您现在的位置是:首页 >技术杂谈 >【大数据之Hadoop】十七、MapReduce之数据清洗ETL网站首页技术杂谈
【大数据之Hadoop】十七、MapReduce之数据清洗ETL
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将分散、零乱、标准不统一的数据整合到一起,为决策提供分析依据。
ETL的设计分三部分:数据抽取、数据的清洗转换、数据的加载。
1 ETL体系结构
ETL主要是用来实现异构数据源数据集成的。多种数据源的所有原始数据大部分未作修改就被载人ETL。无论数据源在关系型数据库、非关系型数据库,还是外部文件,集成后的数据都将被置于数据库的数据表或数据仓库的维度表中,以便在数据库内或数据仓库中作进一步转换。即一般会将最终的数据存储到数据库或者数据仓库中。
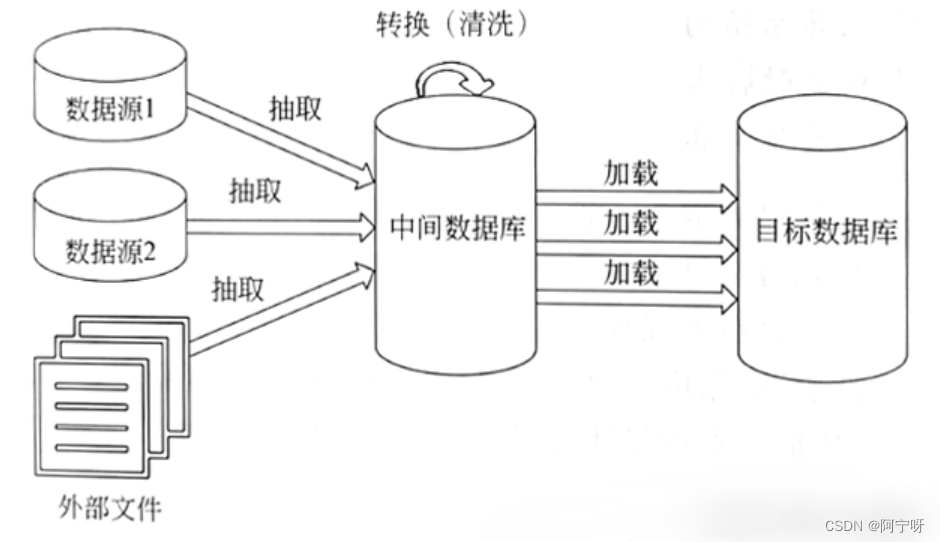
数据源1和2均为数据库管理系统,可以使用SQL语句完成一部分数据清洗工作。
数据源为外部文件时,不能使用SQL语句进行数据清洗工作,只能直接从数据源中抽取出来,然后在数据转换的时候进行数据清洗的工作。
因此,数据仓库中的数据清洗工作主要还是在数据转换的时候进行。清洗好的数据将保存到目标数据库中,用于后续的数据分析、数据挖掘等。
抽取:
这个环节的主要抽取工具:Sqoop、Flume、Kafka、Kettle、DataX、Maxwell。抽取离线数据根据:Sqoop、DataX。抽取实时数据:Flume、Kafka、Maxwell、Kettle。
转换:
转换包括清洗、合并、拆分、加工等,可以用Hadoop生态的东西, MapReduce、Spark、Flink、Hive等对数据的清洗。
加载:
抽取转换之后,将数据加载到目标数据库。用Hbase去存储一些大数据方面的东西,或者HDFS等这些工具。
2 ETL正则匹配汇总
1、匹配中文:[u4e00-u9fa5]
2、英文字母:[a-zA-Z]
3、数字:[0-9]
4、匹配中文,英文字母和数字及下划线:^[u4e00-u9fa5_a-zA-Z0-9]+$
同时判断输入长度:[u4e00-u9fa5_a-zA-Z0-9_]{4,10}
5、
(?!*) 不能以_开头
(?!.*?*$) 不能以_结尾
[a-zA-Z0-9_u4e00-u9fa5]+ 至少一个汉字、数字、字母、下划线
$ 与字符串结束的地方匹配
6、只含有汉字、数字、字母、下划线,下划线位置不限:^[a-zA-Z0-9_u4e00-u9fa5]+$
7、由数字、26个英文字母或者下划线组成的字符串:^w+$
8、2~4个汉字:"^[u4E00-u9FA5]{2,4}$";
9、最长不得超过7个汉字,或14个字节(数字,字母和下划线)正则表达式:
{1,7}$|^[dA-Za-z_]{1,14}$
10、匹配双字节字符(包括汉字在内):[^x00-xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
11、匹配空白行的正则表达式:ns*r
评注:可以用来删除空白行
12、匹配HTML标记的正则表达式:<(S*?)[^>]*>.*?|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
13、匹配首尾空白字符的正则表达式:^s*|s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
14、匹配Email地址的正则表达式:
[w.-]*[a-zA-Z0-9]@[a-zA-Z0-9][w.-]*[a-zA-Z0-9].[a-zA-Z][a-zA-Z.]*[a-zA-Z]$
15、手机号:^((13[0-9])|(14[0-9])|(15[0-9])|(17[0-9])|(18[0-9]))d{8}$
16、身份证:(^d{15}$)|(^d{17}([0-9]|X|x)$)
17、匹配网址URL的正则表达式:[a-zA-z]+://[^s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
18、匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
19、匹配国内电话号码:d{3}-d{8}|d{4}-d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
20、匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
21、匹配中国邮政编码:[1-9]d{5}(?!d)
评注:中国邮政编码为6位数字
22、匹配身份证:d{15}|d{18}
评注:中国的身份证为15位或18位
23、匹配ip地址:d+.d+.d+.d+
评注:提取ip地址时有用
24、匹配特定数字:
^[1-9]d*$ //匹配正整数
^-[1-9]d*$ //匹配负整数
^-?[1-9]d*$ //匹配整数
^[1-9]d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]d*.d*|0.d*[1-9]d*$ //匹配正浮点数
^-([1-9]d*.d*|0.d*[1-9]d*)$ //匹配负浮点数
^-?([1-9]d*.d*|0.d*[1-9]d*|0?.0+|0)$ //匹配浮点数
^[1-9]d*.d*|0.d*[1-9]d*|0?.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]d*.d*|0.d*[1-9]d*))|0?.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
25、匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
26、
在使用RegularExpressionValidator验证控件时的验证功能及其验证表达式介绍如下:
只能输入数字:“^[0-9]*$”
只能输入n位的数字:“^d{n}$”
只能输入至少n位数字:“^d{n,}$”
只能输入m-n位的数字:“^d{m,n}$”
只能输入零和非零开头的数字:“^(0|[1-9][0-9]*)$”
只能输入有两位小数的正实数:“^[0-9]+(.[0-9]{2})?$”
只能输入有1-3位小数的正实数:“^[0-9]+(.[0-9]{1,3})?$”
只能输入非零的正整数:“^+?[1-9][0-9]*$”
只能输入非零的负整数:“^-[1-9][0-9]*$”
只能输入长度为3的字符:“^.{3}$”
只能输入由26个英文字母组成的字符串:“^[A-Za-z]+$”
只能输入由26个大写英文字母组成的字符串:“^[A-Z]+$”
只能输入由26个小写英文字母组成的字符串:“^[a-z]+$”
只能输入由数字和26个英文字母组成的字符串:“^[A-Za-z0-9]+$”
只能输入由数字、26个英文字母或者下划线组成的字符串:“^w+$”
验证用户密码:“^[a-zA-Z]w{5,17}$”正确格式为:以字母开头,长度在6-18之间,
只能包含字符、数字和下划线。
验证是否含有^%&',;=?$"等字符:“[^%&',;=?$x22]+”
只能输入汉字:“^[u4e00-u9fa5],{0,}$”
验证Email地址:“^w+[-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*$”
验证InternetURL:“^http://([w-]+.)+[w-]+(/[w-./?%&=]*)?$”
验证身份证号(15位或18位数字):“^d{15}|d{}18$”
验证一年的12个月:“^(0?[1-9]|1[0-2])$”正确格式为:“01”-“09”和“1”“12”
验证一个月的31天:“^((0?[1-9])|((1|2)[0-9])|30|31)$”
正确格式为:“01”“09”和“1”“31”。
匹配中文字符的正则表达式: [u4e00-u9fa5]
匹配双字节字符(包括汉字在内):[^x00-xff]
匹配空行的正则表达式:n[s| ]*r
匹配HTML标记的正则表达式:/<(.*)>.*|<(.*) />/
匹配首尾空格的正则表达式:(^s*)|(s*$)
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
匹配网址URL的正则表达式:http://([w-]+.)+[w-]+(/[w- ./?%&=]*)?
校验数字的表达式
只含数字:^[0-9]*$
n位的数字:^d{n}$
至少n位的数字:^d{n,}$
m-n位的数字:^d{m,n}$
零和非零开头的数字:^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
带1-2位小数的正数或负数:^(-)?d+(.d{1,2})$
正数、负数、和小数:^(-|+)?d+(.d+)?$
有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
非零的正整数:d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^+?[1-9][0-9]*$
非零的负整数:^-[1-9][]0-9"*$ 或 ^-[1-9]d*$
非负整数:^d+$ 或 ^[1-9]d*|0$
非正整数:^-[1-9]d*|0$ 或 ^((-d+)|(0+))$
非负浮点数:^d+(.d+)?$ 或 ^[1-9]d*.d*|0.d*[1-9]d*|0?.0+|0$
非正浮点数:^((-d+(.d+)?)|(0+(.0+)?))$ 或 ^(-([1-9]d*.d*|0.d*[1-9]d*))|0?.0+|0$
正浮点数:d*.d*|0.d*[1-9]d*$ 或 ^(([0-9]+.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*.[0-9]+)|([0-9]*[1-9][0-9]*))$
负浮点数:^-([1-9]d*.d*|0.d*[1-9]d*)$ 或 ^(-(([0-9]+.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*.[0-9]+)|([0-9]*[1-9][0-9]*)))$
浮点数:^(-?d+)(.d+)?$ 或 ^-?([1-9]d*.d*|0.d*[1-9]d*|0?.0+|0)$
校验字符的表达式
汉字:^[u4e00-u9fa5]{0,}$
英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
长度为3-20的所有字符:^.{3,20}$
由26个英文字母组成的字符串:^[A-Za-z]+$
由26个大写英文字母组成的字符串:^[A-Z]+$
由26个小写英文字母组成的字符串:^[a-z]+$
由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
由数字、26个英文字母或者下划线组成的字符串:^w+$ 或 ^w{3,20}$
中文、英文、数字包括下划线:^[u4E00-u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号:^[u4E00-u9FA5A-Za-z0-9]+$ 或 ^[u4E00-u9FA5A-Za-z0-9]{2,20}$
可以输入含有^%&',;=?$"等字符:[^%&',;=?$x22]+
禁止输入含有~的字符:[^~x22]+
特殊需求表达式
Email地址:^w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*$
SQL中Email的正则匹配:"^[A-Za-z0-9]+([_.][A-Za-z0-9]+)*@([A-Za-z0-9-]+.)+[A-Za-z]{2,6}$"
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+.?
InternetURL:[a-zA-z]+://[^s]* 或 ^http://([w-]+.)+[w-]+(/[w-./?%&=]*)?$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|4|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])d{8}$
电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^((d{3,4}-)|d{3.4}-)?d{7,8}$
国内电话号码(0511-4405222、021-87888822):d{3}-d{8}|d{4}-d{7}
电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号): ((d{11})|^((d{7,8})|(d{4}|d{3})-(d{7,8})|(d{4}|d{3})-(d{7,8})-(d{4}|d{3}|d{2}|d{1})|(d{7,8})-(d{4}|d{3}|d{2}|d{1}))$)
身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^d{15}$)|(^d{18}$)|(^d{17}(d|X|x)$)
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]w{5,17}$
强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.*d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.*d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
日期格式:^d{4}-d{1,2}-d{1,2}
一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
钱的输入格式:
有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\.[x|X][m|M][l|L]$
中文字符的正则表达式:[u4e00-u9fa5]
双字节字符:[^x00-xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
空白行的正则表达式:
s*
(可以用来删除空白行)
HTML标记的正则表达式:<(S*?)[^>]*>.*?|<.*? /> ( 首尾空白字符的正则表达式:^s*|s*$或(^s*)|(s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
中国邮政编码:[1-9]d{5}(?!d) (中国邮政编码为6位数字)
IP地址:((?:(?:25[0-5]|2[0-4]d|[01]?d?d).){3}(?:25[0-5]|2[0-4]d|[01]?d?d))
3 ETL例子
在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
需求:去除日志中字段个数小于等于11的日志。需要在Map阶段对输入的数据根据规则进行过滤清洗。
WebLogMapper类
package com.study.mapreduce.weblog;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
importorg.apache.hadoop.mapreduce.Mapper;
public class WebLogMapper extendsMapper<LongWritable, Text, Text, NullWritable>{
@Override
protectedvoid map(LongWritable key, Text value, Context context) throws IOException,InterruptedException {
//1 获取1行数据
Stringline = value.toString();
//2 解析日志
booleanresult = parseLog(line,context);
//3 日志不合法退出
if(!result) {
return;
}
//4 日志合法就直接写出
context.write(value,NullWritable.get());
}
//2 封装解析日志的方法
privateboolean parseLog(String line, Context context) {
//1 截取
String[]fields = line.split(" ");
//2 日志长度大于11的为合法
if(fields.length > 11) {
returntrue;
}else{
returnfalse;
}
}
}
WebLogDriver类
package com.atguigu.mapreduce.weblog;
importorg.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WebLogDriver {
publicstatic void main(String[] args) throws Exception {
//1 获取job信息
Configurationconf = new Configuration();
Jobjob = Job.getInstance(conf);
//2 加载jar包
job.setJarByClass(LogDriver.class);
//3 关联map
job.setMapperClass(WebLogMapper.class);
//4 设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 设置reducetask个数为0
job.setNumReduceTasks(0);
//5 设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path("D:\loginput"));
FileOutputFormat.setOutputPath(job,new Path("D:\logoutput"));
//6 提交
boolean b =job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结