您现在的位置是:首页 >技术交流 >Transformer结构细节网站首页技术交流
Transformer结构细节
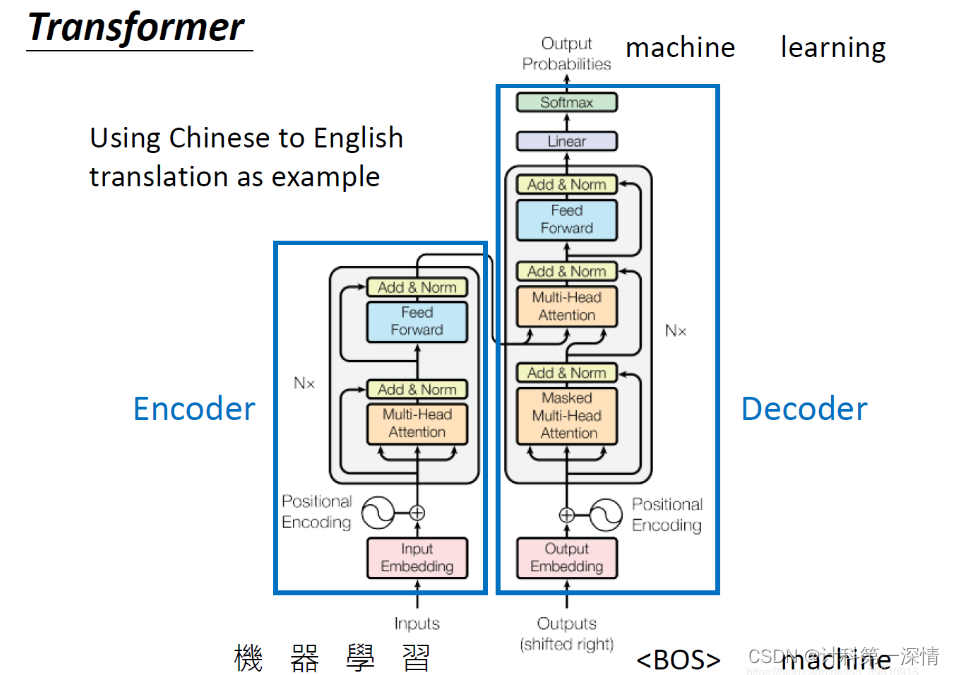
一、结构
Transformer 从大的看由 编码器输入、编码器、解码器、解码器输入和解码器输出构成。
编码器中包含了词嵌入信息编码、位置编码、多头注意力、Add&Norm层以及一个全连接层;
解码器中比编码器多了掩码的多头注意力层。
二、模块
2.1 Input Embedding层
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
2.2 Position Embedding层
在词嵌入向量上加入了位置信息,可能是在原始序列的相对位置,也可能是绝对位置。
2.3 Multi-head Self-Attention层
2.4 Feed Forward全连接层
![]()
全连接层有两层,第一层是一个ReLU函数,第二层是一个普通的线性函数;全连接层输出与X形状一致。
2.5 Add&Norm层

由上面的公式不难看出:Add&Norm接受两个输入相加,一个是处理后的序列向量X,还有一个是X经过多头注意力层或者全连接层的输出,最后再将每层神经元的输出变成均值和方差都一样,这样做的目的是加快收敛。
2.6 Masked Multi-head Self-Attention 模块
通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。
还是根据自注意力的公式来进行矩阵计算:

1. Q * K转置
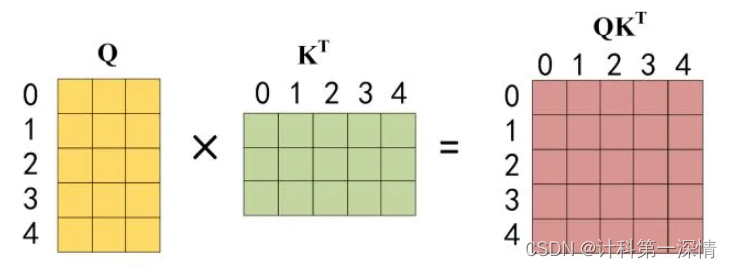
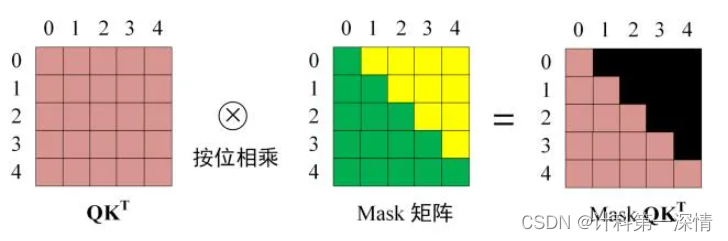
2. 进行softmax
重点来了:需要将矩阵先根据Mask矩阵规定每个单词只能看哪些单词,由此计算注意力。比如说<begin> I love you -> 我爱你中当预测 我 时,就只能看<begin> 和 I 两个单词。
3. 将Mask矩阵与V相乘得到Z,比如第一行Z1是只包含单词1的信息的。
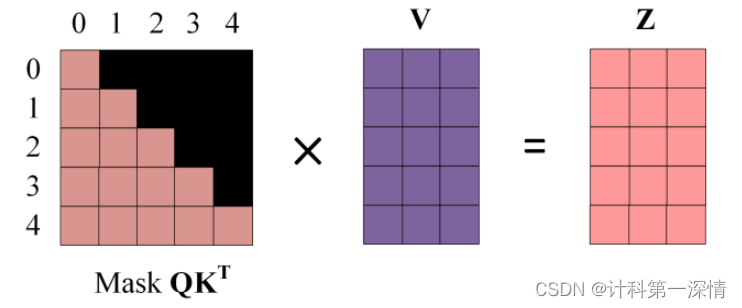
4.最后将多个Z拼接在一起乘一个工具人矩阵就得到了最后结果。输出与X形状一致。
三、过程
3.1 将输入的句子中的每个词编码成一个向量,并加入单词在文本中的位置信息。
最后得到的单词矩阵是N * M的。(N表示有几个单词,M表示单词维度)
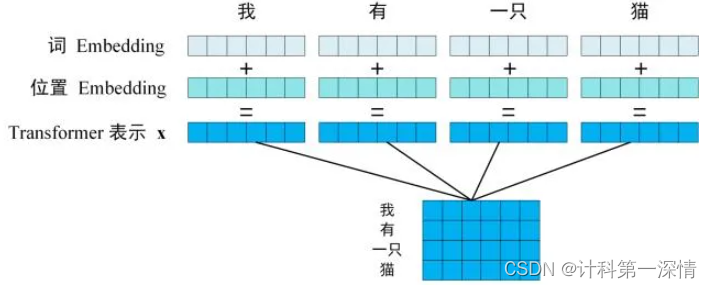
3.2 将句子的矩阵表示输入到编码器中,迭代六次,得到与X形状一直的矩阵C。
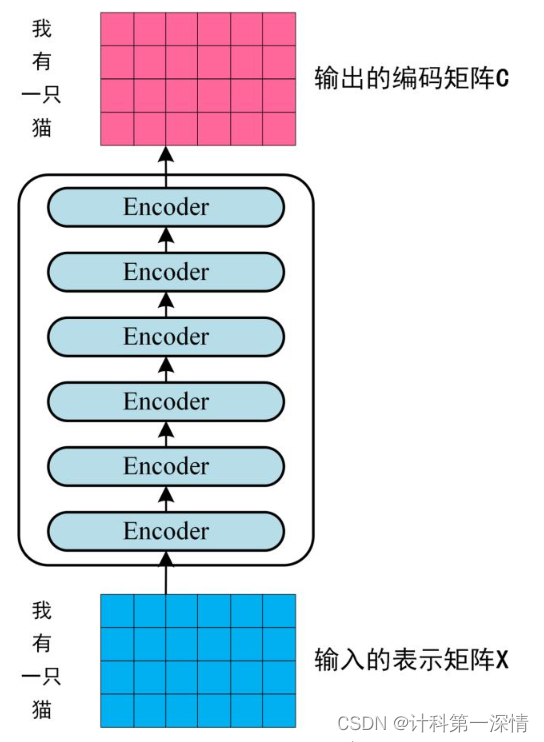
3.3 将句子矩阵C传入到解码器中,在预测第i个词时,根据Mask矩阵mask掉第i+1以及之后的词。
Reference:Transformer模型详解(图解最完整版) - 知乎





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结