您现在的位置是:首页 >其他 >移动端图形API通讲(一)--从Gles、Vulkan到Metal网站首页其他
移动端图形API通讲(一)--从Gles、Vulkan到Metal
引言
一直想整理下关于移动端图形编程API的文档。图形API为何重要?如果说图形编程的内功是计算机图形学的诸原理和算法,那么外功就是实实在在的硬件API。不能精通API的使用,就无法把渲染特性合适高效的实现。
当我们设计引擎的渲染硬件接口层的时候,要面对移动端图形API的三座大山Gles,Vulkan,Metal,他们因为被封装在驱动里,是一些我们只看得到晦涩的接口而看不到实现的黑盒,这是初学者学习API的一个主要阻碍。其实把他们放在一起学习,放在一起横向比较,会更容易发现一些图形API设计上的哲学。
所以这系列文档的一个主要目的是把这三大API放在一起的学习的教学文档,但还有一个目的是试图比较总结他们背后的共性和差异,以试图更容易理解图形API设计上的通用思想。
Vulkan之于图形编程可比C++之于CPU编程,相比下OpenGLes更像脚本语言,所以传统上以Gles为入门API的学习因为看不到图形编程的底层和全貌反而更加不容易让人掌握。Vulkan虽然庞大复杂,但它是一个很纯粹,完整的理解图形编程的API,所以本文档将以Vulkan为主要脉络,以gles和metal为对比实现来讲解,以让读者先建立图形API设计的主要思想,然后看下gles和metal分别从基础和高级的倾向上如何在驱动中为我们隐藏一些实现的。
大多数VK/gles的入门教程都会试图用最简单的十几行代码叫我们如何画出一个三角形,但是读者不免会有疑问,为什么我用这样十几个API调用之后GPU就为我画了三角形,少调用其中某个API会怎样?这个文章我不以实现某个渲染效果为导向,也不使用类似Reference Document中介绍API使用的顺序,而是按照图形API设计的角度试图从基础到复杂来解构,将分成如下章节:
- 数据
- 提交
- 同步
- 内存
- 管线
- 对象
- 命令
- 扩展
- 其它
本篇将是第一篇,介绍最基础的数据和提交模型
希望争取后面每个月可以更新一篇。另外文字量较大,唯恐有重要点的遗漏之处,如有错误的表述和理解,欢迎指正。
一、数据
数据类型
任何一个API都可以分成两部分,CPU一侧的驱动API和GPU一侧的shader代码,shader 编程是一套相对自成体系的GPU编程内容,使用的是GPU一侧定义的数据类型,本文只介绍CPU一侧的API编程部分。
在CPU一侧,API使用的基本数据结构可以分为几三类:
1.简单数据结构,因为这些API都是基于C++的,所以可以使用C++中的所有的数据类型,metal因为属于IOS的编程语言Obj-c/Swift的一部分,所以它的数据类型也是IOS编程语言的一部份,但是Vulkan/Gles一般都还会有一些额外的定义,大多为了跨平台的兼容考虑(布尔值,指针类型,各种精度的浮点数和定点数)。
例如
| Vulkan | gles | |
| 布尔值 | VkBool32/ VK_TRUE/VK_FALSE | glboolean |
| 地址 | VkDeviceAddress | |
| 浮点/定点数 | glbitfield/glhalf/glfixed16 /GLfloat/GLclampf/... | |
2.device(GPU上的)资源
gl和vulkan在CPU一侧都将GPU资源看成一个handle
GL上统一都用这个原始的handle (GLuint)表示
Vulkan则将handle继续typedefine成新的数据类型,如VKBuffer VkImage
Metal则将资源封装到实在的对象中,如MtlBuffer MtlImage
3.提交相关的数据
Gles为我们隐藏了提交的实现细节,所以没有定义这类数据
而现代API则都需要抽象如下概念:
图形设备 Device (如VKDevice MTLDevice)
提交队列 Queue (如VKQueue MtlCommandQueue)
提交指令 Command Buffer(如VkCmdBuffer MtlCommandBuffer)
这些数据大多数不是thread-safe的
对象创建
这里指的是资源类和提交相关结构的实例创建。
一旦对象被创建,对象的结构一般是不变的,只有里面的数据会改变
gles风格的创建API:
gles为我们隐藏了创建的细节,大多数object是先通过GenObject产生handle,在BindObjec时同时创建object并bind到handle,
如创建buffer:
id = glGenBuffer() 产生一个buffer名字或handle
glBindBuffer(target, id) 创建这个buffer对象的实体,并把它通id这个handle绑定,后面用id来操纵对象
gldeletebuffer(id) 释放这个buffer对象,回收名字
也有少量的object有单独的创建api。
高级API:
一般有两种创建方式:
1.直接创建:由于性能不好,要低频使用
vk上如vkCreatexxx,一般用VKxxxCreateInfo作为参数
对应vkDestroyxxx
metal上如
[device newBufferWithLength: bufferSize options:MTLResourceStorageModeShared];
2.从池创建:性能较高
首先需要先创建这个资源类型的资源池,再从池子中分配
vk上如vkAllocatexxx,一般使用VKxxxallocateinfo作为参数,需要先创建这个池
对应 vkFreexxx
metal上则叫做从heap创建,一般要先创建一个metal heap,然后再heap上调用
如[heap newBufferWithLength:bufferSize options:MTLResourceStorageModePrivate];创建一个buffer
数据查询
我们有查询数据的需求,
要么查询全局上下文上的,如当前绑定的管线状态,
要么查询某种对象的,如某个handle的buffer的大小。
Metal上对象都有实在的数据结构,因此可以直接从这些对象上获取
Gles则依靠一些全局API获取,一般用glGetBoolean/interget/float/interger64v/pointer_v/string查询context上的属性
用各种GetXXX类型的API查询object上的属性,相对有些乱,如
GetvertexAttribute查询VAO相关,
GetBufferparameter查询一个buffer 对象的,
GetShader查询某个shader的,
GetSyncs查询某个syncobject对象等
Vulkan则不提供类似查询接口,因为事实上所有数据都是我们自己设置的,vulkan认为我们app测有能力记住这些数据(你会发现不维护多余数据和状态是vulkan的设计哲学之一)。
二 、提交
提交是API的终极目的,我们使用图形API编程的目的就是为了让CPU通过指令控制GPU工作,而最后的一道工序都是为了将指令提交给GPU,所以有必要先了解为了这个终极目的,各种API是怎样工作的,他们的差异很大,但是殊途同归。
图形指令提交的基本模型

上图是APP使用图形处理器绘制图形的基本流程,APP通过调用图形API指挥显卡驱动调度GPU工作。首先明确这里面有四个重要的动作:
API CALL, Command Record, Command Submit,Command Execute。
另外他们工作在两个大的领域上,HOST和DEVICE,这是一个生产者-消费者模式。
HOST为生产者,在Host上有我们的APP,有显卡driver,HOST会产生四个里面的三个关键动作:API CALL, Command Record, Command Submit。HOST一般在CPU上。
(1)API CALL
这发生在APP的渲染线程上,即APP调用图形API命令显卡工作,API一般又分为两大类型:立即执行类,和指令缓存类。
立即执行类API:这类工作立即调用执行,如对资源的创建,查询管线状态,在vulkan上所有不以vkcmd开头的指令都属于这一种,这类API的瓶颈直接出现在APP调用API时,如短时间大量的资源创建。
指令缓存类API:很多渲染工作可以被拆分成一系列的渲染指令,并存在先后时序,数量众多,如需要先设置rt,再设置各种管线状态,最后执行绘制,这些指令不可能每发生一次就去马上触达device,效果会比较差,因此这类型的渲染工作通常是先压入到一个大的command buffer里,再统一提交给device的。 在Vulkan中所有以vkcmd开头的API都是这类API。指令缓存类API一半包括如下几种:设置管线状态、draw、dispatch、资源拷贝。
这类API需要3个步骤才能彻底完成工作:Command Record, Command Submit,Command Execute。
(2)Command Record
将指令缓存类API做适当的解析并压缩到command buffer里,这发生在驱动里,随着API调用而发生,多个Command buffer又会按次序加入一个提交队列Queue中,现代API还支持多个并行的queue(如vulkan和metal,gles则只有单一的queue),这样可以在多线中完成命令的录制和API call。由于渲染指令众多,Command Record通常是移动端在渲染上的最大瓶颈,也是CPU测的最大渲染瓶颈。
(3)Command Submit
APP通过显示的提交类API将queue中的内容提交给device执行,支持多线程Command Record的API也支持多线程的Submit。Submit也发生在驱动里,随着API调用而发生,虽然submit的耗时较高,但是每一帧submit的数量非常有限,大多数情况只有1次,所以通常不会成为瓶颈。
Device为消费者,即消费渲染指令进行真正图形绘制的角色,一般就是指GPU,但是GPU和device绝不是对等的概念,事实上,对于图形API来说,只要实现其规范的处理器都可以被当作device,包括CPU,甚至音视频处理器。我们在一些设备调用vkEnumeratePhysicalDevices时经常可以找到CPU。Device上只发生一个动作,即
(4)Command Execute
它从device submit上来的queue中读取指令并执行。读取和指令的顺序不一定和command在queue中的次序有关,对于多个并行提交上来的queue,读取和执行则也不保证顺序,除非强行指定queue的依赖。一句话说host的录制和提交有显示的顺序,device侧的读取和执行则没有显示顺序,需要靠一系列同步指令进行保证,后面将会提到。Command execute的瓶颈是唯一的GPU上的渲染瓶颈,它发生于复杂的gpu绘制场景上。
提交相关的基本数据结构
首先Gles没有暴露出它的提交相关数据结构,APP所知道的只有调用API CALL,驱动隐藏了对API Command的 Record。至于Comman的Submit,则是通过一些API CALL(glfinish,glreadpixel...都可能)对驱动进行暗示,让驱动觉得自己该提交了,最终还是驱动决定的何时Submit。此外GLES也只有一个command queue,我们在多线程调用API CALL,可以解决提升直接执行类API的CPU性能,但是不能提升指令缓存类API的CPU性能。
Vulkan和Metal则有显示的提交相关数据结构,让APP侧决定怎样record和何时submit,甚至如何精细化command之间的同步,如何在多线程做分工,所以他们都暴露了Host,Device,Command Buffer,Queue的概念,这个才是现代API的精彩所在。
我们下面按照上图中从大到小的概念介绍。
Host
通常代表一个APP实例,管理host一侧的一些全局状态,这个结构较轻。
vk上需要创建一个全局的VkInstance,需要传入当前APP的信息,需要使用的extension,layer等。
Metal上不需要创建类似结构。
Device
代表一个物理上的Device实例,如机器上有两块gpu,一块实现了vk的cpu,那就可能出现3个device。他们都可以以被当前APP同时使用。
Vk上通过vkEnumeratePhysicalDevices查询到所有支持的VkPhysicalDevice,然后被后面使用。
Metal 上,对于IOS,只有一个device,使用MTLCreateSystemDefaultDevice创建这个唯一默认的即可,在mac上才可能存在多个,它返回的是一个MtlDevice* 类型。
Device Group
Vulkan上还有Device Group的概念,一个Device Group的Device才能被APP同时使用。通过API
vkEnumeratePhysicalDeviceGroups来枚举当前支持的所有的Group,以及每个Group内的Device。
Metal尤其在IOS上因为只有一个Device,所以没有这个概念。
Gles上则也因为不能同时使用多个Device而没有这个概念
Device Property
我们经常要了解当前Device支持的能力,以决定我们可以用哪些渲染特性,这个在vk和metal上也有显示的封装。
Vk上可以用vkGetPhysicalDeviceProperties2查询具体某个Device的属性。这里可知道当前的vk版本号,各种指标的limit,具体的vk版本就可以决定core api支持的特性,此外还要使用vkEnumerateDeviceExtensionProperties查询当前加载的extension。
Metal上则不依靠metal的版本号,而是依靠MTLGPUFamily的概念。Metal为不同设备定义了统一的一组GPU Family的概念。

其中Common1-3和Metal3是可能支持各种硬件平台的,metal3支持a13之后的芯片。
Apple2-8针对IOS平台,例如我们一般认为支持apple3的A9处理器开始才算是目前主流移动端特性的分水岭(多数手游以A9的iphone6s为机型下限)。
MAC2则针对mac平台。
详细的所有gpu family的支持特性可参考https://developer.apple.com/metal/Metal-Feature-Set-Tables.pdf
至于Gles,通过glGetinterger/glGetstring获取当前的gles版本号和加载的扩展来推测其能力。
Logical Device
在vulkan上还特有一个VkDevice的概念,它并不是物理device,它是一个app侧管理device的一个实例,一个app可能有多个device使用,但是只有一个vkdevice,为了同物理的device区分,也可以称它为logic device。调用API vkCreateDevice()创建。
VkResult vkCreateDevice(
VkPhysicalDevice physicalDevice,
const VkDeviceCreateInfo* pCreateInfo,
const VkAllocationCallbacks* pAllocator,
VkDevice* pDevice);
创建Logical Device需要基于(Physical )Device创建,因为多数情况一般都使用一个Device(就是唯一的那个显卡),就直接指定这个physicalDevice对象,但是也可以同时使用多device,这时需要设置VkDeviceCreateInfo 参数中的pNext,将其设置为VkDeviceGroupDeviceCreateInfo,里面可以传入同physicalDevice group一样的多个device。
Queue
最终装载所有渲染指令,由Host发送到Device的数据存储,好比CPU开往GPU的列车。
它里面搭载的是一个个Command Buffer的队列(就像一节节车厢),多个Command Buffer按顺序放入一个queue中。
一个Device可能同时有多个并行工作的queue。
Metal上Queue有明确的限制,最多可以容纳64个Command Buffer。
Queue Type
一个device支持的所有queue可以按照类型被划分。如有些queue用来提交图形绘制指令的,有些queue用于提交资源传输操作的。
一个Queue也可能同时支持多个type,如vulkan上,大多情况可以找到一个支持所有type的queue,理论上可以用它提交一切,但是使用更多的queue进行合理的分工意味着更多并行的可能。
command同queue type的适配性:
不同的指令command只能提交到支持它的特定type的queue中,这是非常重要的一个规则,在vulkan上,每一个VkCmd API的最后都有一个Supported Queue Types说明,要注意它是否提交到了争取的queue里面,在metal上,不存在这个困惑,因为metal上不同的queue具有的API本来就是不一样的。
Vulkan上这个queue type称为QueueFamily,并且有4种family,对应枚举类型VKQueueFlags:
VK_QUEUE_GRAPHICS_BIT :用于提交图形绘制指令,如draw call
VK_QUEUE_COMPUTE_BIT :用于提交CS计算指令,如 dispatch
VK_QUEUE_TRANSFER_BIT :用于提交资源传输指令,如cpybuffer
VK_QUEUE_SPARSE_BINDING_BIT :用于提交sparse resource的内存绑定指令
Vulkan上没有API用来直接创建queue,而是打包在了创建logical device
的API vkCreateDevice中,作为logical device创建的一部份:
这里面要传入一个参数VkDeviceCreateInfo,用来指定当前logical device是由哪些queue组成的。这个参数里面有queueCreateInfoCount个VkDeviceQueueCreateInfo结构,
typedef struct VkDeviceCreateInfo {
VkStructureType sType;
const void* pNext;
VkDeviceCreateFlags flags;
uint32_t queueCreateInfoCount;
const VkDeviceQueueCreateInfo* pQueueCreateInfos;
uint32_t enabledLayerCount;
const char* const* ppEnabledLayerNames;
uint32_t enabledExtensionCount;
const char* const* ppEnabledExtensionNames;
const VkPhysicalDeviceFeatures* pEnabledFeatures;
} VkDeviceCreateInfo;
VkDeviceQueueCreateInfo结构如下,里面定义了创建queueCount个queueFamilyIndex类型的queue。
typedef struct VkDeviceQueueCreateInfo {
VkStructureType sType;
const void* pNext;
VkDeviceQueueCreateFlags flags;
uint32_t queueFamilyIndex;
uint32_t queueCount;
const float* pQueuePriorities;
} VkDeviceQueueCreateInfo;
也就是说,vulkan 的logical device里定义了要创建哪几种type的queue,每种type创建多少个。
这里的pQueuePriorities还可以为queue type指定优先级,但注意这是一个在cpu上处理的优先级,不是Device上的。
创建好vkdevice之后,我们就可以通过vkGetDeviceQueue()来获取其中的某个queue的指针。
Metal上只有2种queue type:
Vk上的那四种在这里统一叫做普通queue ,即Commandqueue
另外还有一种Vk没有的用来从文件系统读取文件到Device的叫做IOCommandQueue
Metal上是通过调用MtlDevice的两个不同的API分别创建这两种类型的queue
newCommandQueue
newIOCommandQueue
Command Buffer
Command Buffer是Queue传输的基本单位,他是queue这趟列车的一节车厢,上面乘坐的每个乘客就是一个基本的(缓存类)渲染指令,它是记录指令的一块内存空间。
CommandBuffer通常由他所属的queue负责创建。
在Metal中,调用MtlCommandQueue/MtlIOCommandQueue的API commandBuffer 来为这个queue创建一个Command Buffer。
在Vk上,Command Buffer不属于某个queue,而是全局上属于某个Type或QueueFamily的所有queue。所以是通过vkCreateCommandPool(device, queufamilyindex) 来制定为某个queuefamily的所有queue创建一个VkCmdBufferPool,再调用vkAllocateCommandBuffers从 这个command buffer pool创建一个Cmd Buffer,并且这个command buffer也只能被提交到该queue family type的queue中。
Command Buffer的主要操作
如前面的图所示,我们对缓存类指令的操作主要是Record和Submit。这也是Command Buffer的两种主要操作。
Command Record:
Vulkan上使用了比较简单的做法,直接使用全局的API进行各种record操作,如调用一个drawcall,就直接调用vkcmddrawprimitive函数,vulkan中所有vkcmd开头的函数都是做record用的,这类函数的第一个参数都是它record的目的地VKCommandBuffer。
既然任何vkcmdXXX API都可以传入任何cmdbuffer作为参数,那么vulkan如何保证不同的command同queue type兼容性问题?答案是没有保证,靠用户自己保证(这只是Vulkan设计哲学里,“不检查,不保证,一切靠你自己,调错就崩”的例证之一)
那么你怎么保证?vulkan中cmdbuffer是基于queuefamily创建的,所以可以认为cmdbuffer本身是带有queue type属性的了,每一条vkcmdxxx函数API的下方都有一行叫做Supported Queue Types,详细写明了这个cmd可以进入的queue type,如果你把一条cs指令record 到一个不支持cs的cmdbuffer中,结果是未知的,可能崩溃,vkvalidation layer能够检查。
Metal上则较为复杂,它封装了一个单独的类型Encoder,它用来执行将指令Record 到cmd buffer的操作。
Encoder有5种类型,用于对不同类型的指令做record(或encode),分别用MtlCommandBuffer上的5个不同API创建(MtlIOCommandBuffer比较特殊,它不使用encoder,这里不讨论):
renderCommandEncoderWithDescriptor: 创建一个 render encoder,encoder 图形相关指令
computeCommandEncoderWithDescriptor:创建一个Compute encoder, encoder compute shader相关指令
blitCommandEncoderWithDescriptor:创建一个blit encoder,encoder资源传输类指令
resourceStateCommandEncoderWithDescriptor: 创建一个Resource state encoder,encode sparse resource相关指令。
parallelRenderCommandEncoderWithDescriptor:创建一个可以多线程并行record 指令的encoder。
可以看到metal虽然没有在queue级别做过多type区分,但是在record command buffer时对encoder做了相同的区分,还是殊途同归。
此外Metal还存在一种往argument buffer(用于GPU Pipeline,后面会提到)中encode指令的特殊encoder,MTLArgumentEncoder,它是从mtlArgumentBuffer创建。
Metal使用上面创建的各种Encoder,调用其各种API进行command的record到buffer的操作,不同类型Encoder所拥有的API是不一样的,如drawcall类型的API需要到rendercommandencoder中去找drawPrimitives函数。此外一个encoder在工作完成之前(即endencode()之前),它所在的cmdbuffer,不能同时被另一个encoder操作,也可以这样理解,虽然metal上没有定义queuetype,但一个command buffer一段时间只能看作是一种queue type的。Metal通过明确定义不同类型的encoder和不同名字的API显示保证了不同类型的command只能record到不同类型的queue中。
Encode是有声明周期的,它是一个一次性使用的对象,即endencode之后,就不能再被使用了,自动被回收,下次使用需要创建一个新的出来。
Command Submit:
vulkan上首先要将一些要提交的vkcommandbuffer封装到一个VkSubmitInfo2结构中,submitinfor中的cmdbufer按照数组中的顺序被提交。同时submitinfor也是commad buffer级别在Device一侧的基本同步单位,默认情况下,cmd buffer即使提交时有顺序,在device上执行也不保证顺序,所以submitinfor中可以定义同步结构vksemphone,它可以为submitinfor和submitinfor之间定义device执行顺序。
所以,不同的command buffer依据你的device测同步需求和使用的queue不同被装入不同的submitinfo中,最终调用vkQueueSubmit2(queue,VkSubmitInfo2,vkFence)提交给device。一组submitinfor只能提交到一个queue中。
metal上简单的调用MTLCommandBuffer的commit 进行提提交。在提交前可以调用MTLCommandBufferd enqueue为他在queue上留有一个位置,buffer的enqueue的位置就是他们提交的顺序,如果没有调用过,commit也会自动为它调一下enqueue,这个提交顺序在Device上不一定严格保证还按照这个顺序执行,但是metal会自动检测到Renderpass之间的依赖关系合理的保证同步顺序,通常不需要我们额外关心。
我们用图来总结下Vulkan 和Metal 在Command Record和Submit这里的设计异同

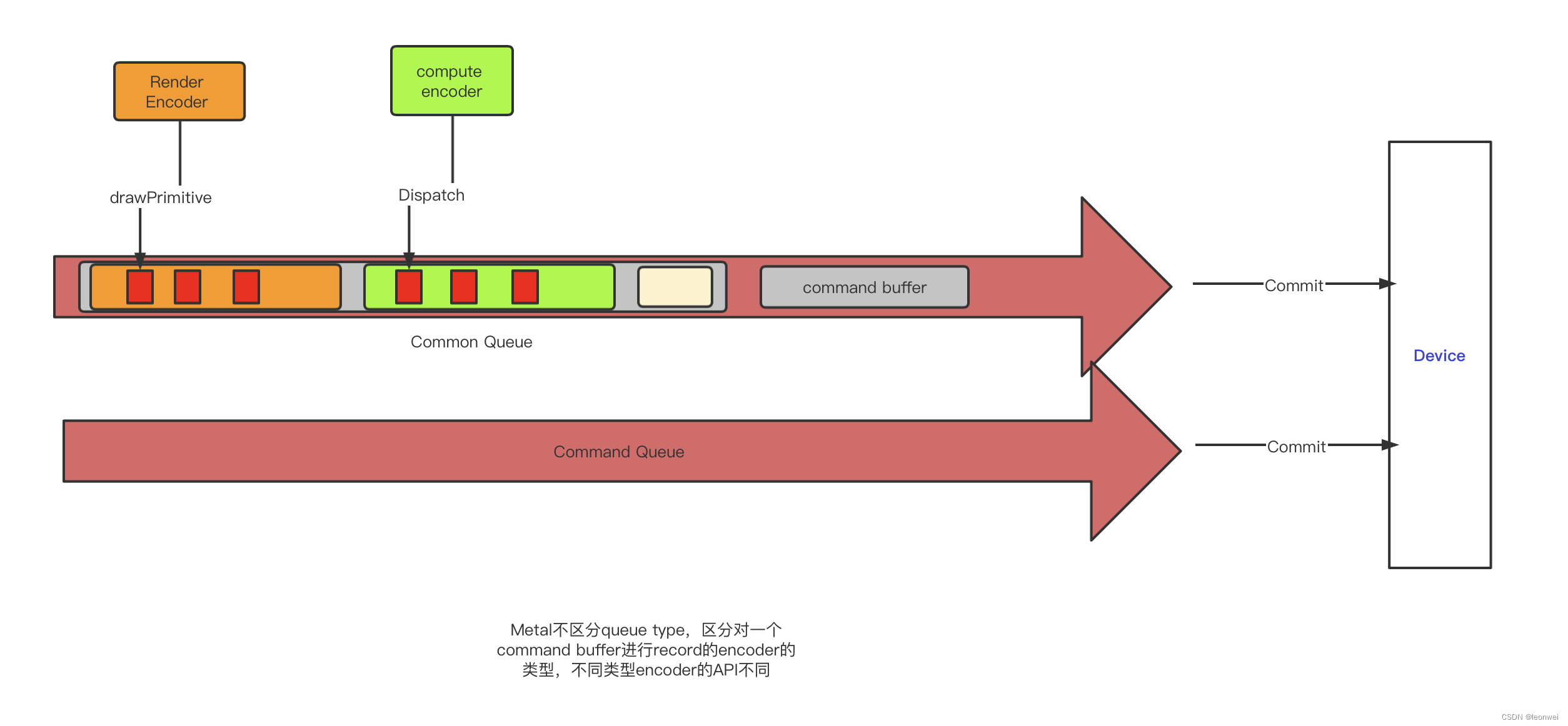
Command Buffer的生命周期
Command Buffer是容纳cmd的最小单位(一节火车箱),游戏过程中往往有大量的cmd buffer的参与,所以它的生命周期是个重要问题。
metal上非常简单
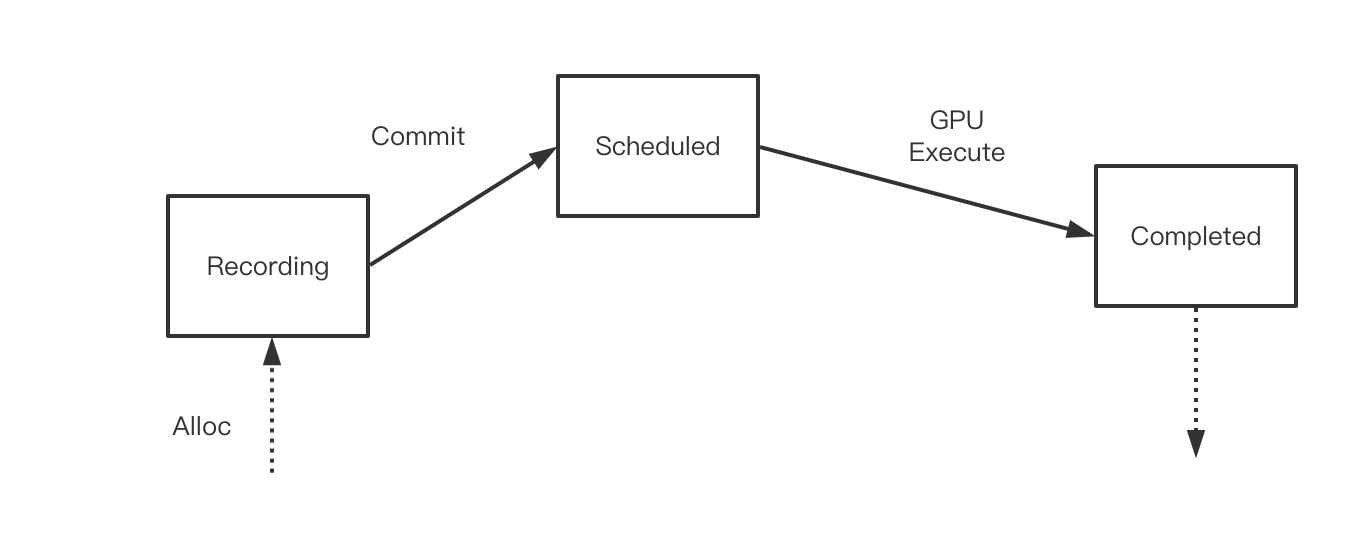
一个command buffer只有一次生命,不能被回收利用,分配出来后,经历record,commit,等GPU处理完之后自动被销毁回收。
Vulkan上这是一个相当复杂的事情,它彻底的暴露了底层cmd buffer的所有管理行为,需要用户全程负责维护他的生命周期,它不仅可以被反复record,并且cmd buffer有着更复杂的行为,包括反复提交,多线程提交等行为也是在cmd buffer这层实现的,这也是VK编程中的难点之一。
先看最简单的vkcmdbuffer的生命周期
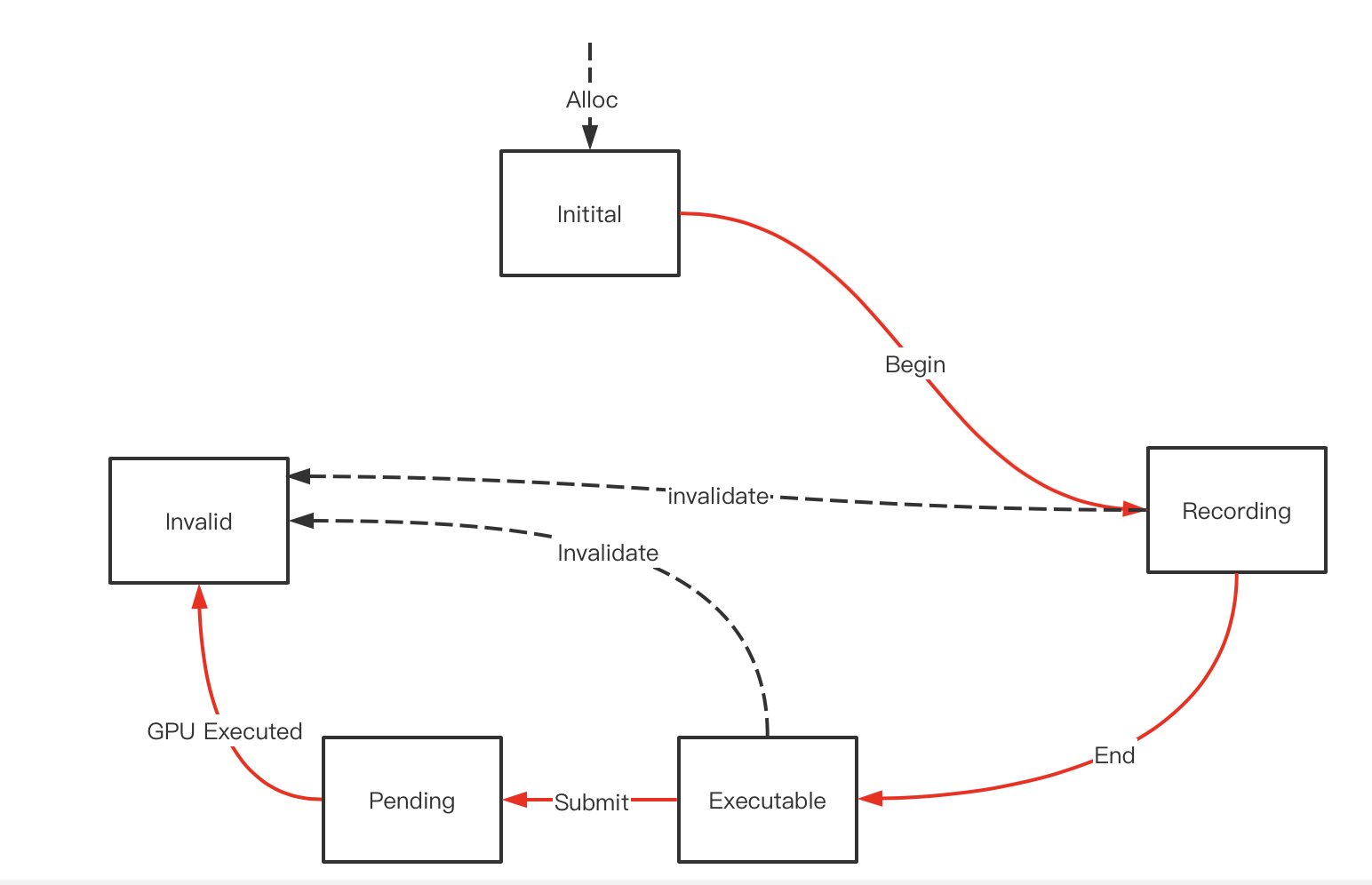
cmd buffer被alloc出来后处于Initial状态,此时它不能接受任何cmd的record操作,必须经过VKBeginCommandBuffer后进入Recording状态才行,在Recording状态进行了各种api操作后(或者也可以不做任何cmd 录制),需要调用VkEndCommandBuffer将其结束后转变为Exuecutable状态,在这个状态下才能调用vksubmitqueue将其提交,提交后它将处于pending状态,意为等待GPU调度,最后GPU执行结束进入到Invalid状态。
到达Invalid状态意味着一次完整的录制-提交-执行的结束,如果Cmd Buffer不能支持重录制和重提交,这个cmd buffer的使命就结束了,只能调用VkFreeCommandBuffer将其回收回pool,此外在任何状态下都可以调用VkFreeCommandBuffer将其回收回pool,此时cmd buffer都等同进入invalida状态。
此外在整个循环的过程中,如果发生一些预期之外的资源问题,比如录制的指令牵扯到的资源被释放等,都会将其立即转到Invalid状态。
可以重新录制的vkcmdbuffer
开启条件:在创建vkcmdbufferpool等时候将VkCommandPoolCreateInfo中的VkCommandPoolCreateFlags设置为包含VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT。
这样当cmd buffer处于Recording(正在录制),Executable(录制结束)和Invalid(GPU执行完毕)状态下都可以重新调用vkbegincommandbuffer,使其清空之前的提交内容重现录制。(Pending状态不可以,此时GPU还在使用)。
此外每次调用vkbegincommandbuffer时底层会根据需要自动为我们加入一个VkResetCommandBuffer,意为清空缓存内容,当然在这三种状态我们也可以手动调用VkResetCommandBuffer,使其进入initial状态。
在实践中,我们一般都会开启Cmd buffer的可重录制,反复复用有限的几个Cmdbuffer,这样相比重新从pool里拿可以减少内存的footprint(不过笔者确实没有经过对比测试)。
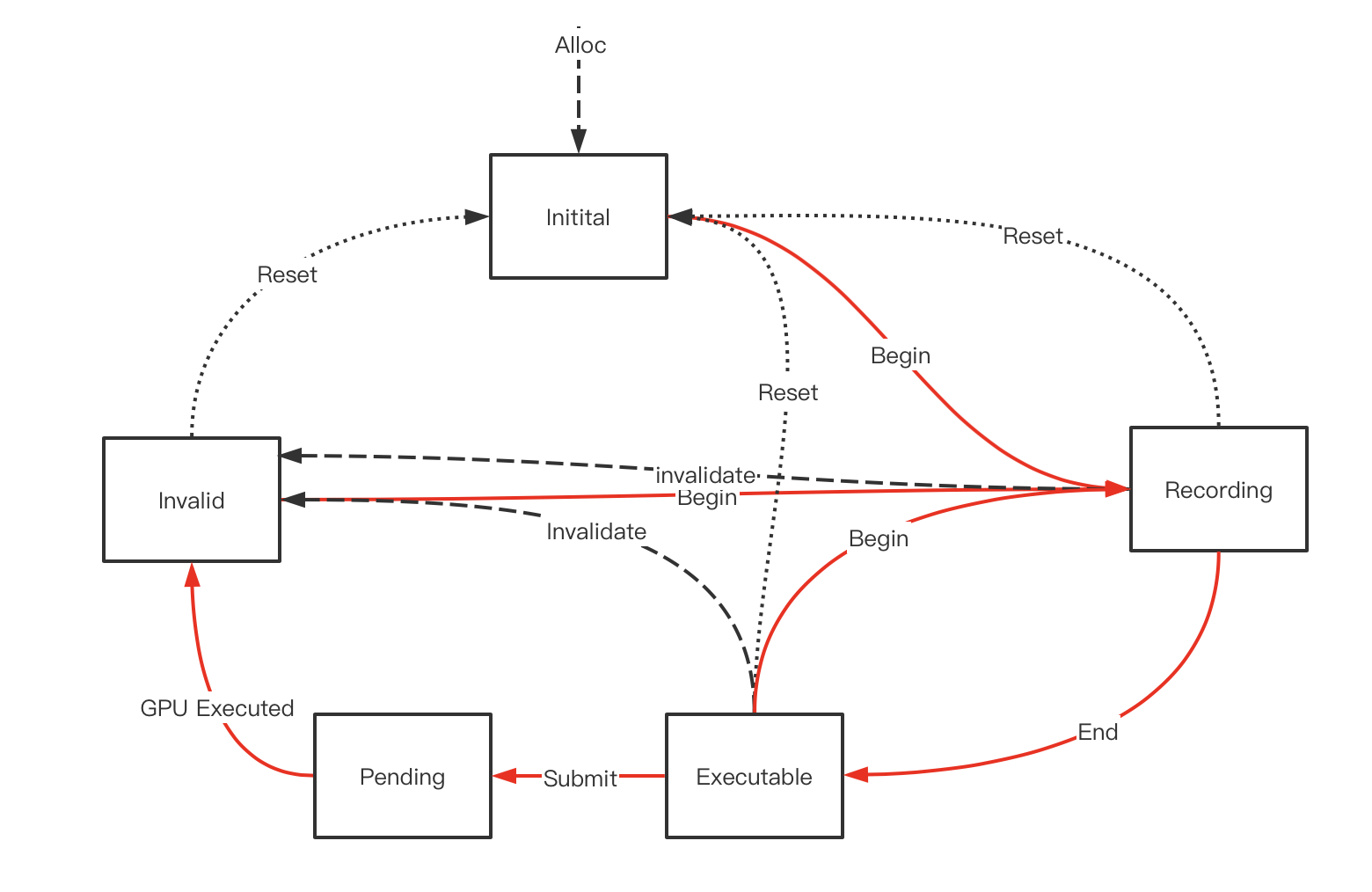
可以重提交的vkcmdbuffer
开启条件:在vkbegincommandbuffer的时候,将VkCommandBufferBeginInfo中的VkCommandBufferUsageFlags包含VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT
这样在一次录制完成后,可以不经过重新录制,而将老的录制内容再次提交,这是一个强大的特性,这相当于对渲染指令做了缓存。(游戏中可以利用这个特性进行插帧渲染,或者将静态场景内容cache下来多次渲染等,而不需要重新走完整的渲染和API调用流程),可以重新录制且可重现提交的cmdbuffer的生命周期如下(注意,cmdbuffer可以只支持重提交,而不支持重录制)
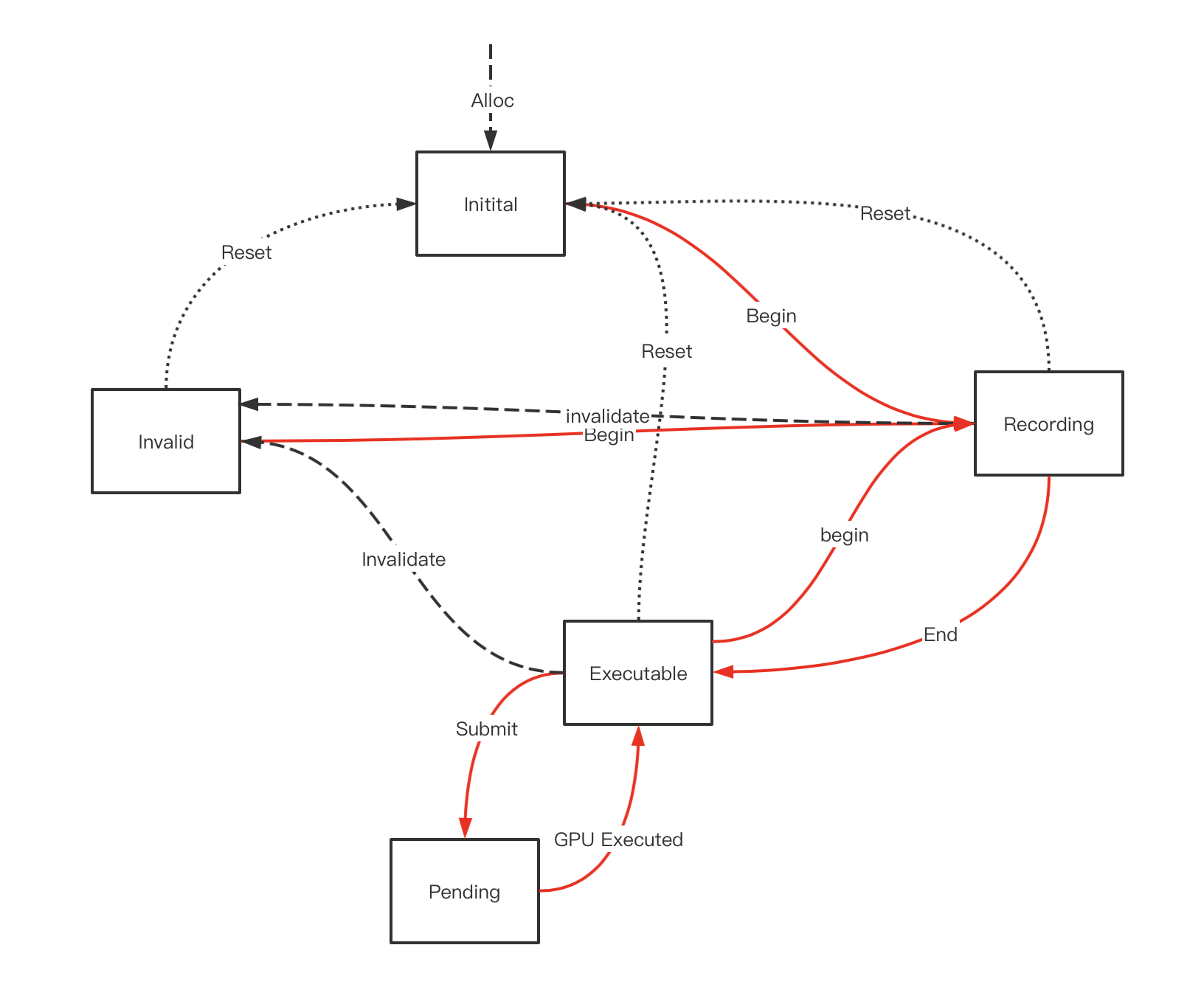
在被GPU执行完后cmdbuffer不会进入invalid状态而是回到Executable状态,可以再次被submit,如此循环下去,如果想打破这个循环重新录制这个cmd buffer,办法可以是在Executable状态下调用Begin使其重新进入录制状态,或者用vkfreecmdbuffer将其回收。
VK下的Command Buffer还有一个重要的特性 Secondary Command Buffer,因为这个和多线程相关,我们等到后面说完RenderPass再讲回来。
RenderPass
什么是RenderPass?简单的定义是使用同一套贴图作为渲染目标(RenderTarget)的一系列渲染指令组成了一个RenderPass。
那么为什么要定义RenderPass这个概念?
首先RenderTarget的改变尤其在移动端是一个非常重要且敏感的事情,移动端的硬件是Tile Based渲染,即在GPU的on-chip buffer上逐个RT子区域绘制。每一次RT的改变,将可能发生on-chip buffer和主存之间的内存交换。所以对于一个tile 渲染来说,一个renderpass内的所有drawcall一般都是合并在一起进行排序优化、绘制、内存同步的最小单元,renderpass之内的drawcall是被放在一起进行考虑的。例如不同renderpass上的drawcall尽管有提交顺序,但是并不一定有gpu渲染上的顺序,也不一定有内存上的读写顺序。
另外RenderPass定义了全局渲染管线状态的边界。我们知道渲染API维护了一个全局的管线的状态机,如当前管线上设置的depthtest属性,当前绑定的贴图都是当前状态机的一部份。前面指令设置的状态,对于后面的指令来说一般是有效的,前面一句API设置了depthtest为less,后面的drawcall都会应用这个状态,但是这个状态有效的边界在哪里,是否一直有效下去?定义了renderpass的概念就为这个状态的时效性定义了边界。一般来说,管线状态是不能跨renderpass生效的。因为事实上跨renderpass的指令甚至都不能保证执行的先后顺序。跨Command Buffer就更不会生效了。但是gles上因为可以认为就是一个全局的大command buffer,也没有明确的renderpass概念,所以一般设置过一次的管线状态会一直有效。
RenderTarget的组成
RenderTarget是RenderPass的输出写入目的地,一个RT可以由N张可写入的贴图(或者gl上的RBO)组成,每个贴图也叫做attachement,被连接到其中的一个attachment slot上,大多数硬件含有多个color attachement slot,一个depth attachement slot和一个stencil attachment slot。

Load/Store Action
移动端,GPU在GPU片上的cache上进行绘制RT的一个小区域(tile),绘制好后将tile的结果拷贝回主存,这个内存行为叫做Store。
在每次设置RT的时候,如果不进行clear,GPU需要从主存上这个RT在某个小区域的内存,将它拷贝到GPU片上cache,以进行接下来的渲染,这个内存行为叫做Load。
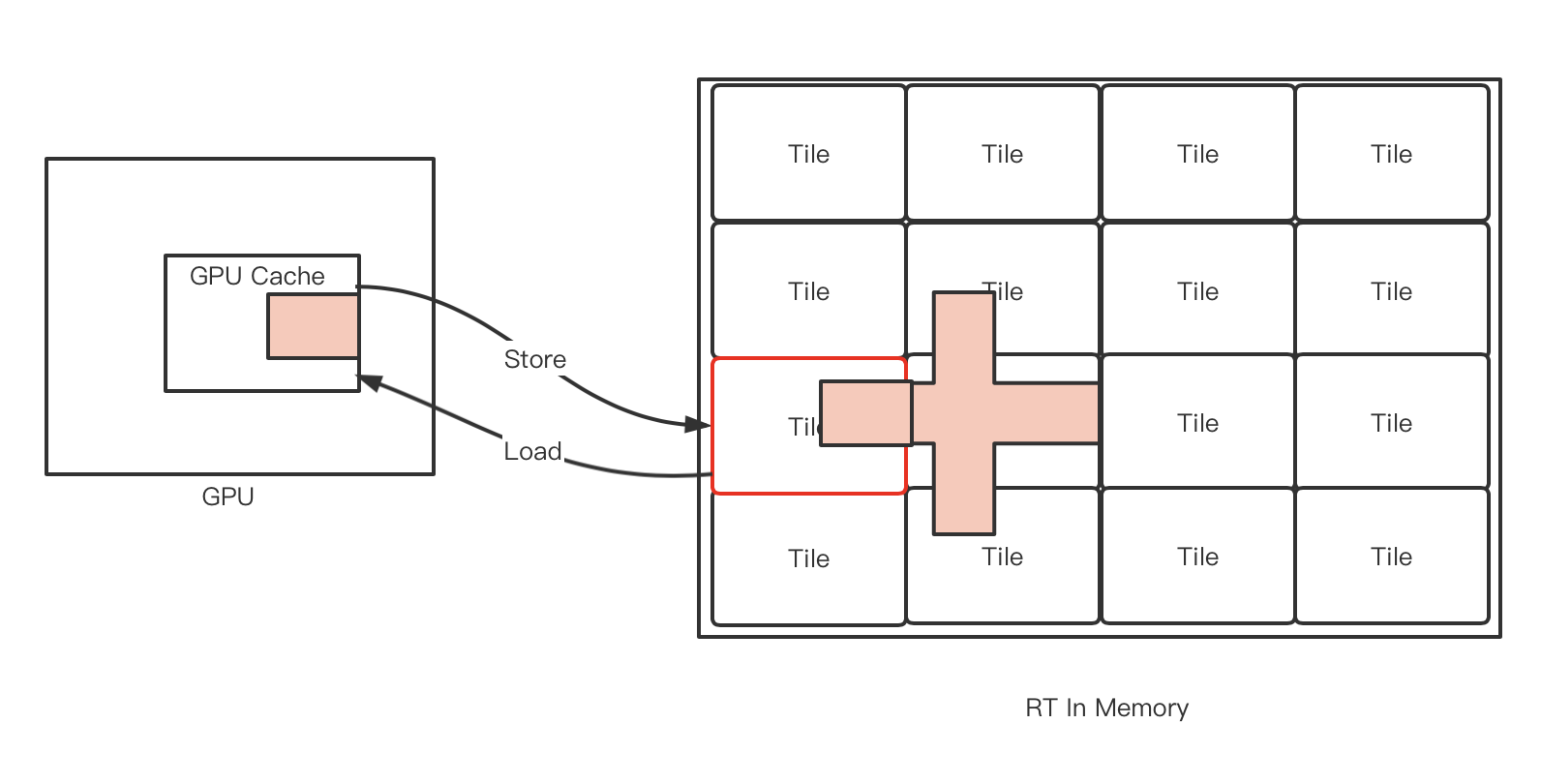
Load和Store操作都要涉及到对内存的传递,这会产生带宽,提高功耗,在移动端是一个特别在意的事情,所以面向移动端的API都要明确声明这个Load/Store的内存行为。
Load通常有以下几种行为:
Dont Care:什么都不做,当前tile上是啥就是啥,通常这样做都是因为后面的drawcall都可以保证把每个像素都填充一遍,例如你的后处理pass,Dont Care相对是节省带宽的
Clear:将像素填充一个初始化的默认值,这个是大多数RT绘制前的常规操作,也是节省带宽的
Load:使用当前RT的值,例如你需要基于现有rt的像素继续对其进行blend,fetch等操作,这个会产生读带宽,尽量避免。
Store的行为:
Dont care:什么都不做,即将tile上的值丢弃,不给主存,有些rt它的生命周期可能只局限于tile内部,如只是用来做depth test的depth,并不需要回到主存,这是节省带宽的。
Store:将tile的内存写回,这可能是多数需要保存rt的行为,例如你的color rt。这产生写带宽。
MultiSampleStore:这也是一些移动端为了节省带宽专有的特性,对于MSAA的渲染来说,如果我们把multi sample的值写回主存,就意味着N倍的写带宽,在支持的硬件上,这个行为将在GPU cache上resolve multi sample的值到一个最终的值,然后写回主存,这将只有1倍写带宽,但也同时意味着这张RT在这次切换后丢失了multi sample信息,不能再当作MSAA渲染了。
RT的读写操作
一张贴图可以用来作为渲染目标,此时为写入状态,也可以用来被贴图采样,此时为读取状态。对RT贴图来说读和写两种状态有什么区别?一个贴图可以同时被读被写么?这里来解释这个问题。
贴图被写入的情形:
- 作为RT被写入像素
- 在Compute Shader中被随机写入,也叫做Unordered Access View(UAV)
贴图被读取的情形:
- 作为RT,但是只被读取不被写入(如作为depth rt,但是当前管线关闭depth write)
- 作为贴图被采样
- 作为贴图做Framebufferfetch/Depthbufferfetch(只能读取当前RT上当前像素的内存,vk没有此概念,vk需要使用后面介绍的subrenderpass机制来实现)
- 作为depth/stencil RT做 depth/stencil测试
- 作为glreadpixel/copy的来源
这些操作有的发生在GPU的tile memory上,有的发生(或者可以被认为发生)在主存上,了解他们的发生场所,将有助于理解他们中的哪些可以共存,哪些不行。

不能共存的情形
- 绝对禁止:同时作为写入RT,且同时被采样。这种行为在大多数硬件上会引起GPU 崩溃,这种行为也叫做FeedbackLoop,因为RT在tile上被写入,在主存上采样,写入的数据不能保证被同步到主存上。这种需求只能使用两张独立的RT,一张采样,一张写入。
- 部分API下有问题:同时作为写入RT,且同时做FrameBufferFetch,这种行为理论上是没有问题的,因为RT的写入和Fetch都是发生在tile上,对于某个像素而言,写入和Fetch必然顺序确定,且不存在像素间的影响。在gles和metal上的确没有问题。在vk上会遇到问题(后面讲vulkan image layout的时候会再次提到),在vulkan上需要使用Subpass来解决。
其他情形没有问题。例如深度图同时被采样和做只读RT(关闭了 depth-write),是符合规范的
读写转换
一些API下,贴图在读和写状态之间切换需要显示的告诉API,例如Vulkan,有明确的image layout transiion 规则,贴图在读的状态下做写入操作会产生问题(后面会详细提到)。
而在metal上,对于贴图只有一个优化API用来标记贴图为GPU访问优化还是为CPU访问优化(optimizeContentsForGPUAccess),本身和读写无关,且并不强制。
在gles上,则是驱动帮你做判断,APP并不知情。
之所以存在读写转换,是因为在不同的状态下,驱动可能为贴图做不同的存储优化,以提升读写效率。
各API上的RenderPass
Gles
ges上没有定义显示的load/store行为,系统根据api和一些扩展api来推测用户的行为。
例如使用
gles上也没有显示的定义RenderPass的概念,随着用户对RT的切换而在驱动中实现renderpass的开始和结束。
gles上begin/end 一个renderpass的方法是先创建一个FrameBufferObject(FBO),然后将它绑定到写属性,再把一个贴图(或是一个RenderBufferObject RBO)连接(attach)到这个FBO上,就完成了一个rt的开启,详细过程
- glGenFramebuffers()创建一个FBO,他是一个GLuint的Handle,系统的backbuffer不需要创建,直接用0表示。
- glBindFramebuffer(GL_DRAW_FRAMEBUFFER, FBO)绑定FBO到写,如果FBO为0,则断掉所有color的attachment,将他绑定到default back buffer上,
- glFramebufferTexture(GL_FRAMEBUFFER,GL_COLOR_ATTACHMENT0/1/../GL_DEPTH_ATTACHMENT/GL_STENCIL_ATTACHMENT,
texture,
miplevel
)将贴图绑定到RT的某个attachment slot上。
- glDrawBuffers()设置shader的每个output流向哪个attachment上。
关于load/store:
gles上使用glInvalidateFramebuffer()来标记对于那个framebuffer的load和store设置为dont care,否则load/store的默认行为是store
gles上通过调用glclear()来将framebuffer的load设置为Clear,clear的值通过glClearColor设置。
gles的core api没有支持multisamplestore,但是可以通过扩展EXT_multisampled_render_to_texture来支持
关于rt读写:
gles上实质上不需要对Framebuffer显示的转换设置它的读写状态,但是要避免实质上发生上面所说的feddbackloop行为。(glBindFramebuffer专门指给一个rt绑定到读或者写,这里的读指glreadpixel的来源,写只设置为rt,但是这里面可以同时绑定到读写,且绑定到写不影响它作为贴图被采样)
RBO
此外gles中还可以将某个Device上的buffer像贴图一样绑定在attachment上,即将渲染内容写到某个GPU的buffer上,这种buffer叫RenderBufferObject (RBO)。使用API
glBindRenderbuffer创建,
使用 API glFramebufferRenderbuffer连接到attachment slot。
使用RBO而不是Texture的目的是什么?首先RBO其实是FBO的底层数据,RBO的内存传输比texture效率高,它使用的gles 的internalformat而不是贴图的format,如果不考虑需要将RT继续当贴图采样,使用RBO效率更高。此外在CoreAPI版本里,它专门用来支持MSAA渲染,如果硬件缺少支持EXT_multisampled_render_to_texture的相关扩展,默认的texture不能支持msaa渲染,但是RBO可以,一般先使用glRenderbufferStorageMultisample渲染到MSAA的RBO,再使用glBlitFramebuffer将MDSAA的RBO resolve到一张正常的texture RT,VK和Metal没有RBO的概念。
Vulkan上的renderpass和subpass
vulkan和metal都有显示的RenderPas对象。通过显示的API创建,开始,并结束一个RenderPass,并且所有的draw 类型的cmd都必须被包含在RenderPass的开始和结束中间,来标志这个drawcal属于哪个renderpass。所以一个Cmd Buffer上的cmd分成两种,一种在RenderPass的包围之外,一种在RenderPass之内,在所有的vkcmdXXX API的定义下面都有一项叫做RenderPass Scope,用户需要在正确的Scope调用API,这个非常重要,不然可能引起崩溃。
这样一个Queue的组织结构看起来应该是这样的。
缓存式指令分为两种:
渲染相关的缓存式指令(绿色):一定嵌入在renderpass之内,如管线状态设置,调用drawprimitive
非渲染相关的缓存式指令(红色):一定在renderpass之外,如disaptch,资源的copy/clear
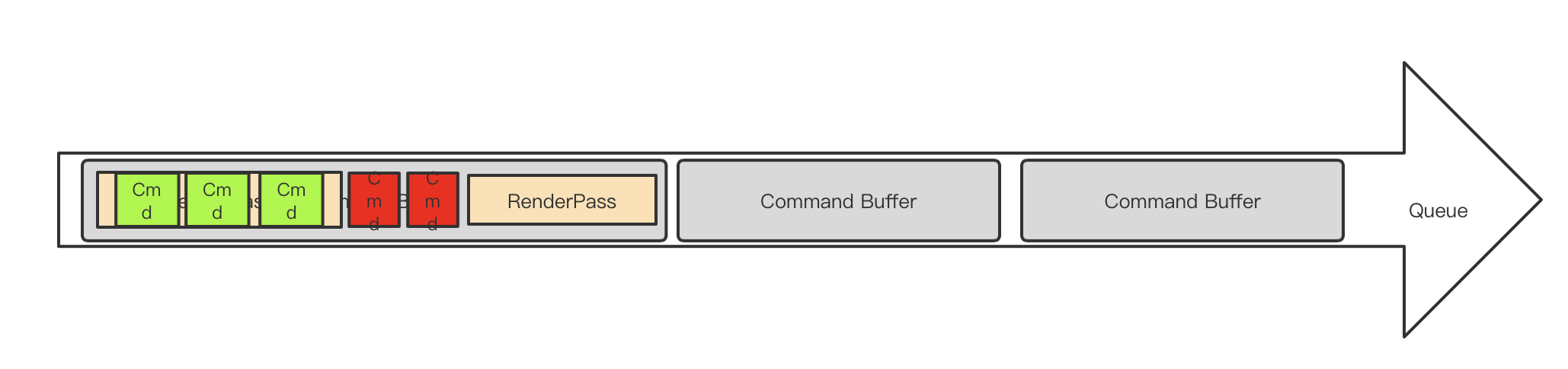
SubRenderPass
子RenderPass是Vulkan独有的概念,也是重要特性,它是组成RenderPass的基本单位,任何一个Renderpass都至少由1个Subrenderpass组成。
为什么需要设计这个概念?为了同步,为了在单个RT内做执行顺序上的同步和内存上的读写同步。
执行顺序的同步:subpass允许安排他们之间的依赖关系,以决定哪个subpass内的drawcall先被GPU执行(不是说谁先提交就谁先执行)
内存的读写同步:subpass允许将某个subpass的输出作为另外一个subpass的输入,这样就产生了内存上的先写后读。
Metal为什么没有这个概念?首先内存的读写同步,metal采用支持framebufferfetch来允许读取当前rt内容,且自动保证读写顺序。另外执行上的同步顺序metal没有把规则设计的这么复杂,而是简单的依靠rt的依赖自动帮助我们决定先后。(从这点上,Metal更像是在一个手动挡上封了一个更简单易用的自动档给APP)
完整的表述subpass,他有如下特性:
- 一个Renderpass内部的所有SubPass共享一个共同的RenderTarget作为output(当然有些subpass只用到其中的部份attachement)
- Subpass可以定义对其他Subpass的依赖关系,依赖关系中可以描述执行和内存的同步
- 通过显示的API 来从上一个Subpass切换到下一个,subpass的切换不会触发RT的load/store,因为RT没有被切换。
- 对于一个特定像素,在一个Subpass内可以读其他Subpass对当前像素的对RT的写入
- Subpass中可以定义该Subpass的MSAA状态,Resolve RT和规则。
- Subpass可以定义它preserve的attachment,一旦该RenderPass的某个attachement在某个subpass上没有被使用(即没被设置为它的attachement),这个attachment就会在tile上变成undefine状态,其值不被保证,如果想在这个subpass内保证它的值继续有效,就要把它声明为preserve的状态。
我们来看一个典型的renderpass的subpass组成和关系:

subpass0先往msaa到color0上绘制不透明物体,color0的msaa data被 resolve到color1,写入深度
subpass1依赖subpass0,读取深度图做某种ao计算,并输出一些颜色到color2,color1这个pass不用,但是需要保留给后面
subpass2依赖subpass1,读取color2的结果,基于color1的结果做某种blend操作最终输出到color1上。
看,这简直就是一个render graph!
下面我们来介绍具体的API部分
创建一个RenderPass
// Provided by VK_VERSION_1_0
VkResult vkCreateRenderPass(
VkDevice device,
const VkRenderPassCreateInfo* pCreateInfo,
const VkAllocationCallbacks* pAllocator,
VkRenderPass*
// Provided by VK_VERSION_1_0
typedef struct VkRenderPassCreateInfo {
VkStructureType sType;
const void* pNext;
VkRenderPassCreateFlags flags;
uint32_t attachmentCount;
const VkAttachmentDescription* pAttachments;
uint32_t subpassCount;
const VkSubpassDescription* pSubpasses;
uint32_t dependencyCount;
const VkSubpassDependency* pDependencies;
} VkRenderPassCreateInfo;
这里面关键要声明这个renderpass的
所有subpass用到的Attachment(VkAttachmentDescription)
所有Subpass(VkSubpassDescription)
Subpass之间的依赖关系(VkSubpassDependency)
Attachment
// Provided by VK_VERSION_1_0
typedef struct VkAttachmentDescription {
VkAttachmentDescriptionFlags flags;
VkFormat format;
VkSampleCountFlagBits samples;
VkAttachmentLoadOp loadOp;
VkAttachmentStoreOp storeOp;
VkAttachmentLoadOp stencilLoadOp;
VkAttachmentStoreOp stencilStoreOp;
VkImageLayout initialLayout;
VkImageLayout finalLayout;
} VkAttachmentDescription;
这里定义了每个attachment slot上的贴图格式,msaa数量,load/store action,以及贴图进入和离开这个rt的layout(layout的概念后面再讲),注意msaa用来在GPU上resolve出来的那个贴图也要放在这个里面。
Subpass描述
// Provided by VK_VERSION_1_0
typedef struct VkSubpassDescription {
VkSubpassDescriptionFlags flags;
VkPipelineBindPoint pipelineBindPoint;
uint32_t inputAttachmentCount;
const VkAttachmentReference* pInputAttachments;
uint32_t colorAttachmentCount;
const VkAttachmentReference* pColorAttachments;
const VkAttachmentReference* pResolveAttachments;
const VkAttachmentReference* pDepthStencilAttachment;
uint32_t preserveAttachmentCount;
const uint32_t* pPreserveAttachments;
} VkSubpassDescription;
// Provided by VK_VERSION_1_0
typedef struct VkAttachmentReference {
uint32_t attachment;
VkImageLayout layout;
} VkAttachmentReference;
这里定义了每个Subpass所使用的各种attachement(在pAttachments上的index,进入这个subpass时的layout),他们分为:
inputattachment:读取的其他依赖的subpass的output
colorattachemnt:color的output
resolveattachment:color 的msaa的resolve
depthstencilattachment:depthstencil的output
preserverattachment:reserve undefine的attachemnt
这里只看到color的msaa resolve,如果想要给depth做msaa resolve怎么办? 需要使用并参考扩展VK_KHR_depth_stencil_resolve(vk1.2成为Core API)
Subpass 依赖
// Provided by VK_VERSION_1_0
typedef struct VkSubpassDependency {
uint32_t srcSubpass;
uint32_t dstSubpass;
VkPipelineStageFlags srcStageMask;
VkPipelineStageFlags dstStageMask;
VkAccessFlags srcAccessMask;
VkAccessFlags dstAccessMask;
VkDependencyFlags dependencyFlags;
} VkSubpassDependency;
这里要定义依赖的subpass的source和dest,用于同步执行顺序和内存读写顺序的相关flag(这些flag会在后面同步的部份专门讲解)
创建FrameBufferObject
创建好了Renderpass之后,还需要创建Frame Buffer ,才能真正开启一个renderpass。
设计RenderPass对象和FrameBuffer两种对象是为了将规则和数据解耦,renderpass只定义规格,framebuffer才是真正的贴图数据。
创建的API:
// Provided by VK_VERSION_1_0
VkResult vkCreateFramebuffer(
VkDevice device,
const VkFramebufferCreateInfo* pCreateInfo,
const VkAllocationCallbacks* pAllocator,
VkFramebuffer* pFramebuffer);
// Provided by VK_VERSION_1_0
typedef struct VkFramebufferCreateInfo {
VkStructureType sType;
const void* pNext;
VkFramebufferCreateFlags flags;
VkRenderPass renderPass;
uint32_t attachmentCount;
const VkImageView* pAttachments;
uint32_t width;
uint32_t height;
uint32_t layers;
} VkFramebufferCreateInfo;
创建Framebuffer需要指定:
它适配的renderpass(Framebuffer创建时用的Renderpass必须和他被使用时管线上用的renderpass是规格适配的)
attachment 数量(也必须同renderpass的规格适配)
每个attachment上放的贴图
开始renderpass
vkCmdBeginRenderPass2,里面需要指定这个使用的renderpass和framebuffer
进入下一个subpass
vkCmdNextSubpass
结束renderpass
vkCmdEndRenderPass
注意所有msaa的resolve操作发生于endrenderpass里
渲染状态是否可以跨越Subpass
我们知道渲染状态不会跨越renderpass,对于subpass,一半也只有当前的RT是多个subpass共享的,其他渲染状态也是要重新设置的,在vk上subpass才是GPU执行的最小粒度,多个subpass之间如果不指定依赖和同步关系,也是不保证Device上执行的先后顺序的(尽管提交上可能有先后)。
在vulkan的实践中,甚至可以把整个一帧内所有的renderpass合成到一个大的renderpass中,以subpass到形式存在,这样全局就只有一个大的renderpass,减少了创建renderpass到开销,毕竟renderpass内部就是一个微型的render graph系统。
在vulkan的实践中,甚至可以把整个一帧内所有的renderpass合成到一个大的renderpass中,以subpass到形式存在,这样全局就只有一个大的renderpass,减少了创建renderpass到开销,毕竟renderpass内部就是一个微型的render graph系统。
Metal
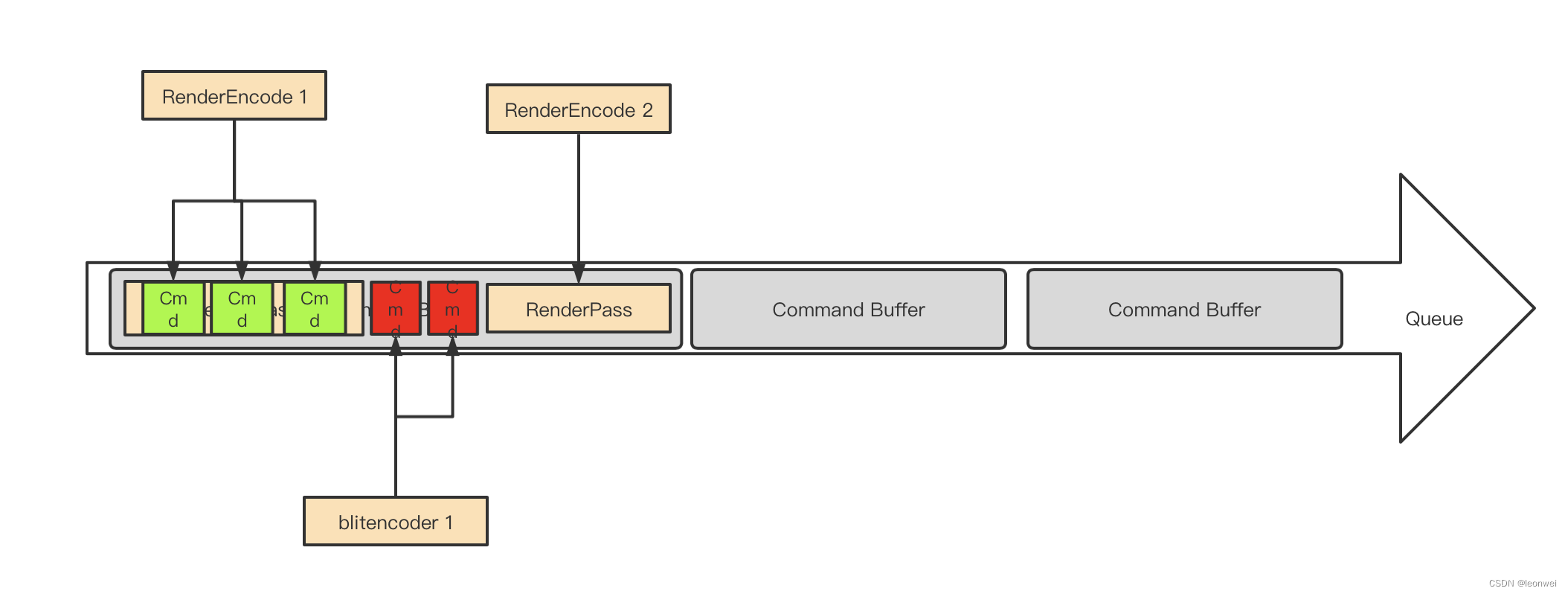
同vulkan比起来,metal的Renderpass的设置就显得过于容易了。
Metal上,renderpass的创建是RenderEncoder创建的一部份,并且metal没有分离renderpass和framebuffer两个概念。
API上是先要指定一个RenderPassDescriptor,设置每个attachement slot的texture,load/store action,最后用这个descriptor来创建一个rendercommandencoder,用于record渲染指令。
也就是说Metal上的一个render encoder就和一个renderpass 一一对应,一个render encoder内部不能切换多个renderpass,一个renderpass也不能跨越多个renderpass,一个renderencoderye只能为一个command buffer服务。
_renderToTextureRenderPassDescriptor.colorAttachments[0].texture = _renderTargetTexture;
_renderToTextureRenderPassDescriptor.colorAttachments[0].loadAction = MTLLoadActionClear;
_renderToTextureRenderPassDescriptor.colorAttachments[0].clearColor = MTLClearColorMake(1, 1, 1, 1);
_renderToTextureRenderPassDescriptor.colorAttachments[0].storeAction = MTLStoreActionStore;
id<MTLRenderCommandEncoder> renderEncoder =
[commandBuffer renderCommandEncoderWithDescriptor:_renderToTextureRenderPassDescriptor];
Metal上的queue,command buffer,renderpass,encoder的关系如图
Metal上实现MSAA渲染是直接在attachement的属性中设置待resolve的贴图,例如将 colorAttachments[0].texture设置为一张MSAA贴图, 将colorAttachments[0].resolveTexture设置为它需要resolve到的贴图。
多线程提交
现代API一个显著的特性是对API的并发处理能力,Vk和Metal都可以对Command Buffer做多线程的录制和多线程的提交。
数据结构的线程安全
引入queue,并允许出现多个queue的意义就是为了可以多线程record和submit command,metal上queue本身就是thread safe的,我们可以在多线程操纵同一个queue,只要app能保证提交顺序,同一个queue分配出来的不同的cmdbuffer也可以在不同线程操作。
而vulkan中包括queue大多数类型都不是thread-safe的,需要APP自己做好同步。同样整个CommandBufferPool级别都不是线程安全的,不能在多线程上同时操纵和同一个CommandPool创建出来的cmdbuffer的内存相关的操作(alloc,begin,end,reset,submit等),例如一个cmdbufferA和cmdbufferB都是从一个CommandPool创建出来,在A线程调用cmdbufferA的begin,在B线程上对cmdbufferB调用reset,就是产生内存错误的操作,但是两个线程分别在不同的cmdbuffer上调用普通的渲染指令,如vkcmddraw则不会产生问题。
我们下面讨论API在CPU一侧的三个主要操作的并发
首先是API CALL
在任何平台下都可以多线程的调用API CALL,vulkan metal上的各种渲染API只要做好资源上的同步,可以随意的在多线程调用。
但是gles有诸多限制,最大特殊之处是需要创建多个glcontext,因为每个线程要绑定不同的context,而每个glcontext下创建的资源默认互不相认,需要将glcontext之间设置parent的方法来使其能够共享(在eglCreateContext的时候指定)。另外在gl上容器类的object不能被多线程共享,如FBO,VAO,Query,Transfrom Feedback,Programe Pipeline。同时如果一个Object在一个线程上被修改,在另外一个可以访问到它的线程上需要重新绑定这个object之后才会得到重新应用。 在gles上因为只有单一的queue,所以只有那些非缓存类指令的API才能从多线程调用API CALL上获益,如多线程创建资源,多线程编译shader等。详细可参考我之前的一篇文章基于UE4的多RHI线程实现_rhithread_leonwei的博客-CSDN博客
其次是Command Submit
Vulkan 和metal有多个queue,所以可以在多线程上对不同的queue同时submit,可以设置如vksepmphore的信号量为queue之间指定GPU上的执行顺序。但是由于大部分APP通常一帧内都只会提交1次,所以submit一般不是瓶颈,较少实际应用中去应用多线程提交
然后就是Command 的Record
这个通常是最大的瓶颈,也是多线程处理的主要收益之处,因为一帧内有大量的渲染指令需要被录制,这个是drawcall真正的瓶颈,同样也只适用于vulkan和metal,我们详细介绍
我们再看一下Queue的结构

渲染相关指令一定被RenderPass包含, 而RenderPass又必须被一个Command Buffer完整包含(renderpass不能跨越多个commandbuffer),并且无论是什么API,command buffer都不是内部保证thread-safe的。
这意味着我们首先考虑到的只能基于一个Renderpass为基本单位并行录制,即准备多个Command Buffer,各自包含不同的Renderpass,在多线程录制,这就是最简单的
RenderPass级别的并发
看起来像这样
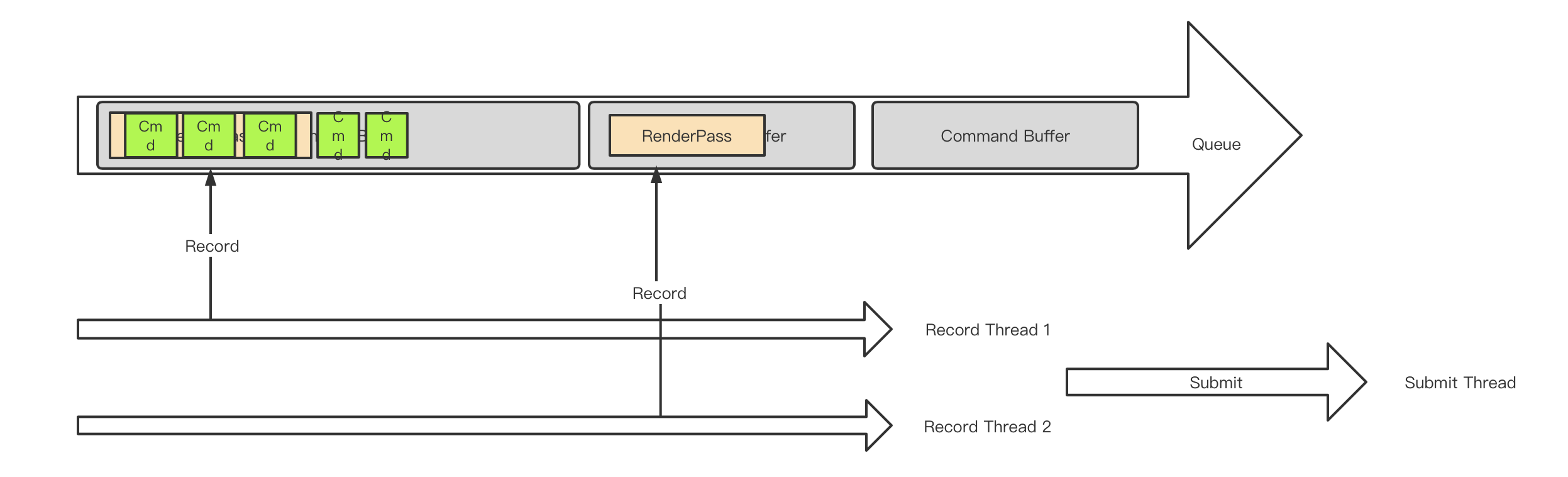
有多个独立的线程,把渲染指令按照renderpass拆解,renderpass放到不同的cmd buffer,在不同的线程record,在最终所有人完成时,在同一个线程将这些cmdbuffer一起提交,提交时的cmdbuffer在提交列表中的顺序就是提交顺序,还可以通过semphore来保证GPU的处理顺序。
但是在移动端我们为了减少带宽,减少rt切换,会尽量减少renderpass数量,尤其是vk下可能全局都只有一个renderpass(全都是subpass),对于pass内部的drawcall,我们难道要为了并发而故意切断renderpass么?这里就要考虑到
RenderPass内部Command 级别的并发
但是renderpass不能跨越多个cmd buffer怎么办?
首先看Vulkan的实现,这就回到了之前将Vk Command Buffer没有讲完了一个问题:
Vulkan中的Secondary Command Buffer
它专为多线程而设计,Vk中的cmd buffer分为两种,在调用vkAllocateCommandBuffers时,通过设置VkCommandBufferAllocateInfo上的VkCommandBufferLevel来指定:
VK_COMMAND_BUFFER_LEVEL_PRIMARY:这是我们前面讨论的默认情况,即Primary Buffer,这种buffer允许被录制,和提交
VK_COMMAND_BUFFER_LEVEL_SECONDARY:即Secondary Buffer,它允许被录制,不能提交,但是允许被录制到其他的primary buffer里(以vkexecutesecondary的方式执行),在primary被执行时执行到这个录制指令时将其上面的所有录制执行(就像是往primary buffer里插入一个指针,由primary间接执行)
secondary buffer内部不能包含renderpass相关指令,它像是从primary上分离出来的一小撮指令,其实就是专门用于分离出来在多线程录制。(所有的vkcmdXXX API的说明下面都会有一行 command buffer level用来说明该cmd可以放在primary或是secondarybuffer里)
secondary command buffer在使用上有以下两种情形。
- 完全内嵌在renderpass内的, 整个secondary command buffer完全包含在另一个primary buffer的某个renderpass里面,这说明他拆解出来的是绘制相关指令。
这需要在这个secondary buffer的vkBeginCommandBuffer时设置VkCommandBufferUsageFlagBits为
VK_COMMAND_BUFFER_USAGE_RENDER_PASS_CONTINUE_BIT
下图展示了一个原本的cmdbuffer等价的拆成如下的使用secondary command buffer的形式,它可以用两个线程分别录制两个secondary cmd buffer,只在主cmdbuffer上录制begin/end pass和executesecondarycmdbuffer。

- 不内嵌在renderpass内,说明这个secondary buffer拆解的不是绘制相关指令,他可能是buffer的copy等其他API。
这需要在这个secondary buffer的vkBeginCommandBuffer时不能设置VkCommandBufferUsageFlagBits为
VK_COMMAND_BUFFER_USAGE_RENDER_PASS_CONTINUE_BIT
如下图原本的cmd buffer可以被拆解成如下形式,其中的一块pass外等cmd被拆解到一个secondary中在线程上录制

注意:一个secondary cmd buffer要么是完全嵌入renderpass的,要么是不嵌入renderpass的,只能选择其一。这意味着一个secondary cmd buffer中的内容要么全是渲染相关指令,要么全是非渲染相关指令,不能混杂。
除了secondary cmd buffer中的cmd不能“混杂”之外,renderpass也有一个不能混杂的原则,如下:
一个renderpass在一个subpass内要么全部执行vkexecutesecondary指令(我们称为subpassinline模式),要么全部不能执行vkexecutesecondary指令,即不能将vkexecutesecondary同其他绘制指令混杂一起。这通过在调vkCmdBeginRenderPass/vkCmdNextSubpass时设置VkSubpassContents是否为VK_SUBPASS_CONTENTS_INLINE来设定。
如下图所示的情形是非法的

再总结下这里的一个重点,renderpass的subpassinline模式和secondary cmd buffer的ENDER_PASS_CONTINUE_BIT模式分别都是存在一个不能混合使用的规则的,
有了secondary cmd buffer概念,Vk中就可以做cmd 级别的并发了,我们可以把一个renderpass中的所有cmd拆成几组,每一组封装到一个secondary cmd buffer里面,每个secondary cmd buffer分别在多线程上record即可。在primary cmd buffer上同一个subpass内调用vkexecutesecondary的顺序就是这些secondary cmd buffer的提交顺序,也是他们在GPU上的执行顺序。
这个过程看起来像这个样子:
这里面有三个线程在并发录制,两个负责其中一个pass各一半的drawcall,第三个负责primary的renderpass
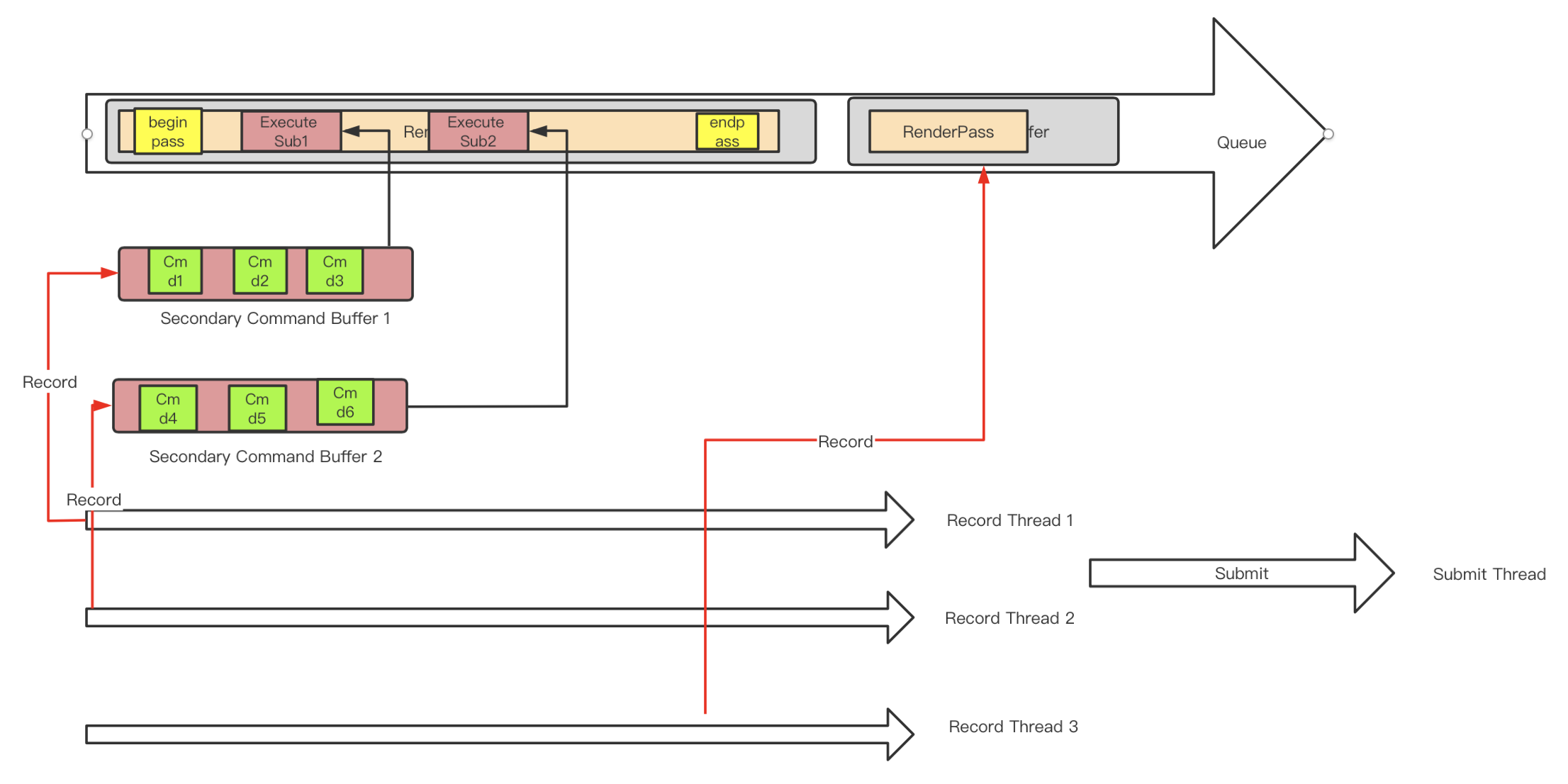
Secondary Command Buffer中的RenderPass状态
前面提到渲染状态不能跨越renderpass和command buffer,那么这里就有个问题,如果将本来在一个renderpass里面的一小撮指令拆出来到一个secondary cmd buffer里填充,这个secondary cmd buffer内部是不是就完全感知不到在原本renderpass里面靠前的一些api的状态设置了?
确实,在secondary cmd buffer你需要重新设置大部分和渲染状态相关的指令,例如原本你在原来完整的renderpass开头设置了depthtest为less,那么现在每个拆出来的secondary cmd buffer中都要加入此api。
但是只有renderpass是不需要设置的,因为在对secondary调用VkBeginCmdBuffer的时候,所传入的VkCommandBufferBeginInfo中的pInheritageInfo需要被设置。 这个结构的定义是
// Provided by VK_VERSION_1_0
typedef struct VkCommandBufferInheritanceInfo {
VkStructureType sType;
const void* pNext;
VkRenderPass renderPass;
uint32_t subpass;
VkFramebuffer framebuffer;
VkBool32 occlusionQueryEnable;
VkQueryControlFlags queryFlags;
VkQueryPipelineStatisticFlags pipelineStatistics;
} VkCommandBufferInheritanceInfo;这里面描述了该secondary command buffer将以它原本所在的那个renderpass为它的renderpass。
当然引入secondary command buffer还是不可避免导致API调用增多一些,所以实践上我们拆分的粒度不要太细,要至少以比较大的渲染管线的异同来拆分。
Metal上的ParallelRenderCommandEncoder
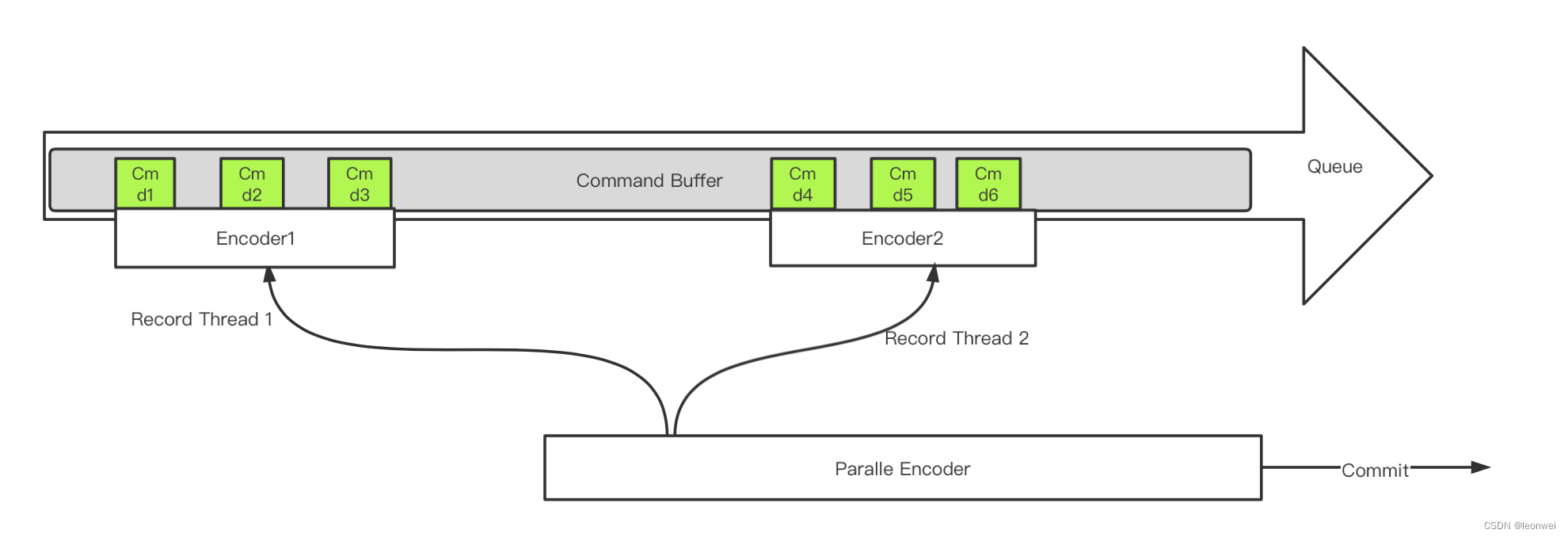
Metal上又一次为我们简化了设计,没有制造出vulkan上这么复杂的secondary command buffer的概念来,command buffer还是那个command buffer,只是改用了一种特殊的encoder。
首先再待拆分的command buffer上使用parallelRenderCommandEncoderWithDescriptor创建一个parallel encoder出来,这种encoder不能用来实际encode,只能进行commit。
我们在parallel encoder创建的时候设置当前renderpass的开始和它的rt,我们对这个renderpass的drawwcall做拆分后,对于每个拆分的组 ,用这个parallel encoder调用paralleencoder产生一个新的render encoder,用几个新产生的encoder去record每个组的绘制指令。
最终等待每个子render encoder完成end encoding之后,parallel encoder调用commit做一次提交。在paralle encoder上调用paralleencoder创建子encoder的顺序即是他们的提交顺序,也是他们在gpu上的执行顺序。
这个流程看起来如下






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结