您现在的位置是:首页 >学无止境 >【标准化方法】(4) Weight Normalization 原理解析、代码复现,附Pytorch代码网站首页学无止境
【标准化方法】(4) Weight Normalization 原理解析、代码复现,附Pytorch代码
今天和各位分享一下深度学习中常用的归一化方法,权重归一化(Weight Normalization, WN),通过理论解析,用 Pytorch 复现一下代码。
Weight Normalization 的论文地址如下:https://arxiv.org/pdf/1903.10520.pdf
1. 原理解析
权重归一化(Weight Normalization,WN)选择对神经网络的权值向量 W 进行参数重写,参数化权重改善条件最优问题来加速收敛,灵感来自批归一化算法,但是并不像批归一化算法一样依赖于批次大小,不会对梯度增加噪声且计算量很小。权重归一化成功用于 LSTM 和对噪声敏感的模型,如强化学习和生成模型。
对深度学习网络权值 W 进行归一化的操作公式如下:
通过一个 k 维标量 g 和一个向量 V 对权重向量 W 进行解耦合。标量 ,即权重 W 的大小,
表示 v 的欧几里得范数(二范数)。
作者提出对参数 v,g 直接重新参数化然后执行新的随机梯度下降,并且认为通过将权重向量(g)的范数与的方向解耦,加速了随机梯度下降的收敛。
假设代价函数记为 L,此时的深度学习网络权值的梯度计算公式为:
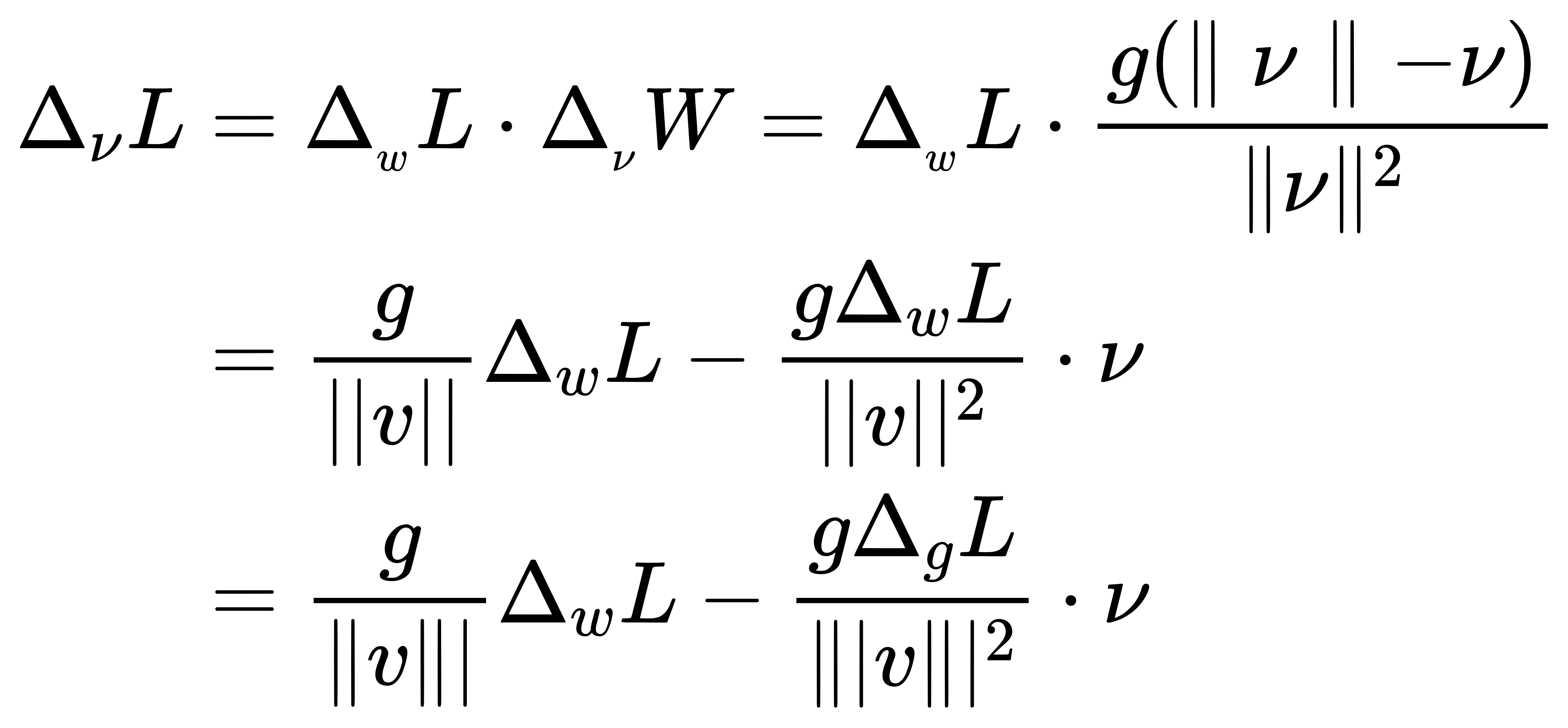
设 ,其中
是投影矩阵。梯度计算可以写成:
。
设 ,当梯度噪声大时,c 变大,有
,则
变小。
当梯度较小时,c 变小趋于0,有 。即:权重归一化 WN 使用这种机制做到梯度稳定。另外,作者也发现 ||v|| 对学习率有很强的鲁棒性。
WN 不像 BN 还具有固定神经网络各层产生的特征尺度的好处,WN 需要小心的参数初始化。给 v 的范数设定一个范围(正态分布均值为零,标准差为 0.05),这样虽然延长了参数更新的时间,但收敛后的测试性能会比较好。
设 ,仅在初始化期间取
可以得到应用 WN 后,
由上式可得,当 WN 进行参数初始化时可以在一开始达到和 BN 相同的作用。
2. 代码演示
这里以《Micro-Batch Training with Batch-Channel Normalization and Weight Standardization》这篇文章中的权重归一化方法为例,展示一下代码,比较简单,只需要对权重文件的每个通道做归一化处理。示意图如下。

import torch
def WS(weight:torch.Tensor, eps:float):
# 权重shape=[c_out, c_in, k_h, k_w]
c_out, c_in, *kernel_shape = weight.shape
# [c_out, c_in, k_h, k_w]-->[c_out, c_in*k_h*k_w]
weight = weight.view(c_out, -1)
# 计算 [c_in*k_h*k_w] 维度上的均值和方差 --> [c_out,1]
var, mean = torch.var_mean(weight, dim=1, keepdim=True)
# 权重标准化
weight = (weight-mean) / torch.sqrt(var+eps)
# [c_out, c_in*k_h*k_w]-->[c_out, c_in, k_h, k_w]
return weight.view(c_out, c_in, *kernel_shape)






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结