在MSR-VTT, MSVC, LSMDC, ActivityNet, DiDeMo等多个数据集上都取得了SOTA的结果。
训练视频-文本检索任务通常有2种方法,一种直接基于视频像素特征进行训练(raw video pixel-level),另一种基于视频特征进行训练 (video feature feature-level)。
基于pixel-level的方法优点可以直接学习视频特征和文本特征,是一种端到端的训练方法,有助于提取底层特征,缺点训练视频特征是耗时费力的。比如ClipBERT提出了一种视频帧的稀疏采样策略,Frozen方法直接将一张图片当作一个视频进行训练,并提出了一种课程学习策略(curriculum learning schedule),来提高训练效率。
基于feature-level的方法优点训练较快,缺点高度依赖特征提取模型的预训练权重,会有domain问题产生。
(1)图片特征对于视频-文本检索是否足够?
单个的图片特征对于视频文本检索中的视频编码是远远不够的。
(2)基于大规模视频-文本数据集对clip模型进行后预训练会影响模型表现吗?
在大规模视频-文本数据集上对CLIP4Clip模型进行后训练是必须的,并且看可以提高模型性能,尤其是在0样本迁移学习中,精度上会有比较大的突破。
(3)有什么方法可以让模型学习视频帧之间的时序依赖?
论文提出了3种方法分别为,无参型(Parameter-free type),顺序型(Sequential type),紧凑型(Tight type),来学习视频帧之间的时许依赖。
(4)在视频-文本检索任务上,模型的超参数设置是否敏感?
论文认真进行了不同超参数设置的实验,汇报了最好的超参数设置。
网络结构:

给定一组视频(或视频片段)V和一组本文T,模型的目标是学习函数s(vi,tj)来计算视频(或视频片段)vi∈V与本文tj∈T之间的相似度。视频采样策略采用1秒采1帧。根据文本到视频检索中的相似性得分对给定查询本文的所有视频(或视频片段)进行排序,或者在视频到文本检索任务中对给定查询视频(或视频片段)的所有文本进行排序。s(vi,tj)的目标是计算相关视频文本对的高相似度分数和不相关视频文本对的低相似度分数。
本文的模型是一种端到端方式(E2E),通过将帧作为输入直接对像素进行训练。上图展示了本文的框架,它主要包含一个文本编码器 、一个视频编码器 和一个相似性计算模块 。
视频编码器:
视频编码模型类似clip采用ViT-B/32,网络深度为12层,包含32个patch。
虽然CLIP对于学习图像的视觉概念是有效的,但从视频中学习时间特征是必不可少的。为了进一步将CLIP的知识迁移为视频,作者用CLIP4Clip模型在Howto100M数据集上进行了后预训练。
通过将视频帧进行分patch,并结合位置attention输入ViT模型中,进行线性投影,得到代表视频的embedding向量。

这里将输入视频序列定义为V,视频生成的embedding定义为Z,文本的embedding定义为W。
这里线性投影的方法有2种,分别为2D线性投影和3D线性投影。

2D线性投影忽略了视频帧之间的时序关系,因此采用3D线性投影。两者主要的区别在于卷积核的选择上。2D线性投影卷积核的维度为[h× w],2D线性投影卷积核的维度为[t × h × w]。其中t表示时序,h表示高度,w表示宽度。

虽然理论上来说3D线性投影会优于2D线性投影。但是作者通过实验发现,反而2D线性投影效果更好。
通过分析发现预训练模型clip是基于2D线性投影训练的,却作为3D线性投影的初始化参数,这导致模型没有学习视频帧间的时序特征。这也是后续作者计划在大规模视频-文本数据集上训练clip模型的原因。
文本编码器:
文本编码器模型直接采用CLIP模型的Transformer网络。模型为12层,宽度为512,包含8个注意力头。将Transformer最后一层在[EOS]的输出作为文本的输出特征。
特征相似性度量:
论文提出了3种度量方法,分别为无参型(Parameter-free type),顺序型(Sequential type),紧凑型(Tight type)
将视频的特征定义为Z,文本的特征定义为W。
无参型(Parameter-free type):

先对视频的特征进行平均池化,然后将池化后的视频特征和文本特征计算cos距离。
顺序型(Sequential type):

直接对视频特征进行平均池化,这样的操作忽略了视频帧之间的序列关系。因此先对视频特征基于LSTM/Transformer编码,然后对编码后的特征进行平均池化操作,最后按照同样的方法计算cos距离。
紧凑型(Tight type):

将文本特征W和视频特征Z拼接起来,得到拼接后的特征U,并将U和位置编码P,类型编码T进行拼接,输入Transformer进行编码,然后使用2个全连接层做特征投影,得到最终的输出。
损失函数:

假设一个batch里面包含B 个(video, text)对。那么将会产生B*B种组合关系。这里损失函数采用对称交叉熵损失函数。损失函数就是优化使得video和text相对应的pair对loss变小,video和text不对应的pair对loss变大。
Lv2t会将batch内的每个视频计算与所有文本的交叉熵。
Lt2v会将batch内的每个文本计算与所有视频的交叉熵。
最终的损失函数L就是Lv2和Lt2v的和。
实验结果:
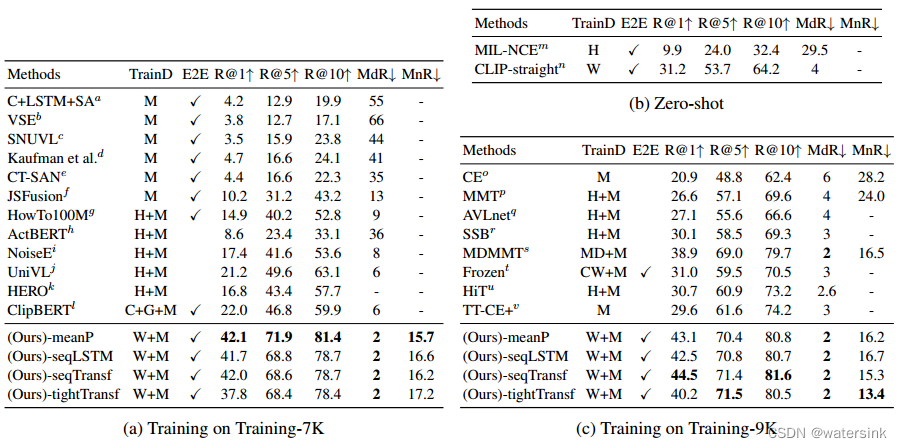
CLIP4Clip方法显著优于其他方法。
结论:
1)图像特征也能促进视频文本检索;
2)在CLIP上进行post-pretrain,可以进一步提高视频文本检索的性能;
3)3D patch线性投影和序列型相似度是检索任务中很有前途的方法;
4)用于视频文本检索的CLIP具有学习率敏感性。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结