您现在的位置是:首页 >其他 >前瞻洞察|Prompt Learning(提示学习)——新的低资源场景克星网站首页其他
前瞻洞察|Prompt Learning(提示学习)——新的低资源场景克星
近年来,预训练语言模型已然成为自然语言处理(NLP)领域中备受瞩目的技术之一。预训练模型可以在大规模文本语料上进行自监督学习,从而获得丰富的语言学知识,并通过在下游任务上进行微调,实现出色的性能。Prompt Learning(提示学习)则是一种最新的预训练模型范式,通过在预训练过程中提供特定任务的提示信息,来指导模型学习,帮助模型更好地利用任务的上下文信息,从而提高模型的性能,也使得模型可以在Few-shot、Zero-shot等低资源场景下保持良好的表现。
本期前瞻洞察从Prompt Learning预训练范式出发,讲述什么是Prompt、为什么要Prompt以及怎么样Prompt,最后会结合当下最火热的科技ChatGPT进行简单的Prompt范式说明,更直观地展现Prompt Learning的魅力。
1、引言
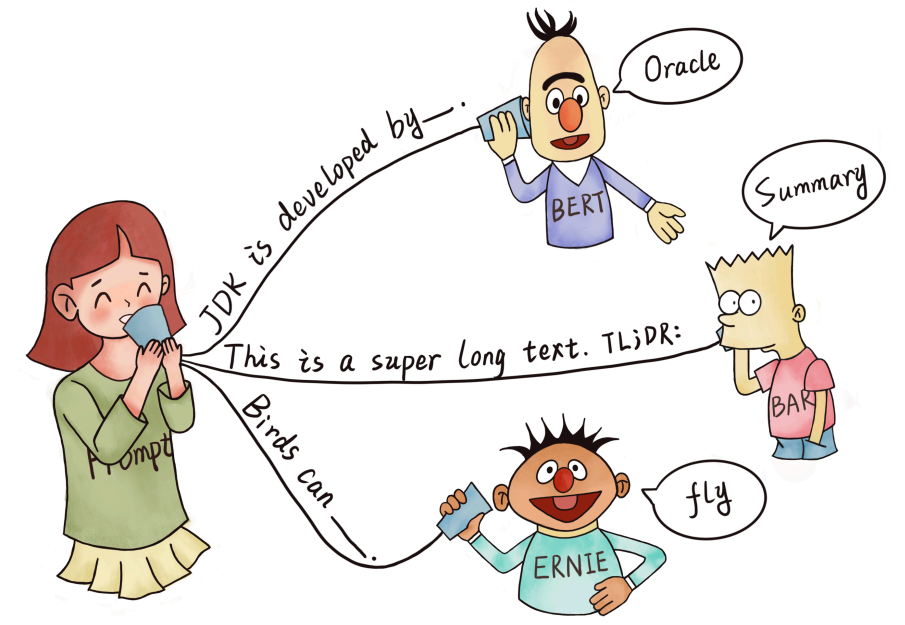
图注:Prompt魔法能力[1]
人工智能的发展一直是科技界的热门话题。在过去的几十年里,人们一直在探索着如何让机器更加智能化。然而,尽管现代机器学习技术取得了长足的进步,但是机器在某些领域的表现仍然远远不如人类。其中最关键的原因之一,机器往往缺乏人类的常识和推理能力。这使得机器在面对一些复杂的任务时表现不佳,例如自然语言理解、文本生成等。
为了解决这个问题,研究人员一直在尝试各种各样的方法。其中最有前途的方法之一就是Prompt Learning。Prompt Learning是一种基于模板的机器学习方法,它通过给模型提供一些“提示”来帮助其更好地理解任务,从而提高模型的性能。
训练模型时,首先需要定义一个提示模板,这个模板包含了一些提示信息,例如关键词、短语、句子等。然后,将提示模板与训练数据一起输入到模型中进行训练。在预测时,可以将提示模板与待预测的数据一起输入到模型中,从而帮助模型更好地理解输入数据。模型训练采用的提示信息通常是可以被人类理解的,这也使得可以更好地理解模型在做决策时的逻辑和推理过程,模型预测时通过结合不同的Prompt模式即可完成不同的任务需求。同时,通过添加提示信息可以帮助模型更好地利用已有的标注数据,学习到更通用的特征表示,从而使得模型在低资源场景任务中仍然可以保持较好的表现。
2、Prompt Learning 衍生之路
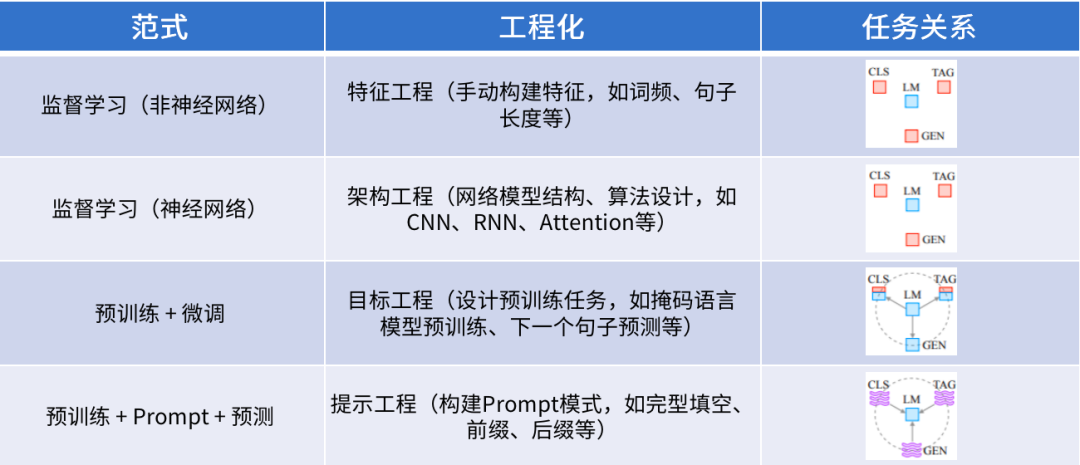
图注:典型NLP技术范式[1]
自然语言处理(NLP)技术的发展经历了典型的四个范式阶段:
特征工程+机器学习阶段,特征工程指从原始数据中提取、构建和转换出有用的特征用于算法模型的训练学习,早期阶段,人们通常需要手动构建特征来解决特定的问题,这个过程可能需要花费大量的时间和精力,并且需要专业知识和技能;随着深度学习技术的发展,特征工程发生了重大变革,模型可以自动从原始数据中提取得到更丰富鲁棒的特征,从而减少了手动构建特征的需求,更多的关注网络模型结构设计和算法优化;
随着大规模预训练语言模型的出现,如BERT、GPT等,江湖逐渐再次形成大一统,预训练+微调范式成为诸多NLP建模任务(如CLS分类任务、TAG序列任务、LM语言模型及GEN生成任务等)的基本解决方案,在预训练模型的基础上引入下游任务数据进行微调训练,通常即可得到一个较好的实现效果,往往优于以前的技术方法,且操作应用更加简便。
既然预训练模型之流已经实现了这么好的效果了,那为什么还要Prompt Learning呢?
可以从两个方面进行诠释,在自然语言处理领域,传统的机器学习算法往往需要大量的人工标注数据,才能够在大规模语料上训练得到较好的模型效果。但是,这些数据通常需要业务领域专家进行标注处理或指导,成本高昂,而且人工的注意力也有限,这就导致了训练数据的不足及数据质量的不稳定性,以致模型性能下降。
另一方面,随着人工智能技术的不断发展,很多自然语言处理任务可以通过预训练语言模型(Pretrained Language Model)来解决,这些模型通过大规模的语料库训练得到,具有较好的性能和泛化能力。但是,这些预训练模型通常只适用于特定的任务和数据集,不能够直接用于新的任务,在很多情况下,需要业务专家基于任务需求进行微调才能够得到更好的表现,无法充分发挥预训练语言模型的能力。因此,研究人员开始探索如何使用自动化技术和预训练模型来一站式解决这些问题。其中,Prompt Learning是一种被广泛研究和应用的技术,通过引入Prompt模板来将原始输入改造成类似于完形填空的格式,让语言模型去回答,进而推断出下游任务的结果。
自从Prompt Learning技术提出以来,迅速受到研究人员及相关从业人员的关注,并基于多个方向展开深度研究开拓,从最初的手动设计Prompt到之后的自适应优化学习Prompt,再到一系列更加精细化、复杂化的Prompt设计,感兴趣的同学可以关注其技术脉络,或许你会有一种豁然开朗的感觉,“原来还可以这么实现!”,这里不再具体展开赘述。当下,谈及最火热的AI 技术,无疑是OPENAI发布的ChatGPT,一经发布,直接掀起了一波人工智能浪潮,甚至在很多领域产生了颠覆性的影响。Prompt Learning是其中一个重要原理模块,在本文的最后会结合作以展示提及。
3、如何进行Prompt Learning
我们可能会发现,在大多实际工作场景中,通常是无法拿到很多监督训练数据的,甚至没有任何可用任务数据,这种弱监督、无监督的应用场景需求往往更符合我们的生产场景。那么此时此刻,如何实现任务需求呢?Prompt Learning无疑给了我们一种较优解决方案。这里,笔者以分类任务为例,结合一个场景任务展开细致阐述如何进行Prompt Learning。
首先,找到一个公开的新闻文本分类数据集,包含“文化”、“财经”、“体育”、“娱乐”等15个类别,共计600条样本数据,如下为3个数据样例:
{"text": "中铁建有多少个局?", "label_name": "财经", "label": 3}
{"text": "世界十大最著名的手枪", "label_name": "军事", "label": 8}
{"text": "高三学生如何复习?", "label_name": "教育", "label": 6}
利用这些数据,我们可以建模一个文本分类任务,构建模型进行训练并预测其所属类别。但是,由于样本数据只有600条,因此,微调训练得到的模型可能并不稳定,很容易存在过拟合等情况,模型实际并不可用。弱监督学习方式可能才是更优的一种解决方案。根据Prompt Learning的原理方式,我们对任务数据进行转换调整,构建一个完形填空任务,让模型给出相应答案,而不再是直接进行文本分类输出类别标签并将其映射回所属类别。可以采用的一种Prompt数据转换方式如下:
{"text": "这是一条____新闻,"+"中铁建有多少个局?", "answer": "财经"}
{"text": "这是一条____新闻,"+"世界十大最著名的手枪", "answer ": "军事"}
{"text": "这是一条____新闻,"+"高三学生如何复习?", " answer ": "教育"}
我们期望模型可以直接预测输出文本数据归属的类别答案,如第一条样例数据,模型的输出即为 "财经"。这里Prompt数据的形式已然符合语言模型的训练范式,可以直接利用预训练语言模型如BERT预测输出完型填空答案结果。当然,也可以基于转换后的数据对BERT模型进行进一步的language model(LM)微调预训练,训练后的BERT模型通常会有更优的预测输出表现。如果采用的语言模型能力足够强,直接基于构建的Prompt数据进行预测输出即可普遍得到较优结果,改换不同的Prompt甚至可以完成多个不同场景任务需求(分类、问答、对话、翻译…),如 "将句子翻译成英文,中铁建有多少个局?",模型会直接推理预测输出其英文译文 "How many bureaus does China Railway Construction Corporation have? "。
笔者基于上述分类任务进行了Prompt-Tuning微调训练,其整体表现相较于直接进行分类任务建模平均提升了3个点左右,且模型方法的泛化性能相对更强。实验测试的是一种叫做 Pattern Exploit Training (PET) [2]的训练方法,是Prompt系列最早的代表方法之一。当然,根据笔者的实践经验,这里性能的提升并不是绝对的,也可能表现稍差,但是模型泛化能力一般会得到较明显改进。Prompt Learning模型方法在Few-shot和Zero-shot的场景中一般会优于同类型任务监督模型,在监督学习任务中有时也会有更好的表现。
4、ChatGPT 小试牛刀
2020年前后,最早的Prompt系列方法如PET模型训练方法提出,短短2年时间,技术集大成者-ChatGPT模型发布上线。ChatGPT是一种优化的大规模预训练对话语言模型,自去年11月份发布上线以来,一度引领掀起大模型研究关注的浪潮,国内外一时也出现了诸多类似的版本模型。我们把上一章节同样的测试问题交给ChatGPT模型,看看ChatGPT模型的效果,由于诸多魔法限制因素,这里我们体验测试的模型为Anthropic公开发布的Claude模型,其测试结果如下:
1. 判断数据所属类型

2. 其它任务类型Prompt体验

针对笔者上一章节给到的示例问题,Claude模型可以直接给出期望的答案,未经过任何训练微调,只是在Prompt中给出了限定的输出范围及输出形式,从而保证输出结果符合预期,同时,引入不同的Prompt任务需求,Claude模型可以直接输出如翻译译文结果等。其核心内容就在于不同Prompt数据模式的构建及应用。
既然Prompt Learning这么强大,结合大规模语言模型之后甚至成为了“万能钥匙”,可以一站式解决诸多建模问题。那么是否可以直接发扬“拿来主义”,直接适配到我们的业务领域场景即可呢?笔者认为,这肯定是不行的,其中最核心的两个问题即是数据安全和成本问题。
结合具体业务场景,类似于ChatGPT这种大模型的部署应用往往需要较高的成本,至少就目前而言是这样的;同时,一旦直接采用如类ChatGPT大模型服务,数据安全问题会是一个更严峻的挑战,使用的数据相当于直接暴露给外部,这是很多企业及用户肯定无法接受的问题。同时,笔者作为一个网络安全领域从业者,发现目前关于该行业垂直领域的大模型鲜有研究,可能确实与行业属性及数据特征具有重要关系。如果能有一个安全领域成熟的大规模语言模型,可以辅助解决诸多如威胁情报分析、溯源、敏感信息识别等安全建模任务,这或许是一件很值得期待的事情。每个垂直行业领域可能都会希望有这样类似的大模型,或者通用大规模语言模型向领域大模型方向收敛应用,这应该可能会是之后很长一段时间研究及业界关注落地实现的重要发展方向!
5、结语
尽管类似于ChatGPT这种大模型的落地应用可能仍存在诸多限制,但不得不说的是这种大模型的出现让Prompt Learning变得愈发火热,甚至衍生了一种新的职业,叫Prompt工程师。Prompt Learning这种技术方式无疑是我们更值得关注和学习的,在实际生产场景中,当我们面临类似低资源问题的困扰,不妨尝试一下这种Prompt-based系列方法,或许会让你有眼前一亮的感觉!
6、参考文献
[1] Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing.
[2] Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference.





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结