您现在的位置是:首页 >技术杂谈 >YOLO学习(四):工作流程网站首页技术杂谈
YOLO学习(四):工作流程
1.概述
CNN通用结构
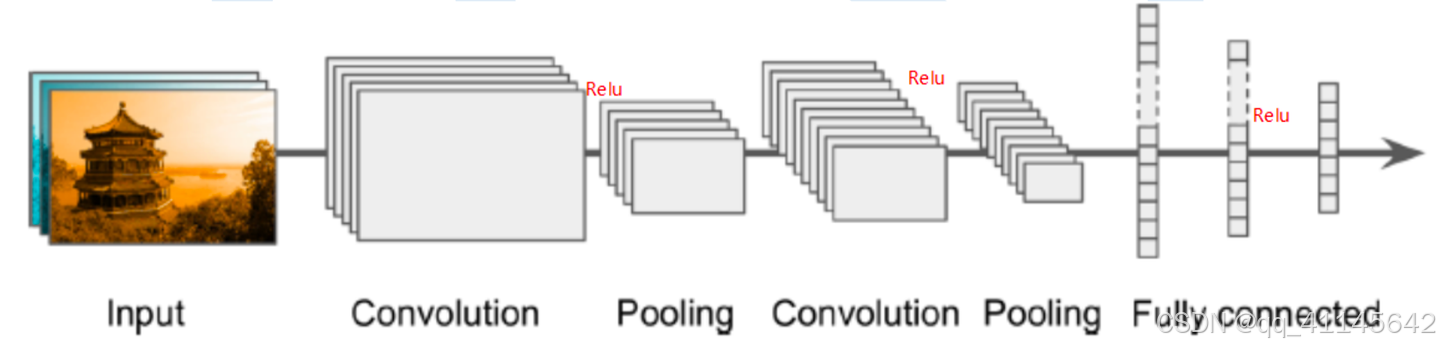
2.输入层
2.1 resize调整尺寸
YOLO模型通常要求输入图像具有固定的尺寸,比如416x416、608x608等。选择具体的尺寸取决于你使用的YOLO版本以及你的具体需求(例如速度与准确性的平衡)。较大的输入尺寸可能会提高检测精度,但同时也会增加计算成本和时间。常见的缩放方法有:等比例缩放、非等比例缩放和等比例缩放后填充。
2.1.1等比例缩放
方法:计算图像的宽高比,根据目标尺寸和原始图像的宽高比确定缩放后的尺寸,确保图像在缩放过程中保持原来的宽高比例。例如,如果原始图像宽高比为 3:2,目标尺寸要求宽度为 416 像素,那么根据宽高比可计算出高度应为约 277 像素。
优点:能保持图像的原始比例,不会使图像产生变形,物体的形状和空间关系得以正确保留,有利于模型准确识别物体。
缺点:可能导致图像在填充到目标尺寸时出现黑边或留白,因为缩放后的图像尺寸不一定能刚好与目标尺寸完全匹配。
2.1.2非等比例缩放
方法:直接将图像的宽度和高度分别按照目标尺寸进行缩放,不考虑原始图像的宽高比。例如,无论原始图像的宽高比是多少,都将其宽度缩放到 416 像素,高度缩放到 416 像素。
优点:可以使图像完全适应目标尺寸,不会出现黑边或留白的情况,能充分利用输入空间,在一定程度上可能提高模型的计算效率。
缺点:会使图像产生变形,可能导致物体的形状和空间关系发生改变,影响模型对物体的准确识别,尤其是在物体形状和比例对识别结果很重要的情况下,可能会降低模型的精度。
2.1.3等比例缩放后填充
方法:先按照等比例缩放的方式将图像缩放到最大尺寸,使得图像的宽或高至少有一个维度与目标尺寸相等,然后将缩放后的图像居中放置在目标尺寸的图像中,其余部分用固定颜色(如黑色)进行填充。例如,原始图像宽高比大于目标尺寸的宽高比,先将图像宽度缩放到目标宽度,高度按比例缩放后小于目标高度,再将缩放后的图像放在目标尺寸图像的中心,上下部分用黑色填充。
优点:既保持了图像的原始比例,又能使图像完整地填充到目标尺寸中,避免了黑边过多或图像变形的问题,能在一定程度上平衡图像的原始信息保留和模型输入要求。
缺点:填充部分可能会引入一些无关信息,对模型的注意力机制可能产生一定的干扰,不过通常情况下这种干扰相对较小。
在实际应用中,具体选择哪种缩放方式,需要根据具体的任务需求、数据特点以及模型性能表现等因素来综合考虑和试验,以找到最适合的方法来提高 YOLO 模型的检测效果。
(2)代码示例
下面是一个简单的代码示例,展示如何使用OpenCV进行图像resize的同时保持宽高比:
import cv2
def resize_image(image, target_size):
# 获取原始图像尺寸
original_height , original_width = image.shape[:2]
target_height, target_width = target_size
# 计算缩放比例
ratio = min(target_width / original_width, target_height / original_height)
new_width = int(original_width * ratio)
new_height = int(original_height * ratio)
# 调整大小
resized_image = cv2.resize(image, (new_width, new_height))
# 创建一个新的空白图像(用灰色填充)
result_image = 127 * np.ones((target_height, target_width, 3), dtype=np.uint8)
# 计算将图像放置在中心位置所需的坐标
x_offset = (target_width - new_width) // 2
y_offset = (target_height - new_height) // 2
# 将调整大小后的图像复制到结果图像的中央
result_image[y_offset:y_offset+new_height, x_offset:x_offset+new_width] = resized_image
return result_image
# 示例使用
image = cv2.imread('your_image_path.jpg')
resized_image = resize_image(image, (416, 416))
(3)示例
以输入图像为448 x 448为例,要使用YOLO模型,首先必须将RGB图像转换为448 x 448 x 3的张量。
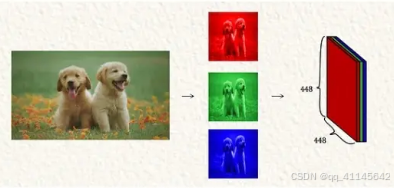
为了便于数学运算,下面将使用一个5 x 5 x 1张量进行说明。
| 1 |
3 |
255 |
4 |
7 |
| 255 |
4 |
7 |
50 |
100 |
| 80 |
32 |
255 |
4 |
7 |
| 4 |
100 |
32 |
80 |
20 |
| 50 |
7 |
4 |
1 |
7 |
2.2 归一化处理
2.2.1什么是BN
BN(Batch Normalization)批归一化是由Google于2015年提出,这是一个深度神经网络训练的技巧,它不仅可以加快了模型的收敛速度,而且更重要的是在一定程度缓解了深层网络中“梯度弥散”的问题,从而使得训练深层网络模型更加容易和稳定。所以目前BN已经成为几乎所有卷积神经网络的标配技巧了。
从字面意思看来Batch Normalization(简称BN)就是对每一批数据进行归一化。对于训练中某一个batch的数据{x1,x2,...,xn},注意这个数据是可以输入也可以是网络中间的某一层输出。在BN出现之前,我们的归一化操作一般都在数据输入层,对输入的数据进行求均值以及求方差做归一化。BN打破了这一个规定,我们可以在网络中任意一层进行归一化处理,因为我们现在所用的优化方法大多






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结