您现在的位置是:首页 >技术交流 >(大数据开发随笔9)Hadoop 3.3.x分布式环境部署——全分布式模式网站首页技术交流
(大数据开发随笔9)Hadoop 3.3.x分布式环境部署——全分布式模式
简介(大数据开发随笔9)Hadoop 3.3.x分布式环境部署——全分布式模式
完全分布式模式
- 分布式文件系统中,HDFS相关的守护进程也分布在不同的机器上,如:
- NameNode守护进程,尽可能单独部署在一台硬件性能较好的机器中
- 其他的每台机器上都会部署一个DataNode进程,一般的硬件环境即可
- SecondaryNameNode守护进程最好不要和NameNode在同一台机器上
守护进程布局
| NameNode | DataNode | SecondaryNameNode | |
|---|---|---|---|
| 主机名1 | √ | √ | |
| 主机名2 | √ | √ | |
| 主机名3 | √ |
集群搭建准备
总纲
- 三台机器的防火墙关闭
- 最好把selinux也关掉,
vi /etc/selinux/config——SELINUX=disabled
- 最好把selinux也关掉,
- 三台机器网络配置通畅(NAT模式,静态IP,主机名的配置)
/etc/host文件配置了ip和hostname的映射关系- 配置了三台机器的免密登录认证
- 时间同步
- jdk和hadoop环境变量配置
配置文件
-
`cd $HADOOP_HOME/etc/hadoop``
-
``vi core-site.xml`
<configuration> <!-- 设置namenode节点 --> <property> <name>fs.defaultFS</name> <value>hdfs://lanr:9820</value> </property> <!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-3.3.1/tmp</value> </property> </configuration> -
vi hdfs-site.xml<configuration> <!-- 块的副本数量 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- secondarynamenode守护进程的http地址;主机名:端口号 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>lanr2:9868</value> </property> <!-- namenode守护进程的http地址;主机名:端口号 --> <property> <name>dfs.namenode.http-address</name> <value>lanr:9870</value> </property> </configuration> -
vi hadoop-env.shexport JAVA_HOME=/usr/local/jdk1.8.0_321 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root # export YARN_RESOURCEMANAGER_USER=root # export YARN_NODEMANAGER_USER=root -
vi workers(删除已有的localhost)主机名1 主机名2 主机名3 -
分发:其他节点也需要保持相同的配置
rm -rf $HADOOP_HOME/tmp cd /usr/local/ scp -r jdk1.8.0_321/ hadoop-3.3.1/ lanr2:$PWD scp -r jdk1.8.0_321/ hadoop-3.3.1/ lanr3:$PWD scp /etc/profile lanr2:/etc/ scp /etc/profile lanr3:/etc/
-
格式化集群
hdfs namenode -format(仅在主机名1上运行)
启动集群
-
start-dfs.sh(仅在主机名1上运行) -
jps分别查看三个机器的节点: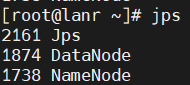
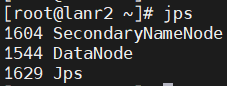
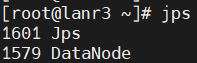
-
访问:192.168.{你的网段}.101 查看节点运行状态

集群控制命令
集群启停
start-dfs.sh # 启动HDFS所有进程(NameNode、SecondaryNameNode、DataNode)
stop-dfs.sh # 停止HDFS所有进程(NameNode、SecondaryNameNode、DataNode)
# hdfs --daemon start 单独启动一个进程
# 补充:daemon译为,守护进程
# 该命令只会启动当前机器上的进程,若当前机器上没有部署特定节点,则无法启动
hdfs --daemon start namenode
hdfs --daemon start secondarynamenode
hdfs --daemon start datanode
# hdfs --daemon stop 单独停止一个进程
hdfs --daemon stop namenode
hdfs --daemon stop secondarynamenode
hdfs --daemon stop datanode
hdfs --workers --daemon start datanode # 启动所有机器上的datanode
hdfs --workers --daemon stop datanode # 停止所有机器上的datanode
# 在哪台机器上运行都可以
进程查看
jps # 查看当前机器上的进程
# 查看所有机器上的进程情况
cd /opt/
mkdir bin
cd bin
vi jps-cluster.sh # 创建脚本
# 添加如下程序:
# -----------------复制以下内容----------------------
#!/bin/bash
HOSTS=( lanr lanr2 lanr3 )
for HOST in ${HOSTS[*]}
do
echo "---------- $HOST ----------"
ssh -T $HOST << DELIMITER
jps | grep -iv jps
exit
DELIMITER
done
# -----------------复制以上内容----------------------
sudo chmod a+x jps-cluster.sh # 赋予执行权限
ln -s /opt/bin/jps-cluster.sh /usr/bin/ # 软链接
-
启动集群:
start-dfs.sh;查看进程:jps-cluster.sh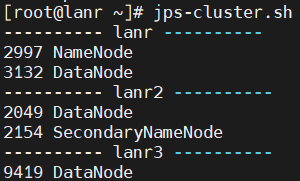
启动日志查看
- 启动节点进程时若出现问题,可以查看日志文件
- 日志的位置:
$HADOOP_HOME/logs/ - 日志的命名:
hadoop-username-daemon-hostname.log - 补充:
shift g跳转到文件最后;gg跳转到文件开头 - 查找error、warn日志:esc——
/error——enter——n查找下一个,shift n查找上一个
集群常见问题
- 格式化集群时报错:
- 当前用户使用不当
- 普通用户可能没有在hadoop安装路径下的权限
- /etc/hosts 里映射关系错误
- 免密登录认证异常
- jdk环境变量配置错误
- 防火墙没有关闭
- 当前用户使用不当
- namenode进程没有启动:
- 当前用户使用不当
- 重新格式化时,忘记删除${hadoop.tmp.dir}目录下的内容
- 网络震荡,造成edit日志文件的事务ID序号不连续
- datanode出现问题:
- /etc/host 里映射关系错误
- 免密登录异常
- 重新格式化时,忘记删除${hadoop.tmp.dir}目录下的内容,造成datanode的唯一标识符不在集群中
- 上述问题的暴力解决方法:重新格式化
- 若想重新格式化,先需要删除每台机器上的${hadoop.tmp.dir}指定路径下的所有内容,然后再进行格式化;最好把logs目录下的内容也清空
cd $HADOOP_HOME/——rm -rf logs/ tmp/(三个节点都要进行删除)rm -rf dfs/data/* dfs/name/*(三个节点都要进行删除)- 格式化集群:
hdfs namenode -format(仅在主机名1上运行)
- 若想重新格式化,先需要删除每台机器上的${hadoop.tmp.dir}指定路径下的所有内容,然后再进行格式化;最好把logs目录下的内容也清空
案例演示:WordCount
-
数据准备
cd ~ mkdir input && cd input echo "hello world hadoop linux hadoop" >> file1 echo "hadoop linux world hadoop linux hadoop" >> file1 echo "hello world hadoop linux hadoop" >> file1 echo "hello world hadoop linux hadoop" >> file1 echo "hello good programmer hadoop linux hadoop" >> file2 echo "hello world hadoop linux hadoop ok nice" >> file2 -
上传到集群
cd ~ hdfs dfs -put input/ / hdfs dfs -ls -R / # 递归查看hdfs上的文件夹与文件 hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output # 该input、output文件夹是在hdfs上的,不是linux本地的 且输出路径不能已存在 hdfs dfs -cat /output/* # 查看结果
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结