您现在的位置是:首页 >技术杂谈 >【Linux】一文读懂HTTP协议:从原理到应用网站首页技术杂谈
【Linux】一文读懂HTTP协议:从原理到应用
🌠 作者:@阿亮joy.
🎆专栏:《学会Linux》
🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根

目录
👉HTTP协议👈
在网络版计算器一文中,我们通过手动地定制协议来加深对协议的认识。虽然我说应用层协议是由程序猿自己定,但实际上已经有大佬们定义了一些现成的、又非常好用的应用层协议,供我们直接参考使用,其中 HTTP 协议就是其中之一。
什么是HTTP协议
HTTP(超文本传输协议)是一种应用层协议,用于在客户端和服务器之间传输超文本。它是 Web 的基础,可用于检索和提交信息,例如 HTML 文件、图像、样式表等。HTTP 是无状态的,也就是说每个请求都是独立的,服务器不会存储任何有关先前请求的信息。HTTP 协议常用于浏览器与 Web 服务器之间的通信。
认识URL
平时我们俗称的网址,其实就是说的 URL。URL,全称是Uniform Resource Locator,即统一资源定位符,它是互联网上用来定位资源的标准方式。URL 是由多个部分组成,通常包含以下信息:
- 协议:例如 http、https、ftp、file 等。
- 域名:指向某个 IP 地址的可读性更好的别名,例如 www.example.com。
- 端口:应用程序使用的端口号。我们所请求的网络服务对应的端口号都是众所周知的,如 HTTP 服务的默认端口号是80,而 HTTPS 服务的默认端口号是443。
- 路径:资源在服务器上的路径。
- 参数:向脚本传递参数。
- 锚点:页面内部的位置。
URL 通常被用于定位 Web 页面、图像、视频、音频、文件等网络资源。它是一种标准化的格式,可以在浏览器中输入 URL,以访问特定的网络资源。
我们平时上网的目的无非两种:一、我们想要获取资源,二、我们想要上传资源。假设我们现在想要获取资源,在我们没有获取到资源之前,这个资源在服务器上。而一个服务器上可能存在多种资源(本质就是文件),那服务器是如何找到我们需要的资源,并将该资源通过网络交给我们呢?
其实我们在向服务器请求资源时,就会在 URL 内部带上资源所在的路径,这样服务器就可以通过该路径找到我们所需要的资源并交给我们。

urlencode 和 urldecode
在 URL 中,某些字符具有特殊含义。这些字符包括保留字符(如 /、?、& 等)和非 ASCII 字符(如中文、日文等)。因此,如果要在 URL 中包含这些字符,需要将它们进行编码。URL 编码是一种将 URL 中的特殊字符转换为标准 ASCII 字符的方法。
urlencode 是 URL 编码的过程,它将 URL 中的非 ASCII 字符和保留字符进行编码,以便在 URL 中安全地传输。具体来说,urlencode 会将非 ASCII 字符转换成它们的 UTF-8 编码,然后将每个字节转换成 %XX 的形式,其中 XX 是两个十六进制数字表示的字节值。转换的规则:将需要转码的字符转为十六进制,然后从右到左,取4位(不足4位直接处理),每两位做一位,前面加上 %,编码成 %XX。
例如,“hello, 世界” 在进行 urlencode 之后会被转换为 “hello%2C%20%E4%B8%96%E7%95%8C”。
urldecode 是将 URL 编码的字符串还原为原始字符串的过程。它将 %XX 形式的编码转换为相应的字节,并将 UTF-8 编码的字节序列还原为原始的 Unicode 字符。

HTTP协议格式
在 HTTP 协议中,客户端向服务器发送请求,服务器接收并响应请求。请求和响应都有特定的格式。

HTTP请求报文格式
请求通常由请求行、请求报头、空行和请求正文四部分组成。请求行包括请求方法、请求 URL 和 HTTP 协议版本;请求报头是一组键值对,用来描述客户端发送的请求的一些信息,例如请求的 Host、User-Agent 等。;请求正文是可选的,可以没有,通常只有在请求方法为 POST 或 PUT 时才会有请求体,用于传输客户端提交的数据。

注:请求中的 HTTP 协议版本是客户端告知服务端,客户端所采用的的 HTTP 协议版本。
HTTP相应报文格式
响应报文也由三部分组成:状态行、响应报头、空行和响应正文。状态行包括 HTTP 协议版本、状态码和状态码描述。响应报头和请求报头类似,也是一组键值对,用于描述服务器发送的响应的一些信息,例如响应的 Content-Type、Content-Length 等。响应正文用于传输服务器返回的数据。

注:响应中的 HTTP 协议版本是服务端告知客户端,服务端所采用的 HTTP 协议版本。
我们知道,每一层协议都需要考虑封装和解包的问题,也就是如何区分报头和有效载荷(正文)的问题?那 HTTP 是如何区分报头和有效载荷的呢?很明显,HTTP 是通过 (区分一行的内容) 和空行来区分报头和有效载荷的。
现在可以将报头和有效载荷区分开来了,那如何得知有效载荷的大小呢?如果有效载荷存在,那么报头中会有一个 Content-Length 属性来标识有效载荷的大小。
HTTP Demo
Log.hpp
#pragma once
#include <cstdio>
#include <cstdarg>
#include <string>
#include <iostream>
#include <ctime>
// 日志等级
#define DEBUG 0
#define NORMAL 1
#define WARNING 2
#define ERROR 3
#define FATAL 4
#define LOGFILE "./Calculate.log"
const char* levelMap[] =
{
"DEBUG",
"NORMAL",
"WARNING",
"ERROR",
"FATAL"
};
void logMessage(int level, const char* format, ...)
{
// 只有定义了DEBUG_SHOW,才会打印debug信息
// 利用命令行来定义即可,如-D DEBUG_SHOW
#ifndef DEBUG_SHOW
if(level == DEBUG) return;
#endif
char stdBuffer[1024]; // 标准部分
time_t timestamp = time(nullptr);
// struct tm *localtime = localtime(×tamp);
snprintf(stdBuffer, sizeof stdBuffer, "[%s] [%ld] ", levelMap[level], timestamp);
char logBuffer[1024]; // 自定义部分
va_list args; // va_list就是char*的别名
va_start(args, format); // va_start是宏函数,让args指向参数列表的第一个位置
// vprintf(format, args); // 以format形式向显示器上打印参数列表
vsnprintf(logBuffer, sizeof logBuffer, format, args);
va_end(args); // va_end将args弄成nullptr
FILE *fp = fopen(LOGFILE, "a");
// printf("%s%s
", stdBuffer, logBuffer);
fprintf(fp, "%s%s
", stdBuffer, logBuffer);
fclose(fp);
}
Sock.hpp
#pragma once
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <iostream>
#include <string>
#include <cstring>
#include "Log.hpp"
class Sock
{
private:
const static int backlog = 20;
public:
Sock() {}
// 返回值是创建的套接字
int Socket()
{
int sock = socket(AF_INET, SOCK_STREAM, 0);
if (sock < 0)
{
logMessage(FATAL, "Create Socket Error! Errno:%d Strerror:%s", errno, strerror(errno));
exit(2);
}
logMessage(NORMAL, "Create Socket Success! Socket:%d", sock);
return sock;
}
// 绑定端口号
void Bind(int sock, uint16_t port, std::string ip = "0.0.0.0")
{
struct sockaddr_in local;
memset(&local, 0, sizeof local);
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = inet_addr(ip.c_str());
if (bind(sock, (struct sockaddr *)&local, sizeof local) < 0)
{
logMessage(FATAL, "Bind Error! Errno:%d Strerror:%s", errno, strerror(errno));
exit(3);
}
}
// 将套接字设置为监听套接字
void Listen(int listenSock)
{
if (listen(listenSock, backlog) < 0)
{
logMessage(FATAL, "Listen Error! Errno:%d Strerror:%s", errno, strerror(errno));
exit(4);
}
logMessage(NORMAL, "Init Server Success!");
}
// 接收链接,返回值是为该连接服务的套接字
// ip和port是输出型参数,返回客户端的ip和port
int Accept(int listenSock, std::string *ip, uint16_t *port)
{
struct sockaddr_in src;
socklen_t len = sizeof(src);
int serviceSock = accept(listenSock, (struct sockaddr *)&src, &len);
if (serviceSock < 0)
{
logMessage(FATAL, "Accept Error! Errno:%d Strerror:%s", errno, strerror(errno));
return -1;
}
if (ip)
*ip = inet_ntoa(src.sin_addr);
if (port)
*port = ntohs(src.sin_port);
return serviceSock;
}
// 发起连接
bool Connet(int sock, const std::string &serverIP, const int16_t &serverPort)
{
struct sockaddr_in server;
memset(&server, 0, sizeof server);
server.sin_family = AF_INET;
server.sin_port = htons(serverPort);
inet_pton(AF_INET, serverIP.c_str(), &server.sin_addr);
if (connect(sock, (struct sockaddr *)&server, sizeof server) == 0)
return true;
else
return false;
}
~Sock() {}
};
HttpServer.hpp
#pragma once
#include <iostream>
#include <functional>
#include <unistd.h>
#include <signal.h>
#include "Sock.hpp"
using func_t = std::function<void(int)>;
class HttpServer
{
public:
HttpServer(const uint16_t& port, func_t func)
: _port(port)
, _func(func)
{
_listenSock = _sock.Socket();
_sock.Bind(_listenSock, _port);
_sock.Listen(_listenSock);
}
~HttpServer()
{
if(_listenSock >= 0)
close(_listenSock);
}
void Start()
{
signal(SIGCHLD, SIG_IGN);
while(true)
{
std::string clientIP;
uint16_t clientPort;
int sockfd = _sock.Accept(_listenSock, &clientIP, &clientPort);
if(sockfd < 0) continue;
// 创建子进程去处理请求
if(fork() == 0)
{
close(_listenSock);
_func(sockfd);
close(sockfd);
exit(0);
}
}
}
private:
int _listenSock;
uint16_t _port;
Sock _sock;
func_t _func; // 回调函数
};
HttpServer.cc
#include <iostream>
#include <memory>
#include "HttpServer.hpp"
void Usage(const std::string proc)
{
std::cout << "
Usage" << proc << " Port" << std::endl;
}
void HandlerHttpRequest(int sock)
{
// 1、读取请求
char buffer[10240];
ssize_t s = recv(sock, buffer, sizeof(buffer) - 1, 0);
// 将接收到的数据直接当成字符串进行打印
if(s > 0)
{
buffer[s] = '�';
std::cout << buffer << "-----------------------" << std::endl;
}
// 2、构建一个HTTP响应
std::string HttpResponse = "HTTP/1.1 200 OK
";
HttpResponse += "
";
HttpResponse += "<html><h3>Singing, dancing, Rap and playing basketball are my favorites</h3></html>";
send(sock, HttpResponse.c_str(), HttpResponse.size(), 0);
}
int main(int argc, char* argv[])
{
if(argc != 2)
{
Usage(argv[0]);
exit(1);
}
std::unique_ptr<HttpServer> ptr(new HttpServer(atoi(argv[1]), HandlerHttpRequest));
ptr->Start();
return 0;
}

注:Web 根目录并不是 Linux 系统中的根目录!!!

使用 telnet 工具来访问

代码细化
Util.hpp
#pragma once
#include <iostream>
#include <vector>
class Util
{
public:
static void cutString(std::string s, const std::string &sep, std::vector<std::string> *out)
{
std::size_t start = 0;
while (start < s.size())
{
auto pos = s.find(sep, start);
if (pos == std::string::npos) break;
std::string sub = s.substr(start, pos - start);
out->push_back(sub);
start += sub.size();
start += sep.size();
}
if(start < s.size()) out->push_back(s.substr(start));
}
};
cutString 接口的作用是以 sep 为分割符,将传入的字符串 s 进行切分,并尾插到输出型参数 out 中。
#define ROOT "./wwwroot" // Web更目录
#define HOMEPAGE "/index.html" // 如果没有指定请求的资源,服务端默认给客户端返回该资源
void HandlerHttpRequest(int sock)
{
// 1、读取请求
char buffer[10240];
ssize_t s = recv(sock, buffer, sizeof(buffer) - 1, 0);
// 将接收到的数据直接当成字符串进行打印
if(s > 0)
{
buffer[s] = '�';
std::cout << buffer << "-----------------------" << std::endl;
}
// 2、构建一个HTTP响应
std::vector<std::string> vline;
Util::cutString(buffer, "
", &vline);
std::vector<std::string> vblock;
Util::cutString(vline[0], " ", &vblock); // 提取HTTP请求
// 请求资源的路径
std::string file = vblock[1]; // vblock[1]是要请求资源的路径
std::string target = ROOT; // target为请求资源的路径
if(file == "/") file = HOMEPAGE; // 如果请求资源的路径是Web根目录,那么给客户端返回默认的资源
target += file;
std::cout << target << std::endl;
std::string content;
std::ifstream in(target);
if(in.is_open())
{
std::string line;
while(std::getline(in, line))
{
content += line; // 将文件中的全部内容读取出来
}
in.close();
}
std::string HttpResponse;
// content为空,说明请求的资源不存在
if(content.empty()) HttpResponse = "HTTP/1.1 404 NotFound
";
else HttpResponse = "HTTP/1.1 200 OK
";
HttpResponse += "
";
HttpResponse += content;
send(sock, HttpResponse.c_str(), HttpResponse.size(), 0);
}

./wwwroot/a/b/index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Summer Beach</title>
<style>
/* 设置背景图片和背景颜色 */
body {
background-image: url("https://images.unsplash.com/photo-1627259317488-8ecb5120a71a?ixid=MnwxMjA3fDB8MHxwcm9maWxlLXBhZ2V8NjJ8MzQ1fHxlbnwwfHx8fDE2MTk5MjIzNzA&ixlib=rb-1.2.1");
background-color: #a9d9e7;
background-size: cover;
background-position: center;
margin: 0;
padding: 0;
font-family: Arial, sans-serif;
}
/* 设置标题的样式 */
h1 {
text-align: center;
margin-top: 50px;
font-size: 64px;
color: #fff;
text-shadow: 2px 2px #000;
}
/* 设置主要内容区域的样式 */
#main {
width: 80%;
margin: 50px auto;
background-color: rgba(255, 255, 255, 0.8);
padding: 20px;
box-shadow: 0px 0px 20px #000;
}
/* 设置表格的样式 */
table {
margin-top: 20px;
width: 100%;
border-collapse: collapse;
text-align: center;
}
/* 设置表格的表头样式 */
th {
background-color: #222;
color: #fff;
font-weight: bold;
padding: 10px;
}
/* 设置表格的单元格样式 */
td {
padding: 10px;
}
/* 设置按钮的样式 */
button {
display: block;
margin: 30px auto;
padding: 10px;
border-radius: 5px;
border: none;
background-color: #222;
color: #fff;
font-size: 24px;
cursor: pointer;
transition: all 0.3s ease-in-out;
}
/* 设置按钮的鼠标悬停样式 */
button:hover {
background-color: #333;
}
</style>
</head>
<body>
<h1>Summer Beach</h1>
<div id="main">
<h2>Travel Destinations</h2>
<table>
<tr>
<th>Location</th>
<th>Description</th>
<th>Photo</th>
</tr>
<tr>
<td>Maldives</td>
<td>A tropical paradise with crystal clear waters and white sandy beaches.</td>
<td><img src="https://images.unsplash.com/photo-1526672312463-7d28e8f0d227?ixid=MnwxMjA3fDB8MHxzZWFyY2h8MXx8bWFsZGl2ZXN8ZW58MHx8MHx8&ixlib=rb-1.2.1&
./wwwroot/index.html
<!DOCTYPE html>
<html>
<head>
<title>远方的诗和画</title>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<style>
/* 样式表 */
body {
background-color: #f8f8f8;
font-family: Arial, sans-serif;
font-size: 16px;
line-height: 1.5;
margin: 0;
padding: 0;
}
header {
background-color: #333;
color: #fff;
padding: 20px;
text-align: center;
}
h1 {
margin: 0;
}
main {
max-width: 800px;
margin: 20px auto;
padding: 0 20px;
}
img {
max-width: 100%;
height: auto;
margin: 20px 0;
}
blockquote {
font-style: italic;
margin: 20px 0;
padding-left: 20px;
border-left: 2px solid #333;
}
</style>
</head>
<body>
<header>
<h1>远方的诗和画</h1>
<p>走过千山万水,追寻梦中的旅途</p>
</header>
<main>
<h2>关于旅游的诗句</h2>
<blockquote>
<p>夜泊牛渚怀古怨,<br>不堪看点滴,<br>尽向湖心画短鸟。</p>
<footer>——宋·杨万里《夜泊牛渚怀古怨》</footer>
</blockquote>
<blockquote>
<p>远山霭漫,<br>长河落日圆;<br>这一生,<br>与谁度过。</p>
<footer>——唐·岑参《旅怀》</footer>
</blockquote>
<h2>风景如画的地方</h2>
<p>以下是一些值得一去的风景胜地:</p>
<ul>
<li>黄山</li>
<li>张家界</li>
<li>九寨沟</li>
<li>桂林漓江</li>
<li>西湖</li>
</ul>
<h2>一些美丽的图片</h2>
<p>以下是一些关于旅游的美丽图片:</p>
<img src="https://picsum.photos/id/1015/800/400" alt="图片1">
<img src="https://picsum.photos/id/1024/800/400" alt="图片2">
<img src="https://picsum.photos/id/1035/800/400"


HTTP的方法

我们平时的上网行为其实就两:1. 从服务器端拿取资源(GET) 2. 把客户端的数据提交到服务端中(POST、GET)。

GET 是获取资源的方法,而图片和音频都是网络资源,因此使用 GET 方法可以方便地获取这些资源。此外,GET方法是幂等的,即对同一资源的多次请求返回的结果是相同的,适合用于获取静态资源。
GET 和 POST 的区别
想要知道 GET 和 POST的区别就需要了解表单。
表单(Form)是 HTML 中一种常用的元素,它是用来接受用户输入的一种方式。表单包含了各种表单元素,如文本框、单选框、复选框、下拉框等,用户可以通过这些元素输入信息,然后通过表单提交(Submit)按钮将这些信息发送到后端服务器。
表单的基本语法如下:
<form action="提交地址" method="提交方式">
表单元素
<input type="submit" value="提交">
</form>
其中,action 属性指定了表单提交的地址,method 属性指定了表单提交的方式。常见的提交方式有两种:GET 和 POST。

表单提交后,后端服务器会接收到表单数据,可以通过对应的程序对表单数据进行处理,并给出响应。注:表单中的数据会变成 HTTP 请求中的一部分!!!
表单示例代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>阿亮Joy.</title>
</head>
<body>
<h3>须知少年凌云志,曾许人间第一流</h3>
<form name="input" action="/a/b/index.html" method="GET">
Username: <input type="text" name="user"> <br/>
Password: <input type="password" name="pwd"> <br/>
<input type="submit" value="Submit">
</form>
</body>
</html>
GET 方法



表单提交方式为 GET 最大的特点就是通过 URL 来传递参数,会将用户名和密码等私密信息回显到 URL中,称为 URL 的一部分。因为用户名和密码成为 URL 中的参数,而我们并没有对该参数进行处理,所以就出现该网页无法正常运作的提示。
POST 方法



POST 方法是通过 HTTP 请求的正文来提交参数,不会将用户名和密码等私密信息回显到 URL 中,私密性有所保证。因为用户名和密码等私密信息等没有回显到 URL 中,所以我们就可以访问到 /a/b/index.html 存在的网页了。
需要注意的是:私密性有所保证并不意味着安全。因为表单在提交的过程中,数据是明文传输的。如果想要保证安全,就需要通过加密和解密来解决,而加密传输可以采用 HTTPS 等安全协议。
GET 和 POST 方法的区别总结如下:
-
参数传递方式不同:GET 请求是通过 URL 的查询字符串传递参数,而 POST 请求则是通过请求正文传递参数。
-
参数传递大小限制不同:由于 GET 请求是通过 URL 传递参数,因此它的参数传递大小受到浏览器和服务器对 URL 长度的限制,通常不能超过 2KB;而 POST 请求的参数传递大小没有限制,但是服务器可以设置最大接收参数大小。
-
缓存处理方式不同:GET 请求可以被浏览器缓存,而 POST 请求则不会被浏览器缓存。
-
安全性不同:由于 GET 请求参数会暴露在 URL 中,因此它不太安全,而 POST 请求的参数则不会暴露在 URL 中,相对来说比较安全。
GET 和 POST 方法的主要应用场景
- GET 方法会将请求参数添加在 URL 中,形成一个完整的 URL,然后发送给服务器。它的主要应用场景是请求资源,例如浏览网页、查看图片等。
- POST 方法会将请求参数封装在 HTTP 请求正文中,然后发送给服务器。它的主要应用场景是提交表单数据,例如登录、注册等。
HEAD 方法

HEAD 方法请求获取指定资源的头部信息,与 GET 方法类似,但不返回响应的正文部分。
OPTIONS 方法

OPTIONS 方法请求获取指定资源支持的通信选项,可以用来查询服务器支持哪些方法或者哪些头部。
注:除了 GET 和 POST 方法外,很多方法很大程度都是不支持的或者支持的不是很好,我们只需要知道即可。
HTTP的状态码

HTTP 状态码是 Web 服务器返回给客户端的 3 位数字代码,用于表示当前 HTTP 请求的处理状态。以下是常见的 HTTP 状态码及其含义:
- 200 OK:服务器成功处理了请求。
- 201 Created:请求已经被实现,而且有一个新的资源已经依据请求的需要而建立。
- 204 No Content:服务器成功处理了请求,但是没有返回任何内容。
- 301 Moved Permanently:被请求的资源已永久移动到新位置。
- 302 Found:请求的资源现在临时从不同的 URL 响应请求,但将来可能会恢复原始地址。
- 304 Not Modified:请求的资源在服务器上没有被修改过,可以直接使用浏览器缓存。
- 400 Bad Request:服务器无法理解请求的格式,客户端不应该重复提交这个请求。
- 401 Unauthorized:请求需要认证或者认证失败。
- 403 Forbidden:服务器理解请求,但是拒绝执行该请求。
- 404 Not Found:服务器找不到请求的资源。
- 500 Internal Server Error:服务器发生错误,无法完成请求。
- 502 Bad Gateway:服务器作为网关或者代理,从上游服务器收到无效响应。
- 503 Service Unavailable:服务器当前无法处理请求,一般用于临时维护或者过载状态。
永久重定向 301 VS 临时重定向 302、307
301 状态码表示永久重定向,意味着请求的 URL 已经被永久移动到了新的位置,以后所有对原始 URL 的请求都将自动转移到新的URL地址,浏览器也将自动更新书签和搜索引擎也将更新其索引。
HTTP/1.1 301 Moved Permanently
Location: http://www.example.com/new-location
302 状态码表示临时重定向,意味着请求的 URL 已经被暂时移动到了新的位置,浏览器会自动跳转到新的 URL 地址,但搜索引擎不会更新其索引。
HTTP/1.1 302 Found
Location: http://www.example.com/new-location
307 状态码与 302 类似,表示临时重定向,但是客户端不应该改变请求方法,而是继续使用原来的请求方法。例如,如果使用 POST 方法请求一个资源,并且服务器返回 307 状态码,那么客户端应该用 POST 方法重新发起请求,而不是使用 GET 方法。307 状态码通常用于临时重定向时需要保留原始请求方法的场景。
HTTP/1.1 307 Temporary Redirect
Location: http://www.example.com/new-location
注:永久重定向会影响用户后序的请求策略,而临时重定向不会影响用户后续的请求策略。

临时重定向代码演示
#define ROOT "./wwwroot"
#define HOMEPAGE "/index.html"
void HandlerHttpRequest(int sock)
{
// 1、读取请求
char buffer[10240];
ssize_t s = recv(sock, buffer, sizeof(buffer) - 1, 0);
// 将接收到的数据直接当成字符串进行打印
if(s > 0)
{
buffer[s] = '�';
}
std::cout << buffer << "-----------------------" << std::endl;
// 2、构建一个HTTP响应
std::vector<std::string> vline;
Util::cutString(buffer, "
", &vline);
std::vector<std::string> vblock;
Util::cutString(vline[0], " ", &vblock);
// 请求资源的路径
std::string file = vblock[1];
std::string target = ROOT;
if(file == "/") file = HOMEPAGE;
target += file;
std::cout << target << std::endl;
std::string content;
std::ifstream in(target);
if(in.is_open())
{
std::string line;
while(std::getline(in, line))
{
content += line;
}
in.close();
}
std::string HttpResponse;
if(content.empty())
{
HttpResponse = "HTTP/1.1 302 Found
";
HttpResponse += "Location: https://blog.csdn.net/m0_63639164
";
}
else HttpResponse = "HTTP/1.1 200 OK
";
HttpResponse += "
";
HttpResponse += content;
send(sock, HttpResponse.c_str(), HttpResponse.size(), 0);
}

404 演示



HTTP常见的报头
- Content-Type:数据类型(text / html 等)
- Content-Length:Body 的长度,用于指示客户端应该接收多少字节的响应
- Host:客户端告知服务器,所请求的资源是在哪个主机的哪个端口上
- User-Agent:声明用户的操作系统和浏览器版本信息
- referer:当前页面是从哪个页面跳转过来的
- location:搭配 3xx 状态码使用,告诉客户端接下来要去哪里访问
- Cookie:用于在客户端存储少量信息,通常用于实现会话(session)的功能
Content-Length


Content-Type

注:HTTP 的 Content Type 也是有对照表的,需要根据资源的类型来填写。
Connection
HTTP 报头中的 Connection 是一个非常重要的字段,用于指示浏览器与服务器之间的长连接是否应该保持打开状态,以便更快地传输多个请求和响应。
-
Keep-Alive:表示浏览器与服务器之间的长连接将保持打开状态,并且后续的请求和响应可以在同一个连接上进行传输,从而减少了连接的建立和断开开销。
-
close:表示浏览器与服务器之间的连接在请求和响应完成后将立即关闭。这是 HTTP/1.0 中默认的行为。
HTTP 的长连接和短连接都是指在 TCP 层面上的连接。HTTP 协议是基于 TCP 协议的,每次 HTTP 请求和响应都需要建立和断开 TCP 连接,因此在高并发场景下会产生大量的 TCP 连接开销,从而影响性能。
短连接指每次HTTP请求和响应都建立一个新的 TCP 连接,并在请求结束后立即关闭连接。这种方式下,每次请求都需要重新建立和断开 TCP 连接,会增加连接管理的负担和开销。
在 HTTP/1.0 中,HTTP 默认采用短连接,也就是每次请求和响应都建立和断开一次 TCP 连接。在 HTTP/1.1 中,HTTP 默认采用长连接,即在一个 TCP 连接上可以连续发送多个 HTTP 请求和响应。
长连接和短连接各有优缺点,长连接可以减少 TCP 连接的建立和断开次数,降低网络开销,但长时间占用连接会增加服务器资源消耗;短连接可以保证每个请求的独立性,减少因单个请求错误导致的影响,但频繁的 TCP 连接建立和断开会影响性能。因此,根据具体的应用场景和需求选择长连接或短连接,或者结合两者的优点,使用 HTTP/2 的多路复用技术。
HTTP的主要特征
-
无状态:每个 HTTP 请求都是独立的,服务器不会保存任何客户端的请求信息,因此 HTTP 被称为无状态协议。为了维护客户端状态,通常使用 Cookie 和 Session技术。
-
可扩展:HTTP 报头可以通过添加自定义报头实现扩展功能。
-
灵活:HTTP 可以传输任何类型的数据,如 HTML、图片、音频、视频等。
-
明文传输:HTTP 是明文传输的,请求和响应中的所有内容都可以被窃听,因此使用 HTTPS 进行加密。
-
请求 / 响应模型:HTTP 采用客户端-服务器模型,客户端发送请求,服务器发送响应。
-
无连接:HTTP 协议不维护连接,连接是 TCP 协议维护的,HTTP直接发起请求和响应即可。
-
缓存:HTTP 支持缓存,可以通过在响应报头中添加缓存信息控制客户端和服务器的缓存机制。
既然 HTTP 的一个主要特征是无状态,那为什么网站一般都能够记录我的状态呢?
虽然 HTTP 协议本身是无状态的,但是在实际应用中,为了实现用户的登录状态等功能,网站会在服务器端保存用户的会话状态,并分配给用户一个唯一的会话标识符(Session ID),这个会话标识符可以在每次请求时传递给服务器,服务器就可以根据这个标识符识别用户,从而实现用户状态的保持。
具体来说,当用户登录时,服务器会创建一个会话对象,保存用户的相关信息,同时生成一个唯一的 Session ID,并将其发送给客户端,通常是通过 Cookie 技术实现。之后,客户端每次请求都会携带这个 Session ID,服务器就可以根据 Session ID 查找对应的会话对象,获取用户的相关信息,从而实现用户状态的保持。
需要注意的是,由于 HTTP 协议是无状态的,因此服务器端保存的会话状态只存在于一定的时间范围内,一般会设置一个过期时间,超过过期时间后,会话状态会被清除。

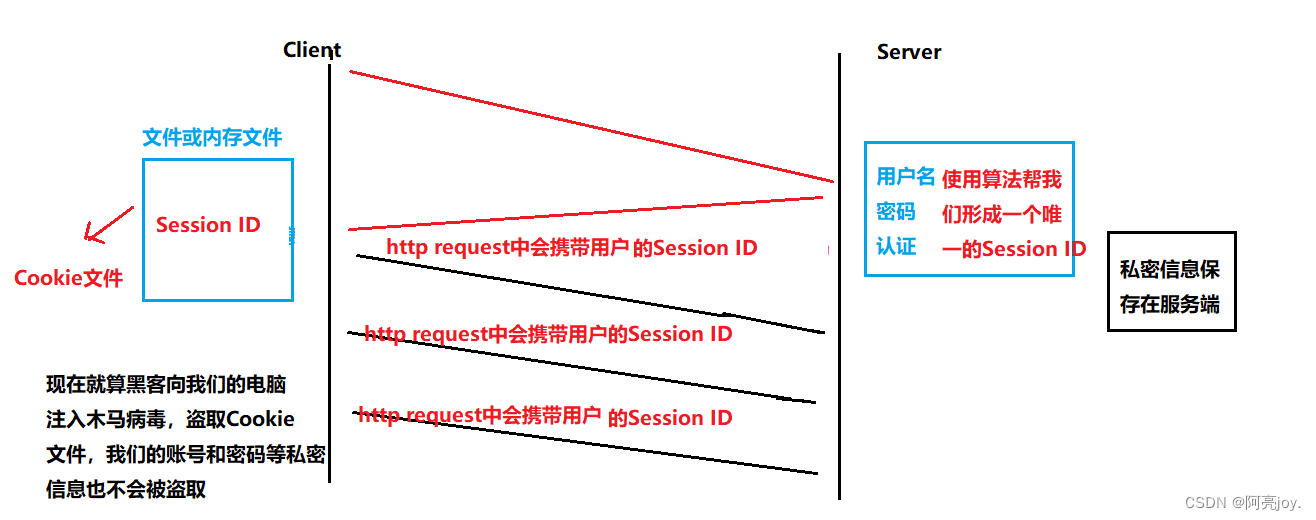
Cookie 是基于 HTTP 协议实现的,可以分为文件级的 Cookie 文件和内存级的 Cookie 文件。
文件级的 Cookie 文件是存储在用户计算机上的硬盘上,是一种持久性的 Cookie。它们的过期时间可以设置为一段时间,也可以永不过期。在访问同一个网站时,浏览器会自动发送该网站存储在本地计算机上的 Cookie文件,以便在服务器端进行身份验证和授权操作。
内存级的 Cookie 文件是存储在内存中的临时 Cookie。当浏览器关闭时,它们会自动删除。内存级的 Cookie 可以用于存储一些敏感信息,如密码和银行账户信息等,以提高安全性。
注:相对来说,文件级 Cookie 文件更容易被盗取。
Cookie 和 Set-Cookie
HTTP 协议中的 Cookie 和 Set-Cookie 是 HTTP 请求和响应中的两个重要报头。其中 Cookie 是客户端请求时携带的用于身份验证和状态管理的信息,而 Set-Cookie 是服务端响应时用于设置 Cookie 的报头。
具体来说,当客户端向服务端发送 HTTP 请求时,如果之前已经设置了 Cookie,则会在请求报头中添加一个 Cookie 字段,将之前设置的 Cookie 信息携带过去,供服务端进行验证和状态管理。而当服务端向客户端发送 HTTP 响应时,如果需要设置新的 Cookie,则会在响应报头中添加一个 Set-Cookie 字段,指定新的 Cookie 信息,包括 Cookie 的名称、值、过期时间、作用域等。



👉抓包工具👈
常见的抓包工具
抓包工具是一种网络工具,可以捕捉和分析网络通信数据包,以便进行网络故障诊断、协议分析、网络安全评估等工作。以下是几种常用的抓包工具:
-
Wireshark:Wireshark 是一款开源的网络协议分析工具,支持多种操作系统,可以用来分析和解码多种协议。Wireshark 功能强大,支持实时抓包和离线分析。
-
tcpdump:tcpdump 是一款常用的命令行抓包工具,支持多种操作系统。它可以捕获网络接口上的数据包,并将其保存到文件中,同时也可以实时分析数据包。
-
Fiddler:Fiddler 是一款基于 Windows 平台的抓包工具,主要用于 HTTP 和 HTTPS 协议的分析和调试。它可以拦截和修改客户端和服务器之间的 HTTP 流量。
-
Charles:Charles 是一款跨平台的抓包工具,支持多种操作系统。它可以拦截和分析 HTTP 和 HTTPS 流量,支持实时分析和修改。
-
Burp Suite:Burp Suite 是一款专业的网络安全测试工具,可以用来检测和利用 Web 应用程序的安全漏洞。它包含了代理服务器、扫描器、攻击工具等多种功能。
抓包工具的原理

抓包工具是用来捕获网络数据包的工具,其原理是通过在计算机与网络之间插入一个“中间人”来监听、记录和分析数据包的传输情况。
当我们使用抓包工具进行数据包捕获时,抓包工具会将计算机和网络之间的通信流量截获并保存在本地,然后对这些数据包进行分析和解析,以便我们可以查看和分析其中的详细信息,如协议、请求头、响应头、数据内容等。
抓包工具实现数据包捕获的主要方式有两种,一种是通过网络适配器(网卡)捕获数据包,另一种是通过端口监听捕获数据包。在捕获数据包后,抓包工具会将数据包保存在本地,并提供可视化的界面,让用户可以方便地查看和分析数据包的内容。
👉总结👈
本篇博客主要讲解了什么是HTTP协议、认识URL、HTTP协议格式、请求方法、状态码、常见报头、主要特征以及常见的抓包工具和抓包工具的原理等等。以上就是本篇博客的全部内容了,如果大家觉得有收获的话,可以点个三连支持一下!谢谢大家啦!💖💝❣️






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结