您现在的位置是:首页 >技术交流 >【C++】海量数据处理面试题(位图和布隆过滤器)网站首页技术交流
【C++】海量数据处理面试题(位图和布隆过滤器)
都是大厂面试题哦~
文章目录
- 一.位图面试题
- 1.给定100亿个整数,设计算法找到只出现一次的整数
- 2.给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
- 3.1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
- 二.布隆过滤器
- 总结
一、位图面试题

如上图理解了位图的原理我们现在就开始实现吧:
namespace sxy
{
template <size_t N>
class biteset
{
public:
biteset()
{
_bits.resize(N / 8 + 1, 0);
}
private:
vector<char> _bits;
};
}首先我们先将大致的框架写出来,N这个模板参数是我们要开多少个比特位,然后我们直接用vector来实现,vector中存char类型,一个char是8个比特位,当用户想要10个比特位的时候我们应该开几个char呢?很明显如果仅仅10/8算出来1个char是不够的,所以我们需要多开一个防止不能整除的情况,然后记得将每个char初始化为0,这样每个比特位都是0了。
//将某个数映射为比特位将那个比特位置为1
void set(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] |= (1 << j);
}
//将某个数的比特位重新置为0
void reset(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] &= ~(1 << j);
}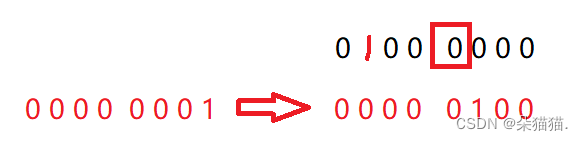
上图中以10这个数演示,最后的结果变成了0 1 0 0 0 1 0 0 既没有改变原先第6个比特位的1又改变了第2个比特位将10这个数表示出来了,所以我们的代码是正确的。
下面看reset函数:
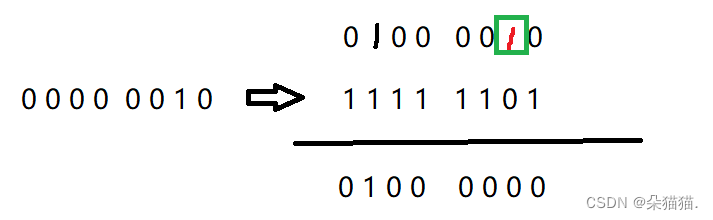
如果对于位运算不懂得还是先去看看位运算-.-。
下面我们用test函数来测试一个数是否存在:
bool test(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
return _bits[i] & (1 << j);
}这里要注意我们只是检查某个数是否存在,不能改变原来的位图所以不是&=,注意我们的返回值是bool型,如果返回值不为0说明那个比特位为1就是存在,否则就是不存在。
当然我们也可以写一个看位图中记录多少个存在的数的函数,不过这个函数与本题无关罢了:
//位图中有映射了多少个数
size_t Count()
{
size_t count = 0;
for (size_t i = 0; i < _bits.size(); i++)
{
int j = 0;
while (j < 8)
{
if (_bits[i] & (1 << j))
{
++count;
}
++j;
}
}
return count;
}只需要让1依次为每个char的比特位按位与一遍,不为0的就是1让计数器++即可。
下面我们测试一下:
void testbit()
{
//-1给无符号就是整形的最大值,开500多MB内存
biteset<200> bt;
bt.set(10);
cout << bt.test(10) << endl;
bt.reset(10);
cout << bt.test(10) << endl;
/*bt.set(11);
bt.set(12);
bt.set(13);
bt.set(19);
bt.set(46);
bt.set(75);
cout << bt.Count() << endl;*/
}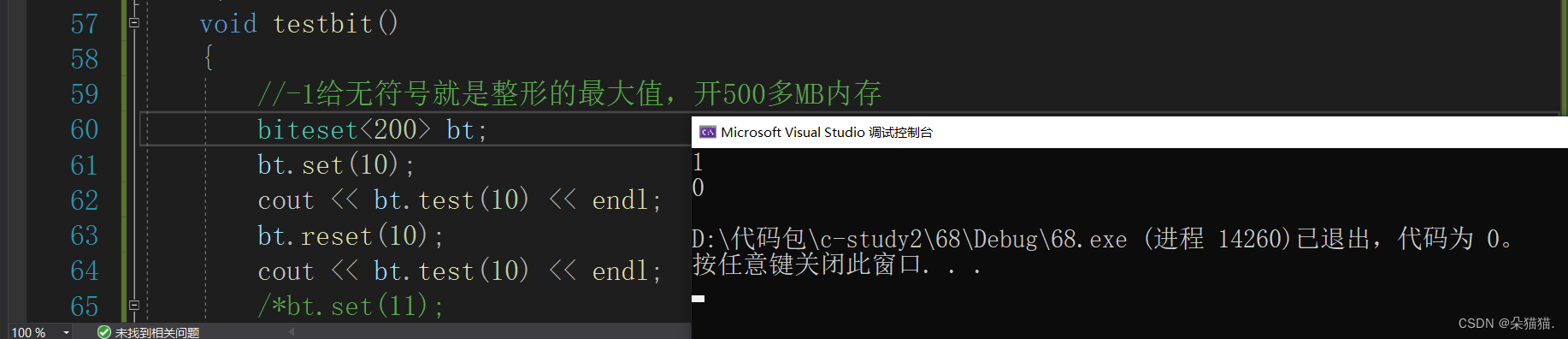
运行没问题我们在看看内存中的值:
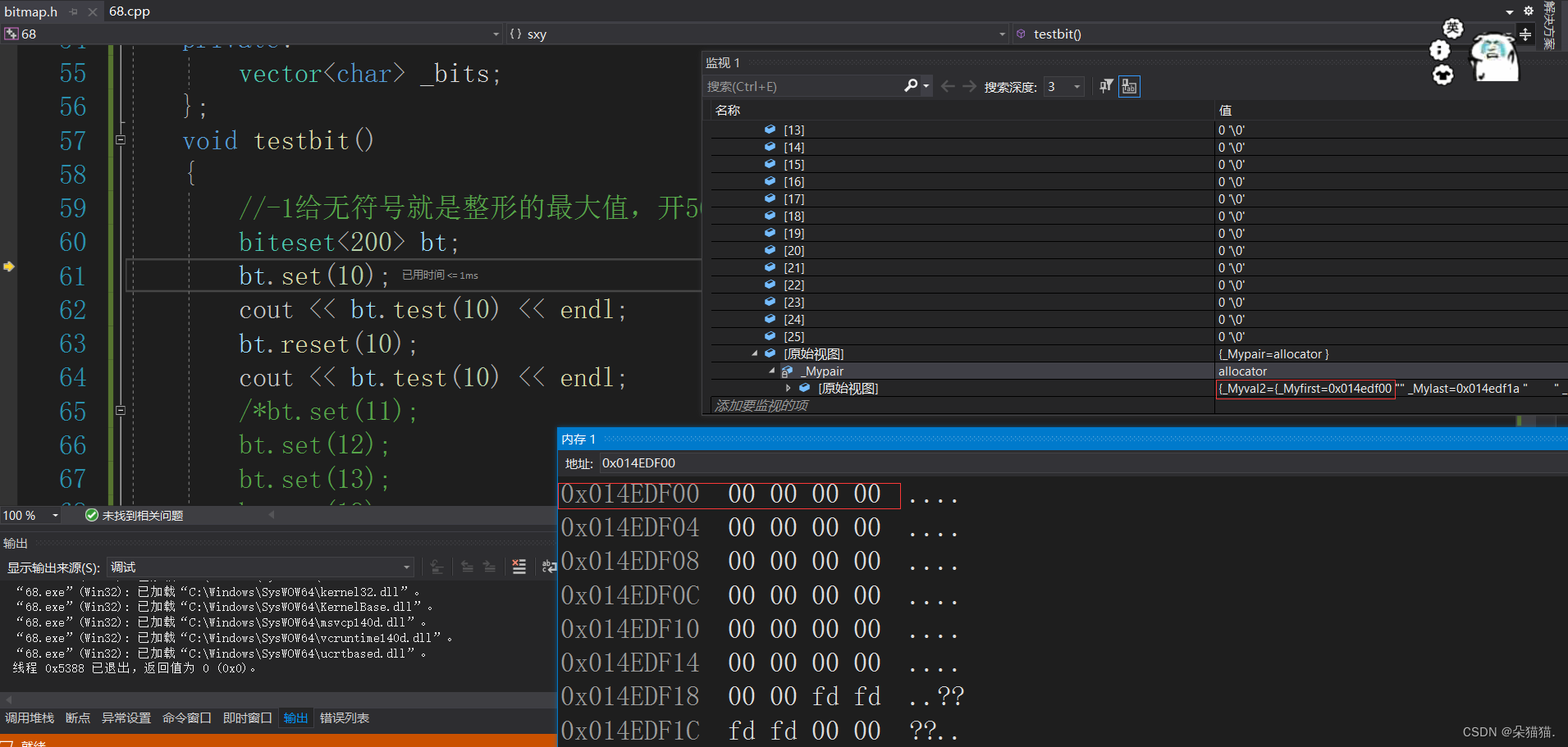
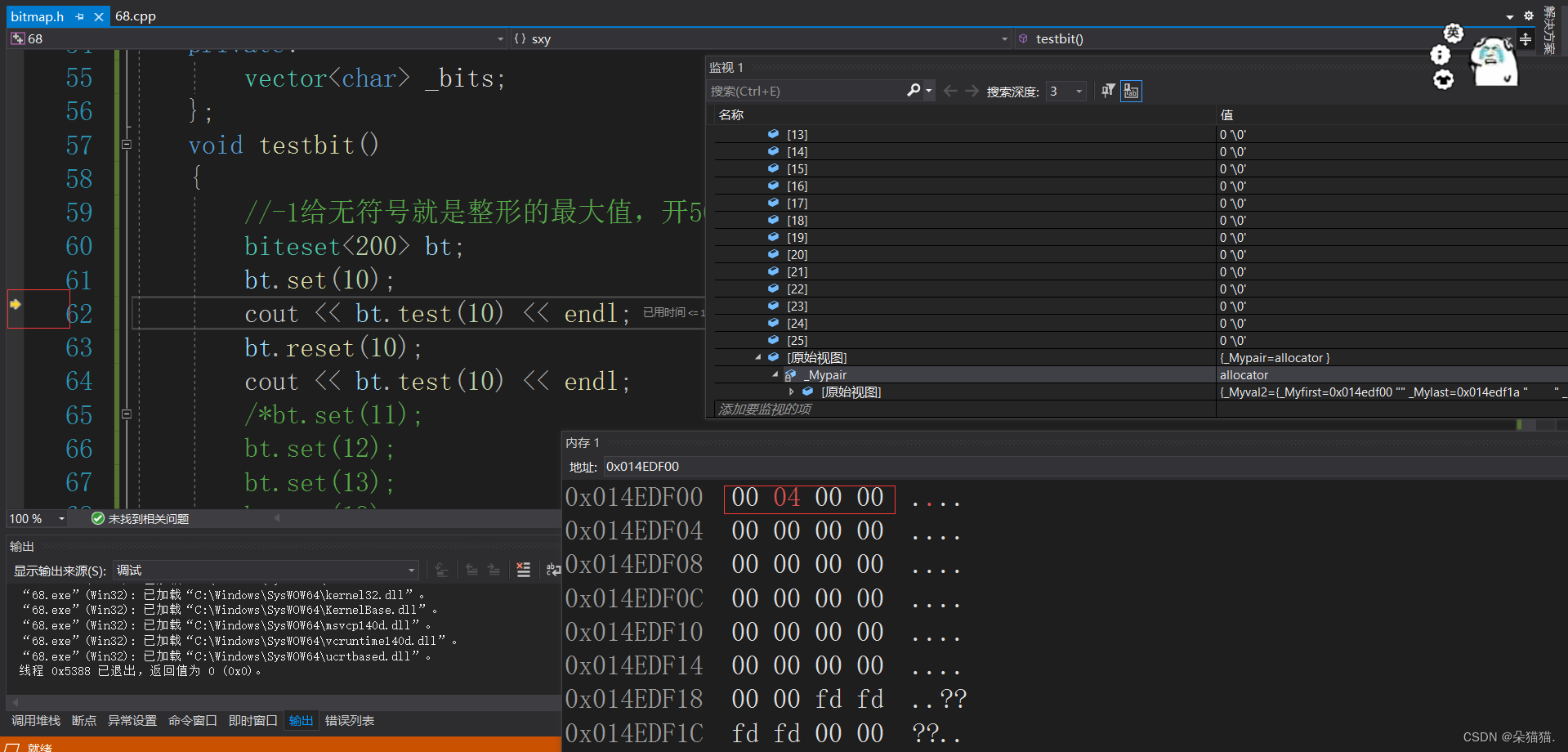
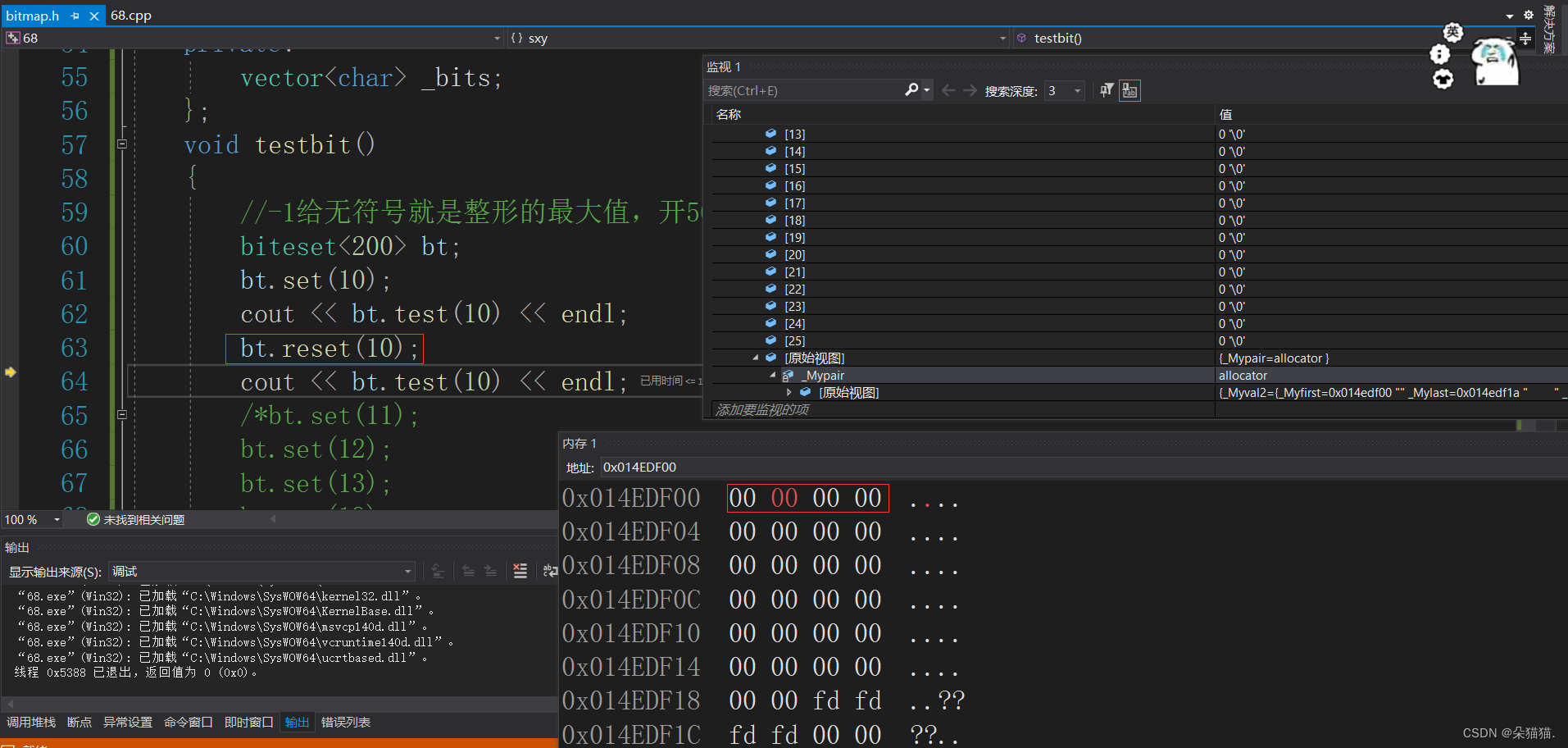 可以看到刚开始设置的时候确实将char的第2个比特位改为1了,因为内存中是16进制,所以
可以看到刚开始设置的时候确实将char的第2个比特位改为1了,因为内存中是16进制,所以
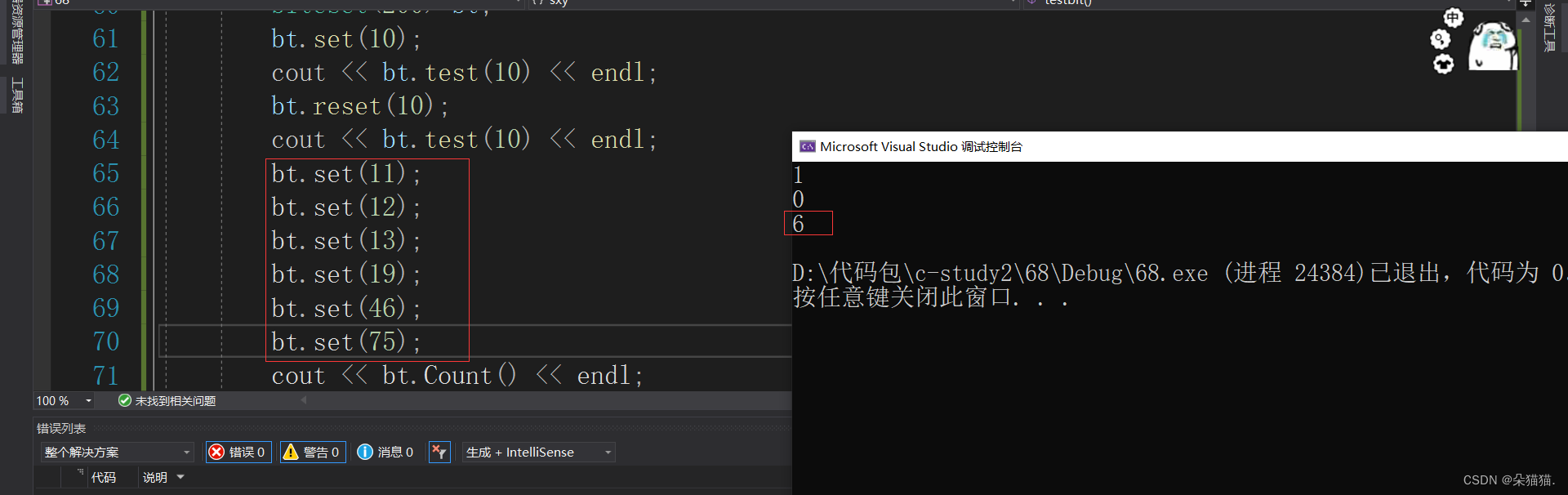
0000 0100在内存显示 :0 4 然后reset的时候又改回了00.下面我们多放几个值测试一下:
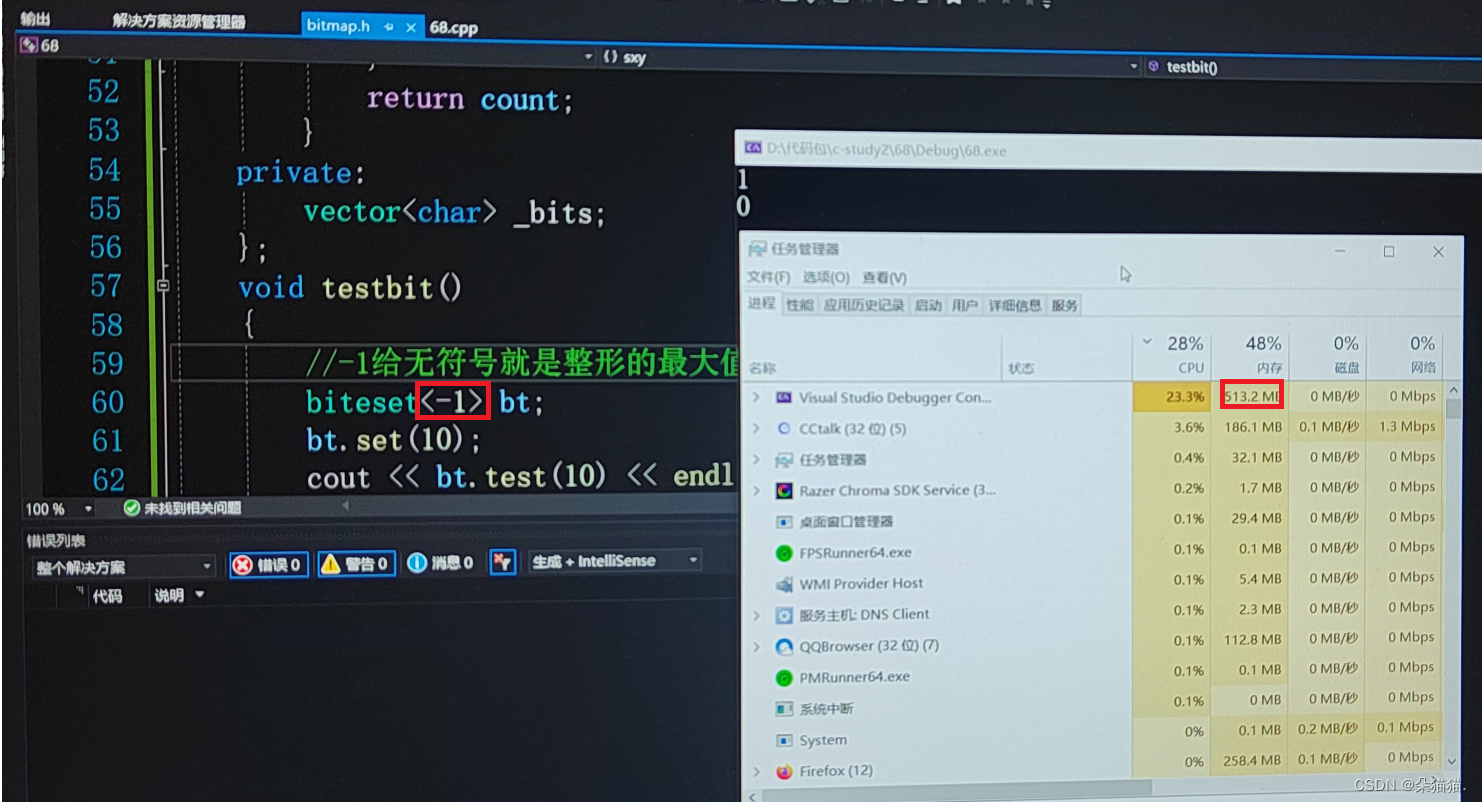
也是没问题的,这里我们讲一下如何开最大整形的比特位,我们的N是size_t无符号整数,当我们传-1时那么就是整形的最大值,如下图:
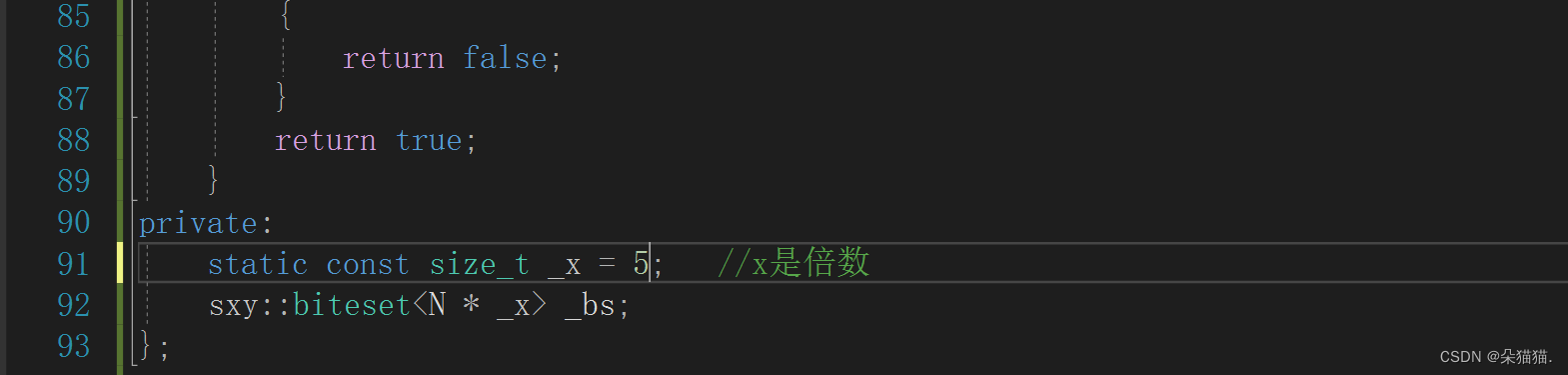
1.给定100亿个整数,设计算法找到只出现一次的整数?
其实很简单,还是我们刚刚的位图,只需要变形一下。我们用两个位图,这样每个值就有两个比特位来表示,00表示0次,01表示1次,10表示多次,然后没有其他情况,下面我们实现一下:
template <size_t N>
class two_biteset
{
public:
void set(size_t x)
{
//如果这个值没有被映射过
if (_bs1.test(x) == false && _bs2.test(x) == false)
{
// 00 我们以bs1代表左边那个0,bs2代表右边那个0
//要想00->01 只需要让s2变1
_bs2.set(x);
}
//如果这个值被映射过1次 01
else if (_bs1.test(x) == false && _bs2.test(x) == true)
{
//将1次改为多次,多次用10表示 01->10
_bs1.set(x);
_bs2.reset(x);
}
}
//打印出现1次的数
void print()
{
for (size_t i = 0; i < N; i++)
{
if (_bs2.test(i) == true)
{
cout << i << " ";
}
}
cout << endl;
}
private:
biteset<N> _bs1;
biteset<N> _bs2;
};我们直接复用刚刚的位图结构,代码中我们已经注释过了,需要注意的是,当用户开100个比特位时,那么要set的数一定是在0-100这个区间内的,超出这个区间的数算出来的第多少个char是越界的,所以我们打印的时候按照范围0-N即可。下面测试一下:
void test_twobite()
{
int a[] = { 1,1,4,4,89,95,45,45,65,65,25,25 };
two_biteset<100> bt;
for (auto& e : a)
{
bt.set(e);
}
bt.print();
}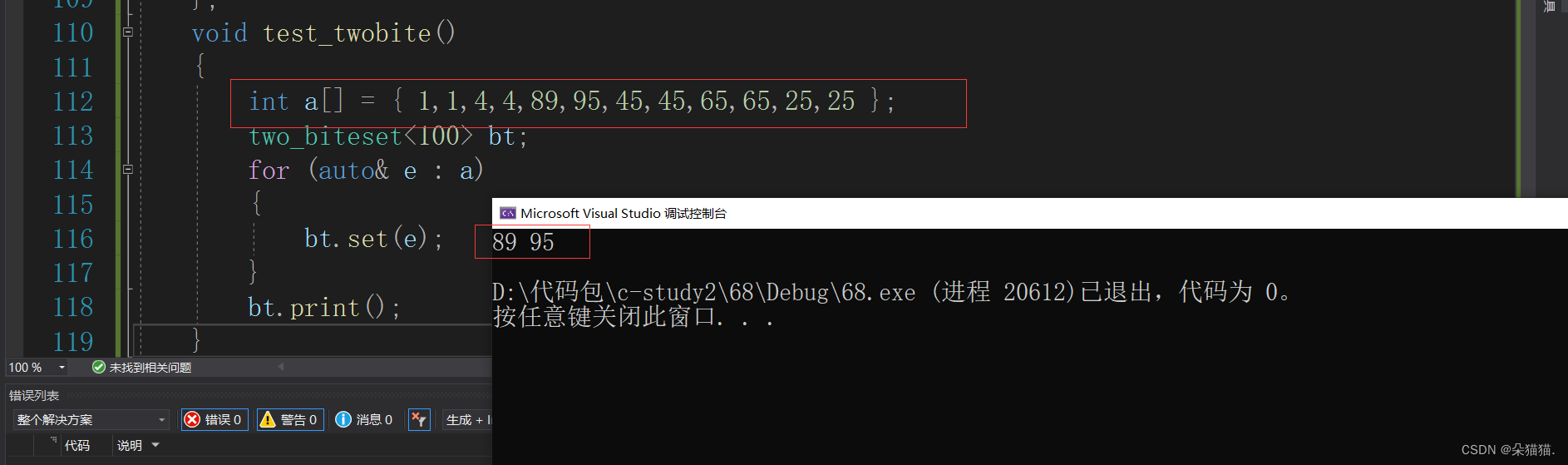
可以看到并没有问题,这样就解决了100亿个整数找出只出现1次的数的问题了。
2.给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
两个文件,100亿整数是400亿字节,也就是40G,两个40G的文件如何找交集呢?
1.将一个文件的数据映射到位图中,然后遍历第二个文件,判断第二个文件中的数是否在位图中存在,如果存在就是交集。当然有可能发生:第一个文件{1,3,4},第二个文件{1,1,3,4,4},这个时候判断出来的交集是{1,1,3,4,4,}也就是会有重复的值,所以我们可以再去一次重。当然也可以不去重,直接看是否存在,存在就保存这个交集中的值然后将这个值映射的比特位置为0,这样下面的重复值就不会被保存。
2.将两个文件分别映射到两个位图中,这样做可以直接去除两个文件中的重复值。然后范围遍历,两个位图中某个数都为true则这个数就是交集,代码如下:
for (size_t i = 0;i<N;i++)
{
if (bs1.test(i)==true&&bs2.test(i)==true)
{
//则是交集
}
}
3. 1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
不超过两次的整数就是1次和2次,所以我们将上面的代码修改一下,让10表示2次,11表示多次。
template <size_t N>
class three_biteset
{
public:
void set(size_t x)
{
//如果这个值没有被映射过
if (_bs1.test(x) == false && _bs2.test(x) == false)
{
// 00 我们以bs1代表左边那个0,bs2代表右边那个0
//要想00->01 只需要让s2变1
_bs2.set(x);
}
//如果这个值被映射过1次 01
else if (_bs1.test(x) == false && _bs2.test(x) == true)
{
//将1次改为2次,2次用10表示 01->10
_bs1.set(x);
_bs2.reset(x);
}
else
{
//多次用11表示
_bs1.set(x);
_bs2.set(x);
}
}
void print()
{
for (size_t i = 0; i < N; i++)
{
if (_bs1.test(i) == true && _bs2.test(i) == false
|| _bs1.test(i) == false && _bs2.test(i) == true)
{
cout << i << " ";
}
}
cout << endl;
}
private:
biteset<N> _bs1;
biteset<N> _bs2;
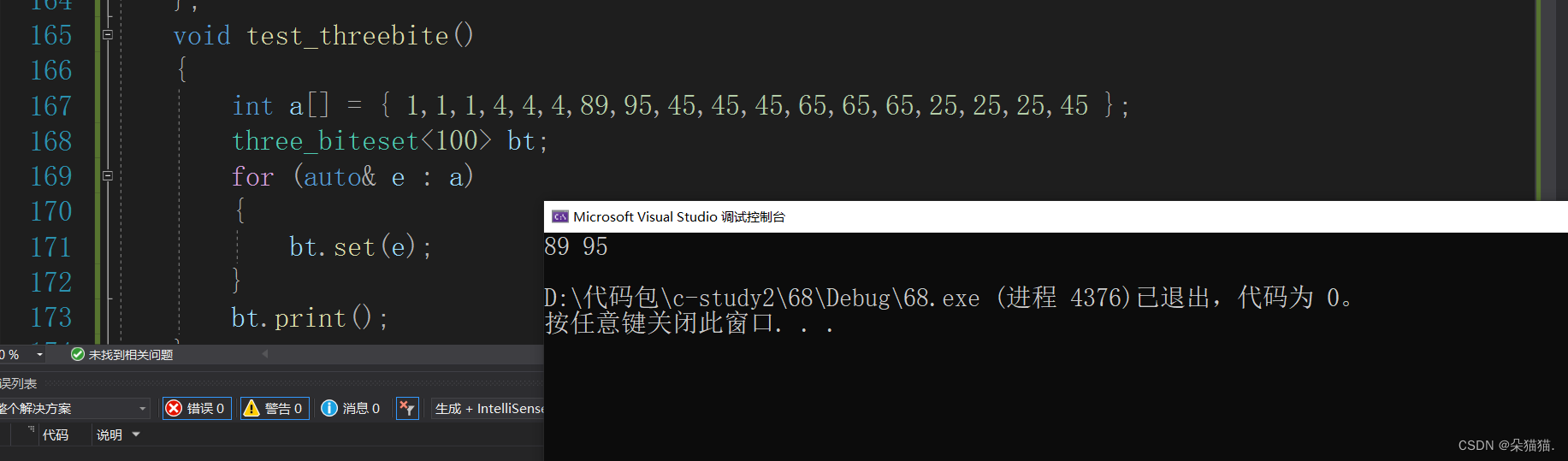
};void test_threebite()
{
int a[] = { 1,1,1,4,4,4,89,95,45,45,45,65,65,65,25,25,25,45 };
three_biteset<100> bt;
for (auto& e : a)
{
bt.set(e);
}
bt.print();
}
我们总结一下位图的优缺点:
优点:速度快,节省空间
缺点:只能映射整形,其他类型如:浮点数,string等等不能存储映射。
二、布隆过滤器
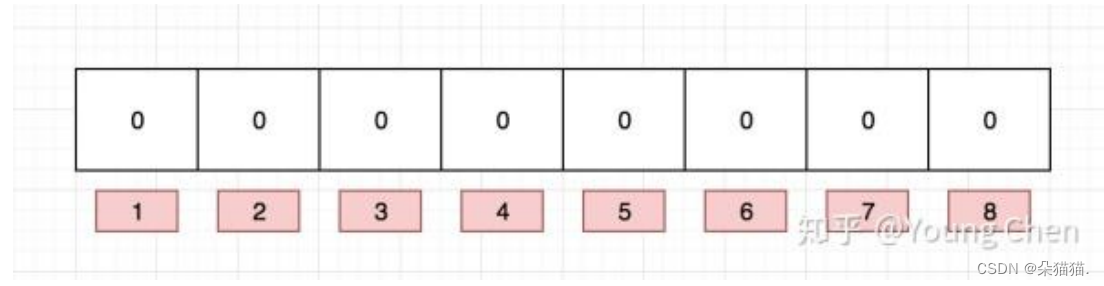
布隆过滤器实际上就是位图和哈希的组合,位图只能处理整形处理不了字符串,而布隆过滤器可以映射字符串,如下图(图片是转载):
这个时候向布隆过滤器插入“baidu”:
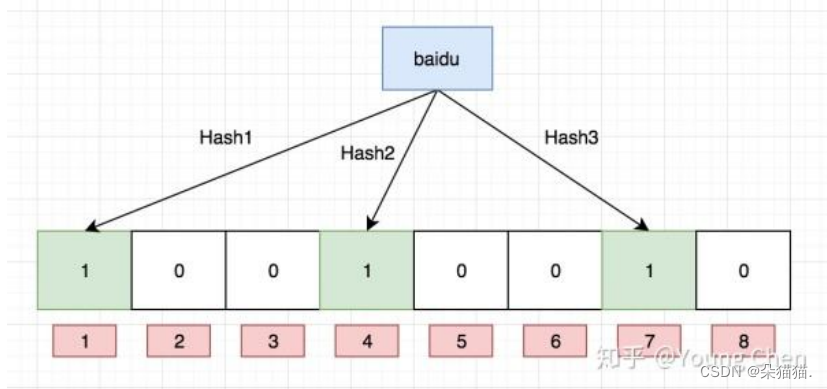
也就是说我们让哈希函数将字符串进行转化,转化后将这个值映射到位图中,学过哈希我们都知道哈希冲突是解决不了的,所以一定会存在冲突问题(一个值映射一个位置有很大概率会冲突,一个值映射多个位置就可以减少冲突),为了避免冲突我们就引入多个哈希函数,让多个哈希函数将字符串转化后映射到不同的比特位。
了解了以上知识后问大家一个问题,布隆过滤器是判断在的时候会被冲突还是判断不在的时候会被冲突呢?这里一定是在的时候被冲突,如下图:

现在有baidu和left两个字符串,如果有一个字符串hello计算出来的哈希值映射到位图中正好是baidu和left被置为1的位置,那么这个时候就会误判hello是存在,但实际上hello并不存在。所以布隆过滤器一定可以判断某个字符串不存在,而对于存在的情况会产生误判。所以布隆过滤器的使用场景是:能容忍误判的场景。比如:注册时快速判断昵称是否使用过
那么手机号码是否注册过可以用布隆过滤器判断吗?可以,但是一定要结合数据库。我们用布隆过滤器判断手机号码是否注册过,因为布隆过滤器判断不存在是准确的,所以如果不存在那么就一定没有注册过,如果判断存在我们就让其去数据库再判断一次,最后的结果是看数据库的结果,这样的效率比直接去数据库查找手机号码是否注册快了很多,因为数据库是在磁盘中存储的。
下面我们实现一下:
struct BKDRHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto& e : s)
{
hash += e;
hash *= 31;
}
return hash;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
size_t ch = s[i];
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
template <size_t N, class K = string,
class Hash1 = BKDRHash,
class Hash2 = APHash,
class Hash3 = DJBHash>
class BloomFilter
{
public:
void set(const K& key)
{
size_t hash1 = Hash1()(key) % N;
//用第一个哈希函数映射位图
_bs.set(hash1);
size_t hash2 = Hash2()(key) % N;
//用第二个哈希函数映射位图
_bs.set(hash2);
size_t hash3 = Hash3()(key) % N;
//用第三个哈希函数映射位图
_bs.set(hash3);
}
bool test(const K& key)
{
size_t hash1 = Hash1()(key) % N;
if (_bs.test(hash1) == false)
{
return false;
}
size_t hash2 = Hash2()(key) % N;
if (_bs.test(hash2) == false)
{
return false;
}
size_t hash3 = Hash3()(key) % N;
if (_bs.test(hash3) == false)
{
return false;
}
return true;
}
private:
sxy::biteset<N> _bs;
};首先模板参数中的N代表最多要插入多少个key数据的个数,K是存储数据的类型,然后就是3个哈希函数,当然也可以多来几个哈希函数。set也很简单,就是用哈希函数算出K类型的值然后去位图中映射,要注意的是我们每次算出来后都要对N进行一次取模。查找是否存在也很简单,只需要判断每一个哈希函数算出来的值映射的比特位是否为1,如果有一个为0那么一定不存在(这点我们上面说过,布隆过滤器判断不存在是准确的)。注意:布隆过滤器天生不支持删除,如果实现删除可以像我们用两个位图实现计数那样,要删除只需要--即可。
下面是哈希算法的网址:https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html
下面我们优化一下布隆过滤器:

也就是说哈希函数的个数和N之间有一个关系,3 = (m/n)*0.69,然后同时除0.69得到m与n之间是4倍的关系。

void set(const K& key)
{
size_t len = N * _x;
size_t hash1 = Hash1()(key) % len;
//用第一个哈希函数映射位图
_bs.set(hash1);
size_t hash2 = Hash2()(key) % len;
//用第二个哈希函数映射位图
_bs.set(hash2);
size_t hash3 = Hash3()(key) % len;
//用第三个哈希函数映射位图
_bs.set(hash3);
}
bool test(const K& key)
{
size_t len = N * _x;
size_t hash1 = Hash1()(key) % len;
if (_bs.test(hash1) == false)
{
return false;
}
size_t hash2 = Hash2()(key) % len;
if (_bs.test(hash2) == false)
{
return false;
}
size_t hash3 = Hash3()(key) % len;
if (_bs.test(hash3) == false)
{
return false;
}
return true;
}
下面我们打印哈希函数看一下冲突的情况:
void test_bloomfilter()
{
BloomFilter<100> bf;
bf.set("sort");
bf.set("bloom");
bf.set("hello world");
bf.set("test");
bf.set("etst");
bf.set("estt");
}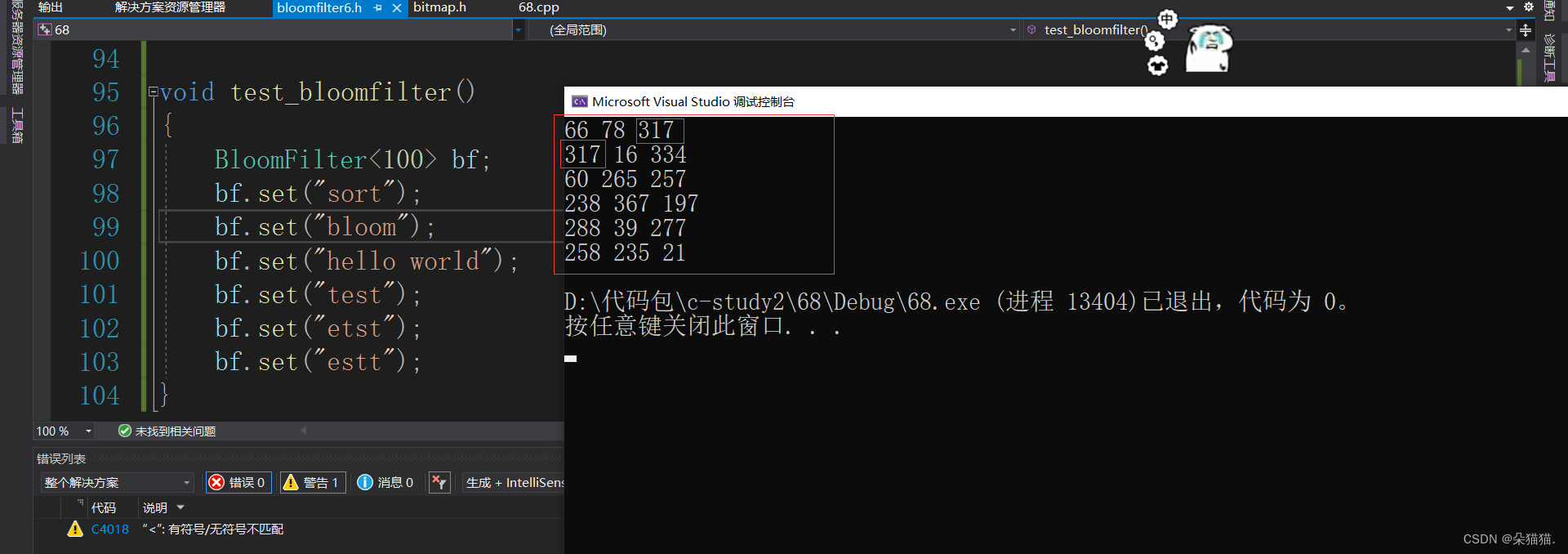
我们可以看到sort字符串的hash3这个值和bloom字符串的hash1冲突了都是相同的值,下面我们用一个测试用例来测试布隆过滤器发生冲突的百分比:
void test_bloomfilter2()
{
srand(time(0));
const size_t N = 10000;
BloomFilter<N> bf;
std::vector<std::string> v1;
std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(i));
}
for (auto& str : v1)
{
bf.set(str);
}
// v2跟v1是相似字符串集,但是不一样
std::vector<std::string> v2;
for (size_t i = 0; i < N; ++i)
{
std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
url += std::to_string(999999 + i);
v2.push_back(url);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.test(str))
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集
std::vector<std::string> v3;
for (size_t i = 0; i < N; ++i)
{
string url = "zhihu.com";
//string url = "https://www.cctalk.com/m/statistics/live/16845432622875";
url += std::to_string(i + rand());
v3.push_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
}v1是字符串集,v2是v1的相似字符串集合,下面我们运行一下:

测试后我们发现4倍的误判率在15%左右,下面我们换成5倍看看:
 可以发现5倍时误判率下降到了%6,但这是用空间换来的,以上就是布隆过滤器,下面我们做两道面试题:
可以发现5倍时误判率下降到了%6,但这是用空间换来的,以上就是布隆过滤器,下面我们做两道面试题:
我们之前用两个位图实现了计算数据1次两次或多次,如果要让布隆过滤器支持删除只需要把映射的值改为可以记录次数的,每次删除只需要--即可。
总结





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结