您现在的位置是:首页 >技术交流 >基于ResNet-18实现Cifar-10图像分类网站首页技术交流
基于ResNet-18实现Cifar-10图像分类
目录
1、作者介绍
安耀辉,男,西安工程大学电子信息学院,22级研究生
研究方向:小样本图像分类算法
电子邮箱:1349975181@qq.com
张思怡,女,西安工程大学电子信息学院,2022级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:981664791@qq.com
2、数据集介绍
2.1Cifar-10数据集介绍:
CIFAR-10 数据集由 60000张图片,每张为32✖32大小的彩色图像组成,每类 6000 张图像。有 50000 张训练图像和 10000 张测试图像(共10个类,如图所示)。
数据集分为五个训练批次和一个测试批次,每个批次有 10000 张图像。测试批次包含来自每个类的 1000 个随机选择的图像。训练批次以随机顺序包含剩余的图像,但某些训练批次可能包含来自一个类的图像多于另一个类的图像。在它们之间,训练批次正好包含来自每个类的 5000 张图像。

3、ResNet网络介绍
3.1Residual Network残差网络
ResNet全名Residual Network残差网络。Kaiming He 的《Deep Residual Learning for Image Recognition》获得了CVPR最佳论文。他提出的深度残差网络在2015年可以说是洗刷了图像方面的各大比赛,以绝对优势取得了多个比赛的冠军。而且它在保证网络精度的前提下,将网络的深度达到了152层,后来又进一步加到1000的深度。论文的开篇先是说明了深度网络的好处:特征等级随着网络的加深而变高,网络的表达能力也会大大提高。因此论文中提出了一个问题:是否可以通过叠加网络层数来获得一个更好的网络呢?作者经过实验发现,单纯的把网络叠起来的深层网络的效果反而不如合适层数的较浅的网络效果。因此何恺明等人在普通平原网络的基础上增加了一个shortcut, 构成一个residual block。此时拟合目标就变为F(x),F(x)就是残差:
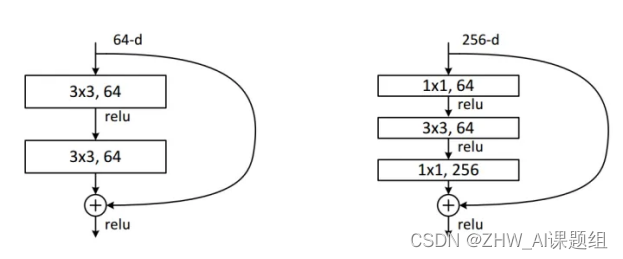
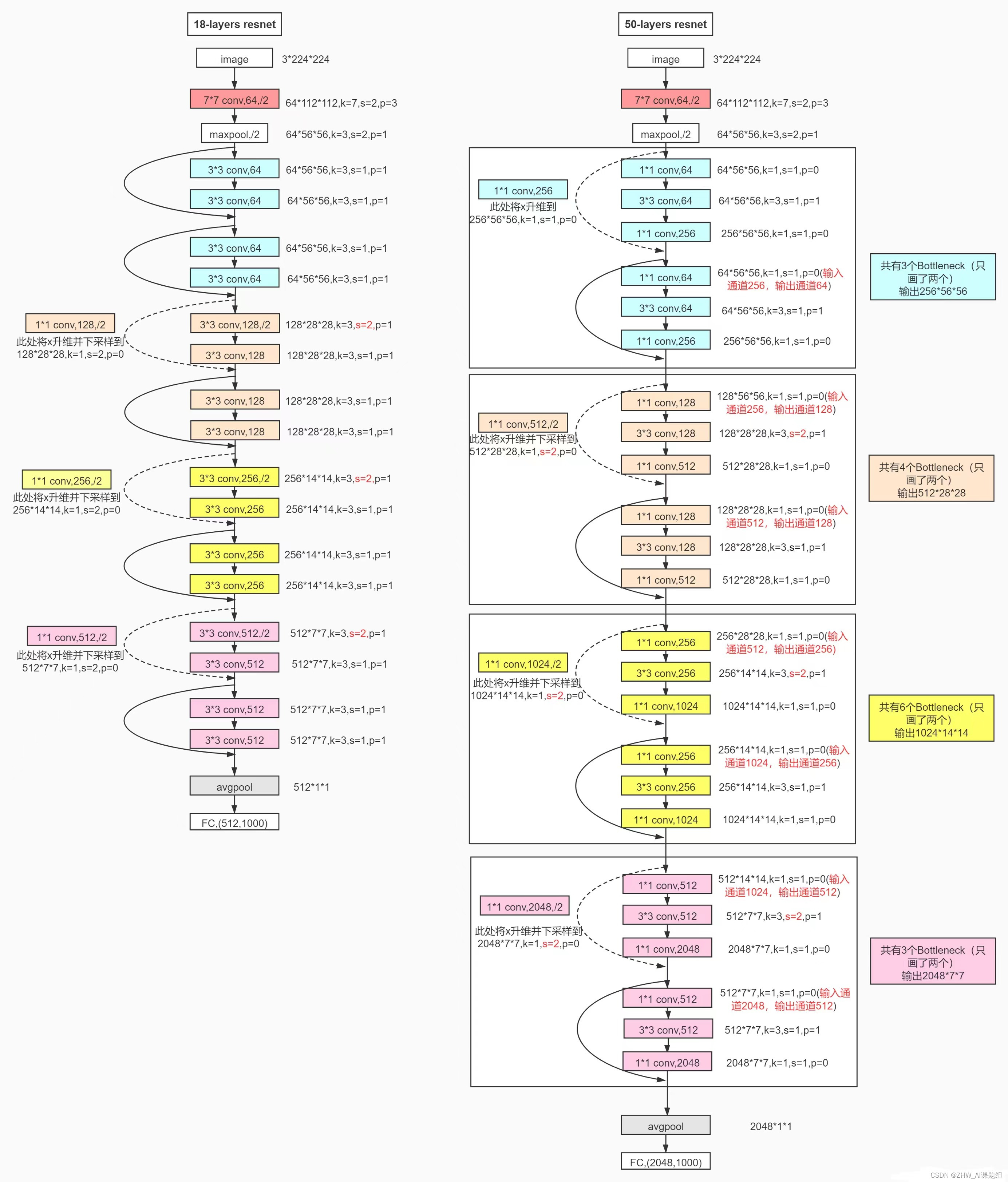
3.2ResNet18网络结构
这里给出比较详细的ResNet18网络具体参数和执行流程图:
4、代码复现及实验结果
4.1训练代码
import torch
import numpy as np
from tqdm import tqdm
import torch.nn as nn
import torch.optim as optim
from utils.readData import read_dataset
from utils.ResNet import ResNet18
# set device
device = 'cuda' if torch.cuda.is_available() else 'cpu' # gpu使能
# 读数据
batch_size = 128
train_loader,valid_loader,test_loader = read_dataset(batch_size=batch_size,
pic_path='D:AnYaohuiCifar10data')
# 加载模型(使用预处理模型,修改最后一层,固定之前的权重)
n_class = 10
model = ResNet18()
"""
ResNet18网络的7x7降采样卷积和池化操作容易丢失一部分信息,
所以在实验中我们将7x7的降采样层和最大池化层去掉,替换为一个3x3的降采样卷积,
同时减小该卷积层的步长和填充大小
"""
model.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1,
bias=False)
model.fc = torch.nn.Linear(512, n_class) # 将最后的全连接层改掉
model = model.to(device)
# 使用交叉熵损失函数
criterion = nn.CrossEntropyLoss().to(device)
# 开始训练
n_epochs = 250
valid_loss_min = np.Inf # track change in validation loss 表示+∞,是没有确切的数值的,类型为浮点型
accuracy = []
lr = 0.1
counter = 0
for epoch in tqdm(range(1, n_epochs+1)):
# keep track of training and validation loss
train_loss = 0.0
valid_loss = 0.0
total_sample = 0
right_sample = 0
# 动态调整学习率
if counter/10 ==1:
counter = 0
lr = lr*0.5
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
###################
# 训练集的模型 #
###################
model.train() #作用是启用batch normalization和drop out
for data, target in train_loader:
data = data.to(device)
target = target.to(device)
# clear the gradients of all optimized variables(清除梯度)
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
# (正向传递:通过向模型传递输入来计算预测输出)
output = model(data).to(device) #(等价于output = model.forward(data).to(device) )
# calculate the batch loss(计算损失值)
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
# (反向传递:计算损失相对于模型参数的梯度)
loss.backward()
# perform a single optimization step (parameter update)
# 执行单个优化步骤(参数更新)
optimizer.step()
# update training loss(更新损失)
train_loss += loss.item()*data.size(0)
######################
# 验证集的模型#
######################
model.eval() # 验证模型
for data, target in valid_loader:
data = data.to(device)
target = target.to(device)
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data).to(device)
# calculate the batch loss
loss = criterion(output, target)
# update average validation loss
valid_loss += loss.item()*data.size(0)
# convert output probabilities to predicted class(将输出概率转换为预测类)
_, pred = torch.max(output, 1)
# compare predictions to true label(将预测与真实标签进行比较)
correct_tensor = pred.eq(target.data.view_as(pred))
# correct = np.squeeze(correct_tensor.to(device).numpy())
total_sample += batch_size
for i in correct_tensor:
if i:
right_sample += 1
print("Accuracy:",100*right_sample/total_sample,"%")
accuracy.append(right_sample/total_sample)
# 计算平均损失
train_loss = train_loss/len(train_loader.sampler)
valid_loss = valid_loss/len(valid_loader.sampler)
# 显示训练集与验证集的损失函数
print('Epoch: {} Training Loss: {:.6f} Validation Loss: {:.6f}'.format(
epoch, train_loss, valid_loss))
# 如果验证集损失函数减少,就保存模型。
if valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(valid_loss_min,valid_loss))
torch.save(model.state_dict(), 'checkpoint/resnet18_cifar10.pt')
valid_loss_min = valid_loss
counter = 0
else:
counter += 1
4.2测试代码
import torch
import torch.nn as nn
from utils.readData import read_dataset
from utils.ResNet import ResNet18
# set device
device = 'cuda' if torch.cuda.is_available() else 'cpu'
n_class = 10
batch_size = 100
train_loader,valid_loader,test_loader = read_dataset(batch_size=batch_size,pic_path='dataset')
model = ResNet18() # 得到预训练模型
model.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
model.fc = torch.nn.Linear(512, n_class) # 将最后的全连接层修改
# 载入权重
model.load_state_dict(torch.load('checkpoint/resnet18_cifar10.pt'))
model = model.to(device)
total_sample = 0
right_sample = 0
model.eval() # 验证模型
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data).to(device)
# convert output probabilities to predicted class(将输出概率转换为预测类)
_, pred = torch.max(output, 1)
# compare predictions to true label(将预测与真实标签进行比较)
correct_tensor = pred.eq(target.data.view_as(pred))
# correct = np.squeeze(correct_tensor.to(device).numpy())
total_sample += batch_size
for i in correct_tensor:
if i:
right_sample += 1
print("Accuracy:",100*right_sample/total_sample,"%")
4.3实验结果
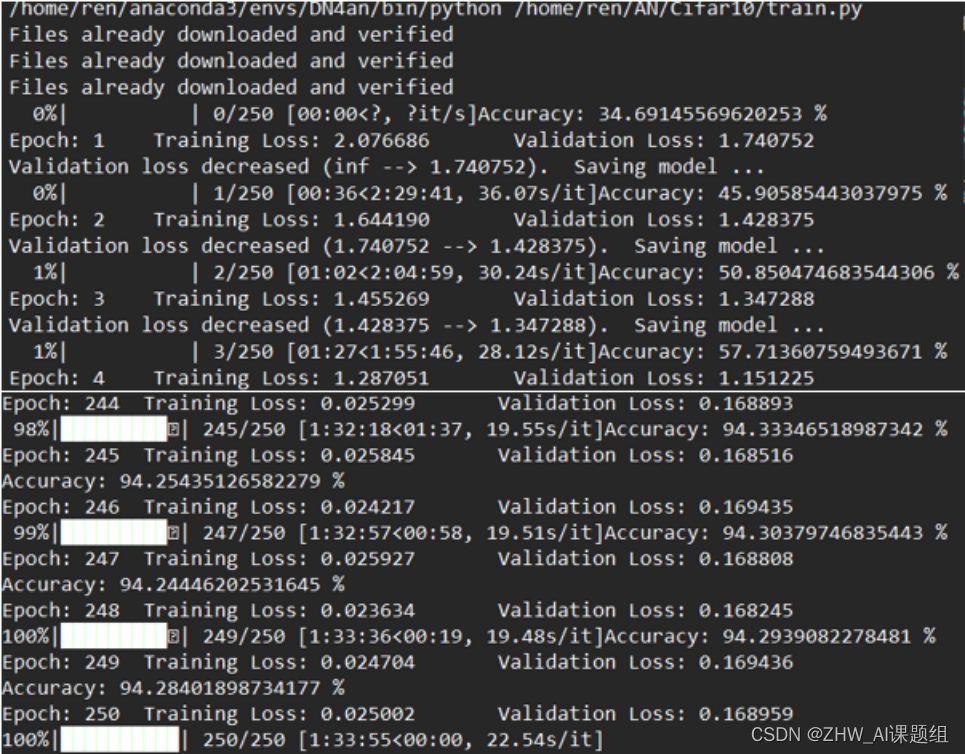
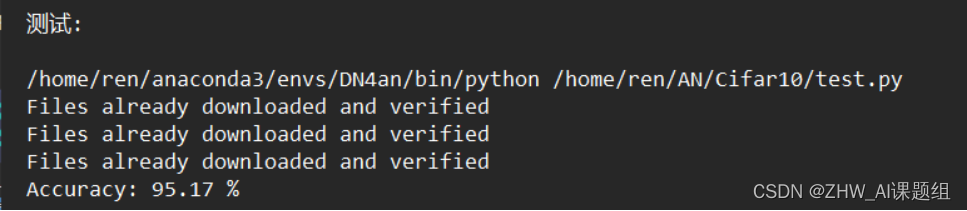






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结