您现在的位置是:首页 >学无止境 >HTTP/HTTPS协议详解网站首页学无止境
HTTP/HTTPS协议详解
目录
TCP/UDP是位于传输层的一种协议,而HTTP/HTTPS是位于应用层的的一中协议;
一. HTTP详解
✅1.1 概念
HTTP 协议一般指 HTTP(超文本传输协议),超文本传输协议(英语:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议,是因特网上应用最为广泛的一种网络传输协议,所有的 WWW 文件都必须遵守这个标准。HTTP 是为 Web 浏览器与 Web 服务器之间的通信而设计的,但也可以用于其他目的,HTTP 是一个基于 TCP/IP 通信协议来传递数据的(HTML 文件、图片文件、查询结果等)。
✅1.2 HTTP的协议格式
想要更好的看清HTTP的格式,我们可以通过抓包工具来解析,这里我推荐大家使用Fiddler进行抓包,亲测好用,下载链接:
Fiddler | Web Debugging Proxy and Troubleshooting Solutions (telerik.com)
https://www.telerik.com/fiddler我们通过访问百度来进行抓包,打开 Fiddler 我们可以看到:
1.2.1 HTTP请求体格式:
我们通过 Fiddler 来打开请求体可以看到:
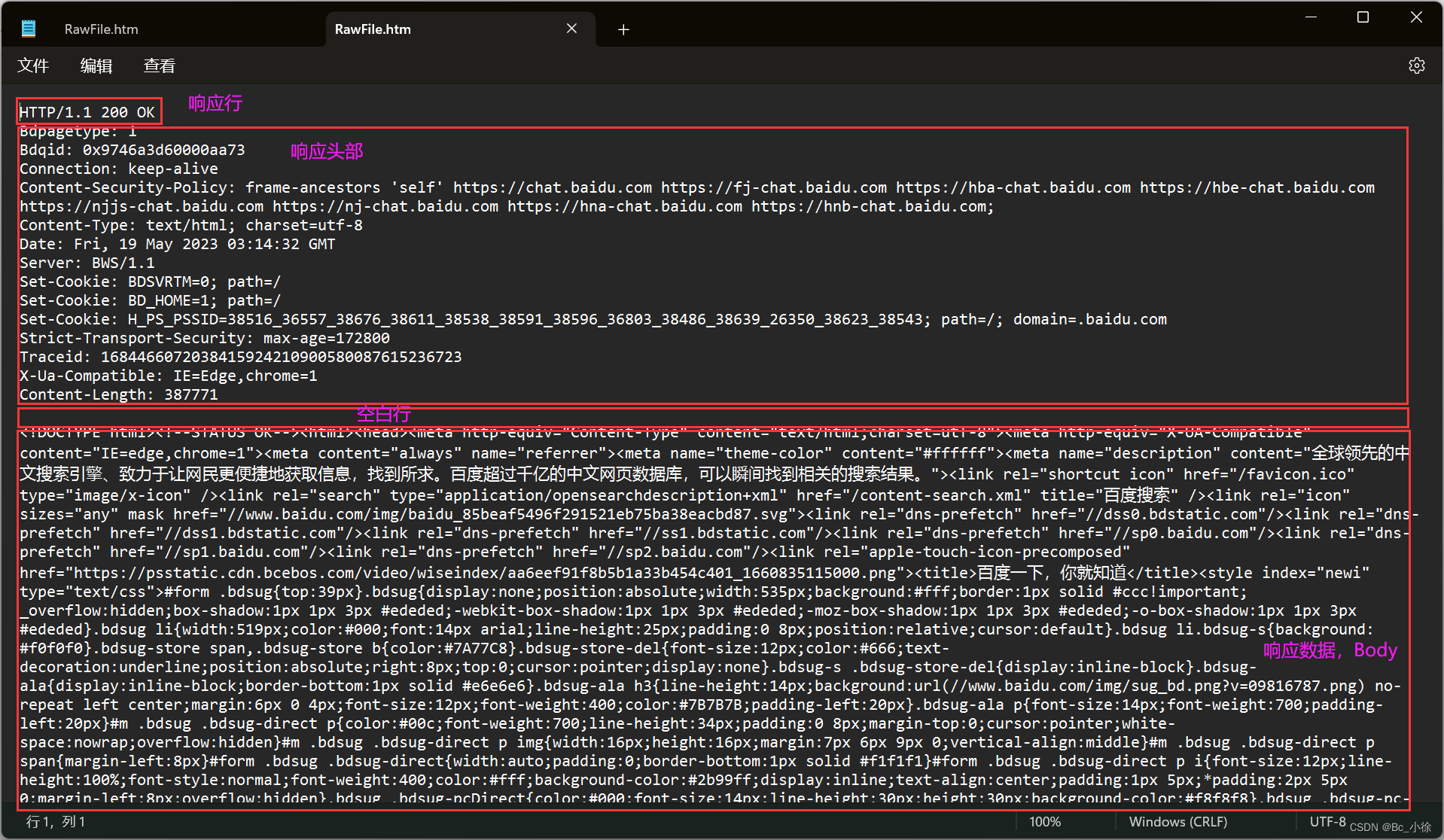
1.2.2 HTTP响应体格式:
我们通过 Fiddler 来打开响应体可以看到:
其实我们不难发现,HTTP响应的Body里就是HTML的本体,浏览器拿到了这个响应,也就拿到了HTML里面的所以信息,就可以显示了;




✅1.3 HTTP请求方法
根据 HTTP 标准,HTTP 请求可以使用多种请求方法;
这里最常用的就是 GET 和 POST 方法了;通俗点说 GET 就是从服务器里拿了什么数据,POST 就是往服务器里提交了什么数据,在我们日常使用中,绝大部分情况下我们都是GET,只有少部分会 POST ,举一个最常见的例子,我们登录或者上传文件的时候就是最常见的 POST 请求,GET 的 Body 一般为空,而 POST 的 Body 一般不为空,但是这个也不是绝对的;GET 是可缓存的,而 POST 不能;
序号 方法 描述 1 GET 请求指定的页面信息,并返回实体主体。 2 HEAD 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 3 POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 4 PUT 从客户端向服务器传送的数据取代指定的文档的内容。 5 DELETE 请求服务器删除指定的页面。 6 CONNECT HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 7 OPTIONS 允许客户端查看服务器的性能。 8 TRACE 回显服务器收到的请求,主要用于测试或诊断。 9 PATCH 是对 PUT 方法的补充,用来对已知资源进行局部更新 。
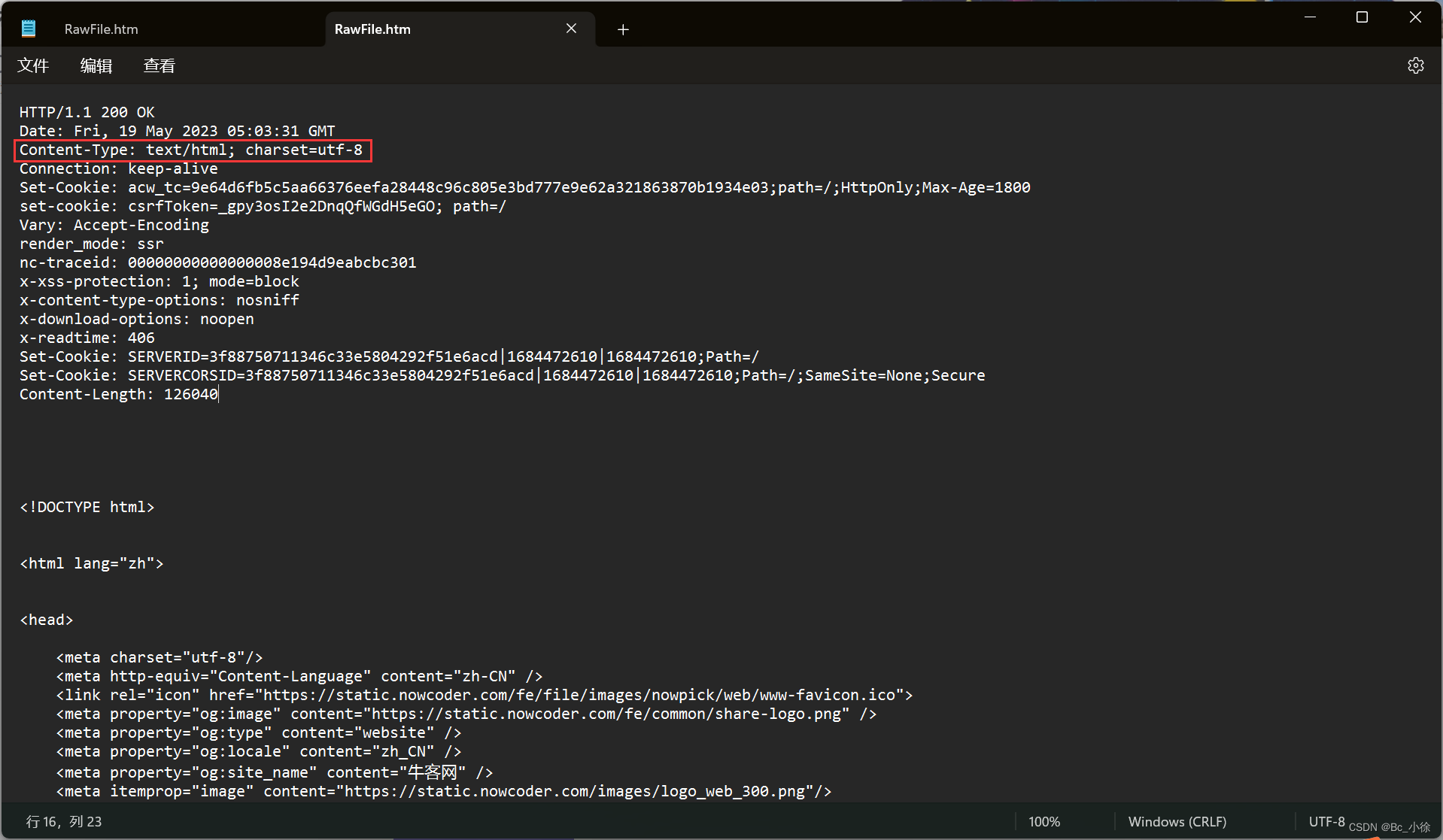
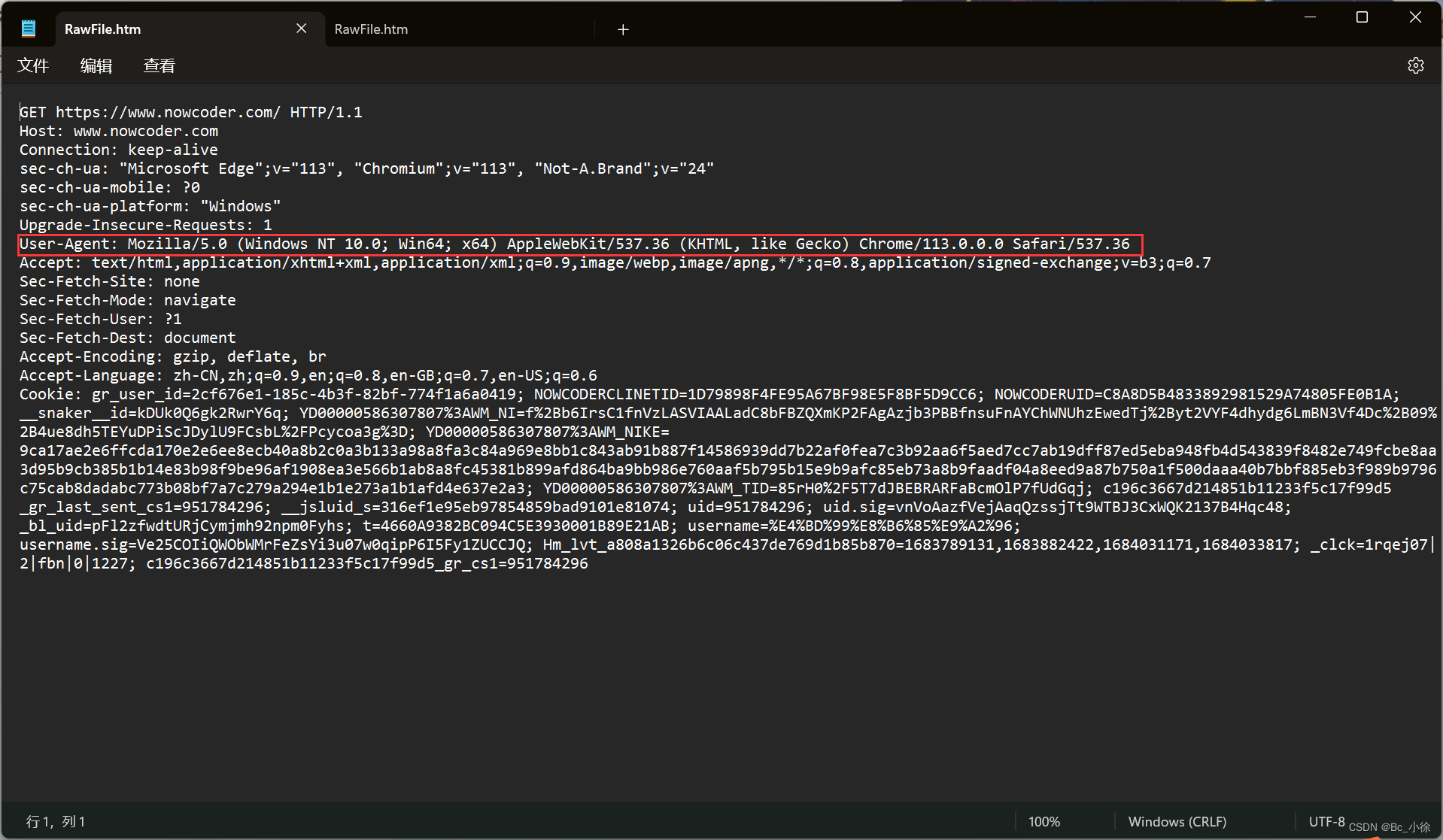
✅1.4 认识请求报头
1)Host:表示服务器主机的地址和端口.
2)Content-Length:表示 body 中的数据长度.
3)Content-Type:表示请求的 body 中的数据格式
4)User-Agent (简称 UA):表示浏览器/操作系统的属性
5)Referer:表示这个页面是从哪个页面跳转过来的.
6)Cookie:Cookie 中存储了一个字符串, 这个数据可能是客户端(网页)自行通过 JS 写入的, 也可能来自于服务器(服务器在 HTTP 响应的 header 中通过 Set-Cookie 字段给浏览器返回数据);
关于Cookie的几个点:
1. Cookie 从哪里来?
是从服务器来的,当我们的浏览器访问服务器的时候,服务器就会在HTTP响应中,通过 Set-Cookie 字段,把Cookie的键值对返回给浏览器,浏览器收到这个数据,就会保存到浏览器的本地存储;
2. Cookie到哪里去?
会在下次请求的时候把Cookie再带给服务器;
3. Cookie有什么用?
是浏览器本地存储数据的机制;




✅1.5 HTTP请求过程
HTTP请求过程实际上是一问一答的方式,就是浏览器向服务器发起请求,服务器会返回请求对应的数据包给浏览器;
✅1.6 认识状态码
1)200 OK
这是一个最常见的状态码, 表示访问成功,这里通过抓包可以看见;
2)404 Not Found
404表示没有找到资源,比如我们在百度的网址后面加个abc子目录,这里就会提示没有找到资源,因为百度的服务器上面没有你想要的东西,所以服务器不能返回给你想要的数据;
3) 403 Forbidden
表示访问被拒绝. 有的页面通常需要用户具有一定的权限才能访问(登陆后才能访问). 如果用户没有登陆,直接访问, 就容易见到 403,通俗点来说就是你没有访问的权限;
4)500 Internal Server Error
服务器出现内部错误. 一般是服务器的代码执行过程中遇到了一些特殊情况(服务器异常崩溃)会产生这个状态码;5)504 Gateway Timeout
当服务器负载比较大的时候, 服务器处理单条请求的时候消耗的时间就会很长, 就可能会导致出现超时的情况;6)302 Move temporarily
临时重定向(下次要不要继续重定向,这是不确定的)
重定向:就是访问旧的地址,被自动引导到一个新的地址上;
举个例子:假设我有一个用了好长时间的手机号码,我现在想换个新的号码,但是别人不知道我换了新的号码,所以就设置了一下,别人拨打我的旧手机号码时候,我让他自动跳转到新的号码,这样我就可以接到电话了;
7)301 Moved Permanently
永久重定向(一直都重定向了,以后都重定向了)


二. HTTPS详解
✅2.1 HTTPS简介
其实 HTTP 和 HTTPS 没有太大的本质区别,他们可以说是一对孪生兄弟,只不过 HTTPS在 HTTP 的基础上进行了加密;

✅2.2 HTTPS加密过程
1)对称加密
首先,客户端生成一个密钥key,通过key对所发送的数据进行加密,然后发送到服务器端,服务器端接收到之后,进行解密,再返回响应的响应给客户端,这一切看似平静祥和,但是如果中间出现一个黑客,在你转发的路由节点对这个key进行截获,也是轻而易举的事情,那么数据的安全性就得不到保障了;所以这里又引入了非对称加密;
2)非对称加密
非对称加密要用到两个密钥, 一个叫做 "公钥", 一个叫做 "私钥";
公钥和私钥是配对的. 最大的缺点就是运算速度非常慢,比对称加密要慢很多;
通过公钥对明文加密, 变成密文
通过私钥对密文解密, 变成明文对于非对称加密的工作流程是这样的:
1.客户端的目的的是想要自己的对称密钥key安全的传输给服务器;
2.首先客户端向服务器端索要公钥,然后服务器端把公钥返回给客户端,此时如果中间有黑客劫持的话,他也得到了公钥pub;
3.客户端使用pub对key进行加密,再发送给服务器端,但是此时黑客并不能截获这个key,因为这个key是被pub加密过的,只有服务器的私密pri才可以解开;
4.服务器端使用私密pri进行解密,得到了客户端发来的key;
3)证书加密
对于上述的非对称加密,看似是安全了,其实还是存在漏洞的,假设中间有黑客想要拦截数据,在第一步的过程中,服务器端返回公钥给客户端,黑客通过自己生成一对非对称密钥,把自己的公钥返回给客户端,这样一来,数据的安全性又得不到保障了;这里也就引入了证书加密进行安全的保障;证书这个东西是具有权威的官方机构下发的,黑客对此也束手无策,因此这样保证了安全性;
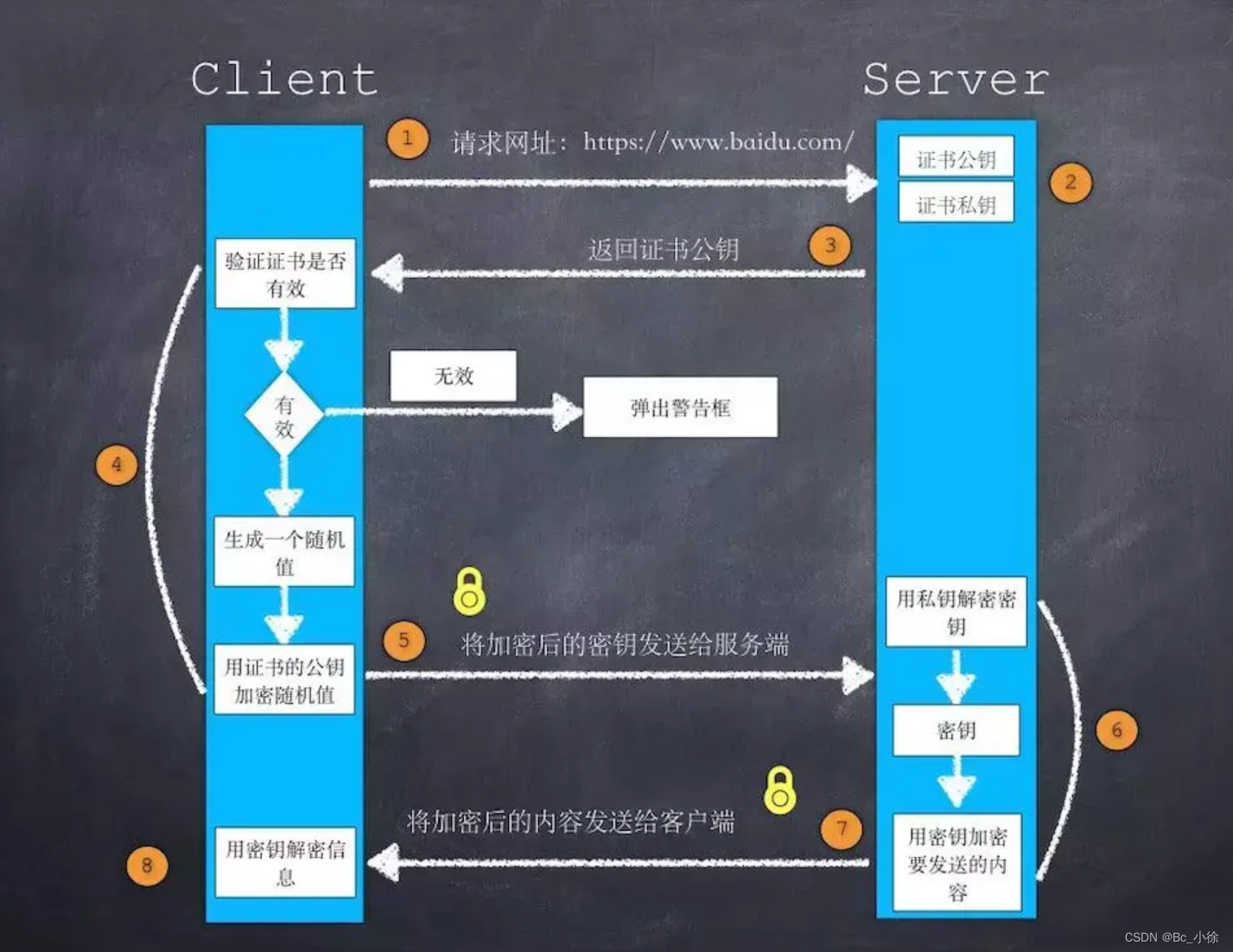
4)总结整个过程:
步骤1:客户端向服务器发送 HTTPS 请求
当客户端需要从服务器获取数据时,它会向服务器发送一个 HTTPS 请求。这个请求包括请求的 URL、HTTP 请求头和请求体;
步骤2:服务器将公钥证书发送给客户端
当服务器接收到 HTTPS 请求后,它会将公钥证书发送给客户端,公钥证书中包含了服务器的公钥、服务器的域名、证书颁发机构、证书有效期等信息,客户端接收到证书后,会从中提取出服务器的公钥;
步骤3:客户端验证服务器的证书
客户端接收到服务器的证书后,会对其进行验证,以确保该证书是由可信任的证书颁发机构颁发的,并且证书中的域名和服务器的实际域名一致,如果证书验证失败,客户端会中断连接。如果验证通过,客户端会生成一个用于会话的对称密钥;
步骤4:客户端生成一个用于会话的对称密钥
客户端生成一个用于会话的对称密钥。对称密钥是一种加密方式,它使用相同的密钥进行加密和解密。这个密钥只存在于客户端和服务器之间,因此被称为“对称”。
步骤5:客户端使用服务器的公钥对对称密钥进行加密,并将加密后的密钥发送给服务器
客户端使用服务器的公钥对对称密钥进行加密,并将加密后的密钥发送给服务器。在这个过程中,客户端和服务器都知道对称密钥,但是只有客户端知道对称密钥的值。
步骤6:服务器使用私钥对客户端发送的加密密钥进行解密,得到对称密钥
服务器使用私钥对客户端发送的加密密钥进行解密,得到对称密钥。由于私钥只在服务器端保存,因此只有服务器才能解密客户端发送的加密密钥,并得到对称密钥的值;
步骤7:服务器和客户端使用对称密钥进行加密和解密数据传输
服务器和客户端使用对称密钥进行加密和解密数据传输。这个对称密钥只存在于客户端和服务器之间,因此对数据的加密和解密只有客户端和服务器可以进行;








站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结