您现在的位置是:首页 >技术交流 >effective c++ item30-34网站首页技术交流
effective c++ item30-34
item30:理解inline
1、inline函数
用inline修饰函数可以防止multiple definition的错误
// foo.h
inline int foo(int x){ // 如果不加inline,在编译时会有两个foo.h被包含进去,导致链接出错
static int n = 1;
return x * (n ++);
}
// bar1.cpp
#include "foo.h"
int bar1(){
return foo(1);
}
// bar2.cpp
#include "foo.h"
int bar2(){
return foo(2);
}
// main.cpp
int bar1();
int bar2();
int main(){
int r = bar1() + bar2();
}
2、inline变量(c++17)
// foo.h
struct Foo{
// 如果不加inline,需要在cpp文件中单独初始化static变量
inline static int foo = 1;
}
// bar1.cpp
#include "foo.h"
int bar1(){
return Foo::foo + 1;
}
// bar2.cpp
#include "foo.h"
int bar2(){
return Foo::foo + 2;
}
// main.cpp
int bar1();
int bar2();
int main(){
int r = bar1() + bar2();
}
3、修饰命名空间
有利于用来做版本控制
#define macro 2022L
// foo.h
namespace libfoo{
#if macro >= 2022L
inline
#endif
namespace libfoo_2022{
int foo(int );
float foo(float);
}
#if macro >= 2019L && macro < 2022L
inline
#endif
namespace libfoo_2019{
int foo(int);
}
//other version...
}
// main.cpp
using namespace libfoo;
int main(){
std::cout << foo(5) << std::endl; // aka libfoo::libfoo_2022::foo(int)
}
以下情况只能用inline来实现:
// foo.h
namespace libfoo{
class Bar1{};
// 如果不加inline,会导致ADL(argument-dependent lookup)特性失效
inline namespace libfoo_2022{
void foo1(Bar1);
class Bar2{};
template <typename T>
T &foo(T &);
}
void foo2(Bar2);
}
// main.cpp
int main(){
libfoo::foo(3.2); // aka libfoo::libfoo_2022::foo
libfoo::Bar1 bar;
libfoo::Bar2 bar2;
foo1(bar1); // lib::libfoo_2022::foo1
foo2(bar2); // lib::foo2
}
4、隐式inline
class A{
public:
int geta(){return a;} // implicit inline request; geta() is defined in a class definition
private:
int a;
}
inline void f() {... }
void (*pf)() = f;
pf(); // this call won't be, because it's a function pointer
// 该调用不会触发内联,编译器会老老实实进行函数调用
类的空的构造函数不一定就被内联,因为构造函数中要调用基类的构造函数、成员变量的构造函数等,如果都要内联会导致代码过多。
item31:最小化文件依赖|编译防火墙
如果我们修改了某个类的一个成员变量,那么所有包含这个类的文件都要重新编译,为了节约编译的时间我们应该尽量减小文件的依赖。
headle class
Person p(params);
// 如果使用指针就可以避免文件依赖,因为编译器不需要关心对象的内存布局、内存大小,只分配8字节的指针大小就可以
Person *p;
基于此,我们可以将类中的成员做一个前向声明,这也被称为pimpl
 使用一个智能指针impl_指向真正的成员实现,当Data、Address发生变化时,Person并不受影响
使用一个智能指针impl_指向真正的成员实现,当Data、Address发生变化时,Person并不受影响
依赖声明而不是而不是定义
Avoid using objects when object references and pointers will do. You may define references and pointers to a type with only a declaration for the type. Defining objects of a type necessitates the presence of the type’s definition.
Depend on class declarations instead of class definitions whenever you can. Note that you never need a class definition to declare a function using that class, not even if the function passes or returns the class type by value:
class Date; // class declaration.使用者不需要包含Date.h,只需要依赖于此声明文件即可
Date today(); // ok--no definition
void clearAppointments(Date d); // Date is needed
Provide separate header files for declarations and definitions.
#include "datefwd.h" // header file declaring(but not defining)
Date today(); // as before
void clearAppointments(Date d);
The name of the declaration-only header file “datefwd.h” is based on the header <iosfwd> from the standard C++ library. <iosfwd> contains declarations of iostream components whose corresponding definitions are in several different headers, including <sstream>…

interface classes

Person类便是一个接口
代价
- 使用pimpl要多一个指针,并且在使用时需要经过一次转调,开销大
- 使用接口的需要虚函数,内存占用同样多出来一个虚指针,虚函数的调用也需要查找
item32:确定public继承建模出is-a关系
class A : public B
所以A is a B。A一定是B
凡是基类可以包含的内容,派生类也应该可以包含。
item33:避免遮掩继承而来的名称
public
名称遮掩:
int x; // global variable
void fun(){
double x; // local variable
cin >> x; // local x
}

B.func()发生了名称遮蔽,将A的覆盖掉了。违反了item32的is-a的关系。
此时可以做出以下更改:

private:
使用私有继承,func1便成为了D的私有成员,此时外部访问func1会出错。使用using可以给D访问权限。使用using C::func1声明将类C中的名称func1带入类D的作用域,使类D的成员函数可以访问它。

如果我们只需要让无参的func1对外公开,使用using就达不到我们想要的结果,此时不论无参还是有参函数都不会报错。
我们只能自己手动重写调用:
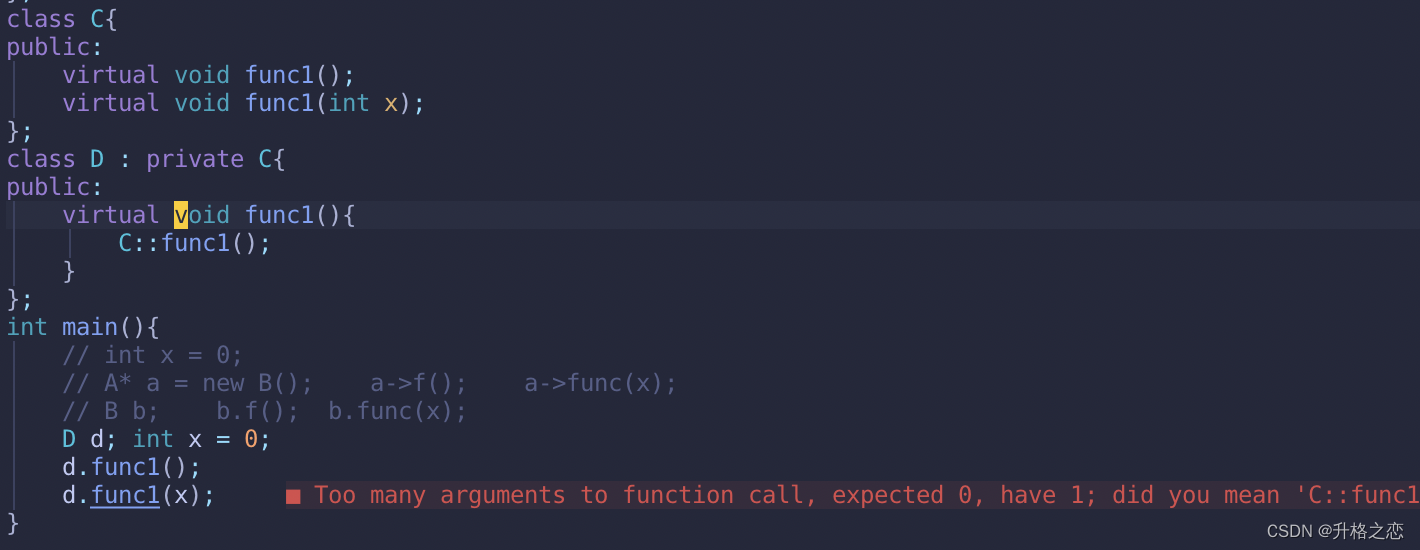
或者这样写:
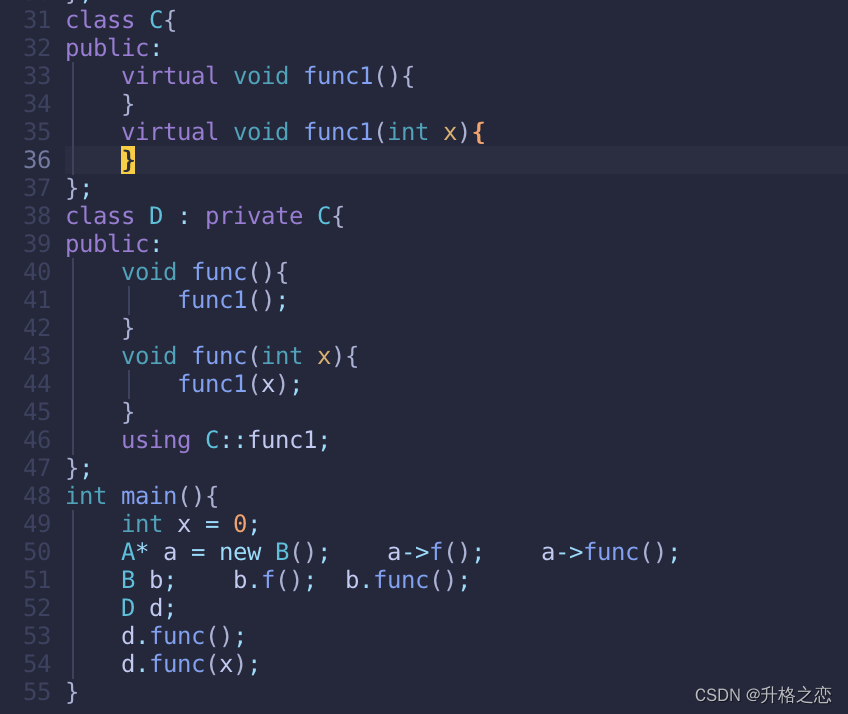
item34:区分接口继承和实现继承
纯虚函数:要求子类必须复写实现方法。
带有函数体的虚函数:不强制要求实现继承
普通函数:强制接口继承且实现继承






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结