您现在的位置是:首页 >技术交流 >PAN(Pyramid Attention Network for semantic segmentation)paper解读网站首页技术交流
PAN(Pyramid Attention Network for semantic segmentation)paper解读
Pyramid Attention Network for Semantic Segmentation讲PAN用于语义分割,网络结构类似encoder-decode, u-shape。
背景
encoder-decoder结构,
在encoding到高维度特征的过程中,原始的纹理信息会遭遇空间分辨率损失,例如FCN。
PSPNet和DeepLab用了空间金字塔和空洞卷积(ASPP)来对应这个问题,
然而ASPP容易引起grid artifacts, 空间金字塔会损失像素级别的定位信息。
作者从SENet和Parsenet中获得灵感,从高维特征中提取pixel level的attention信息。
PAN由2个结构组成,FPA(Feature Pyramid Attention)和GAU(Global Attention Upsample),
FPA类似于encoder和decoder的连接处,作用是增大感受野,区分较小的目标。
GAU类似FCN后面decoder的上采样,同时还能从高维度特征中提取attention信息,计算量也不会很大。
Related work
PAN结构类似于encoder-decoder, attention, 还考虑了PSPNet中的空间金字塔结构,
所以类似的work就有encoder-decoder, Global Context Attention, 空间金字塔。
encoder-decoder: 结构就不多说了,主要特点是连接相邻stage的特征,但没有考虑到全局的特征信息。
Global Context Attention:起源于ParseNet, 应用了一个global branch来增加感受野,加强pixel-wise分类的一致性。
DFN用了一个global pooling分支在U-shape的顶端,使U-shape变成了V-shape. 本文作者也用了global
average pooling加在decoder branch, 以选择有区分性的特征。
空间金字塔:用于提取多尺度信息。Spatial pyramid pooling适用于有不同尺度的目标。PSPNet和DeepLab系列把global pooling扩展为Spatial pyramid pooling和ASPP,虽说效果不错,但计算量很大。
PAN
PAN包括了FPA和GAU,模块如下图,backbone为ResNet-101,
FPA相当于encoder decoder的转折处。
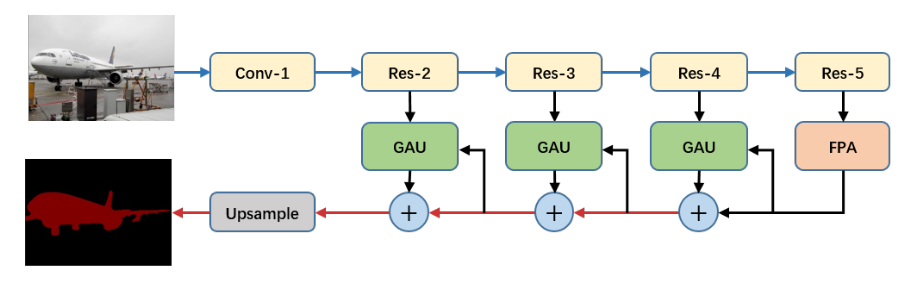
FPA
目的是为CNN的high-level特征提供pixel-wise的attention.
最近的语义分割中,金字塔结构可以提取不同尺度的特征,增大感受野,不过这种结构缺乏全局的信息(缺乏选择channel的机制)。
同时,如果选择channel attention的向量,那么又不能提取多尺度的特征,缺少了pixel-wise的信息。
作者把 pixel-wise的attention 和 多尺度的特征 结合起来。
于是,这个module就把3个不同尺度的特征用一个U-shape结构结合起来,为了提取不同尺度的特征,金字塔中用了3x3, 5x5, 7x7的卷积层。因为用的是高维特征,高维特征图通常比较小,所以较大的卷积核并不会带来很大的计算量。
然后,CNN输出的input特征通过一个1x1卷积之后,就可以和FPA输出的特征pixel-wise地相乘。起到了pixel wise attention的作用,又结合了多尺度。
又加上了前面提到的global branch, 用了global average pooling, 加到output特征。
最后得到的结构如下图,
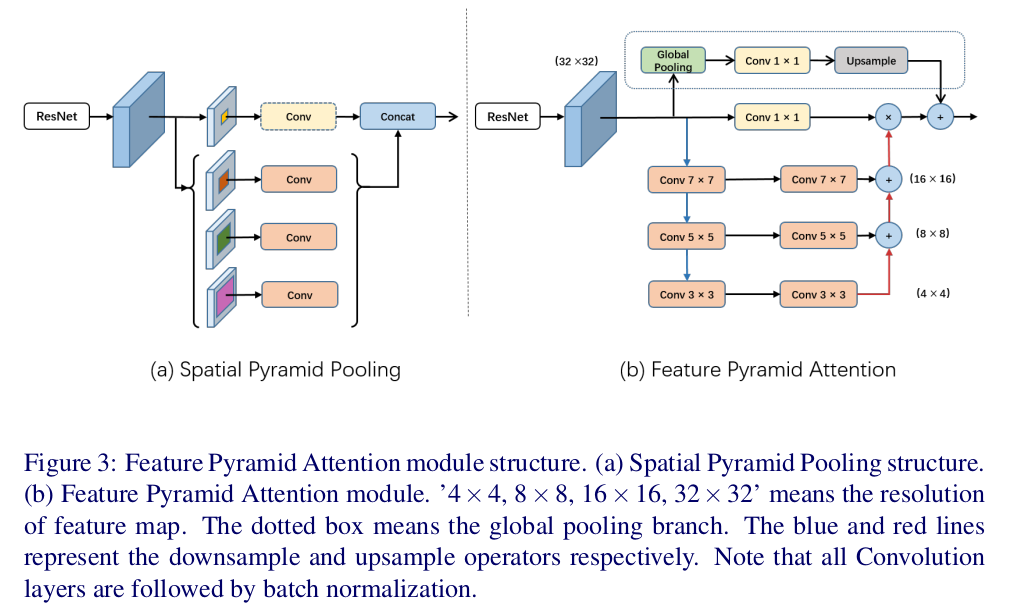
作者提到了在处理相乘之前做了channel reduce, 所以并不像PSPNet和ASPP那样耗大量的计算。
GAU
这块属于decoder,PSPNet和Deeplab中用了双线性插值上采样,可看作是简单的decoder.
一般的encoder-decoder网络主要考虑用不同尺度的特征,在decoder中逐渐恢复目标的边界。这种网络一般很复杂,计算量较大。
最近研究显示把CNN和金字塔结合起来可以提高效果, 类别信息也会加强。
作者考虑利用高维特征加辅助的类别信息 为 低维信息 提供权重,用来选择准确的细节。
GAU用了global average pooling提供全局信息,给低维特征提供权重,用来选择类别定位细节。
细节上,给低维特征过3x3卷积,用来reduce channel(减小计算量)。
高维特征通过global average pooling层,再过一个1x1卷积+BN+ReLU得到权重向量, 用这个权重和低维output相乘,
相乘的结果和原高维特征相加。
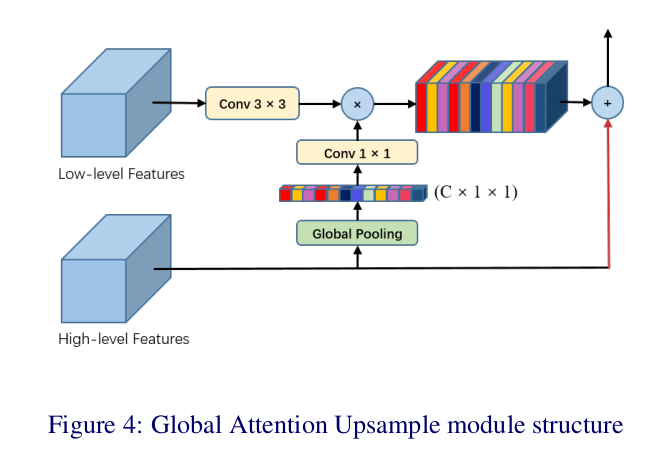
网络结构
网络结构贴在了PAN部分,再贴一遍吧
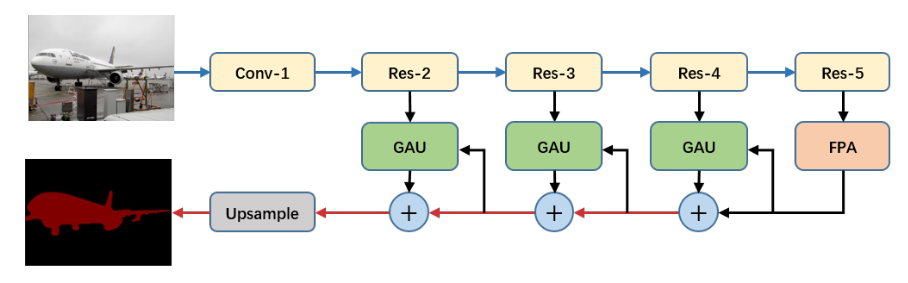
细节:
backbone: ResNet-101, 在ImageNet上预训练,
在res5b block上用rate=2的空洞卷积提取特征图,这样特征图的size是input image的1/16(和DeepLabv3+类似)。
把ResNet-101中的7x7卷积换成3个3x3conv(和PSPNet类似)
训练细节:

训练用的是扩充版的PASCAL, 参考数据集使用方法
github参考如下:
pytorch版目标分割
pytorch版语义分割






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结