您现在的位置是:首页 >技术教程 >Python网络爬虫原理及实践 | 京东云技术团队网站首页技术教程
Python网络爬虫原理及实践 | 京东云技术团队
作者:京东物流 田禹
1 网络爬虫
网络爬虫:是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
网络爬虫相关技术和框架繁多,针对场景的不同可以选择不同的网络爬虫技术。
2 Scrapy框架(Python)
2.1. Scrapy架构
2.1.1. 系统架构
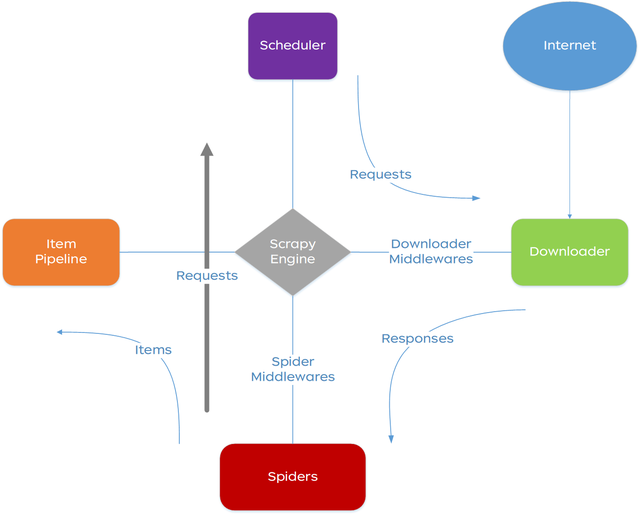
2.1.2. 执行流程
总结爬虫开发过程,简化爬虫执行流程如下图所示:
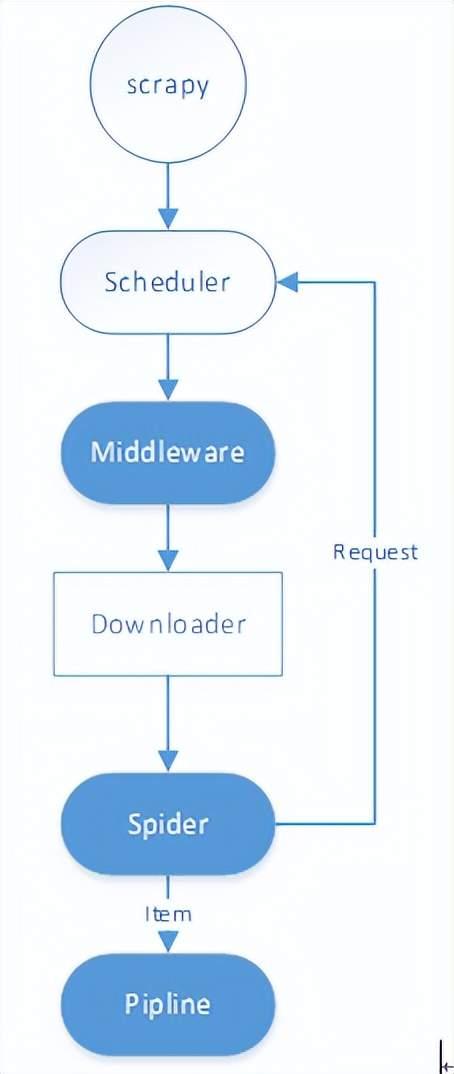
爬虫运行主要流程如下:
(1) Scrapy启动Spider后加载Spaider的start_url,生成request对象;
(2) 经过middleware完善request对象(添加IP代理、User-Agent);
(3) Downloader对象按照request对象下载页面;
(4) 将response结果传递给spider的parser方法解析;
(5) spider获取数据封装为item对象传递给pipline,解析的request对象将返回调度器进行新一轮的数据抓取;
2.2. 框架核心文件介绍
2.2.1. scrapy.cfg
scrapy.cfg是scrapy框架的入口文件,settings节点指定爬虫的配置信息,deploy节点用于指定scrapyd服务的部署路径。
|
[settings]
default = sfCrawler.settings
[deploy]
url =http://localhost:6800/
project = jdCrawler
|
2.2.2. settings.py
settings主要用于配置爬虫启动信息,包括:并发线程数量、使用的middleware、items等信息;也可以作为系统中的全局的配置文件使用。
**注:**目前主要增加了redis、数据库连接等相关配置信息。
2.2.3. middlewares.py
middleware定义了多种接口,分别在爬虫加载、输入、输出、请求、请求异常等情况进行调用。
**注:**目前主要用户是为爬虫增加User-Agent信息和IP代理信息等。
2.2.4. pipelines.py
用于定义处理数据的Pipline对象,scrapy框架可以在settings.py文件中配置多个pipline对象,处理数据的个过程将按照settings.py配置的优先级的顺序顺次执行。
**注:**系统中产生的每个item对象,将经过settings.py配置的所有pipline对象。
2.2.5. items.py
用于定义不同种数据类型的数据字典,每个属性都是Field类型;
2.2.6. spider目录
用于存放Spider子类定义,scrapy启动爬虫过程中将按照spider类中name属性进行加载和调用。
2.3. 爬虫功能扩展说明
2.3.1. user_agents_middleware.py
通过procces_request方法,为request对象添加hearder信息,随机模拟多种浏览器的User-Agent信息进行网络请求。
2.3.2. proxy_server.py
通过procces_request方法,为reques对象添加网络代理信息,随机模拟多IP调用。
2.3.3. db_connetion_pool.py
文件位置
db_manager/db_connetion_pool.py,文件定义了基础的数据连接池,方便系统各环节操作数据库。
2.3.4. redis_connention_pool.py
文件位置db_manager/ redis_connention_pool.py,文件定义了基础的Redis连接池,方便系统各环节操作Redis缓存。
2.3.5. scrapy_redis包
scrapy_redis包是对scrapy框架的扩展,采用Redis作为请求队列,存储爬虫任务信息。
spiders.py文件:定义分布式RedisSpider类,通过覆盖Spider类start_requests()方法的方式,从Redis缓存中获取初始请求列表信息。其中RedisSpider子类需要为redis_key赋值。
pipelines.py文件:定义了一种简单的数据存储方式,可以直接将item对象序列化后保存到Redis缓存中。
dupefilter.py文件:定义数据去重类,采用Redis缓存的方式,已经保存的数据将添加到过滤队列中。
queue.py文件:定义几种不同的入队和出队顺序的队列,队列采用Redis存储。
2.4. 微博爬虫开发示例
2.4.1. 查找爬虫入口
2.4.1.1. 站点分析
网站一般会分为Web端和M端两种,两种站点在设计和架构上会有较大的差别。通常情况下Web端会比较成熟,User-Agent检查、强制Cookie、登录跳转等限制,抓取难度相对较大,返回结果以HTML内容为主;M端站点通常采用前后端分离设计,大多提供独立的数据接口。所以站点分析过程中优先查找M端站点入口。微博Web端及M端效果如图所示:
微博Web端地址:https://weibo.com/,页面显示效果如下图所示:
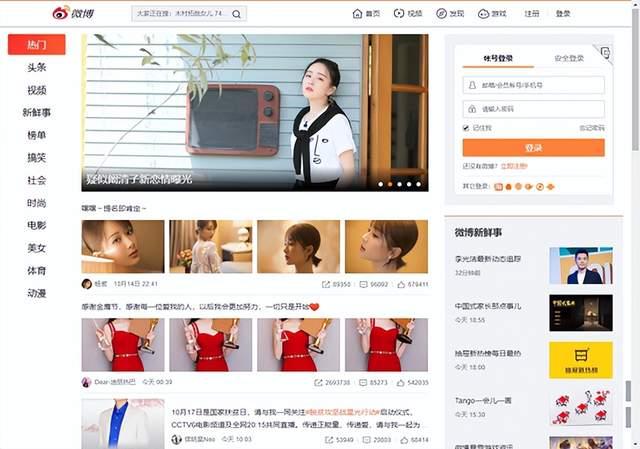
注:图片来源于微博PC端截图
微博M端地址:https://m.weibo.cn/?jumpfrom=weibocom,页面显示效果如下图所示:
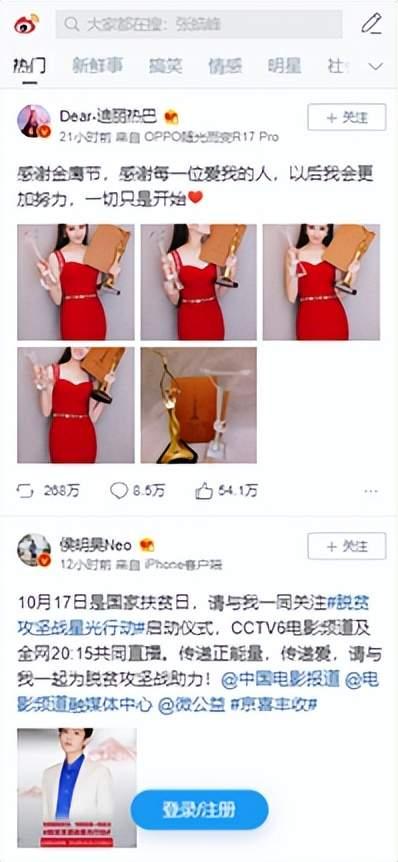
注:图片来源于微博M端截图
2.4.1.2. HTML源码分析
Web端站点和M端站点返回结果都是HTML格式,部分站点为了提升页面渲染速度,或者为了增加代码分析难度,通过动态JavaScrip执行等方式,动态生成HTML页面,网络爬虫缺少JS执行和渲染过程,很难获取真实的数据,微博Web端站点HTML代码片段如下所示:

脚本中的正文内容:

M端站点HTML内容:

M端HTML内容中并未出现页面中的关键信息,可以判定为前后端分离的设计方式,通过Chrome浏览器开发模式,能够查看所有请求信息,通过请求的类型和返回结果,基本可以确定接口地址,查找过程如下图所示:
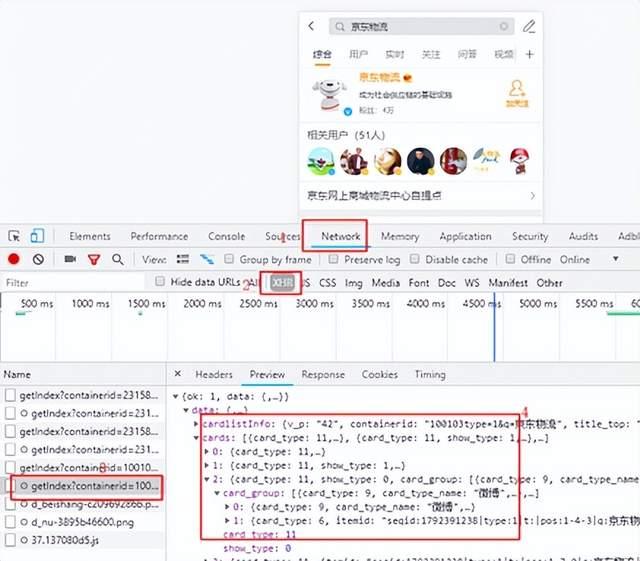
注:图片来源于微博M端截图
(1) 打开Chrome开发者工具,刷新当前页面;
(2) 修改请求类型为XHR,筛选Ajax请求;
(3) 查看所有请求信息,忽略没有返回结果的接口;
(4) 在接口返回结果中查找页面中相关内容。
2.4.1.3. 接口分析
接口分析主要包括:请求地址分析、请求方式、参数列表、返回结果等。
请求地址、请求方式和参数列表可以根据Chrome开发人员工具中的网络请求Header信息获取,请求信息如下图所示:
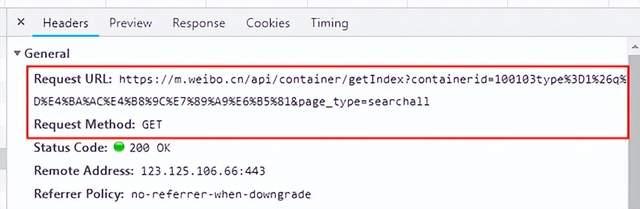
上图中接口地址采用的是GET方式请求,请求地址是unicode编码,参数内容可以查看Query String Parameters列表查看请求参数,效果如下图所示:

请求结果分析主要分析数据结构的特点,查找与正文内容相同的数据结构,同时要检查所有结果是否与正文内容一致,避免特殊返回结果影响数据解析过程。
2.4.1.4. 接口验证
接口验证一般需要两个步骤:
(1)用浏览器(最好是新开浏览器,如Chrome的隐身模式)模拟请求过程,在地址栏中输入带有参数的请求地址查看返回结果。
(2)采用Postman等工具模拟浏览器请求过程,主要模拟非Get方式的网络请求,同样也可以验证站点是否强制使用Cookie和User-Agent信息等。
2.4.2. 定义数据结构
爬虫数据结构定义主要结合业务需求和数据抓取的结果进行设计,微博数据主要用户国内的舆情系统,所以在开发过程中将相关站点的数据统一定义为OpinionItem类型,在不同站点的数据保存过程中,按照OpinionItem数据结构的特点装配数据。在items.py文件中定义舆情数据结构如下所示:
class OpinionItem(Item):
rid = Field()
pid = Field()
response_content = Field() # 接口返回的全部信息
published_at = Field() # 发布时间
title = Field() # 标题
description = Field() # 描述
thumbnail_url = Field() # 缩略图
channel_title = Field() # 频道名称
viewCount = Field() # 观看数
repostsCount = Field() # 转发数
likeCount = Field() # 点赞数
dislikeCount = Field() # 不喜欢数量
commentCount = Field() # 评论数
linked_url = Field() # 链接
updateTime = Field() # 更新时间
author = Field() # 作者
channelId = Field() # 渠道ID
mediaType = Field() # 媒体类型
crawl_time = Field() # 抓取时间
type = Field() # 信息类型:1 主贴 2 主贴的评论
2.4.3. 爬虫开发
微博爬虫采用分布式RedisSpider作为父类,爬虫定义如下所示:
class weibo_list(RedisSpider):
name = 'weibo'
allowed_domains = ['weibo.cn']
redis_key = 'spider:weibo:list:start_urls'
def parse(self, response):
a = json.loads(response.body)
b = a['data']['cards']
for j in range(len(b)):
bb = b[j]
try:
for c in bb['card_group']:
try:
d = c['mblog']
link = 'https://m.weibo.cn/api/comments/show?id={}'.format(d['mid'])
# yield scrapy.Request(url=link, callback=self.parse_detail)
# 内容解析代码片段
opinion['mediaType'] = 'weibo'
opinion['type'] = '1'
opinion['crawl_time'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
yield opinion
except Exception as e:
print(e)
continue
except Exception as e:
print(e)
continue
代码解析:
代码行1:定义weibo_list类,继承RedisSpider类;
代码行2:定义爬虫名称,爬虫启动时使用;
代码行3:增加允许访问的地址域名列表;
代码行4:定义微博开始请求地址的redis key;
代码行6:定义爬虫的解析方法,爬虫下载页面后默认调用parser方法;
代码行7~21:将下载结果内容解析后装配到item对象中;
代码行22:通过yield关键字,生成Python特有的生成器对象,调用者可以通过生成器对象遍历所有结果。
2.4.4. 数据存储
数据存储主要通过定义Pipline实现类,将爬虫解析的数据进行保存。微博数据需要增加进行情感分析的加工过程,开发过程中首先将微博数据保存到Redis服务中,通过后续的情感分析解析服务获取、加工,并保存到数据库中。数据保存代码如下所示:
class ShunfengPipeline(object):
def process_item(self, item, spider):
if isinstance(item, OpinionItem):
try:
print('===========Weibo查询结果============')
key = 'spider:opinion:data'
dupe = 'spider:opinion:dupefilter'
attr_list = []
for k, v in item.items():
if isinstance(v, str):
v = v.replace(''', '\'')
attr_list.append("%s:'%s'" % (k, v))
data = ",".join(attr_list)
data = "{%s}" % data
# 按照数据来源、类型和唯一id作为去重标识
single_key = ''.join([item['mediaType'], item['type'], item['rid']])
if ReidsPool().rconn.execute_command('SADD', dupe, single_key) != 0:
ReidsPool().rconn.execute_command('RPUSH', key, data)
except Exception as e:
print(e)
pass
return item
关键代码说明:
代码行1:定义Pipline类;
代码行2:定义process_item方法,用于接收数据;
代码行3:按照Item类型分别处理;
代码行4~17:Item对象拼装为JSON字符串;
代码行18~21:对数据进行去重校验,并将数据保存到redis队列中;
代码行26:返回item对象供其他Pipline操作;
Pipline定义完成后,需要在工程中的settings.py文件中进行配置,配置内容如下所示:
|
# 配置项目管道
ITEM_PIPELINES = {
“sfCrawler.pipelines.JdcrawlerPipeline”: 401,
“sfCrawler.pipelines_manage.mysql_pipelines.MySqlPipeline”: 402,
“sfCrawler.pipelines_manage.shunfeng_pipelines.ShunfengPipeline”: 403,
}
|
爬虫入门地址:
https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
3 WebMagic框架(Java)
3.1 前言
总结Scrapy使用过程中存在的问题,以及爬虫系统后期上线需求考虑,采用Java语言进行爬虫的设计与开发。具体原因如下:
(1)上线基础环境依赖:需要使用线上Clover、JimDB、MySQL等基础环境;
(2)可扩展性强:以现有框架为基础,二次封装Request请求对象,实现通用网络爬虫开发,提供易扩展的地址生成、网页解析接口。
(3)集中部署:通过部署通用爬虫方式,抓取所有支持站点的爬虫,解决Scrapy框架一站点一部署问题。
(4)反-反爬虫:部分站点针对Scrapy框架请求特点,实施反爬虫策略(如:天猫),拒绝所有爬虫请求。WebMagic模拟浏览器请求,不受该爬虫限制。
3.2 WebMagic概述
(内容来源:https://webmagic.io/docs/zh/posts/ch1-overview/architecture.html)
3.2.1 总体架构
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。WebMagic的设计参考了Scapy,但是实现方式更Java化一些。
而Spider则将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以认为Spider是一个大的容器,它也是WebMagic逻辑的核心。
WebMagic总体架构图如下:
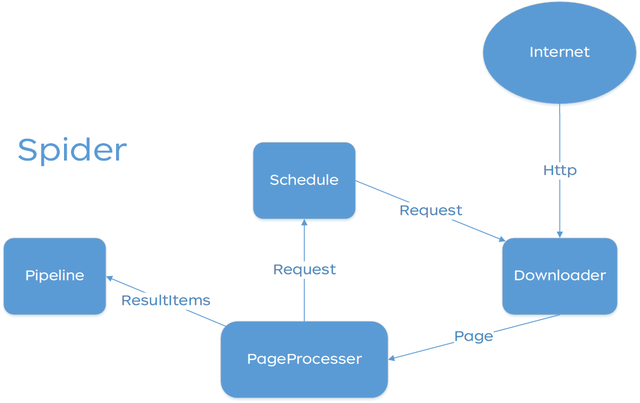
3.1.2 WebMagic的四个组件
3.1.2.1 Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
3.1.2.2 PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.1.2.3 Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
3.1.2.4 Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
3.1.3 用于数据流转的对象
3.1.3.1 Request
Request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。
除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。
3.1.3.2 Page
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。在第四章的例子中,我们会详细介绍它的使用。
3.1.3.3 ResultItems
ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不应被Pipeline处理。
3.1.4 控制爬虫运转的引擎–Spider
Spider是WebMagic内部流程的核心。Downloader、PageProcessor、Scheduler、Pipeline都是Spider的一个属性,这些属性是可以自由设置的,通过设置这个属性可以实现不同的功能。Spider也是WebMagic操作的入口,它封装了爬虫的创建、启动、停止、多线程等功能。下面是一个设置各个组件,并且设置多线程和启动的例子。详细的Spider设置请看第四章——爬虫的配置、启动和终止。
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor())
//从https://github.com/code4craft开始抓
.addUrl("https://github.com/code4craft")
//设置Scheduler,使用Redis来管理URL队列
.setScheduler(new RedisScheduler("localhost"))
//设置Pipeline,将结果以json方式保存到文件
.addPipeline(new JsonFilePipeline("D:\data\webmagic"))
//开启5个线程同时执行
.thread(5)
//启动爬虫
.run();
}
3.3 通用爬虫分析及设计
3.2.1 通用爬虫功能分析
(1)单个应用同时支持多个站点的数据抓取;
(2)支持集群部署;
(3)容易扩展;
(4)支持重复抓取;
(5)支持定时抓取;
(6)具备大数据分析扩展能力;
(7)降低大数据分析集成复杂度,提高代码复用性;
(8)支持线上部署;
3.2.2 通用爬虫设计
通用爬虫设计思路是在WebMagic基础上,将Scheduler、Processor、Pipeline进行定制,设计如下图所示:
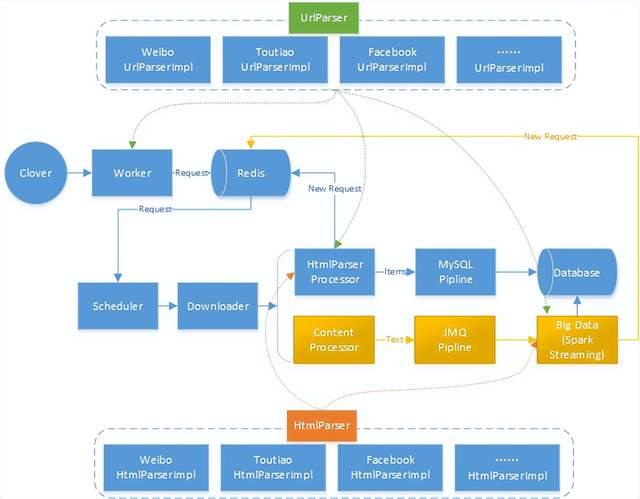
设计过程中按照爬虫开发的特点,将爬虫实现过程拆分为两个环节:生成请求和内容解析。
(1)生成请求(UrlParser):按照不同站点的请求地址及参数特点(如:Get/Post请求方式,URL参数拼接等)及业务需要(如:使用国内代理还是国外代理),按照站点参数拼装成为通用的Request请求对象,指导Downloader进行网页下载。
(2)内容解析(HtmlParser):按照解析网页内容的特点,通过XPATH、JSON等方式对页面内容进行提取过程,每个内容解析器只针对相同页面内容进行解析,当内容中包含深度页面抓取的请求时,由UrlParser生成新的请求对象并返回给调度器。
3.2.3 任务调度设计
为了实现爬虫的分布式,将Scheduler功能进行弱化,实现过程增加Clover、Worker、Redis环节。Clover负责定时调度Worker生成默认请求对象(一般为检索功能、首页重复抓取任务等),将生成的请求对象添加到Redis队列中,Scheduler只负责从Redis队列中获取请求地址即可。
3.2.4 Processor设计
Processor用于解析Downloader下载的网页内容,为了充分利用服务器网络和计算资源,设计之初考虑能够将网页下载和内容解析拆分到不同服务中进行处理,避免爬虫节点CPU时间过长造成网络带宽的浪费。所以,设计过程中按照爬虫内部解析和外部平台集成解析两种方式进行设计。
(1)爬虫内部解析:即下载内容直接由Processor完成页面解析过程,生成Items对象和深度Request对象。为了简化对多个站点内容的解析过程,Processor主要负责数据结构的组织和HtmlParser的调用,通过Spring IOC的方式实现多个站点HtmlParser集成过程。
(2)外部平台集成:能够将爬虫抓取内容通过MQ等方式,实现其他平台或服务的对接过程。实现过程中可以将抓取的网页内容组织成为文本类型,通过Pipline方式将数据发送到JMQ中,按照JMQ方式实现与其他服务和平台的对接过程。其他服务可以复用HtmlParser和UrlParser完成内容解析过程。
3.2.5 Pipline设计
Pipline主要用于数据的转储,为了适用Processor的两种方案,设计MySQLPipeline和JMQPipeline两种实现方式。
3.4 通用爬虫实现
3.4.1 Request
WebMagic提供的Request类能够满足网络请求的基本需求,包括URL地址、请求方式、Cookies、Headers等信息。为了实现通用的网络请求,对现有请求对象进行业务扩展,增加是否过滤、过滤token、请求头类型(PC/APP/WAP)、代理IP国别分类、失败重试次数等。扩展内容如下:
/**
* 站点
*/
private String site;
/**
* 类型
*/
private String type;
/**
* 是否过滤 default:TRUE
*/
private Boolean filter = Boolean.TRUE;
/**
* 唯一token,URL地址去重使用
*/
private String token;
/**
* 解析器名称
*/
private String htmlParserName;
/**
* 是否填充Header信息
*/
private Integer headerType = HeaderTypeEnums.NONE.getValue();
/**
* 国别类型,用于区分使用代理类型
* 默认为国内
*/
private Integer nationalType = NationalityEnums.CN.getValue();
/**
* 页面最大抓取深度,用于限制列表页深度钻取深度,按照访问次数依次递减
* <p>Default: 1</p>
* <p> depth = depth - 1</p>
*/
private Integer depth = 1;
/**
* 失败重试次数
*/
private Integer failedRetryTimes;
3.4.2 UrlParser & HtmlParser
3.4.2.1 UrlParser实现
UrlParser主要用与按照参数列表生成固定的请求对象,为了简化Workder的开发过程,在接口中增加了生成初始化请求的方法。
/**
* URL地址转换
* @author liwanfeng1
*/
public interface UrlParser {
/**
* 获取定时任务初始化请求对象列表
* @return 请求对象列表
*/
List<SeparateRequest> getStartRequest();
/**
* 按照参数生成Request请求对象
* @param params
* @return
*/
SeparateRequest parse(Map<String, Object> params);
}
3.4.2.2 HtmlParser实现
HtmlParser主要是将Downloader内容进行解析,并返回data列表及深度抓取的Request对象。实现如下:
/**
* HTML代码转换
* @author liwanfeng1
*/
public interface HtmlParser {
/**
* HTML格式化
* @param html 抓取的网页内容
* @param request 网络请求的Request对象
* @return 数据解析结果
*/
HtmlDataEntity parse(String html, SeparateRequest request);
}
/**
* @author liwanfeng1
* @param <T> 数据类型
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class HtmlDataEntity<T extends Serializable> {
private List<T> data;
private List<SeparateRequest> requests;
/**
* 添加数据对象
* @param obj 数据对象
*/
public void addData(T obj){
if(data == null) {
data = new ArrayList<>();
}
data.add(obj);
}
/**
* 添加Request对象
* @param request 请求对象
*/
public void addRequest(SeparateRequest request) {
if(requests == null) {
requests = new ArrayList<>();
}
requests.add(request);
}
}
3.4.3 Worker
Workder的作用是定时生成请求对象,结合UrlParser接口的应用,设计统一的WorkerTask实现类,代码如下:
/**
*
* @author liwanfeng1
*/
@Slf4j
@Data
public class CommonTask extends AbstractScheduleTaskProcess<SeparateRequest> {
private UrlParser urlParser;
private SpiderQueue spiderQueue;
/**
* 获取任务列表
* @param taskServerParam 参数列表
* @param i 编号
* @return 任务列表
*/
@Override
protected List<SeparateRequest> selectTasks(TaskServerParam taskServerParam, int i) {
return urlParser.getStartRequest();
}
/**
* 执行任务列表,组织Google API请求地址,添加到YouTube列表爬虫的队列中
* @param list 任务列表
*/
@Override
protected void executeTasks(List<SeparateRequest> list) {
spiderQueue.push(list);
}
}
添加Worker配置如下:
<!-- Facebook start -->
<bean id="facebookTask" class="com.jd.npoms.worker.task.CommonTask">
<property name="urlParser">
<bean class="com.jd.npoms.spider.urlparser.FacebookUrlParser"/>
</property>
<property name="spiderQueue" ref="jimDbQueue"/>
</bean>
<jsf:provider id="facebookTaskProcess"
interface="com.jd.clover.schedule.IScheduleTaskProcess" ref="facebookTask"
server="jsf" alias="woker:facebookTask">
</jsf:provider>
<!-- Facebook end -->
3.4.4 Scheduler
调度主要用于推送、拉取最新任务,以及辅助的推送重复验证、队列长度获取等方法,接口设计如下:
/**
* 爬虫任务队列
* @author liwanfeng
*/
public interface SpiderQueue {
/**
* 添加队列
* @param params 爬虫地址列表
*/
default void push(List<SeparateRequest> params) {
if (params == null || params.isEmpty()) {
return;
}
params.forEach(this::push);
}
/**
* 将SeparaterRequest地址添加到Redis队列中
* @param separateRequest SeparaterRequest地址
*/
void push(SeparateRequest separateRequest);
/**
* 弹出队列
* @return SeparaterRequest对象
*/
Request poll();
/**
* 检查separateRequest是否重复
* @param separateRequest 封装的爬虫url地址
* @return 是否重复
*/
boolean isDuplicate(SeparateRequest separateRequest);
/**
* 默认URL地址生成Token<br/>
* 建议不同的URLParser按照站点地址的特点,生成较短的token
* 默认采用site、type、url地址进行下划线分割
* @param separateRequest 封装的爬虫url地址
*/
default String generalToken(SeparateRequest separateRequest) {
return separateRequest.getSite() + "_" + separateRequest.getType() + "_" + separateRequest.getUrl();
}
/**
* 获取队列总长度
* @return 队列长度
*/
Long getQueueLength();
}
4 浏览器调用爬虫(Python)
浏览器调用爬虫主要借助Selenium与ChromeDriver技术,通过本地化浏览器调用方式加载并解析页面内容,实现数据抓取。浏览器调用主要解决复杂站点的数据抓取,部分站点通过流程拆分、逻辑封装、代码拆分、代码混淆等方式增加代码分析的复杂度,结合请求拆分、数据加密、客户端行为分析等方式进行反爬操作,使爬虫程序无法模拟客户端请求过程向服务端发起请求。
该种方式主要应用于顺丰快递单号查询过程,订单查询采用腾讯滑动验证码插件进行人机验证。基本流程如下图所示:

首先配置ChromeDriver组件到操作系统中,组件下载地址:
https://chromedriver.storage.googleapis.com/index.html?path=2.44/,将文件保存到系统环境变量“PATH”中指定的任意路径下,建议:C:Windowssystem32目录下。
组件添加验证:启用命令行窗口->任意路径运行“ChromeDriver.exe”,程序会以服务形式运行。
爬虫实现过程如下:
(1)启动浏览器:为了实现爬虫的并发,需要通过参数方式对浏览器进行优化设置;
启动浏览器
def getChromeDriver(index):
options = webdriver.ChromeOptions()
options.add_argument("--incognito") # 无痕模式
options.add_argument("--disable-infobars") # 关闭菜单栏
options.add_argument("--reset-variation-state") # 重置校验状态
options.add_argument("--process-per-tab") # 独立每个tab页为单独进程
options.add_argument("--disable-plugins") # 禁用所有插件
options.add_argument("headless") # 隐藏窗口
proxy = getProxy()
if proxy is not None:
options.add_argument("--proxy-server==http://%s:%s" % (proxy["host"], proxy["port"])) # 添加代理
return webdriver.Chrome(chrome_options=options)
(2)加载页面:调用浏览器访问指定地址页面,并等待页面加载完成;
driver.get('http://www.sf-express.com/cn/sc/dynamic_function/waybill/#search/bill-number/' + bill_number)
driver.implicitly_wait(20) #最长等待20秒加载时间
(3)切换Frame:验证码采用IFrame方式加载到当前页面,接下来需要对页面元素进行操作,需要将driver切换到iframe中;
driver.switch_to.frame("tcaptcha_popup")
driver.implicitly_wait(10) #等待切换完成,其中iframe加载可能有延迟
(4)滑动模块:滑动页面中的滑块到指定位置,实现验证过程;
滑动验证码操作过程如下图所示:
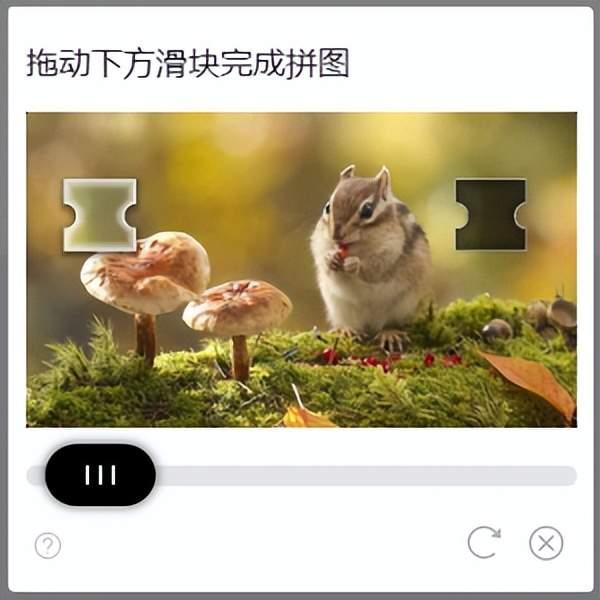
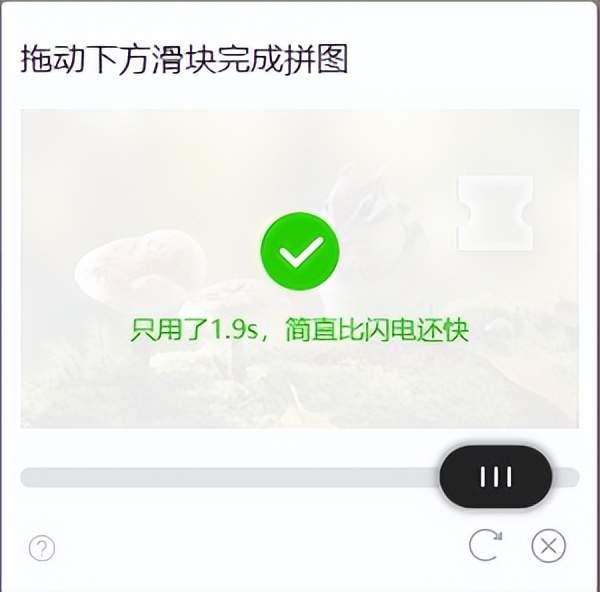
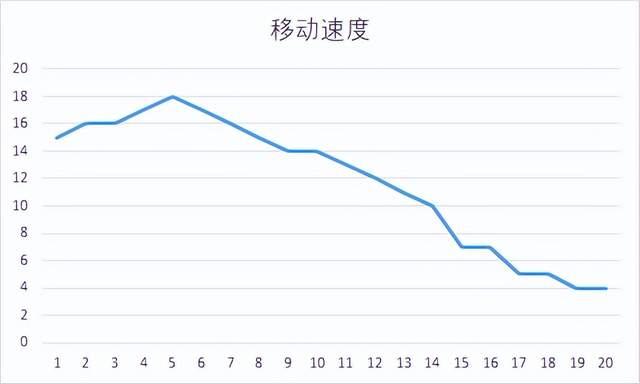
滑动模块执行距离在240像素前后,整个滑动过程取样14个,模拟抛物线执行过程控制滑动速度,将这个滑动过程分为20次移动(避免每次采样结果相同),分析如下图所示:

代码如下:
# 随机生成滑块拖动轨迹
def randomMouseTrace():
trace = MouseTrace()
trace.x = [20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 9, 9, 8, 8, 7, 7, 6, 6, 5, 5]
trace.y = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
trace.time = [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]
return trace
# 拖动滑块
def dragBar(driver, action):
dragger = driver.find_element_by_id("tcaptcha_drag_button")
action.click_and_hold(dragger).perform() # 鼠标左键按下不放
action.reset_actions()
trace = randomMouseTrace()
for index in range(trace.length()):
action.move_by_offset(trace.x[index], trace.y[index]).perform() # 移动一个位移
action.reset_actions()
time.sleep(trace.time[index]) # 等待停顿时间
action.release().perform() # 鼠标左键松开
action.reset_actions()
return driver.find_element_by_id("tcaptcha_note").text == ""
(4)数据解析及存储:数据解析过程主要是按照id或class进行元素定位获取文本内容,将结果插入到数据库即完成数据抓取过程。
(5)其他:采用Python的threading进行多线程调用,将订单编号保存到Redis中实现分布式任务获取过程,每执行一次将POP一个订单编号。
待改进:
(1)模块滑动速度和时间固定,可以进行随机优化;
(2)未识别滑块释放位置,目前采用滑块更新的方式重试,存在一定的错误率;
(3)如果不切换代理IP,需要对浏览器启动进行优化,减少启动次数,提升抓取速度;
5 gocolly框架(Go)
多线程并发执行是Go语言的优势之一,Go语言通过“协程”实现并发操作,当执行的协程发生I/O阻塞时,会由专门协程进行阻塞任务的管理,对服务器资源依赖更少,抓取效率也会有所提高。
(以下内容转自:https://www.jianshu.com/p/23d4ecb8428f)
5.1 概述
gocolly是用go实现的网络爬虫框架gocolly快速优雅,在单核上每秒可以发起1K以上请求;以回调函数的形式提供了一组接口,可以实现任意类型的爬虫;依赖goquery库可以像jquery一样选择web元素。
gocolly的官方网站是http://go-colly.org/,提供了详细的文档和示例代码。
5.2 安装配置
安装
go get -u github.com/gocolly/colly/
引入包
import "github.com/gocolly/colly"
5.3 流程说明
5.3.1 使用流程
使用流程主要是说明使用colly抓取数据前的准备工作
-
初始化Collector对象, Collector对象是colly的全局句柄
-
设置全局设置,全局设置主要是设置colly 句柄的代理设置等
-
注册抓取回调函数, 主要是用于在抓取数据后在数据处理的各个流程提取数据以及出发其他操作
-
设置辅助工具,如抓取链接的存放队列,数据清洗队列等
-
注册抓取链接
-
启动程序开始抓取
5.3.2 抓取流程
每次抓取数据流程中的各个节点都会尝试触发用户注册的抓取回调函数,以完成提取数据等需求, 抓取流程如下。
-
根据链接每次准备抓取数据前调用 注册的OnRequest做每次抓取前的预处理工作
-
当抓取数据失败时会调用OnError做错误处理
-
抓取到数据后调用OnResponse,做刚抓到数据时的处理工作
-
然后分析抓取到的数据会根据页面上的dom节点触发OnHTML回调进行数据分析
-
数据分析完毕后会调用OnScraped函数进行每次抓取后的收尾工作
5.4. 辅助接口
colly也提供了部分辅助接口,协助完成数据抓取分析流程, 以下列举一部分主要的支持。
-
queue 用于存放等待抓取的链接
-
proxy 用于代理发起抓取源
-
thread 支持多携程并发处理
-
filter 支持对特殊链接进行过滤
-
depth 可以设置抓取深度控制抓取
5.5. 实例
更多可以参考源码链接中的例子(https://github.com/gocolly/colly/tree/master/_examples)






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结