您现在的位置是:首页 >其他 >【论文阅读】Robustness in Reinforcement Learning网站首页其他
【论文阅读】Robustness in Reinforcement Learning
原文为 Trustworthy Reinforcement Learning Against Intrinsic Vulnerabilities: Robustness, Safety, and Generalizability,是 2022 年 CMU 发表的综述文章。
本文主要关注文章的第二部分即鲁棒性
1. 概述
鲁棒性主要解决的问题是提高策略在面对不确定性或者对抗性攻击场景时的最差性能。我们在训练策略的时候通常是在模拟环境,但执行时会在真实环境中,真实环境往往存在参数不同从而导致策略执行出现问题,此时鲁棒性就是避免造成灾难故障的重要性能。
2. 鲁棒性问题定义
除了常规RL的MDP过程,还定义了不确定变量U,U可以是状态变量S、动作变量A、奖励函数R或者转换函数P,鲁棒性RL算法旨在找到一种策略,使不确定变量U的最差性能最大化
max
π
min
U
∈
F
u
J
M
(
π
,
U
)
max_{pi}min_{Uin F_u} J_M(pi,U)
maxπminU∈FuJM(π,U)
J
M
(
π
,
U
)
J_M(pi,U)
JM(π,U)代表期望累积回报
2.1 对于不确定的观测状态
大多数鲁棒RL方法旨在鲁棒处理观测状态和实际状态之间的不匹配。在实际环境中,由于传感器错误或传感器容量有限,会出现,一般来说,实际状态和状态观察之间的不匹配会降低策略的性能,甚至可能在安全关键情况下导致灾难性故障。实际观测状态为 s t s_t st,但得到的观测状态为 s ^ hat s s^,鲁棒性RL在观测状态下得到动作a,在实际状态下通过转换函数得到下一个状态。
在测试阶段,攻击者可以通过引诱目标agent进入设定的目标对抗状态
s
a
d
v
s^{adv}
sadv来破坏性能,或者引诱agent进行错误的动作选择即
π
(
s
^
)
≠
π
(
s
)
pi(hat s)
e pi(s)
π(s^)=π(s)
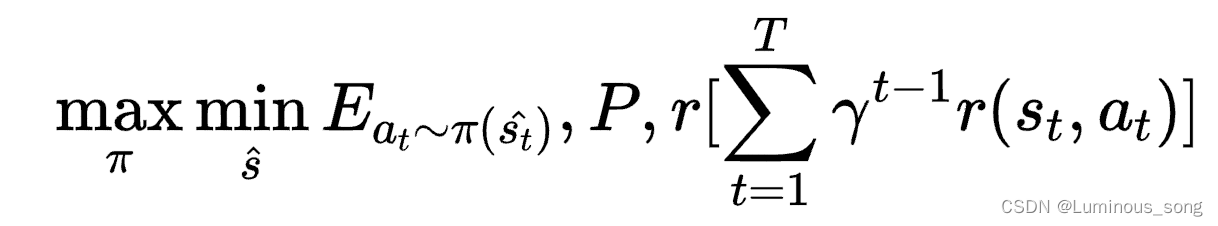
2.2 对于不确定的动作状态
针对行动不确定性的鲁棒RL侧重于RL代理生成的行动与执行的行动之间的差异,也就是由于来自现实世界中的致动器噪声、有限的功率范围或致动器故障,导致智能体实际动作与策略产生动作产生差异即 a ^ = v ( π ( s ) ) hat a = v(pi(s)) a^=v(π(s))。鲁棒RL要在存在这种差异的情况下,使策略的最差性能保持在较高水平。
2.3 对于不确定转移函数和奖励函数
由于训练和测试环境存在差异从而导致转换函数和奖励函数具有差异,在这种情况下 U = ( P , r ) 或者 U = r U=(P,r)或者U=r U=(P,r)或者U=r
- 环境差异
对于环境差异,分布鲁棒性分布对转换过程和奖励的分布信息进行编码,来平衡性能和鲁棒性,分布式鲁棒MDP公式可以通过平衡性能和最坏情况下的性能来产生不那么保守的策略
3. 鲁棒性RL方法
3.1 与对手进行鲁棒训练
对抗性训练是传统监督学习中最有效的防御方法之一。在本小节中,我们将讨论一种类型的对抗性训练策略,即用局部对抗性攻击获得的损失的下界(累积奖励的上界)来训练RL代理。
-
State Observation
对于观测状态的不确定性,直接向RL代理的状态向量或者梯度更新中添加扰动,对抗性训练可以是对手与agent代理并行训练,也可以是预先训练好的对手 -
Action
目前提出了两个针对动作不确定性的鲁棒性标准:PR-MDP和NR-MDP分别考虑了偶尔的对抗性动作和持续的对抗性动作 -
Transitions and rewards
RARL是目前处理环境不确定性最流行的框架之一,RARL将环境的差异设定为意外玩家施加的额外干扰,提出了交替优化对手和agent的策略,直到收敛。此外还有ARPL方法,利用自然发生的对抗性场景学习来获得策略的鲁棒性
3.2 鲁棒性松弛训练
与上一节设置累计奖励上界相反,本节设置累计奖励的下界,可以通过relaxation的方法获得
3.3 正则化
在鲁棒RL中可以利用正则化来增强策略的鲁棒性,正则化可以鼓励策略学习更加平滑,防止在状态观测的扰动下策略也发生剧烈变化
3.4 约束优化
使用模糊集来解决最小化问题,例如WR2L,在训练agent时,假设环境对手在Wasserstein范围内添加扰动,直到收敛。
3.5 模型估计
-
Transitions
将EPOpt与对抗性训练结合,EPOpt使用模型集合对源域进行建模。并未源域找到稳健的策略,在给定从目标域收集的数据中细化模型集合 -
Rewards
通过考虑有限奖励集,使用融合矩阵对不确定的奖励进行建模来近似真实的奖励信号。AIRL就是一种基于对抗性学习的反向学习算法,近似得出奖励函数
鲁棒测试方法
-
被动选择防御行为
CARRL通过将最差的观测结果传递给训练过的DNN模型,来选择最差观测扰动下的行为 -
主动检测潜在攻击
这种类型的方法手贱检测对抗性攻击或者预测有利状态/奖励函数,然后根据已经训练好的模型提供关于行动的建议






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结