您现在的位置是:首页 >其他 >DAB-Deformable-DETR代码学习记录之模型构建网站首页其他
DAB-Deformable-DETR代码学习记录之模型构建
DAB-DETR的作者在Deformable-DETR基础上,将DAB-DETR的思想融入到了Deformable-DETR中,取得了不错的成绩。今天博主通过源码来学习下DAB-Deformable-DETR模型。
首先我么看下Deformable的创新之处:
Deformable-DETR创新
多尺度融合
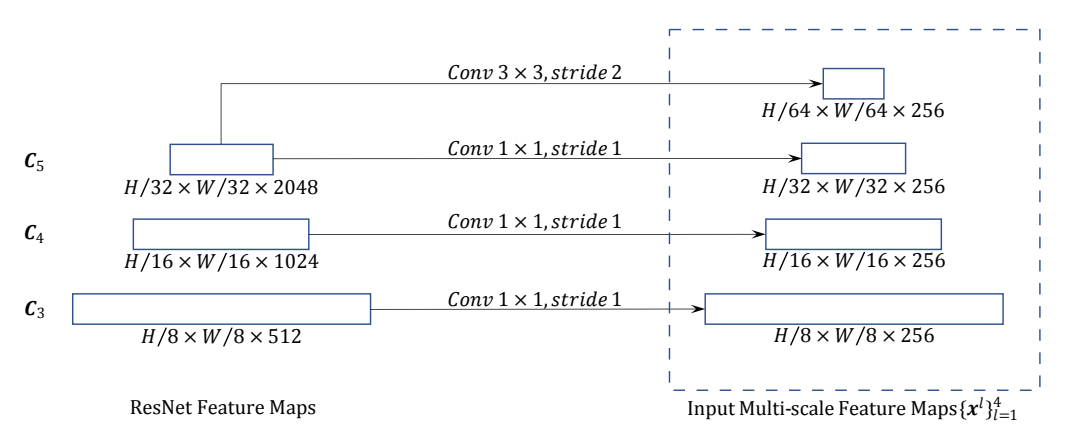
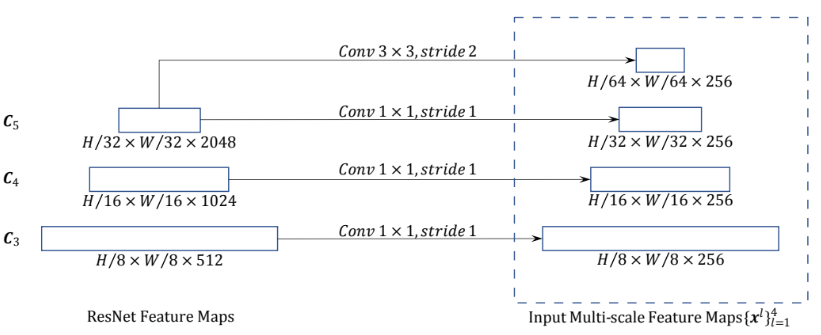
首先便是老生常谈但却不得不提的多尺度融合问题,作者将ResNet50的后三层作为输出,并将其融合在一起送入Transformer。
可变形注意力机制
这是Deformable-DETR的主要创新点,即可变形的注意力。详细介绍可以看博主这篇博文:
接下来我们便从源码入手来学习DAB-Deformable-DETR
DAB-Deformable-DETR整体模型
首先来到DAB-Deformable-DETR的模型构建文件DAB-Deformable-DETR.py
通过预处理的样本数据samples:
我们主要看两个数据,分别是tensors,这是送入DAB-Deformable-DETR模型的样本数据,为torch.Size([2, 3, 608, 760]),分别代表batch-size=2,channel=3,width=608,height=760。
其次便是mask,这是图像进行尺寸统一后进行填充后得到的掩码信息,其表示哪些是填充的部分,哪些是图像本身,为 torch.Size([2, 608, 760])。

随后将样本数据送入backbone,原本是resnet50,但这里博主由于显存限制便把backbone改为resnet18。
features, pos = self.backbone(samples)
得到features有三个,分别为 Resnet8 倒数3层的输出结果,对应论文中第一个创新点:多尺度特征信息。此外还有对应的位置编码信息pos。(pos数据的维度信息与feature相同)
feature数据的维度信息分别为:torch.Size([2, 256, 76, 95]) torch.Size([2, 256, 38, 48]) torch.Size([2, 256, 19, 24])
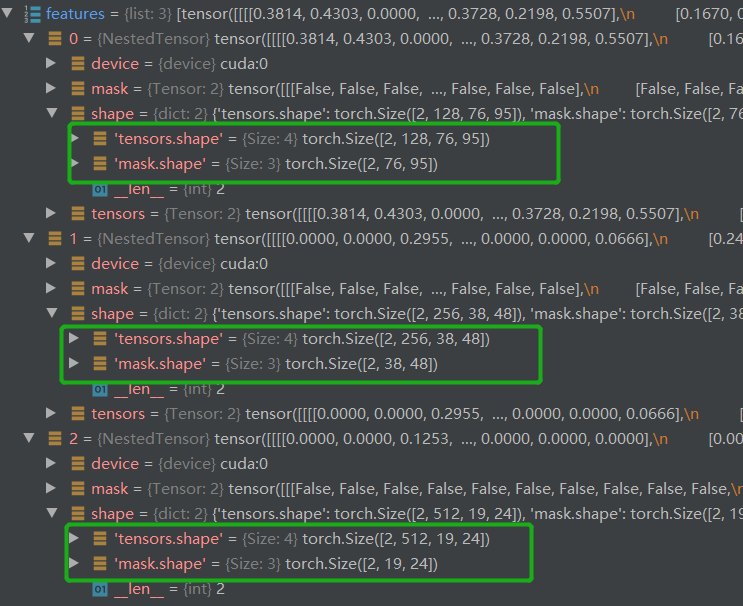
随后对feature进行处理,获得送入Transformer模块的src与mask。获得的srcs包含三个数据,即分别为torch.Size([2, 256, 76, 95]) torch.Size([2, 256, 38, 48]) torch.Size([2, 256, 19, 24]) ,mask相比只是少了通道维度。
srcs = []
masks = []
for l, feat in enumerate(features):
src, mask = feat.decompose()
srcs.append(self.input_proj[l](src))
masks.append(mask)
assert mask is not None
紧接着对feature最后一层进行处理,将其生成src,初次之外还生成了对应的mask,添加到srcs。其对应下图:
if self.num_feature_levels > len(srcs):
_len_srcs = len(srcs)
for l in range(_len_srcs, self.num_feature_levels):
if l == _len_srcs:
src = self.input_proj[l](features[-1].tensors)
else:
src = self.input_proj[l](srcs[-1])
m = samples.mask
mask = F.interpolate(m[None].float(), size=src.shape[-2:]).to(torch.bool)[0]
pos_l = self.backbone[1](NestedTensor(src, mask)).to(src.dtype)
srcs.append(src)
masks.append(mask)
pos.append(pos_l)
其中mask = F.interpolate(m[None].float(), size=src.shape[-2:]).to(torch.bool)[0],m为torch.Size([2, 608, 760]),m 转化为与 src 相同大小的mask为 torch.Size([2, 10, 12])
在该项目中,不启用双阶段,并使用dab方法,紧接着执行下面的步骤。
得到 refanchor:torch.Size([300, 4]) tgt_embed:torch.Size([300, 256]),随后将其拼接得到
query_embeds torch.Size([300, 260])(按照dim=1维度拼接)
if self.num_patterns == 0:
tgt_embed = self.tgt_embed.weight # nq, 256
refanchor = self.refpoint_embed.weight # nq, 4
query_embeds = torch.cat((tgt_embed, refanchor), dim=1)
随后将数据送入Transformer模型,得到输出结果如下:
hs, init_reference, inter_references, enc_outputs_class, enc_outputs_coord_unact = self.transformer(srcs, masks, pos, query_embeds)
hs:torch.Size([6, 2, 300, 256]) 语义特征信息
init_reference:torch.Size([300, 4])
inter_references:torch.Size([6, 2, 300, 4]) 参考点box
enc_outputs_class:None
enc_outputs_coord_unact:None

最终,hs还要经过分类头与回归头,回归头获得的box与inter_references相加。
outputs_classes = []#存放分类结果
outputs_coords = []#存放box结果
for lvl in range(hs.shape[0]):#6层
if lvl == 0:
reference = init_reference#初始化的,没变
else:
reference = inter_references[lvl - 1]
reference = inverse_sigmoid(reference)#反归一化
outputs_class = self.class_embed[lvl](hs[lvl])#6个分类头,各自预测各自的 torch.Size([2, 300, 91])
tmp = self.bbox_embed[lvl](hs[lvl])#6个回归头 torch.Size([2, 300, 4])
if reference.shape[-1] == 4:
tmp += reference#预测出box结果加上reference,默认为4
else:
assert reference.shape[-1] == 2
tmp[..., :2] += reference
outputs_coord = tmp.sigmoid()#获取输出box结果并进行归一化
outputs_classes.append(outputs_class)
outputs_coords.append(outputs_coord)
outputs_class = torch.stack(outputs_classes)#凭借输出结果
outputs_coord = torch.stack(outputs_coords)
reference = inverse_sigmoid(reference)后的结果:

outputs_coord = tmp.sigmoid()获取输出box结果并进行归一化

最终获得outputs_classes:list值有6个,每个为 torch.Size([2, 300, 91])

经过outputs_class = torch.stack(outputs_classes)后为:torch.Size([6, 2, 300, 91])

outputs_coord也预祝同理,变为 torch.Size([6, 2, 300, 4])
最终将结果返回即可。由此可见,DAB-Deformable-DETR的外部逻辑并没有发生太大变化,我们重点来看看Transformer内部如何变化。
Transformer模块
首先由于在骨干网络模块引入了多尺度特征,那么在Encoder前的处理也发生了变化。
进入Transformer模块是由此开始的。
hs, init_reference, inter_references, enc_outputs_class, enc_outputs_coord_unact = self.transformer(srcs, masks, pos, query_embeds)
传入的参数为:
srcs:经过backbone获得的语义特征信息,list形式,共4个值,分别为:
torch.Size([2, 256, 76, 95]) torch.Size([2, 256, 38, 48])
torch.Size([2, 256, 19, 24]) torch.Size([2, 256, 10, 12])`

masks:掩码值,有4个,每个大小与对应层的src相同,只是没有通道维度,如 mask0:torch.Size([2, 76, 95]),mask1:torch.Size([2, 38, 48])

pos:位置编码,维度与srcs相同。
query_embeds:torch.Size([300, 260]),这个是通过下面代码拼接得到的。
tgt_embed = self.tgt_embed.weight # nq, 256
refanchor = self.refpoint_embed.weight # nq, 4
query_embeds = torch.cat((tgt_embed, refanchor), dim=1)
随后我们进行Transformer模块,首先是先对输入的backbone数据进行预处理,先定义变量:
src_flatten = []
mask_flatten = []
lvl_pos_embed_flatten = []
spatial_shapes = []
对srcs,masks,pos进行转换:
注意:lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)(可学习的参数)
self.level_embed = nn.Parameter(torch.Tensor(num_feature_levels, d_model))
self.level_embed[lvl]是Transformer模块自定义的参数,为【4,256】,取其中一个即为256,随后经过view变为1X1X256,则可与pos_embed(torch.Size([2, 7220, 256]))相加,即在前2X7220中,每个256相加。相加完维度lvl_pos_embed与pos_embed相同,为torch.Size([2, 7220, 256])
for lvl, (src, mask, pos_embed) in enumerate(zip(srcs, masks, pos_embeds)):
bs, c, h, w = src.shape
spatial_shape = (h, w)
spatial_shapes.append(spatial_shape)
src = src.flatten(2).transpose(1, 2)# 由bs,c,h,w变为bs, hw, c
mask = mask.flatten(1)#由bs,h,w变为 bs, hw
pos_embed = pos_embed.flatten(2).transpose(1, 2)#由bs,c,h,w变为bs, hw, c
lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
lvl_pos_embed_flatten.append(lvl_pos_embed)
src_flatten.append(src)
mask_flatten.append(mask)
最终得到转换后的src mask pos (其实就是做了个维度转换)。如下:

随后src在第二维进行拼接,即将所有的src(共四层,list形式)变为 torch.Size([2, 9620, 256])
同理,mask,pos也做相同变换。
src_flatten = torch.cat(src_flatten, 1) # bs, sum{hxw}, c
mask_flatten = torch.cat(mask_flatten, 1) # bs, sum{hxw}
lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
spatial_shapes:[(76, 95), (38, 48), (19, 24), (10, 12)],truple格式经转换:
spatial_shapes = torch.as_tensor(spatial_shapes, dtype=torch.long, device=src_flatten.device)
得到Tensor格式
tensor([[76, 95],
[38, 48],
[19, 24],
[10, 12]], device=‘cuda:0’)
获取每个leavel的初始index(我们将4个level的值拼接在一起了)
level_start_index = torch.cat((spatial_shapes.new_zeros((1, )), spatial_shapes.prod(1).cumsum(0)[:-1]))
得到:level_start_index 为 tensor([ 0, 7220, 9044, 9500], device=‘cuda:0’)
valid_ratios = torch.stack([self.get_valid_ratio(m) for m in masks], 1)
get_valid_ratio方法定义如下:该方法的作用其实是返回一个扩张比例值(即占长宽比例),维度为torch.Size([2, 4, 2]),即batch=2,4为每个layer,2为长宽比例
def get_valid_ratio(self, mask):
_, H, W = mask.shape
valid_H = torch.sum(~mask[:, :, 0], 1)
valid_W = torch.sum(~mask[:, 0, :], 1)
valid_ratio_h = valid_H.float() / H
valid_ratio_w = valid_W.float() / W
valid_ratio = torch.stack([valid_ratio_w, valid_ratio_h], -1)
return valid_ratio

完整代码如下:
src_flatten = []
mask_flatten = []
lvl_pos_embed_flatten = []
spatial_shapes = []
for lvl, (src, mask, pos_embed) in enumerate(zip(srcs, masks, pos_embeds)):
bs, c, h, w = src.shape
spatial_shape = (h, w)
spatial_shapes.append(spatial_shape)
src = src.flatten(2).transpose(1, 2) # bs, hw, c
mask = mask.flatten(1) # bs, hw
pos_embed = pos_embed.flatten(2).transpose(1, 2) # bs, hw, c
lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
lvl_pos_embed_flatten.append(lvl_pos_embed)
src_flatten.append(src)
mask_flatten.append(mask)
src_flatten = torch.cat(src_flatten, 1) # bs, sum{hxw}, c
mask_flatten = torch.cat(mask_flatten, 1) # bs, sum{hxw}
lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
spatial_shapes = torch.as_tensor(spatial_shapes, dtype=torch.long, device=src_flatten.device)
level_start_index = torch.cat((spatial_shapes.new_zeros((1, )), spatial_shapes.prod(1).cumsum(0)[:-1]))
valid_ratios = torch.stack([self.get_valid_ratio(m) for m in masks], 1)
Encoder模块
随后将数据送入Encoder模块
memory = self.encoder(src_flatten, spatial_shapes, level_start_index, valid_ratios, lvl_pos_embed_flatten, mask_flatten)
首先看看送入的参数值:
src_flatten:torch.Size([2, 9620, 256]) 展平后的src(backbone的提取结果)
spatial_shapes:各个层的大小。
tensor([[76, 95],
[38, 48],
[19, 24],
[10, 12]], device='cuda:0')
level_start_index:tensor([ 0, 7220, 9044, 9500], device=‘cuda:0’)
valid_ratios:torch.Size([2, 4, 2]) 各层的缩放比例:
tensor([[[1.0000, 1.0000],
[1.0000, 1.0000],
[1.0000, 1.0000],
[1.0000, 1.0000]],
[[0.8421, 0.8421],
[0.8542, 0.8421],
[0.8750, 0.8421],
[0.9167, 0.9000]]], device='cuda:0')
上面比例中第一张全为1,说明其比较大,第二张是padding到与第一张相同大小。
lvl_pos_embed_flatten:torch.Size([2, 9620, 256]) 展平后的位置编码信息
mask_flatten:torch.Size([2, 9620]) 展平后的掩码信息
进入Encoder中,该模块从整体结构上没有变化:
生成参考点坐标。
reference_points = self.get_reference_points(spatial_shapes, valid_ratios, device=src.device)
得到 reference_points 为 torch.Size([2, 9620, 4, 2]) 其各维度代表的含义为:batch=2
4个WH相加后为9620,4为4层,2为x,y值。
生成时,以0.5开始,以1为间隔,减去0.5结束,生成网格点(参考点坐标),为防止网格点不存在,还要乘以其缩放比例。
meshgrid 函数用来生成网格矩阵,可以是二维网格矩阵
linspace函数:通过定义均匀间隔创建数值序列。指定间隔起始点、终止端,以及指定分隔值总数(包括起始点和终止点);最终函数返回间隔类均匀分布的数值序列。请看示例:
np.linspace(start = 0, stop = 100, num = 5)
def get_reference_points(spatial_shapes, valid_ratios, device):
reference_points_list = []
for lvl, (H_, W_) in enumerate(spatial_shapes):
ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H_ - 0.5, H_, dtype=torch.float32, device=device),
torch.linspace(0.5, W_ - 0.5, W_, dtype=torch.float32, device=device))
ref_y = ref_y.reshape(-1)[None] / (valid_ratios[:, None, lvl, 1] * H_)
ref_x = ref_x.reshape(-1)[None] / (valid_ratios[:, None, lvl, 0] * W_)
ref = torch.stack((ref_x, ref_y), -1)
reference_points_list.append(ref)
reference_points = torch.cat(reference_points_list, 1)
reference_points = reference_points[:, :, None] * valid_ratios[:, None]
return reference_points
对应该部分的网格点参考坐标。
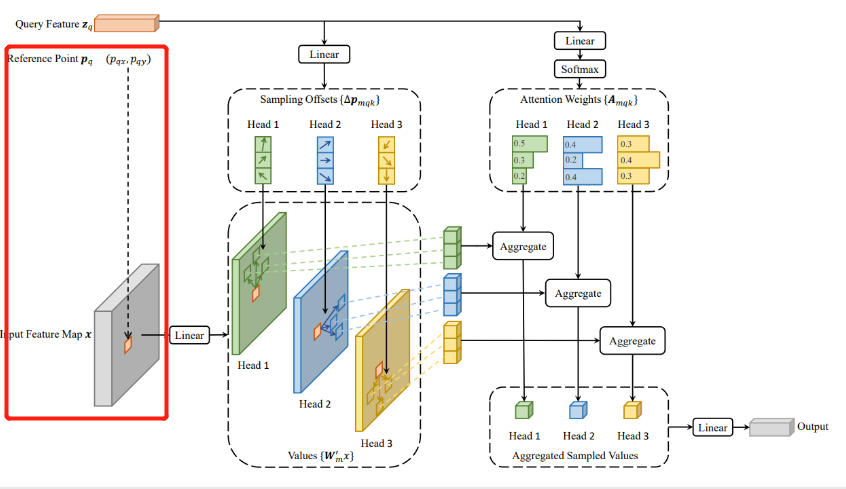
EncoderLayer模块
开启循环送入EncoderLayer模块,首先查看送入的参数信息:
在一层循环时:
output 为 torch.Size([2, 9620, 256]),即backbone提取的特征信息。
pos:位置编码信息 torch.Size([2, 9620, 256])
reference_points:参考点 torch.Size([2, 9620, 4, 2])
spatial_shapes:torch.Size([4, 2]) 其值为:
tensor([[76, 95],
[38, 48],
[19, 24],
[10, 12]], device='cuda:0')
level_start_index:tensor([ 0, 7220, 9044, 9500], device=‘cuda:0’)
padding_mask:torch.Size([2, 9620])

output = layer(output, pos, reference_points, spatial_shapes, level_start_index, padding_mask)
进入EncoderLayer后,进行自注意力的计算,由于这里使用了Deformable-Attention(可变形注意力),即self.self_attn,该部分的注意力计算重新进行了编写。
src2 = self.self_attn(self.with_pos_embed(src, pos), reference_points, src, spatial_shapes, level_start_index, padding_mask)
src = src + self.dropout1(src2)
src = self.norm1(src)
src = self.forward_ffn(src)
return src
随后将得到结果 src2 为 torch.Size([2, 9620, 256]),之后便是与普通的 EncoderLayer 完全相同了。最终返回 src 为 torch.Size([2, 9620, 256])
可变形注意力模块
终于到了最关键的部分了:可变形注意力。
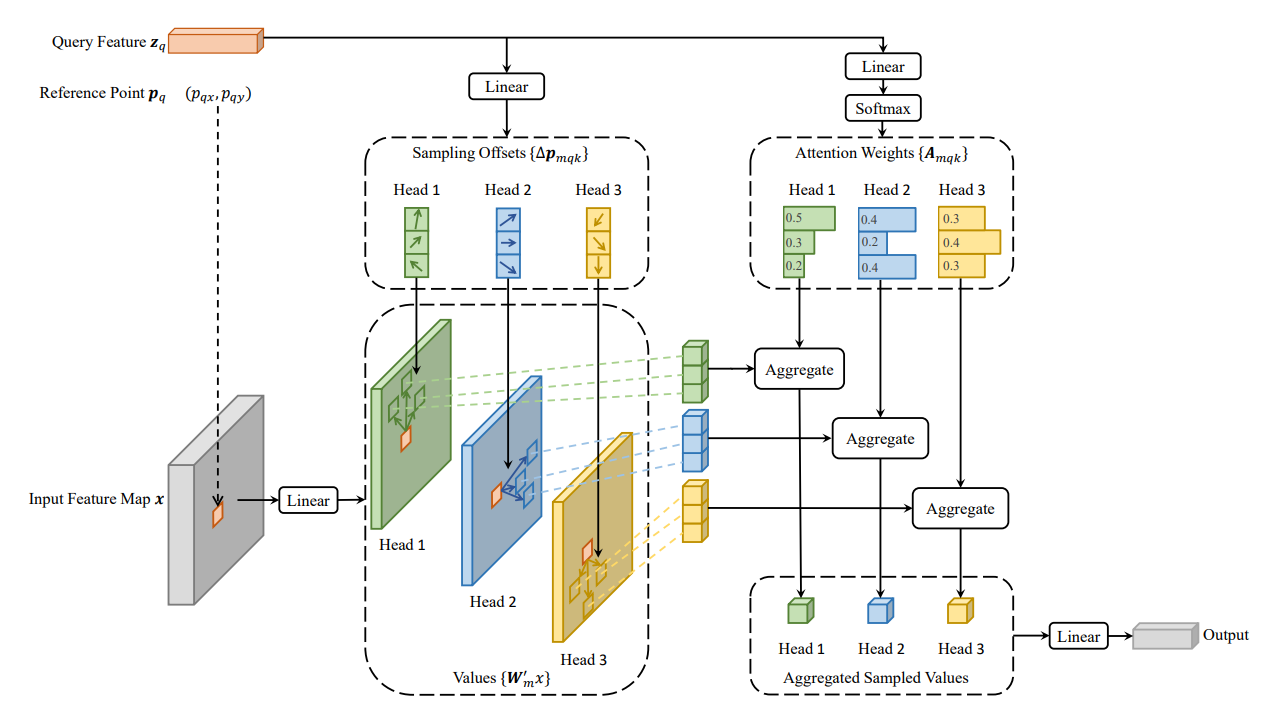
可变形注意力的思想很简单,即每个query在每个head上采样K个位置,只需和这些位置的特征进行交互,不同于detr那样,每个query需要与全局位置进行交互。需要注意的是,位置偏移量Δp mqx 是由query经过全连接得到的,注意力权重也是由query经全连接层得到的,同时在K个采样点之间进行权重归一化
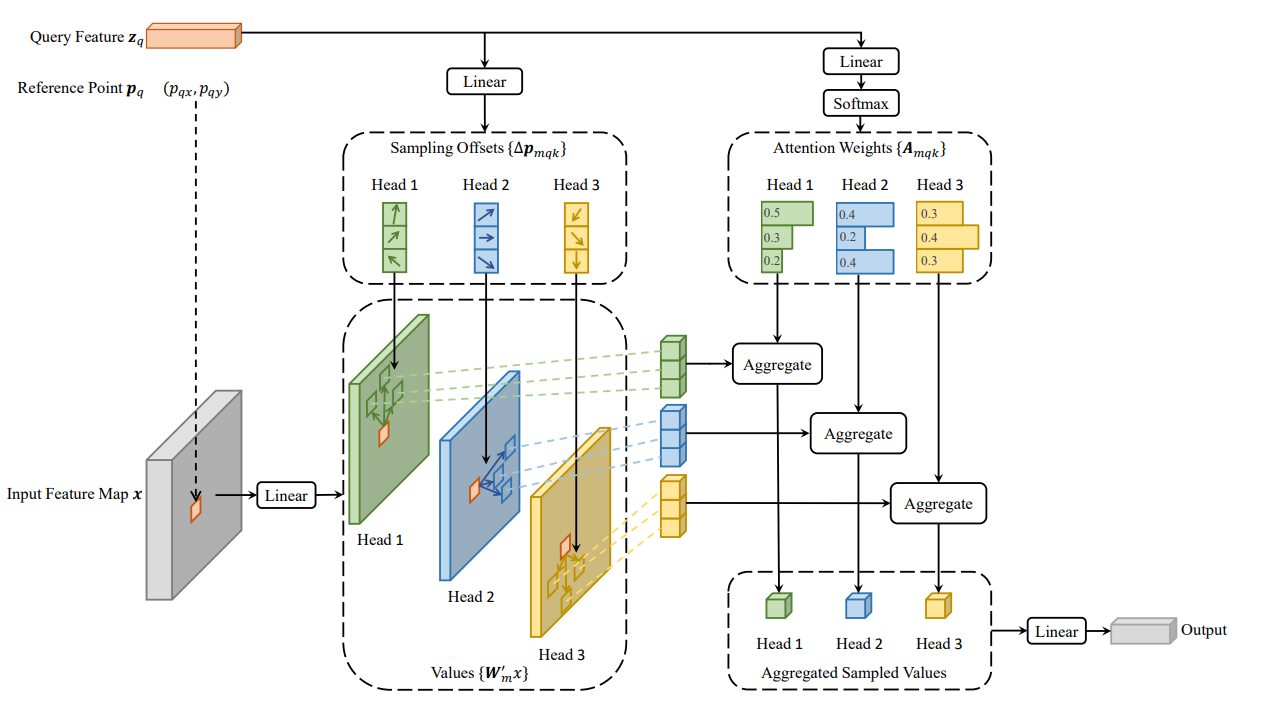
src2 = self.self_attn(self.with_pos_embed(src, pos), reference_points, src, spatial_shapes, level_start_index, padding_mask)
我们来看看送入self_attn的参数信息:
def forward(self, query, reference_points, input_flatten, input_spatial_shapes, input_level_start_index, input_padding_mask=None):
参考点坐标
首先是位置编码信息与经过backbone提取的特征信息进行相加。
with_pos_embed(src, pos)
reference_points:torch.Size([2, 9620, 4, 2])这里我们记住,reference_points只是一个坐标值而已,没有实际语义信息,或者是个网格,是要套在特征图上使用的。
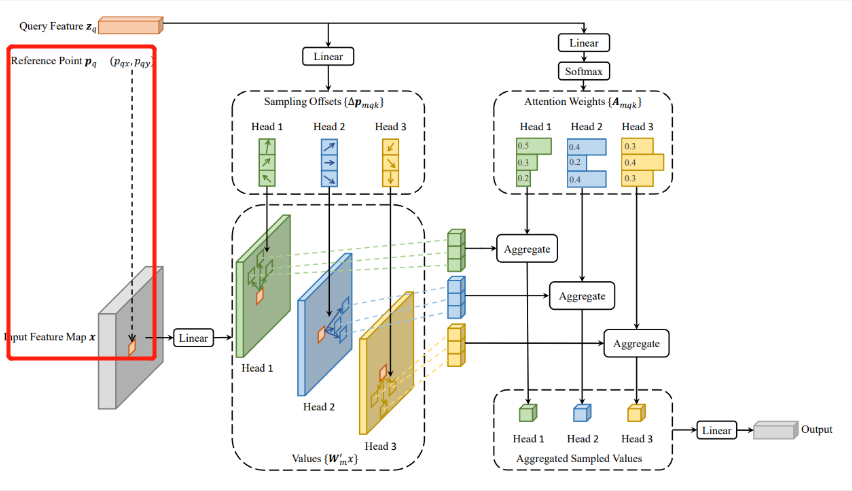
spatial_shapes:torch.Size([4, 2])
tensor([[76, 95],
[38, 48],
[19, 24],
[10, 12]], device='cuda:0')
src:torch.Size([2, 9620, 256])
padding_mask:torch.Size([2, 9620])
def with_pos_embed(tensor, pos):
return tensor if pos is None else tensor + pos
特征图value
进入ms_deform_attn.py 进行计算:
首先 query 为 torch.Size([2, 9620, 256])
input_flatten即src ,维度为 torch.Size([2, 9620, 256])
value = self.value_proj(input_flatten)
其对应下图操作:
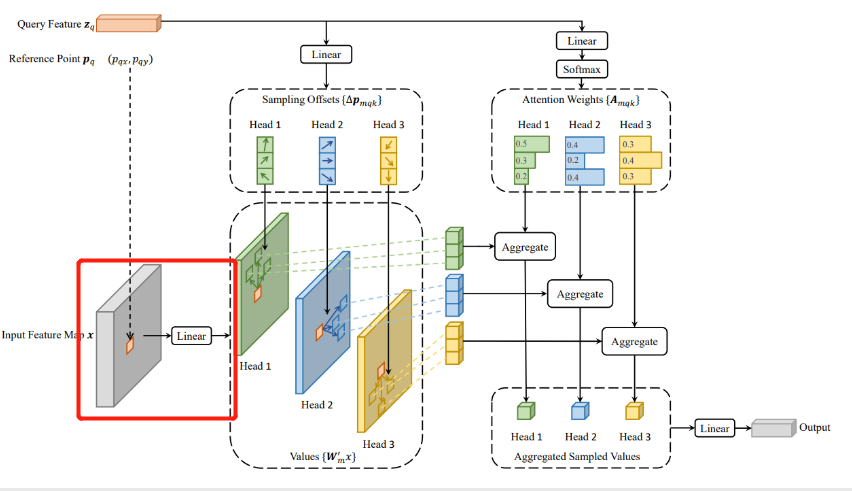
masked_fill方法有两个参数,mask和value,mask是一个pytorch张量(Tensor),元素是布尔值,value是要填充的值,填充规则是mask中取值为True位置对应于self的相应位置用value填充。
if input_padding_mask is not None:
value = value.masked_fill(input_padding_mask[..., None], float(0))
对value进行维度变换为 torch.Size([2, 9620, 8, 32])
value = value.view(N, Len_in, self.n_heads, self.d_model // self.n_heads)
偏移量与权重值
sampling_offsets = self.sampling_offsets(query).view(N, Len_q, self.n_heads, self.n_levels, self.n_points, 2)
attention_weights = self.attention_weights(query).view(N, Len_q, self.n_heads, self.n_levels * self.n_points)
attention_weights = F.softmax(attention_weights, -1).view(N, Len_q, self.n_heads, self.n_levels, self.n_points)
上述代码对应下面的部分,即将query通过linear获得:
偏移量sampling_offsets(该偏移量是在特征图上的偏移量):torch.Size([2, 9620, 8, 4, 4, 2]),batch=2,4个WH之和,8个头,4个特征层,4个采样点(图中画了3个),2为偏移量坐标(x,y)
通过linear获得权重值。
attention_weights,最开始时为 torch.Size([2, 9620, 8, 16]) ,16代表的是4个特征层与4个采样点相乘,后面经过softmax后变为 torch.Size([2, 9620, 8, 4,4])
从这里可以看出:deformable atten不需要通过Q点乘K来获取attention_weight,其attention_weight是通过object query学出来的。
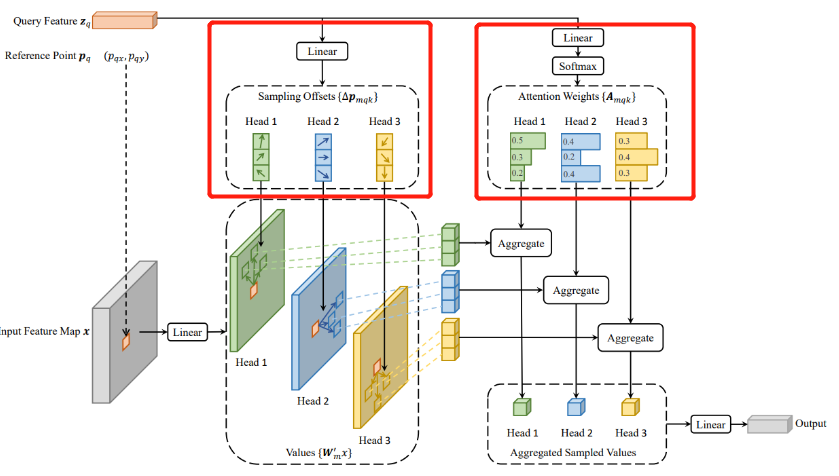
对应的全连接层:
self.sampling_offsets = nn.Linear(d_model, n_heads * n_levels * n_points * 2)
随后判断采样点最后的一维是否为2,这里reference_points为 torch.Size([2, 9620, 4, 2]),sampling_offsets 为 torch.Size([2, 9620, 8, 4, 4, 2]) ,offset_normalizer 为 torch.Size([4, 2])
即参考点的坐标加上偏移量(这里的偏移量还要除以特征图的大小),从而得到真正的采样点的位置。
if reference_points.shape[-1] == 2:
offset_normalizer = torch.stack([input_spatial_shapes[..., 1], input_spatial_shapes[..., 0]], -1)
sampling_locations = reference_points[:, :, None, :, None, :]
+ sampling_offsets / offset_normalizer[None, None, None, :, None, :]
第一句代码为对 input_spatial_shapes的宽高进行位置调换为高宽,如原来为:
tensor([[76, 95],
[38, 48],
[19, 24],
[10, 12]], device='cuda:0')
变为offset_normalizer:
tensor([[95, 76],
[48, 38],
[24, 19],
[12, 10]], device='cuda:0')
第二句为求出真正的参考点坐标。其中[:, :, None, :, None, :] 中None的作用是升维,因为其要与sampling_offsets进行加法运算,而其为 torch.Size([2, 9620, 4, 2]) ,而 sampling_offsets 为 torch.Size([2, 9620, 8, 4, 4, 2]) ,在相加时注意力头不考虑(所有的头都加上),4个采样点也需要全部加上,故扩充时使用 [:, :, None, :, None, :] 。同理,由于其偏移值为在特征图上的(src)所以要除以其变换后的宽高值(层数对应层数,x,y对应宽高)
最终我们将获取到的上述值送入CUDA的实现(可以认为是注意力值的计算)
output = MSDeformAttnFunction.apply(
value, input_spatial_shapes, input_level_start_index, sampling_locations, attention_weights, self.im2col_step)
output输出结果为 torch.Size([2, 9620, 256])

输出结果
最后通过一个全连接层将计算结果输出:
output = self.output_proj(output)
其转换后结果依旧为:torch.Size([2, 9620, 256])
全连接层的定义:
self.output_proj = nn.Linear(d_model, d_model)
完成的便是下面过程:
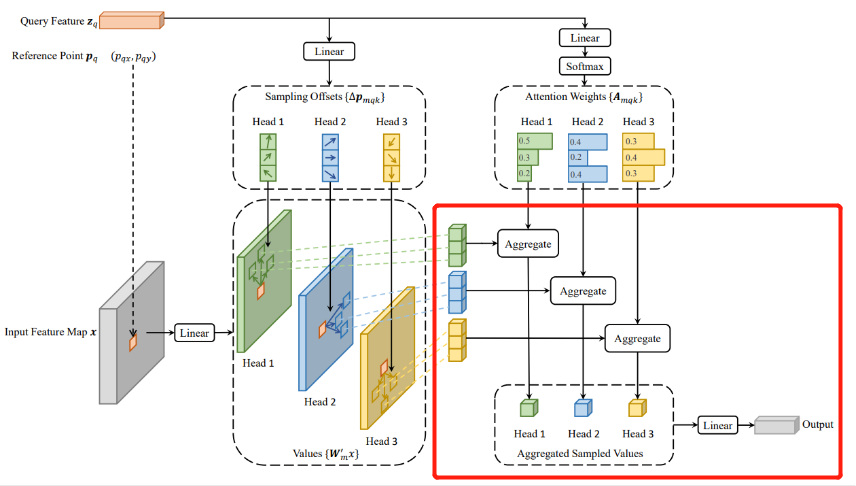
经过上面一系列过程,便完成了下面公式的计算:
多头下注意力计算:
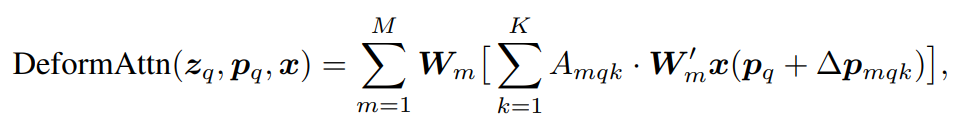
多尺度多头注意力计算:
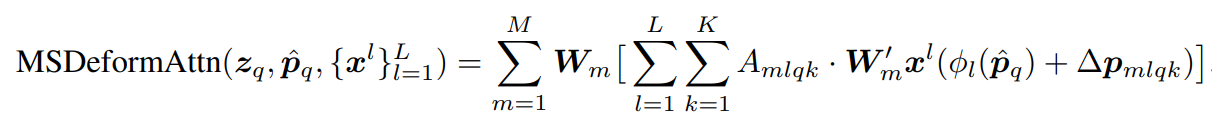
Two-Stage 双阶段
经过一系列运算,memory为encoder的输出结果 torch.Size([2, 9620, 256])
memory = self.encoder(src_flatten, spatial_shapes, level_start_index, valid_ratios, lvl_pos_embed_flatten, mask_flatten)
随后判断是否开启双阶段,这是Deformable-DETR的第二个创新点。
memory 为 torch.Size([2, 9620, 256])
memory_padding_mask 为 torch.Size([2, 9620])
spatial_shapes 为
tensor([[76, 95],
[38, 48],
[19, 24],
[10, 12]], device='cuda:0')
gen_encoder_output_proposals该方法是对encoder的输出值memory进行一系列的处理,最终将用于Decoder中的参考点初始化。
def gen_encoder_output_proposals(self, memory, memory_padding_mask, spatial_shapes):
N_, S_, C_ = memory.shape#batch_size ,长度,通道数
base_scale = 4.0 #多尺度数为4
proposals = []
_cur = 0
for lvl, (H_, W_) in enumerate(spatial_shapes):
mask_flatten_ = memory_padding_mask[:, _cur:(_cur + H_ * W_)].view(N_, H_, W_, 1) #按照尺度大小得出mask值 并转换维度为:torch.Size([2, 76, 95, 1])
valid_H = torch.sum(~mask_flatten_[:, :, 0, 0], 1) #计算高有多少为真 tensor([76, 64], device='cuda:0') 第一张图片最大,全部为真,第二张图片64为真
valid_W = torch.sum(~mask_flatten_[:, 0, :, 0], 1) #计算宽多少为真tensor([95, 80], device='cuda:0')
grid_y, grid_x = torch.meshgrid(torch.linspace(0, H_ - 1, H_, dtype=torch.float32, device=memory.device),
torch.linspace(0, W_ - 1, W_, dtype=torch.float32, device=memory.device))#生成矩阵网格点坐标
grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1)
#unsqueeze(-1) 再加一层维度
scale = torch.cat([valid_W.unsqueeze(-1), valid_H.unsqueeze(-1)], 1).view(N_, 1, 1, 2)
grid = (grid.unsqueeze(0).expand(N_, -1, -1, -1) + 0.5) / scale
wh = torch.ones_like(grid) * 0.05 * (2.0 ** lvl)
proposal = torch.cat((grid, wh), -1).view(N_, -1, 4)
proposals.append(proposal)
_cur += (H_ * W_)
output_proposals = torch.cat(proposals, 1)
output_proposals_valid = ((output_proposals > 0.01) & (output_proposals < 0.99)).all(-1, keepdim=True)
output_proposals = torch.log(output_proposals / (1 - output_proposals))
output_proposals = output_proposals.masked_fill(memory_padding_mask.unsqueeze(-1), float('inf'))
output_proposals = output_proposals.masked_fill(~output_proposals_valid, float('inf'))
output_memory = memory
output_memory = output_memory.masked_fill(memory_padding_mask.unsqueeze(-1), float(0))
output_memory = output_memory.masked_fill(~output_proposals_valid, float(0))
output_memory = self.enc_output_norm(self.enc_output(output_memory))
return output_memory, output_proposals
最终输出值
output_memory:torch.Size([2, 9620, 256])

output_proposals:torch.Size([2, 9620, 4])

开始二阶段计算,调用分类头与回归头,初始化时初始化了7个,class_embed[self.decoder.num_layers]刚好是第7个。
enc_outputs_class = self.decoder.class_embed[self.decoder.num_layers](output_memory)#对encoder的结果进行分类预测 torch.Size([2, 9620, 91])
enc_outputs_coord_unact = self.decoder.bbox_embed[self.decoder.num_layers](output_memory) + output_proposals#对encoder进行回归并加上output_proposals
torch.Size([2, 9620, 4])
Decoder模块
有些累了,稍后补充






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结