您现在的位置是:首页 >其他 >Python学习——数据排序及分箱pd.cutpd.qcut网站首页其他
Python学习——数据排序及分箱pd.cutpd.qcut
简介Python学习——数据排序及分箱pd.cutpd.qcut
文章目录
1 排序
dataFrame进行排序时,可以按照索引排序,也可以按照值进行排序。
1.1 按照索引排序 df.sort_index
df.sort_index() #按照索引进行排序,默认升序排序,axis决定按照行索引还是列索引
ascending=False #降序
df.reset_index() #重置索引,把原来的索引列转化成一个普通列,行索引用位置信息做索引名
二维列表排序

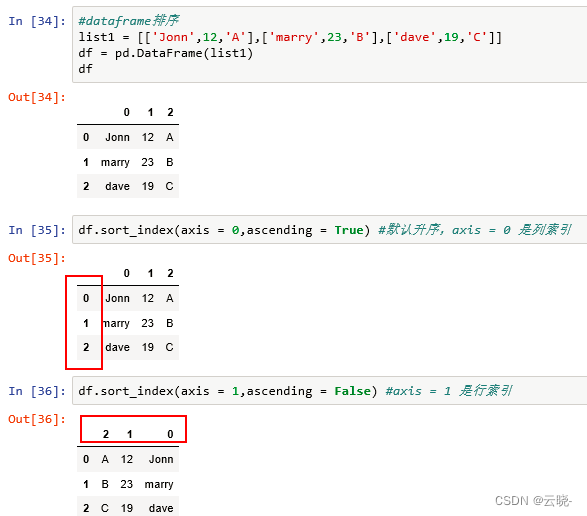
1.2 按照值进行排序 df.sort_values
df.sort_values(by = '列名') #按照某一列进行排序
df.sort_values(by =[ '列名','列名'],ascending=[False,True])

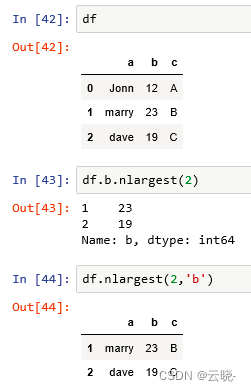
1.3 数值型数据快速排序 df.nlargest
df.列名.nlargest() #默认取前五个,先排序,取前五名
df.nlargest(5,'列名')
df.列名.nsmallest() #默认取后五个,先排序,取后五名
df.nsmallest(5,'列名')
2 分箱(离散化)
2.1 pd.cut
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
用途:返回 x 中的每一个数据 在bins 中对应 的范围
参数:
# x : 必须是一维数据
# bins: 不同面元(不同范围)类型:整数,序列如数组, 和IntervalIndex
# right: 最后一个bins是否包含最右边的数据,默认为True
# precision:精度 默认保留三位小数
# retbins: 即return bins 是否返回每一个bins的范围 默认为False
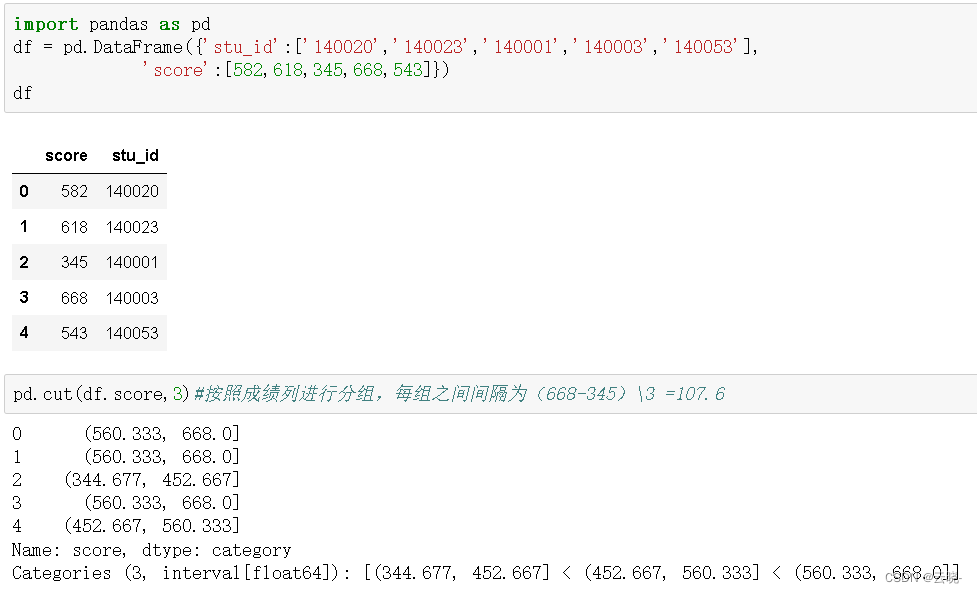
2.1.1 均匀切分,等距分箱
例:按照总分列进行分组,pd.cut(df.总分,n) 是把这一列数基于数值区间的大小分为n组,即(max-min)/n,然后统计每个数在哪一个区间,这样至于每个区间内有几个数就不一定了。
pd.cut(df.总分,3,labels=["不及格","及格","优秀"])

2.1.2 指定切分点切分
ser0=pd.cut(df.score,[300,400,600,800],labels=["不及格","及格","优秀"])
ser0

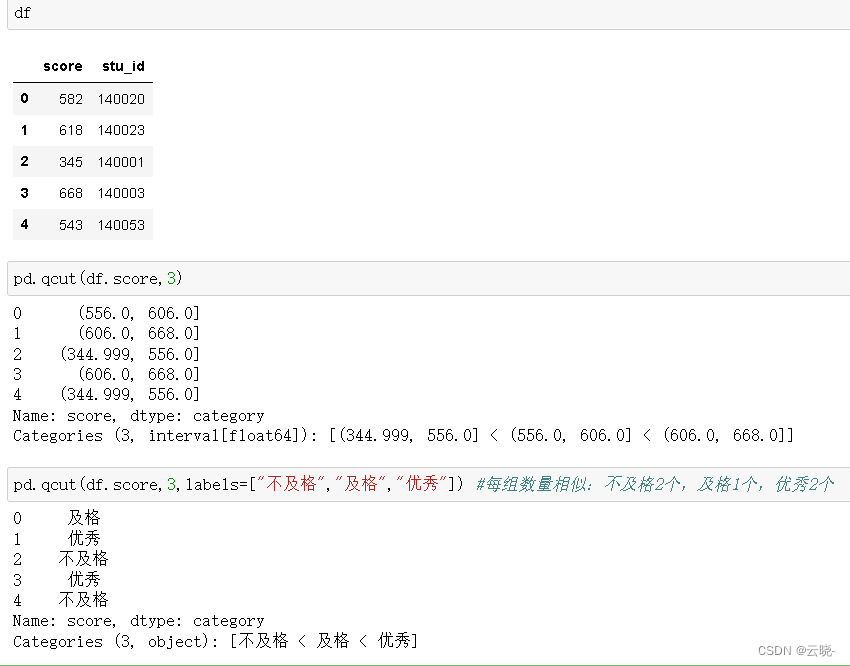
2.2 pd.qcut
等深分箱:每个离散化的类别中样本个数相似
pandas.qcut(x, q, labels=None, retbins=False, precision=3, duplicates=’raise’)
用途:基于样本分位数划分数据。即把一组数字按大小区间进行分区
参数:
# x:是数据 1d ndarray或Series
# q:整数或分位数数组;定义区间分割方法
例:按照总分列进行分组,pd.qcut(a,n) 就是把这一列数的个数等分为n组,然后根据每组数据的大小值确定分组区间。
pd.qcut(x, q)
参考链接:https://blog.csdn.net/tcy23456/article/details/84797418
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结