您现在的位置是:首页 >其他 >做爬虫,学会它就够了?网站首页其他
做爬虫,学会它就够了?
大家好,我是阿爬!这里是讲述阿爬和阿三爬虫故事的爬友圈
作为一个爬虫开发工程师,大家都知道

逆向是非常耗时、耗神的,而且涉及的知识面也非常广,对于开发的时间成本也比较高,那么相比之下自动化框架的爬虫就会有一定的优势,本期就做一个自动化爬虫分享,而且个人觉得这个自动化框架也非常强大。
一、使用它的原因
本期的目标网站是:eWFvamlhbmp1CiA=;众所周知这个网站的最大的反爬就是rs,并且也在不断的升级,目前的版本好像是6

在此之前也曾尝试过用selenium去做自动化爬虫,发现网站对selenium做了很多特征检测,导致使用selenium开发的时间成本也增加了。于是现在换一个自动化框架来绕过rs的反爬,提升开发效率。最近也是一个偶然的机会接触到了它,据说没有任何selenium的特征,就像来试一试看是否能轻松获取到数据,其次再看看效率如何。
使用它的原因:
1、能过特征检测。
2、各个标签之间cookie能共享;
3、不紧可以获取html数据,还可以获取接口数据包(不需要逆向、不需要逆向、不需要逆向);

4、同样支持xpath、selector等方式
二、获取数据的方式
共享一个page对象:
首先需要创建一个page对象,直接使用page.get()方法访问目标网站;
其次是定位元素,ele=page.ele()方法定位元素,可以传一个字符串,格式为:’xpath:/html/body/div[9]/div[2]/div[1]/ul/li[1]/a‘。
如果需要点击使用ele.click();需要输入内容使用ele.input();
元素问题解决了接下来看内容获取。
1、获取html中的相关数据 获取元素下所有文本信息:ele.ele().text;获取HTML:ele.ele().html;获取属性:ele.ele().attr();获取链接地址:ele.ele().link;接下来看对目标网站的文本内容获取的结果
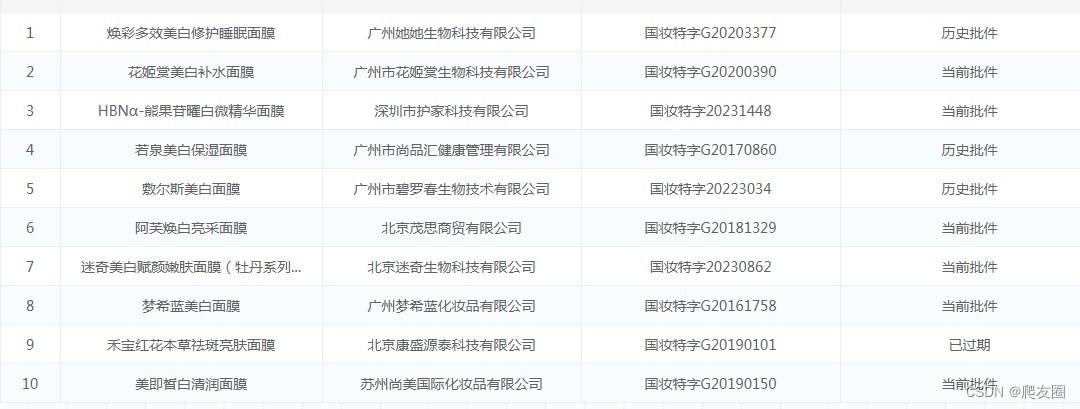

2、直接获取接口数据
监听接口数据:有个set_targets()方法,传入目标接口地址,部分也可以;
接收接口数据:data_packets()方法,返回一个response对象,调用其body属性即可获取到相关数据,看一下实际效果
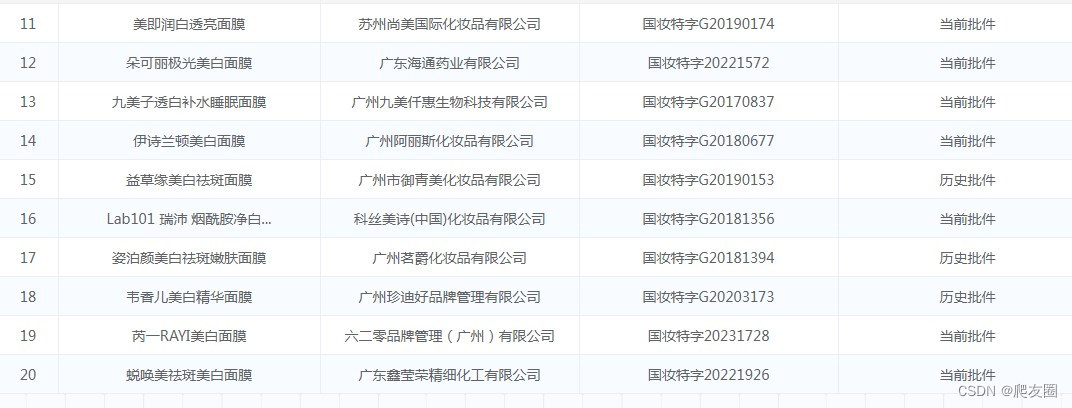

此功能个人认为是最大的亮点,可以省去逆向,提升开发效率,减少时间成本,感觉比在web端做了一个rpc用起来还更舒服,实属妙哉!
三、总结
本期内容的重点是想说找到了绕过rs获取数据的爬虫方案,通过此自动化框架可以做很多事情(做过自动化爬虫的都懂的),基本上这个方案可以抓取大多数网页数据,解决掉大部分问题。当然验证码、滑块、风控这些依然需要想办法解决,最后贴出框架:Jycuam9pbihbJ3BhZ2UnLCAnc3Npb24nLCdkcmknXVs6Oi0xXSkKIA==
欢迎大家评论区留言,关注阿爬了解更多爬虫故事!
特别声明:本文章只作为学术研究,不作为其他不法用途;如有侵权请联系作者删除。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结