您现在的位置是:首页 >其他 >python爬虫学习简记(更新中)网站首页其他
python爬虫学习简记(更新中)
页面结构的简单认识
如图是我们在pycharm中创建一个HEML文件后所看到的内容
这里我们需要认识的是上图的代码结构,即html标签包含了head标签与body标签
table标签
table标签代表了一个网页页面中的表格,其包含了行和列,其中行标签我们使用tr标签,在行中我们可以定义列,列我们使用的是td标签
如图我们在body标签中 编写了上图代码,即定义了一个一行三列的表格
在浏览器中运行可以看到
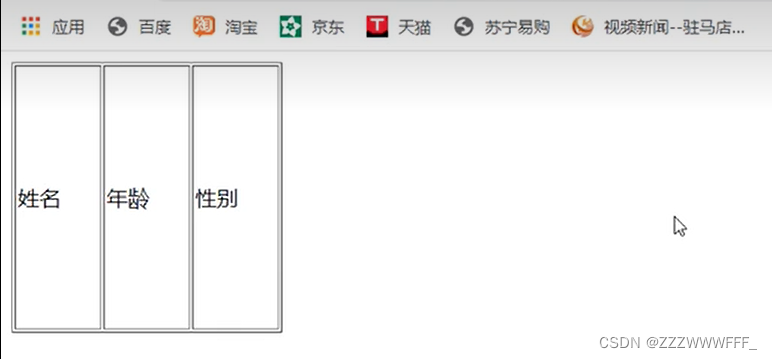
如果想要表格的结构更明确,我们可以这样
为表格添加一些属性,运行结果如下
ul标签
ul标签代表的是网页中的无序列表,我们可以往列表中添加我们想要的元素,这些元素我们使用li标签进行定义
ol标签
ol标签代表的是网页中的有序列表,其中的元素也是使用li标签定义
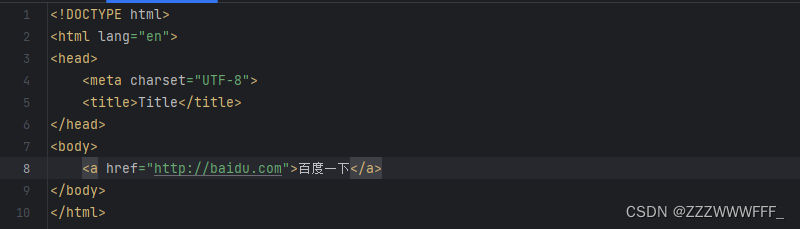
a标签
a标签代表的是网页中的超链接,即点击后可以进行页面的跳转,我们使用href属性指定想要的跳转到的域名
点击即跳转到百度








爬虫概念理解
我们一般有以下两种理解
- 通过一个程序,根据url进行爬取网页,获取有用信息
- 使用程序模拟浏览器,去向服务器发送请求,获取相应信息
爬虫核心
- 爬取网页:爬取整个网页,包含了网页中所有的内容
- 解析数据:将你得到的数据进行解析
- 难点:爬虫与反爬虫之间的博弈

urllib库使用
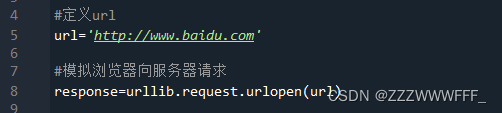
urllib是python自带的库,我们可以直接使用,无需下载,下面演示使用urllib爬取baidu首页源码
先导入该库
再使用urlopen()函数去向参数url发出请求,返回值为服务器的响应对象 ,其中包含了关于该网页的内容,也包括源码,我们使用read()方法即可得到源码,但是注意得到的是二进制形式的数据,因此我们需要将其解码,这里使用编码为utf8的decode()方法进行解码
再打印出解码后的数据即可
一个类型与六个方法
- 一个类型即我们上面样例中urlopen()的返回值为HTTPResponse类型
六个方法如下:
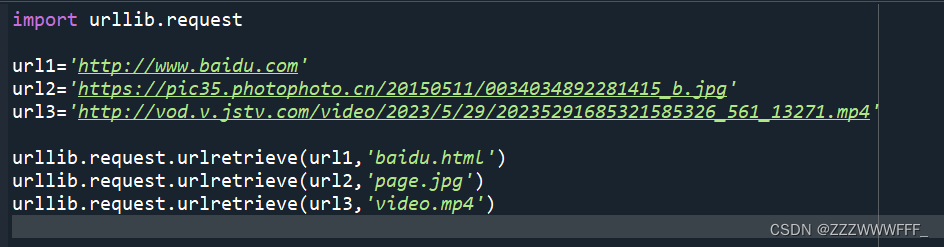
将爬取到的网页、图片、视频下载到本地
这里主要使用的函数是urlretrieve(参数1,参数2)
其中参数1是需要下载的对象地址,参数2是想要下载到的本地位置,上图中我没有指定位置,因此直接下载到的该python文件的目录下
反爬手段User-Agent
User Agent中文名为用户代理,简称 UA。
它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等等。
也就是说,假设:一个平台,设置了UA权限,必须以浏览器进行访问
当你使用爬虫脚本去访问该网站的时候,就会出现,访问失败、没有权限、或者没有任何资源返回的结果等错误信息。
那么我们应该如何克服它呢??
我们需要在爬虫时添加一个User-Agent请求头即可
具体怎么做呢?
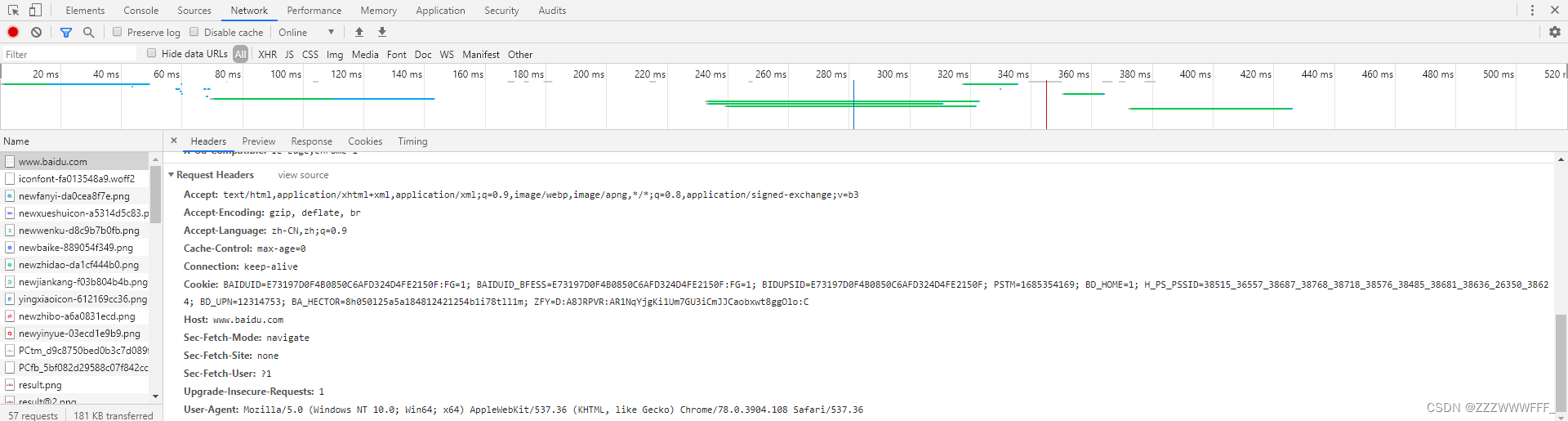
如上图所示,我们在爬取协议为https的百度首页时发现得到的源码很少,就是遇到了反爬手段UA
下面是对url知识的补充
https协议比http协议更为安全
好了继续解决UA
如上,我们在最下面可以看到网页的UA
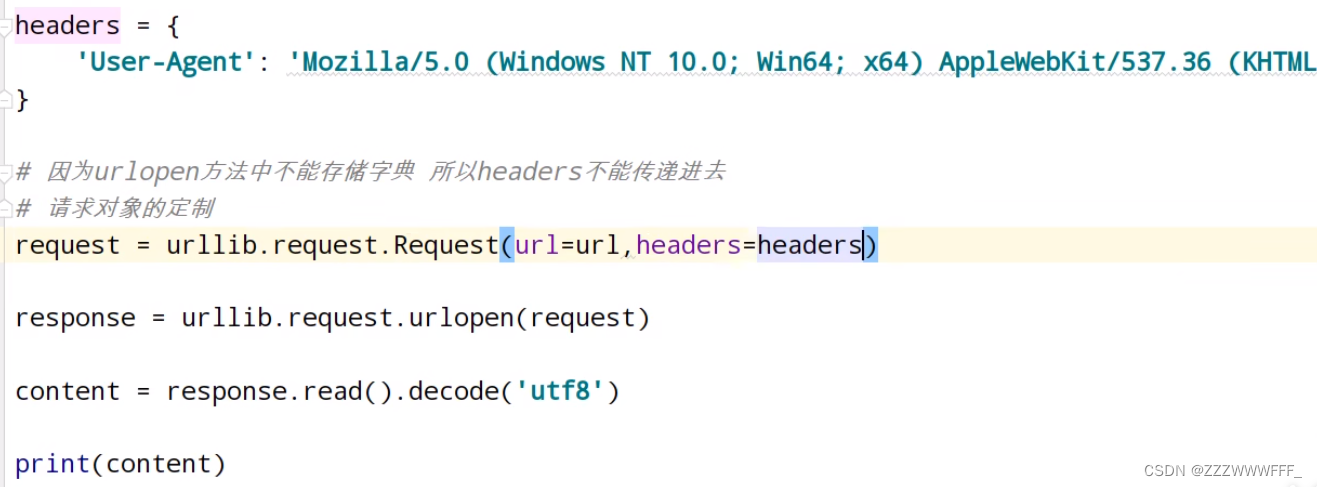
我们将其复制下来,在代码中存储为一个字典,然后使用Request得到一个带有UA的请求头的url,然后按照前面所学即可爬取内容啦
需要强调的是,这里因为Request()方法的参数第二个参数并非headers因此我们需要使用关键字传参
get请求的quote方法
在前面我们在代码中输入一个url时,我们可能会输入包含有中文字符的url
例如
此时如果我们直接就这样按照前面所学去爬取该域名内的源码,会出现编码报错问题,因此我们需要将“周杰伦”进行编码,这里就使用到了urllib.parse.quote()方法,该方法可以将中文字符编码为Unicode,再将其拼接到我们将被输入的url上即可
get请求的urlencode()方法
有时候我们会需要将多个参数拼接到我们的url上,但是此时再去使用quote方法便会变得麻烦,因此就有了urlencode方法,它用于拼接多个参数的url
如下我们将我们需要的参数wd与sex与location拼接到了我们的url上同时实现了爬虫
post请求
post是相对于前面所学的get请求的另外一种请求,二者的区别在于post请求的url参数并不是直接拼接在url后面的,而是在进行 请求对象的定制中 进行传参赋值
下面通过百度翻译例子进行解析
在百度翻译中输入python进行翻译后刷新,其实不难发现,页面上马上就发生了改变,其实这是浏览器快速对服务器进行了请求,我们通过查看这些请求,发现上图中该请求实现了翻译
在获取到该请求的url地址后,我们希望将kw参数传给它
正如上面所说,我们在进行请求对象定制的时候将参数data传给了url,这里需要注意的是data在作为参数传递时必须是编码后的形式,而urlencode得到的是字符串类型是不能直接作为data传给Request的,因此需要encode('utf-8')














站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结