您现在的位置是:首页 >技术杂谈 >【MySQL速通篇003】MySQL视图,MySQL触发器,MySQL函数,MySQL存储过程(参数分类,存储过程的增删改查等),SQL的动态执行,支持事务的存储过程,pymysql网站首页技术杂谈
【MySQL速通篇003】MySQL视图,MySQL触发器,MySQL函数,MySQL存储过程(参数分类,存储过程的增删改查等),SQL的动态执行,支持事务的存储过程,pymysql
🍀博客大纲
这篇万字博客主要包括了我对:MySQL视图,MySQL触发器,MySQL函数,MySQL存储过程(参数分类,存储过程的增删改查等),SQL的动态执行,支持事务的存储过程,pymysql等的总结,可谓非常的详细😃
文章毕竟这么长,对于文章中的一些语法,概念,例子等错误,欢迎并感谢各位读者的指出😃
PS:如果这篇博客帮助到你的话,记得关注我噻!
🏆:CSDN主页
🏆:博客园主页

🍀1、delimiter
概念:
delimiter是用来指定mysql分隔符,在mysql客户端中分隔符默认是分号(;)。如果一次输入的语句较多,并且语句中间有分号,这时需要新指定一个特殊的分隔符。比如我们指定SQL以(//)结尾而不使用默认的(;)那需要执行下面的语句
delimiter // 记得使用完要改回默认的,因为要防止其他人使用;结尾而发生错误 delimiter ;
🍀2、union 与 union all
union与union all都可以实现上下连表,但是不同的是union 会对新加入的数据进行去重,而union all不会
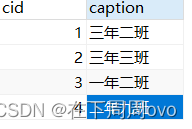
比如我有一张class表如下:
执行如下:
SELECT cid, caption FROM class UNION SELECT cid, caption FROM class 输出结果去重: cid caption 1 三年二班 2 三年三班 3 一年二班 4 二年九班 SELECT cid, caption FROM class UNION SELECT cid, caption FROM class 输出结果不去重: cid caption 1 三年二班 2 三年三班 3 一年二班 4 二年九班 1 三年二班 2 三年三班 3 一年二班 4 二年九班
🍀3、MySQL视图
什么是视图?
答:先不说概念,首先假设我们在MySQL操作中不断会使用到
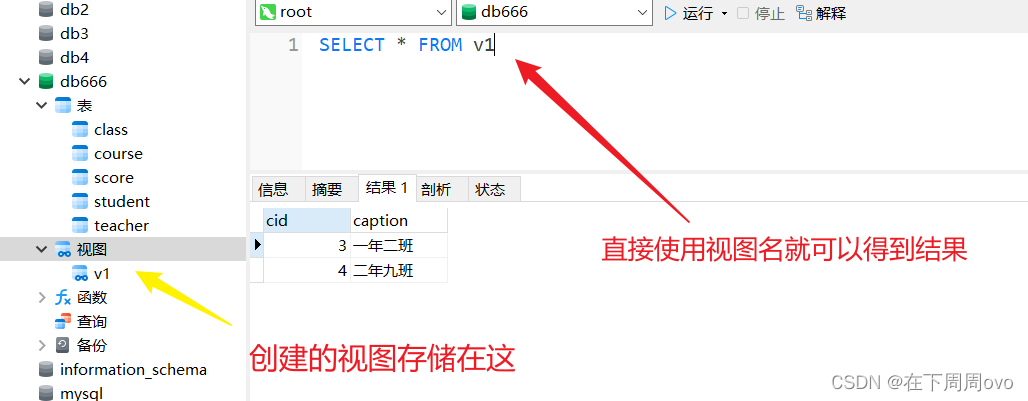
SELECT * FROM class WHERE cid>2这一条语句,那每当我们要使用这条语句的时候,就要重复书写,这样是十分麻烦的,那么我们可不可以将这一句会重复使用到的语句取个别名比如叫**“v666”**,每当我们要使用这条语句的时候只要用它的别名来代替那么就会十分省事,我们将给MySQL语句取别名的过程就叫做创建视图相当于基于存在的物理表而创建了一张虚拟表视图的创建方法:
CREATE VIEW 视图名称 AS 需要取别名的SQL语句 列如: CREATE VIEW v1 AS SELECT * FROM class WHERE cid>2
问题一:如果我们在class表中增加一条数据,基于class表产生的视图中的数据会发生改变吗?
答案:视图中会发生动态的改变
问题二:我们可以向创建出来的视图中(也就是所说的虚拟表)中插入数据吗?例如执行以下的语句
INSERT INTO v1(xx, xx) VALUES(xx,xx)吗?答案:都说了视图是创建出来的方便查询的虚拟表,那当然是不可以的如果执行上面的语句是百分百会报错的
🍀4、MySQL触发器
🍁4.1、创建触发器
什么是触发器?
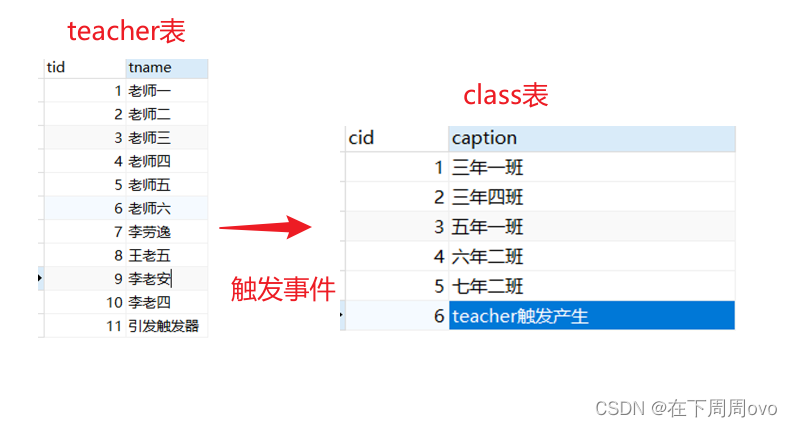
答:触发器(TRIGGER)是由事件来触发某个操作。这些事件包括insert语句、update语句和delete语句查询是不会引发的。当数据库系统执行这些事件时,就会激活触发器执行相应的操作。比如我有两张表分别为【class】【teacher】比如我只要在teacher表中插入一条数据,对应的class会触发在表中插入相应的数据,要实现这种关系我们就要使用到触发器
触发器的实现:
1、在MySQL中,创建只有一个执行语句的触发器的基本形式如下: create trigger 触发器名 before | after 触发事件 on 表名 for each row 执行语句 1、MySQL中,触发器触发的执行语句可能有多个。创建有多个执行语 句的触发器的基本形式如下: create trigger 触发器名 before | after 触发事件 on 表名 for each row begin 执行语句列表; end实例:
-- 创建触发器 -- 方法1 -- delimiter // -- CREATE TRIGGER t1 BEFORE INSERT ON teacher FOR EACH ROW -- BEGIN -- INSERT INTO class(caption) values("触发产生"); -- END// -- delimiter ; -- 方法2 -- CREATE TRIGGER t1 BEFORE INSERT ON -- teacher FOR EACH ROW INSERT INTO class(caption) values("触发产生"); -- 执行触发事件 INSERT into teacher(tname) VALUES("引发触发器"); 如果执行下面的语句触发器将会执行两次,因为向teacher表中插入了两行数据 INSERT into teacher(tname) VALUES("引发触发器1"),("引发触发器2");
🍁4.2、触发器之 NEW与OLD
mysql触发器中, NEW关键字,和 MS SQL Server 中的 INSERTED 和 DELETED 类似,MySQL 中定义了 NEW 和 OLD,用来表示触发器的所在表中,触发了触发器的那一行数据。
具体地:
在 INSERT 型触发器中,NEW 用来表示将要(BEFORE)或已经(AFTER)插入的新数据;
在 UPDATE 型触发器中,OLD 用来表示将要或已经被修改的原数据,NEW 用来表示将要或已经修改为的新数据;
在 DELETE 型触发器中,OLD 用来表示将要或已经被删除的原数据;
使用方法: NEW.columnName (columnName 为相应数据表某一列名)
另外,OLD 是只读的,而 NEW 则可以在触发器中使用 SET 赋值,这样不会再次触发触发器,造成循环调用。栗子:
CREATE TRIGGER t1 BEFORE INSERT ON teacher FOR EACH ROW INSERT INTO class(caption) values(NEW.tname);//触发器插入的数据为teacher新插入数据的sname
🍁4.3、查看触发器
方式1:查看当前数据库的所有触发器的定义
SHOW TRIGGERS;方法2: 查看当前数据库中某个触发器的定义
SHOW CREATE TRIGGER 触发器名方式3:从系统库information_schema的TRIGGERS表中查询触发器的信息
SELECT * FROM information_schema.TRIGGERS;
🍁4.4、删除触发器
DROP TRIGGER IF EXISTS 触发器名称;
🍀5、MySQL函数
🍁5.1、执行函数
可以用以下语句来执行mysql的内置函数,以及自定义函数
select 函数栗子:
-- 内置的求字符串长度的函数 SELECT CHAR_LENGTH('abcdefg') as len 返回结果: ---- len ---- 7 ----
🍁5.2、创建函数
mysql创建函数可能会报的错误以及解决的方法:
mysql函数报错:This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled这是因为创建函数、存储过程、触发器这类操作会写入二进制日志,当有主丛模式的时候这些功能也会进入从服务器,然而这些操作的重复执行会导致主从数据不一致,因此MySQL要求:此时在主服务器上,子程序必须声明为确定性的或者不更改数据,否则创建或者替换子程序就会被拒绝。这就是上面报错的原因,
报错中已经提级可用的参数:DETERMINISTIC, NO SQL, or READS SQL DATA 三者之一,实际有以下5个参数,但在function里面,只有 DETERMINISTIC, NO SQL 和 READS SQL DATA 被支持。如下:
1 DETERMINISTIC 确定的
2 NO SQL 没有SQl语句,不修改数据
3 READS SQL DATA 只读取数据,不修改数据
4 MODIFIES SQL DATA 修改数据
5 CONTAINS SQL 包含SQL语句原文链接附上非常详细:mysql函数报错解决方法
从上面的栗子我们可以得知函数体内不能够存在类似于select等修改数据的语句
方法如下:
CREATE FUNCTION <函数名> ( [ <参数1> <类型1> [ , <参数2> <类型2>] ] … ) RETURNS <返回类型> <函数主体>栗子:
delimiter \ create function f1( var1 int, var2 int ) returns int -- 此处加上声明没有SQL语句。才能成功创建函数 NO SQL begin -- 将int变量num的默认值为0 declare num int default 0; set num = var1 + var2; -- 设置返回值 return(num); end \ delimiter ; 执行函数: SELECT f1(1, 2) 输出结果: --------+ f1(1, 2) --------+ 3 --------+
🍀6.存储过程
🍁6.0、概念
什么是存储过程?
存储过程是一组为了完成特定功能的 SQL 语句集合。使用存储过程的目的是将常用 或复杂的工作预先用 SQL 语句写好并用一个指定名称存储起来,这个过程经编译和 优化后存储在数据库服务器中,因此称为存储过程。当以后需要数据库提供与已定义 好的存储过程的功能相同的服务时,只需调用“CALL存储过程名字”即可自动完成。
🍁6.1、参数分类
存储过程的参数类型可以是in、out和inout
下面我们来具体介绍这些吗参数的作用:
1、没有参数(无参数无返回) 2、仅仅带 IN 类型(有参数无返回) 3、仅仅带 OUT 类型(无参数有返回) 4、既带 IN 又带 OUT(有参数有返回) 5、带 INOUT(有参数有返回) 注意: IN、OUT、INOUT 都可以在一个存储过程中带多个。 说明: IN:当前参数为输入参数,也就是表示入参; 存储过程只是读取这个参数的值。如果没有定义参数种类,默认就是 IN,表示输入参数。 OUT:当前参数为输出参数,也就是表示出参; 执行完成之后,调用这个存储过程的客户端或者应用程序就可以读取这个参数返回的值了。 INOUT:当前参数既可以为输入参数,也可以为输出参数。
🍁6.2、创建存储过程
方法:
create procedure 存储过程名( IN|OUT|INOUT 参数名 参数类型,... ) [characteristics ...] BEGIN 存储过程体 END栗子:
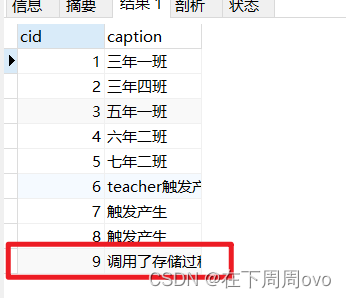
create procedure p1() begin INSERT INTO class(caption) VALUES ("调用了存储过程"); SELECT * from class; end
🍁6.3、调用存储过程
方法:
call 存储过程名(实参列表)调用存储过程
call p1()输出结果:
格式:
1、调用in模式的参数:
CALL p1('值');2、调用out模式的参数:
特别的由于存储过程中没有一个类似于return的可返回返回值的关键字,所以我们有结果集以及使用out伪造一个类似于返回值的效果。@加变量名,相当Python中声明了一个全局变量,存储过程中out变量的改变可以改变外部的@变量名的值,从而得到类似于返回值的效果
SET @name; CALL p1(@name); SELECT @name;栗子下面这个栗子在6.8还要用到:
创建存储过程
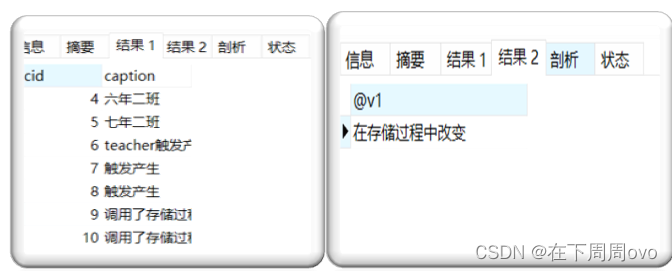
delimiter // create procedure p2( in n1 int, out n2 char(15) ) begin set n2 = "在存储过程中改变"; SELECT * FROM class WHERE cid > n1; end // delimiter ;执行下面的语句:
set @v1 = "开始值"; call p2(3, @v1); select @v1;
3、调用inout模式的参数:
SET @name=值; CALL p1(@name); SELECT @name;
🍁6.4、conn.cursor()
概念:
这个函数是pymysql用来调用存储过程的,语法如下:
conn.cursor('存储过程的名称')示例【还是用上面的class表】:
import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='@123456', db='testdb', charset='utf8') # 创建游标 cursor = conn.cursor() # 调用存储过程p1 cursor.callproc('p1') conn.commit() print(cursor.fetchall()) cursor.close() conn.close() 输出结果: ((1, '三年一班'), (2, '三年四班'), (3, '五年一班'), (4, '六年二班'), (5, '七年二班'), (6, 'teacher触发产生'), (7, '触发产生'), (8, '触发产生'), (9, '调用了存储过程'), (10, '调用了存储过程'))
🍁6.5、删除存储过程
语法:
DROP PROCEDURE [IF EXISTS] 存储过程名
🍁6.6、查看存储过程
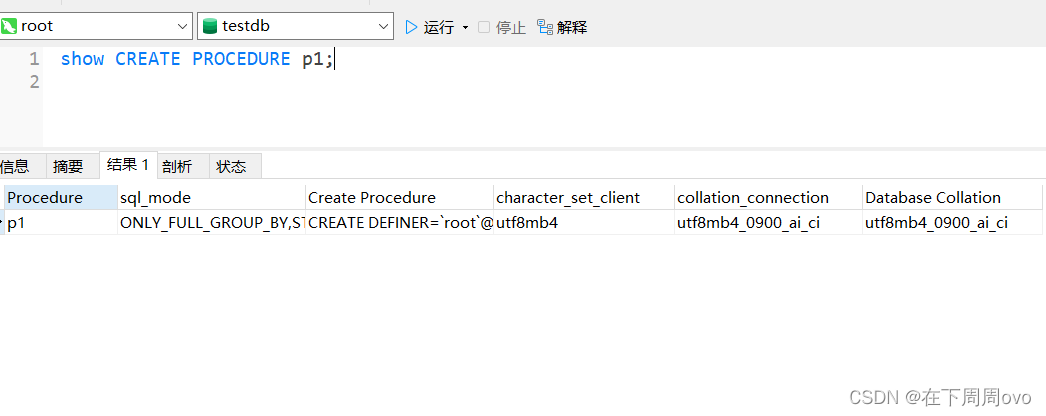
- 使用SHOW CREATE语句查看存储过程和函数的创建信息
语法:
SHOW CREATE PROCEDURE 存储过程名
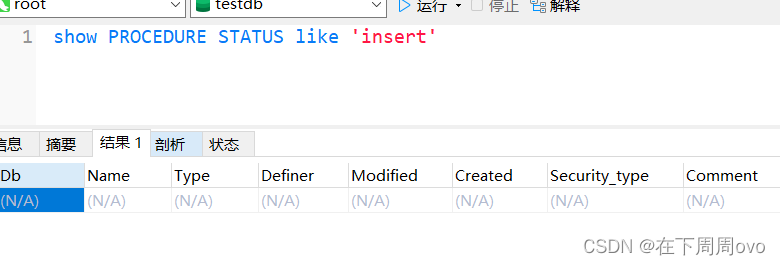
- 使用SHOW STATUS语句查看存储过程和函数的状态信息:
这个语句返回子程序的特征,如数据库、名字、类型、创建者及创建和修改日期。
[LIKE 'pattern']匹配存储过程的名称,可以省略。当省略不写时,会列出MySQL数据库中存在的所有存储过程的信息。语法:
SHOW PROCEDURE STATUS [LIKE 'pattern']
3、使用SHOW STATUS语句查看存储过程和函数的状态信息:
MySQL中存储过程的信息存储在information_schema数据库下的Routines表中。可以通过查询该表的记录来查询存储过程和函数的信息。
语法结构:
SELECT * FROM information_schema.Routines WHERE ROUTINE_NAME='存储过程的名' [AND ROUTINE_TYPE = 'PROCEDURE'];说明: 如果在MySQL数据库中
存在存储过程和函数名称相同的情况,最好指定ROUTINE_TYPE查询条件来指明查询的是存储过程还是函数。
🍁6.7、修改存储过程
修改存储过程,不影响存储过程功能,只是修改相关特性。使用ALTER语句实现。
ALTER PROCEDURE 存储过程名;
🍁6.8、pymysql实现拿结果集
我使用6.3中2、调用out模式的参数:的存储过程的栗子
存储过程:
delimiter // create procedure p2( in n1 int, out n2 char(15) ) begin set n2 = "在存储过程中改变"; SELECT * FROM class WHERE cid > n1; end // delimiter ;python代码:
import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='@123456', db='testdb', charset='utf8') # 创建游标 cursor = conn.cursor() # 调用存储过程,并且传参数 cursor.callproc('p2', (8,"开始值")) print(cursor.fetchall()) # 拿到结果集 cursor.execute('select @_p2_0,@_p2_1') print(cursor.fetchall()) cursor.close() conn.close() 输出结果: ((9, '调用了存储过程'), (10, '调用了存储过程')) ((8, '在存储过程中改变'),)
cursor.execute('select @_p2_0,@_p2_1')@_p2_0表示拿p2中第一个参数,因为第一个参数是in得到的就是传入的值,@_p2_0_1表示拿p2中第二个参数,因为第二个参数是out所以得到的就是在存储过程中发生改变后的变量的值,,如果是inout的话就会根据变量在存储过程中是否发生改变而返回对应的结果【不改变的话就是传入的参数,改变的就是在存储过程中发生改变的值】我们也可以如下的方法:
set @_v1_0 = 8; set @_v1_1 = "开始值"; call p2(@_v1_0, @_v1_1); select @_v1_0, @_v1_1; 输出结果: 结果一 结果二 +---------------------+ +--------------------+ cid caption @_v1_0 @_v1_1 9 调用了存储过程 8 在存储过程中改变 10 调用了存储过程 +---------------------+ +---------------------+
🍁6.9、其他拓展内容
⚡6.9.1、LOOP实现
实现的需求,假如我有一张A表如下
id num 1 9 2 8 3 4要实现循环拿到A表中每一行的id与num 并且将他们的值分别对应相加放到B表中的num列
实现的B表示例如下:
id num 1 10 2 10 3 7实现答案:
delimiter // create procedure p6() begin -- 自定义变量用来存储每一行id值 declare row_id int; declare row_num varchar(50); -- 如果done为false表示还没有终止,下面的游标还能继续执行 declare done int default false; declare temp int -- 去A表中逐行取数据,相当于遍历A表中的每一行 declare my_cursor cursor for select id, num from A; -- 游标终止的条件 ,检测当A表中没有数据done = ture就退出 declare continue handler for not found set done = ture; -- 创建游标 open my_cursor; -- 表示开启循环 loop表示循环 loop_label: LOOP fetch my_cursor into row_id, row_num; IF done THEN LEAVE loop_label; END IF; set temp = row_id + row_num; INSERT INTO B(num) VALUES(temp); -- 循环终止的条件 END LOOP loop_label; end // delimiter ;
⚡6.9.2、条件语句
delimiter \ -- 创建一个条件存储过程 CREATE PROCEDURE proc_if () BEGIN declare i int default 0; if i = 1 THEN SELECT 1; ELSEIF i = 2 THEN SELECT 2; ELSE SELECT 7; END IF; END\ delimiter ;
⚡6.9.3、while循环
delimiter \ CREATE PROCEDURE proc_while () BEGIN DECLARE num INT ; SET num = 0 ; WHILE num < 10 DO SELECT num ; SET num = num + 1 ; -- 结束的标识就是while不满足 END WHILE ; END\ delimiter ;
⚡6.9.4、repeat循环
delimiter \ CREATE PROCEDURE proc_repeat () BEGIN DECLARE i INT ; SET i = 0 ; repeat select i; set i = i + 1; until i >= 5 end repeat; END\ delimiter ;
🍁6.10、动态执行SQL
目的:防SQL注入
实现:
delimiter \ DROP PROCEDURE IF EXISTS proc_sql \ CREATE PROCEDURE proc_sql () BEGIN declare p1 int; set p1 = 11; -- 必须要写,在下面using后才不会报错 set @p1 = p1; -- 预检测某个东西 SQL语句的合法性,prod为自定义的变量 PREPARE prod FROM 'select * from tb2 where nid > ?'; -- @p1表示用p1的值替换上一行语句中的?号 EXECUTE prod USING @p1; -- 执行上面的已经格式化完成的SQL语句 DEALLOCATE prepare prod; END\ delimiter ;
🍁6.11、支持事务的存储过程
事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。
delimiter \ create PROCEDURE p1( -- p_return_code根据值的不同用来表示状态 OUT p_return_code tinyint ) BEGIN -- 设置发生SQL异常退出 DECLARE exit handler for sqlexception BEGIN -- ERROR(错误时返回1) set p_return_code = 1; -- 回滚到未发生错误时的初始状态 rollback; END; -- 设置发生SQL警告退出 DECLARE exit handler for sqlwarning BEGIN -- WARNING(警告时返回2) set p_return_code = 2; -- 回滚到初始状态 rollback; END; -- START TRANSACTION立即启动一个事务,而不管当前的提交模式设置如何。 -- 无论当前的提交模式设置如何,以START transaction开始的事务必须通过 -- 发出显式COMMIT或ROLLBACK来结束。 START TRANSACTION; DELETE from tb1; insert into tb2(name)values('seven'); -- 因为没有发生错误,就将更改的数据提交 COMMIT; -- SUCCESS(成功时返回0) set p_return_code = 0; END\ delimiter ;
🍀7、其他
MySQL中如果对性能的要求比较高的话,一般是不推荐使用函数的,因为函数的使用可能会破坏索引加速查找的效果。可以在程序或者架构级别使用函数操作,有创建函数的想法时先看看有没有内置函数可以满足,避免重复造轮子😀






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结