您现在的位置是:首页 >技术交流 >论文导读 | 大语言模型上的精调策略网站首页技术交流
论文导读 | 大语言模型上的精调策略
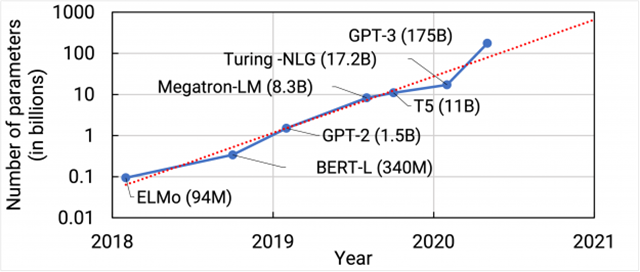
随着预训练语言模型规模的快速增长,在下游任务上精调模型的成本也随之快速增加。这种成本主要体现在两方面上:一,计算开销。以大语言模型作为基座,精调的显存占用和时间成本都成倍增加。随着模型规模扩大到10B以上,几乎不可能在消费级显卡或者单卡上进行训练;二,存储开销。如果对于每一个下游任务,我们都需要精调全量模型并存储相应的参数,那么所需要的存储开销也是相当惊人的。以GPT-3 175B为例,为仅仅一个任务存储精调模型的全量参数就需要350/700GB(取决于精度)。因此,如何在兼顾精调的表现的同时提升效率,是一个重要的研究问题。
本篇文章将介绍差值精调策略(delta tuning)。这类方法的核心思路是,通过只训练少量参数,并冻结其他模型参数,逼近甚至达到全量参数精调的效果。具体而言,现有的主流方法可以总结为三类:添加参数方法(addition-based),限制参数方法(Specification-based)和重参数化方法(reparameterization-based)。
一、添加参数方法
1.1 Adapter方法

Houlsby et al.[1]最早提出了adapter方法,即在语言模型的每个transformer层中添加少量可学习的参数,并冻结其余参数,如图所示。为了减少参数量,作者采用了两层FFN作为adapter的网络结构进行降维-升维。为了使得初始化结果等价于原始网络,作者采用了残差连接并零初始化adapter结构。实验表明,在多项任务上,仅使用0.5%-8%的训练参数就能逼近全量参数精调的效果,并且训练速度能提升约60%。需要注意的是,由于引入了串行的额外模块,模型的推理速度会略微下降4%-6%。
1.2 连续化提示学习
1.2.1 Prompt tuning[2]

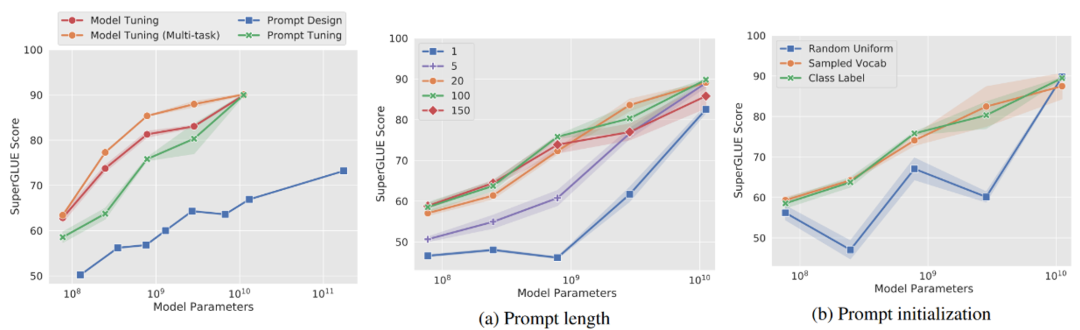
提示工程是语言模型随着规模增大而产生的新范式。针对不同的任务,提示工程会在输入文本中添加特定的token,并预测[MASK]位置的单词,然后将预测结果映射回任务的标签空间,如图所示。随着近几年的探索,提示工程经历了手工设计-离散空间搜索-连续空间搜索的几个阶段。为了使得prompt模板可以通过梯度下降学习,在连续空间搜索这一方式中,prompt直接作为固定长度的embedding添加到了输入层,并且这部分参数是可学习的。
由于只有prompt embedding的参数需要调整,因此prompt tuning的可学习参数也是相当少的。但相对应的,学习这部分参数的难度会较大,即训练的收敛速度会比较慢,而且它的效果对于prompt的长度、初始化方式等非常敏感。此外,在模型的规模比较小时,prompt tuning的表现和全量精调以及其余方法的差距都比较大。随着模型规模的增长,这个差距才会逐渐缩小。
1.2.2 Prefix tuning[3]
Prompt tuning只在embedding层加入了可学习的参数,但transformer在计算的过程中,每层都会计算self-attention,因此每层隐状态的输入长度都是P+N的(P为prompt长度,N为原始文本长度)。Prefix tuning的做法更进一步,将每层模板对应位置都替换成了可学习参数(而非通过attention从上一层聚合)。为了提升训练的稳定性,作者同时使用了重参数化技巧,降低embedding的维度,并通过MLP将其升维到隐状态的语义空间中。
作者在文本生成任务上进行了实验。令人惊讶的是,在低资源少样本的训练条件下,prefix tuning的效果能超过全量精调。这有可能是出于全量精调的过拟合问题影响了其泛化性能。
二、限制参数方法
为了缩减训练的参数量,一个自然的想法是,我们直接冻结部分参数不变,然后在剩余参数上进行梯度下降学习。具体到选取哪些参数,有些研究者提出了可学习的方法,但出于简化考虑,我们只介绍几种经验性选取的方式。
一个出于直觉的考虑是,越靠近输入的层的语义空间编码的语义更通用,越靠近输出的层的语义空间编码的语义更贴近具体的任务。因此,一个直观的做法是,只精调最后一层(或最后几层)的参数,维持其余参数不变。除此之外,Zaken et al.[4]发现,只精调网络中所有的误差项(bias),维持矩阵乘法权重不变,也能在下游任务上取得95%的表现。
三、重参数化方法
语言模型的神奇之处在于,只需要少量(数百-数千条)训练样本,我们就能训练海量(数亿-百亿)的参数,并且能取得良好的泛化效果。关于这个现象,Aghajanyan et al.[5]提出的解释是,PLM往往具有很低的本征维度。
什么是本征维度呢?考虑精调的训练过程,其实相当于在预训练初始化之上学习领域对应的参数
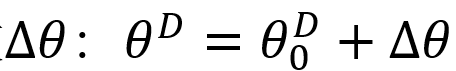
,其中D为参数的维度。那么,假设能找到一个维数很低的子空间,并通过投影等映射方式将其升维到原始空间,
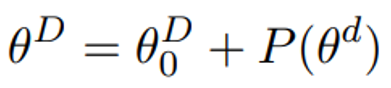
同时能达到和在原始空间中精调类似的效果,那么我们就称这个子空间的最大维度为PLM的本征维度。为了量化衡量“达到类似的效果”,作者定义其为在具体的任务上达到原始的90%的表现分数。因此,这样定义的本征维度是特定于任务的。
由于使用简单的密集投影的计算复杂度和空间复杂度都是O(Dd)的,考虑到D的范围在100M-100B之间,因此这样子的计算代价是不可接受的。作为替代,作者使用了Fastfood[6]变换作为替代:

最后,作者还考虑到为每层分别添加了超参数并学习不同的映射:
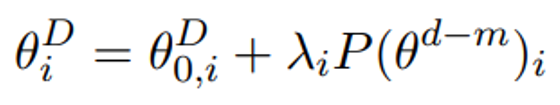
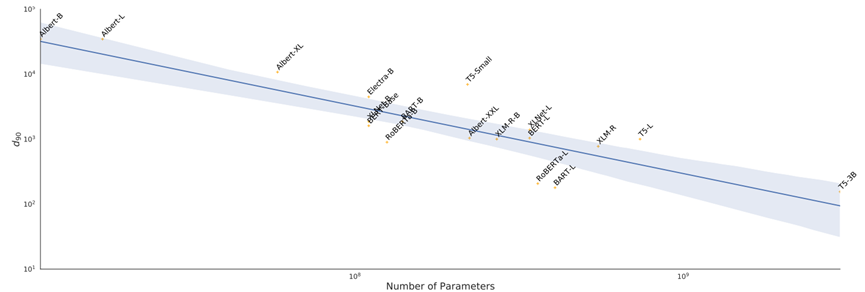
在实验部分,除了发现PLM的本征维度都很低以外,作者还发现,规模越大的模型,本征维度反而会更小,并且,在较难的任务上本征维度会更大。
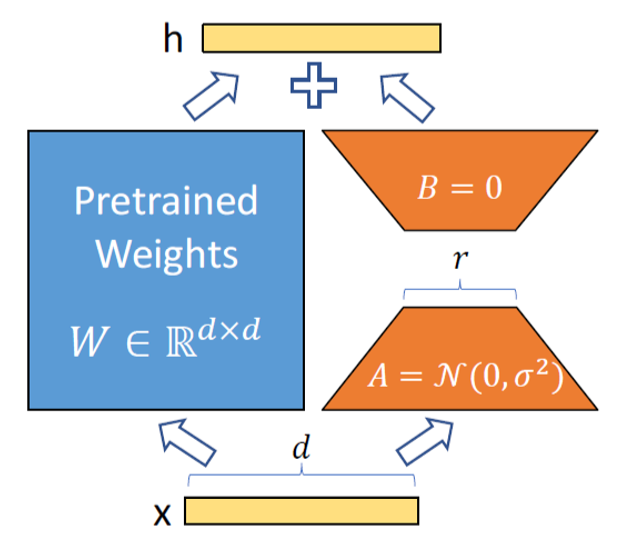
在本征维度假设之上,Hu et al.[6]提出了模型参数的低秩近似方法LoRA。即,对于所有参数矩阵的改变量,都通过ΔW=BA进行低秩分解。其中,为了保证零初始化,矩阵B采用零初始化,矩阵A则从正态分布中采样。相比于adapter方法,LoRA可以保证训练参数的收敛等价于原始网络(adapter等价于MLP),同时不会在推理阶段引起额外的延时。此外,LoRA能够极大地节省显存和存储占用,并提升训练的速度(约25%)。以GPT-3 175B为例,LoRA的精调显存占用可以从1.2TB减小为350GB,同时存储占用从350GB减为35MB。
参考文献
[1] Houlsby, Neil, et al. "Parameter-efficient transfer learning for NLP." International Conference on Machine Learning. PMLR, 2019.
[2] Lester, Brian, Rami Al-Rfou, and Noah Constant. "The Power of Scale for Parameter-Efficient Prompt Tuning." Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021.
[3] Li, Xiang Lisa, and Percy Liang. "Prefix-Tuning: Optimizing Continuous Prompts for Generation." Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021.
[4] Zaken, Elad Ben, Yoav Goldberg, and Shauli Ravfogel. "BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models." Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022.
[5] Aghajanyan, Armen, Sonal Gupta, and Luke Zettlemoyer. "Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning." Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021.
[6] Hu, Edward J., et al. "LoRA: Low-Rank Adaptation of Large Language Models." International Conference on Learning Representations. 2022.
[7] Ding, Ning, et al. "Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models." arXiv preprint arXiv:2203.06904 (2022).







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结