您现在的位置是:首页 >技术交流 >python电影评论网站首页技术交流
python电影评论
1电影评论首先得对网页进行访问,然后才能查看相关评论,因此,我们得先下载用于访问网页的requests库。因为这些库都是放在国外的,所以我们使用国内的镜像源提高下载速度,这里用的是清华的镜像。然后管理员模式打开命令行输入
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
2接着便是要下载lxml库,lxml中的etree可以帮助我们将获取的网页内容整理成一个节点树,方便我们使用Xpath找到评论,评分等内容所在的节点。
下载方式也是同样的,将requests替换成etree即可。
3要访问一个网页,必不可少的是网址,但同时也需要header,什么是header?header是发送请求时携带的头部信息,里面包含一些相应的参数告诉网站一些客户端的相关信息,我们这里提供header是为了使python更像人为的,而非机器,从而尽量避免网站的反爬措施。
如何获取header?
获取方式为要的打开要获取的网页,F12 选择网络(为空的话重载网页),选择全部,选择第一个文件的header部分,拉至底下可看见header的User-Agent内容。

4所以访问前的准备就全部做好,使用rquetsts的get函数进行访问,编写成代码如下
import requests
from lxml import etree
url = "https://movie.douban.com/subject/33420285/comments?status=P"
headers = {
'Referer': 'https://movie.douban.com/subject/33420285/comments?status=P',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
request = requests.get(url,headers=headers)
print(request.status_code)
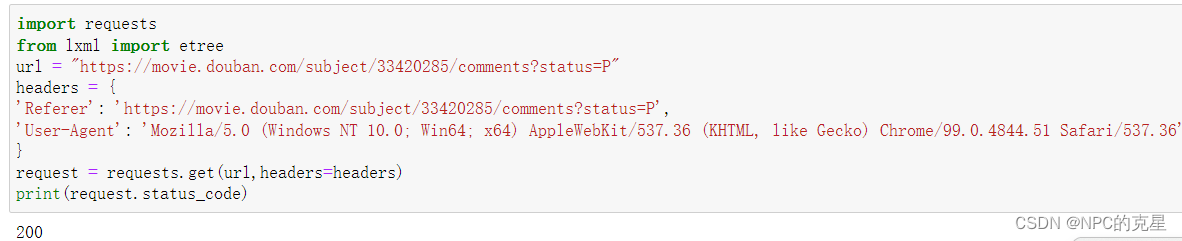 可以看到状态码为200,即为访问成功
可以看到状态码为200,即为访问成功
5在获取网页内容之前,我们先看些html的代码编码格式
 可以看到为utf-8,所以获取内容时设置的编码方式时也要相同
可以看到为utf-8,所以获取内容时设置的编码方式时也要相同
html = request.content.decode('utf-8')
print(html)
获取内容如下
6接下来便是将获取到的内容整理成一个节点树,并通过Xpath获取其中的评论节点的文本。这里我们要获取评论人的昵称,评论内容,评论分数。
首先鼠标悬浮于评论人名右键检查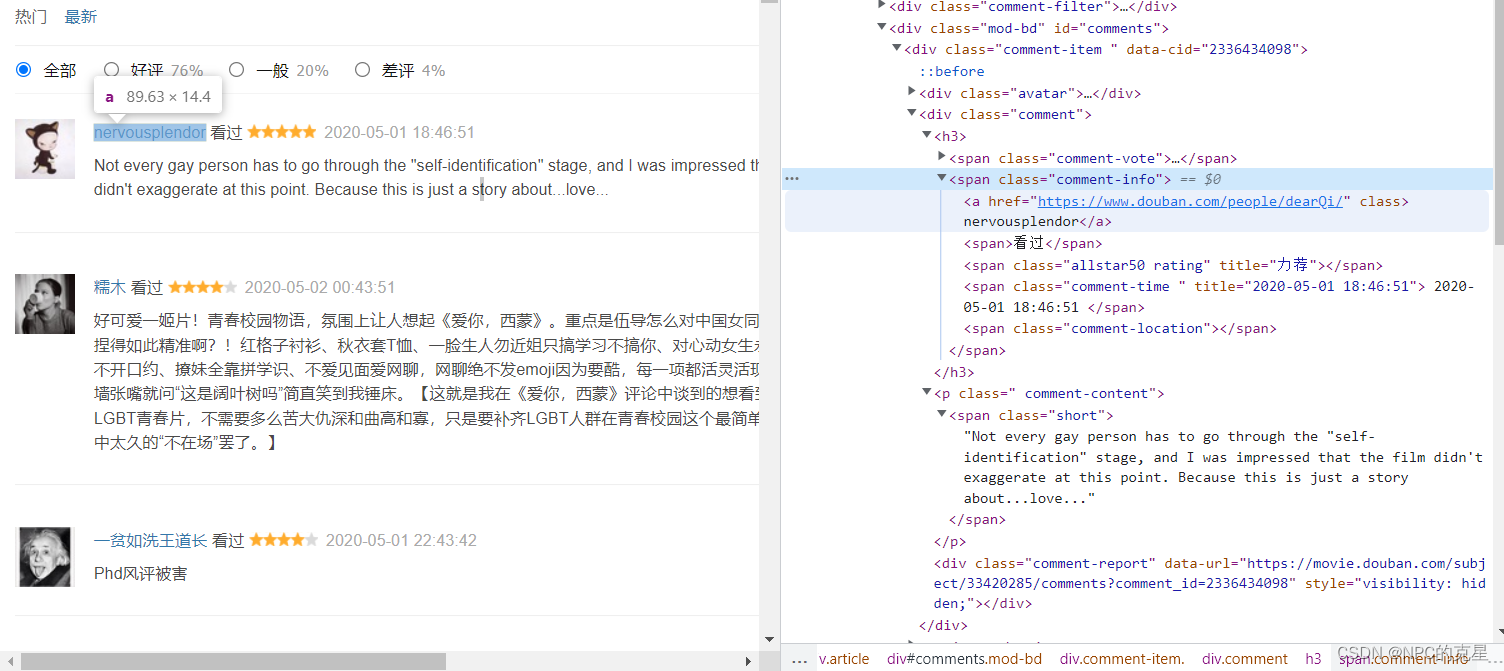 可以看到这里的昵称是标签a里面的文本,而标签a是包括在上一级的class属性名为comment-info的sapn标签中,而这一标签又是包含在id为comments的dive中的。所以他的Xpath路径可以这样写
可以看到这里的昵称是标签a里面的文本,而标签a是包括在上一级的class属性名为comment-info的sapn标签中,而这一标签又是包含在id为comments的dive中的。所以他的Xpath路径可以这样写
//*[@id="comments"]//span[@class="comment-info"]/a/text()
表示的从任意节点开始的id为comments的子孙节点span的class值为comment-info的a标签中的文本
所以这一段的代码为:
tree = etree.HTML(html)
name = tree.xpath('//*[@id="comments"]//span[@class="comment-info"]/a/text()')
print(name)
print(len(name))

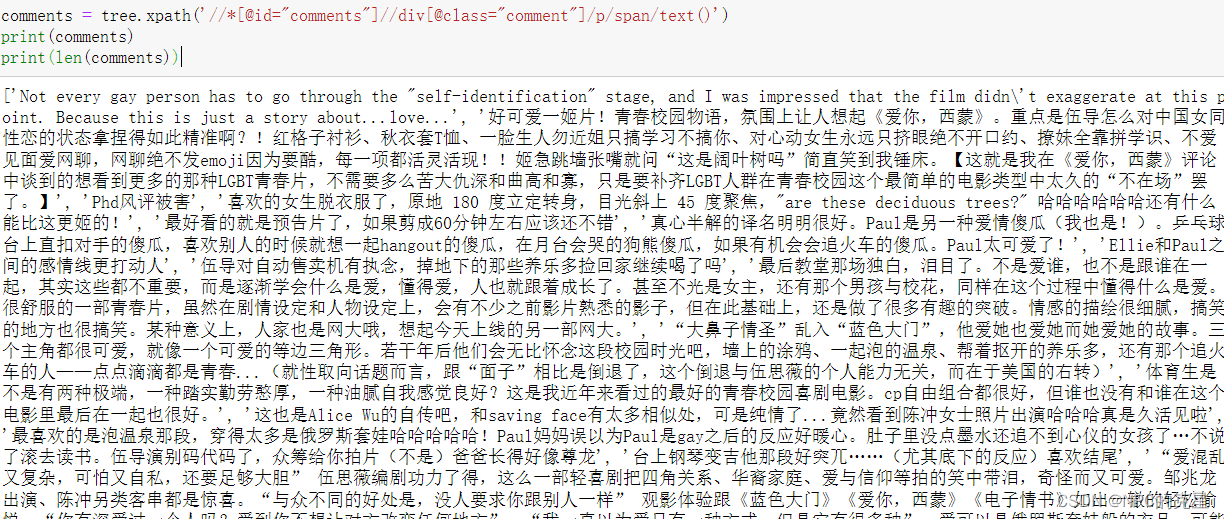
7接下来便是同样的操作,观察评论的所在位置,获取写出Xpaht的表达式为
//*[@id="comments"]//div[@class="comment"]/p/span/text()
代码如下
comments = tree.xpath('//*[@id="comments"]//div[@class="comment"]/p/span/text()')
print(comments)
print(len(comments))
 8接下来便是获取评分的星的数量
8接下来便是获取评分的星的数量
同样的Xpath表示为:
//*[@id="comments"]//div[@class="comment"]//span[2]/span[2]/@class
代码如下:
star_text = tree.xpath('//*[@id="comments"]//div[@class="comment"]//span[2]/span[2]/@class')
print(len(star_text))
print(star_text)
 由于这里获取到的星数文本包含了其他字符,而且是实际给予星树的十倍,所以这里对该列表进行操作。
由于这里获取到的星数文本包含了其他字符,而且是实际给予星树的十倍,所以这里对该列表进行操作。
我们首先想到通过re表达式提取其中的数字,并转换为整型进行除10操作,然后保存至一个新的列表中。
但是此时的这里是一个列表,re只适用字符串,因此,我们需要使用join方法来使得此列表变成一个字符串,并以空格隔开。
同时,在代码的首位我们也要导入re这个库

代码如下:
mid = " ".join(star_text)
star_num = re.findall(r'd+',mid)
star_num1 = list()
for i in star_num:
star_num1.append(int(i)/10)
print(star_num)
print(star_num1)
print(len(star_num1))
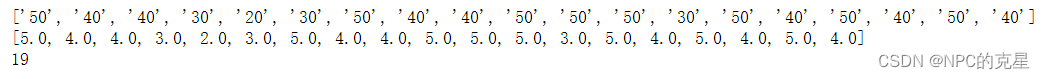
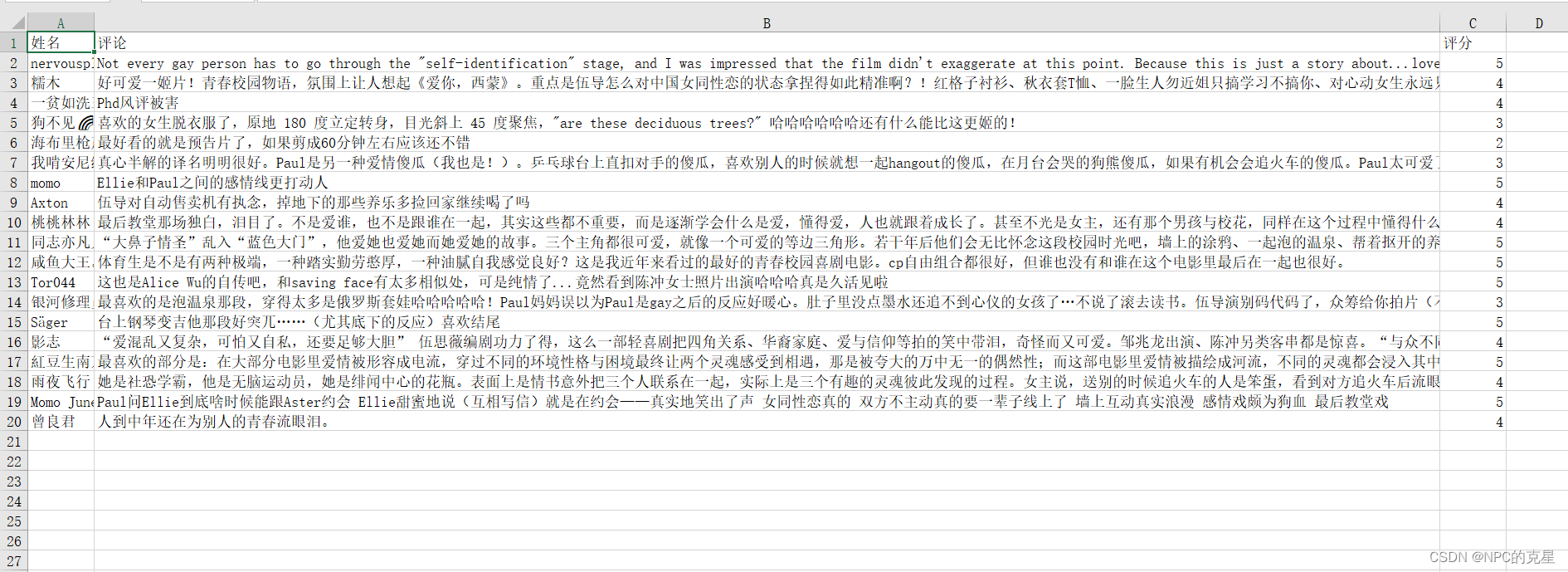
9这样的话,name中包含了评论的人名,comments包含了评论内容,star_num中包含了观众给的星树。我们导入openpyxl中的Workbook
 来对excel文件进行操作,以便将数据写入excel中。
来对excel文件进行操作,以便将数据写入excel中。
代码如下:
wb = Workbook()
sheet = wb.active
sheet.title = "comments_doubian_真心半解"
sheet["A%d" % 1].value = "姓名"
sheet["B%d" % 1].value = "评论"
sheet["C%d" % 1].value = "评分"
for i in range(len(star_num1)):
sheet["A%d" % (i+2)].value = name[i]
sheet["B%d" % (i+2)].value = comments[i]
sheet["C%d" % (i+2)].value = star_num1[i]
print(i)
wb.save("D:\tem\001\comments2.xlsx")
这样,我们就完成了对一页网站的爬取。
获取接下来的几个页面,只需观察网址差异,使用for循环访问,并将昵称,评论,星树这些保存下路即可。
我也是参考了这篇文章,写得很好,点击前往
但是不考虑comments = comments +Xpath路径这种方式,你之前有运行,内存保存有初始的comments的值时不会出错,但当你重新开机,或者在其他机子上运行时,会由于找不到comments的值就会报错。
因此,我改进了下改为:comments += Xpath这种方式
comments += tree.xpath('//*[@id="comments"]//div[@class="comment"]/p/span/text()')
全文最后总代码即为:
import requests
from lxml import etree
import re
from openpyxl import Workbook
url = "https://movie.douban.com/subject/33420285/comments?status=P"
headers = {
'Referer': 'https://movie.douban.com/subject/33420285/comments?status=P',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
for i in range(0,100,20):
url = f'https://movie.douban.com/subject/33420285/comments?start={i}&limit=20&sort=new_score&status=P'
request = requests.get(url,headers=headers)
print(request.status_code)
html = request.content.decode('utf-8')
print(html)
tree = etree.HTML(html)
name += tree.xpath('//*[@id="comments"]//div[@class="avatar"]/a/@title')
print(name)
print(len(name))
comments += tree.xpath('//*[@id="comments"]//div[@class="comment"]/p/span/text()')
print(comments)
print(len(comments))
star_text += tree.xpath('//*[@id="comments"]//div[@class="comment"]//span[2]/span[2]/@class')
print(len(star_text))
star='//*[@id="comments"]/div[2]/div[2]/h3/span[2]/span[2]'
print(star_text)
mid = " ".join(star_text)
star_num = re.findall(r'd+',mid)
star_num1 = list()
for i in star_num:
star_num1.append(int(i)/10)
print(star_num)
print(star_num1)
print(len(star_num1))
wb = Workbook()
sheet = wb.active
sheet.title = "comments_doubian_真心半解"
sheet["A%d" % 1].value = "姓名"
sheet["B%d" % 1].value = "评论"
sheet["C%d" % 1].value = "评分"
for i in range(len(star_num1)):
sheet["A%d" % (i+2)].value = name[i]
sheet["B%d" % (i+2)].value = comments[i]
sheet["C%d" % (i+2)].value = star_num1[i]
print(i)
wb.save("D:\tem\001\comments5.xlsx")

总结:熟练使用re以及Xpath将会大大助益于相关内容的爬取。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结