您现在的位置是:首页 >学无止境 >大数据分析案例-基于GBDT梯度提升决策树算法构建数据科学岗位薪资预测模型网站首页学无止境
大数据分析案例-基于GBDT梯度提升决策树算法构建数据科学岗位薪资预测模型

?♂️ 个人主页:@艾派森的个人主页
✍?作者简介:Python学习者
? 希望大家多多支持,我们一起进步!?
如果文章对你有帮助的话,
欢迎评论 ?点赞?? 收藏 ?加关注+
喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章
1.项目背景
该项目的背景是构建一个数据科学相关岗位薪资预测模型,帮助求职者更好地了解行业薪资水平,为求职者提供更加准确的薪资参考。
数据科学是一个快速发展的领域,与之相关的岗位也越来越多,比如数据分析师、机器学习工程师、数据挖掘工程师等。随着数据科学领域的发展,对这些岗位的需求也越来越大,因此对这些岗位的薪资水平进行预测具有很大的实用价值。
该项目的目标是使用GBDT算法构建一个数据科学相关岗位薪资预测模型,该模型将基于一些与薪资相关的特征(比如学历、工作经验、所在城市等)来预测岗位的薪资水平。预测模型的输出将是一个连续值,表示该岗位的薪资范围。为了构建这个模型,需要收集大量的数据,并对数据进行预处理和特征工程,以提高模型的预测性能。
该项目的应用场景非常广泛,比如可以为求职者提供更加准确的薪资参考,为企业提供更加科学的薪资策略制定依据,为人力资源管理提供更加全面的数据支持,等等。因此,该项目具有非常大的实用价值和广阔的应用前景。
2.项目简介
2.1项目说明
本项目旨在分析数据科学相关岗位的薪资情况,探究数据科学岗位的规律,最后建立回归模型来预测数据科学相关岗位的薪资,并找出影响薪资的重要因素。
2.2数据说明
本数据集来源于kaggle,原始数据集共有3755条, 11列特征,各特征具体含义如下:
work_year:发工资的年份。
experience_level:该职位在一年内的经验水平
employment_type:角色的雇佣类型
job_title:这一年中工作的角色
工资:支付的工资总额
salary_currency:作为ISO 4217货币代码支付的工资的货币
salaryinusd:以美元计算的工资
employee_residence:作为ISO 3166国家代码,雇员在工作年度的主要居住国家
remote_ratio:远程完成的总工作量
company_location:雇主的主要办事处或承包分公司所在的国家
company_size:该年度为该公司工作的人数中位数
2.3技术工具
Python版本:3.10
代码编辑器:jupyter notebook
3.算法原理
GBDT(Gradient Boosting Decision Tree)是一种常见的集成学习算法,其基本原理是利用多个决策树进行集成,从而提高预测性能。在GBDT中,每个决策树都是基于梯度提升(Gradient Boosting)算法构建的,因此GBDT也被称为梯度提升决策树(Gradient Boosting Decision Tree)。
梯度提升算法的基本思路是,首先构建一个简单的模型(如单个决策树),然后对模型进行改进,使其能够更好地拟合数据。在每一轮迭代中,梯度提升算法都会使用当前模型的预测结果与真实值之间的误差来构建一个新的模型,并将其与当前模型相加。这样,模型的预测结果就会逐步接近真实值,从而提高模型的预测性能。
具体来说,GBDT的算法流程如下:
-
初始化模型:将目标变量的平均值作为初始模型的预测结果。
-
迭代训练:在每一轮迭代中,执行以下步骤:
a. 计算残差:用当前模型的预测结果与真实值之间的差值作为残差。
b. 构建新模型:使用残差作为目标变量,构建一棵新的决策树模型。
c. 更新模型:将新模型的预测结果与当前模型的预测结果相加,得到更新后的模型。
-
返回模型:当迭代次数达到设定的值或者模型的性能满足一定的条件时,返回最终的模型。
在GBDT中,每个决策树都是基于回归树(Regression Tree)算法构建的。在构建每个决策树时,通常会采用贪心策略来选择最优的划分点,以最小化预测误差。同时,为了避免过拟合,通常会对决策树进行剪枝操作。
GBDT算法的优点是能够有效地处理非线性关系和高维数据,具有很强的预测能力和鲁棒性。但是,GBDT算法也存在一些缺点,比如对异常值和噪声数据比较敏感,需要进行特殊处理。此外,由于每个决策树都是串行构建的,因此算法的训练速度较慢。
4.项目实施步骤
4.1理解数据
首先使用pandas导入原始数据集并查看前五行
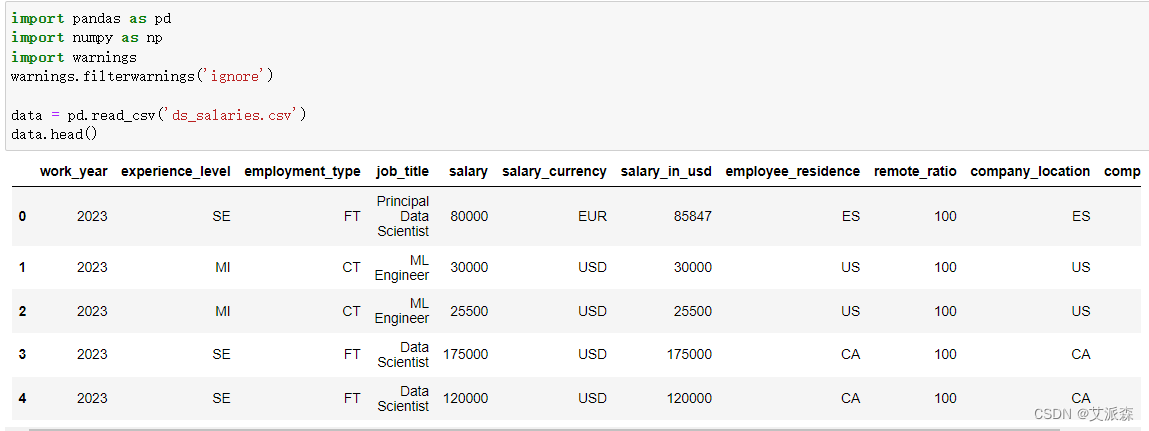
查看数据大小
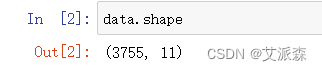
查看数据基本信息
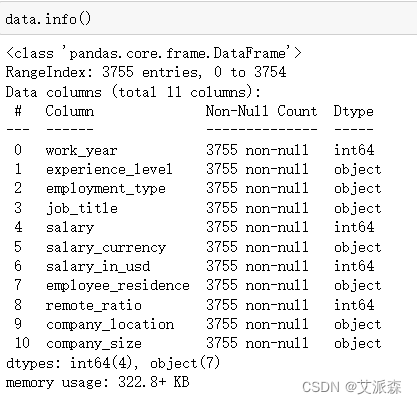
查看数值型数据的描述性统计
查看非数值型数据的描述性统计
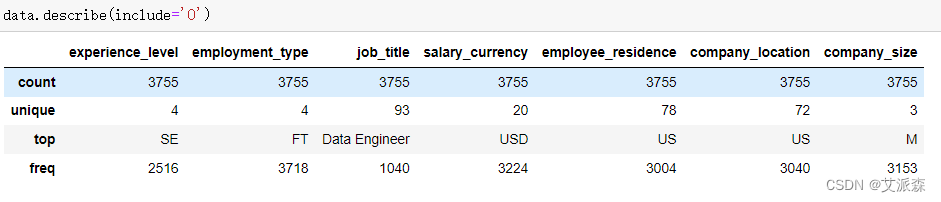
4.2数据预处理
查看数据是否有缺失值
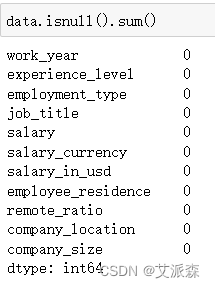
从结果中发现,每列特征都不存在缺失值,故不需要处理
检验数据是否存在重复值
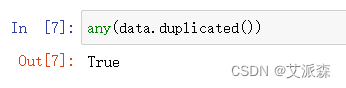
结果为True表明存在重复值,需要进行处理
这里我们直接删除即可
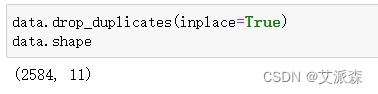
可以发现删除重复值的数据明显少了很多,说明原始数据集质量不好
4.3探索性数据分析
4.3.1分析工作年份
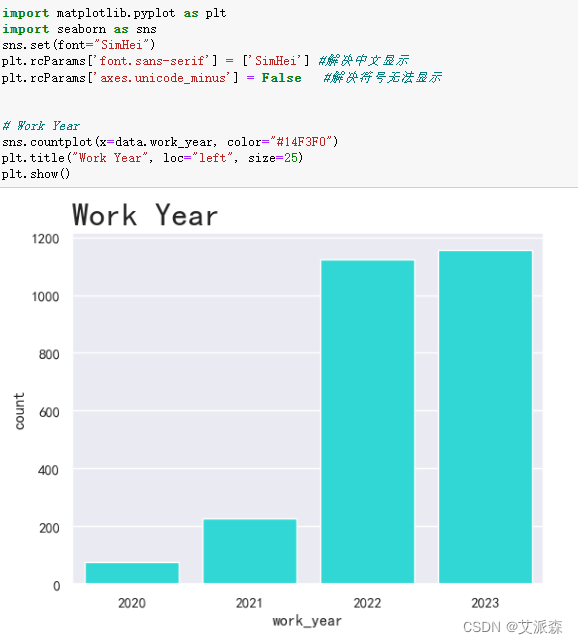
从结果看出,该数据集主要是针对2022和2023年的。
4.3.2分析工作经验水平
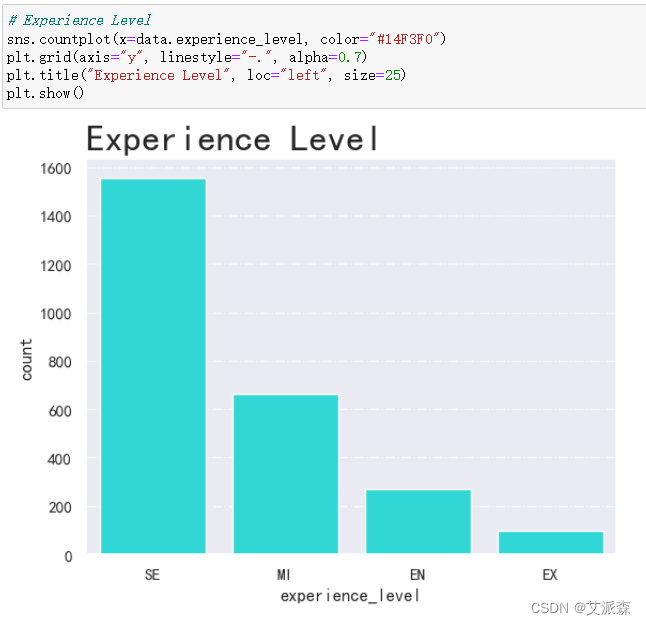
从结果看出,水平为SE的数据最多,EX的数据最少。
4.3.3分析雇佣类型
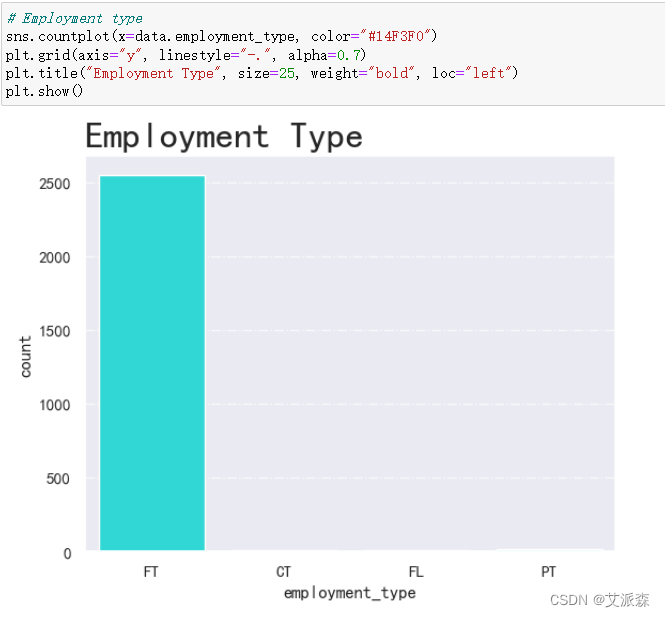
从结果发现该数据集几乎的雇员类型都是FT,说明这列特征没有意义,建模的时候需要删除。
4.3.4分析工作角色
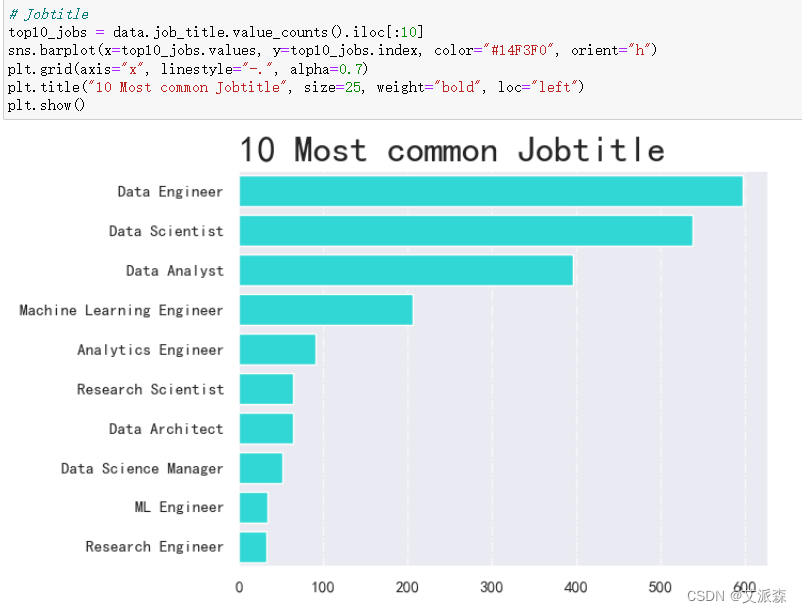
从结果看出,人数最多的是数据工程师、数据科学家、数据分析师。
接着我们使用词云图进行展示一下
 4.3.5分析薪资水平
4.3.5分析薪资水平

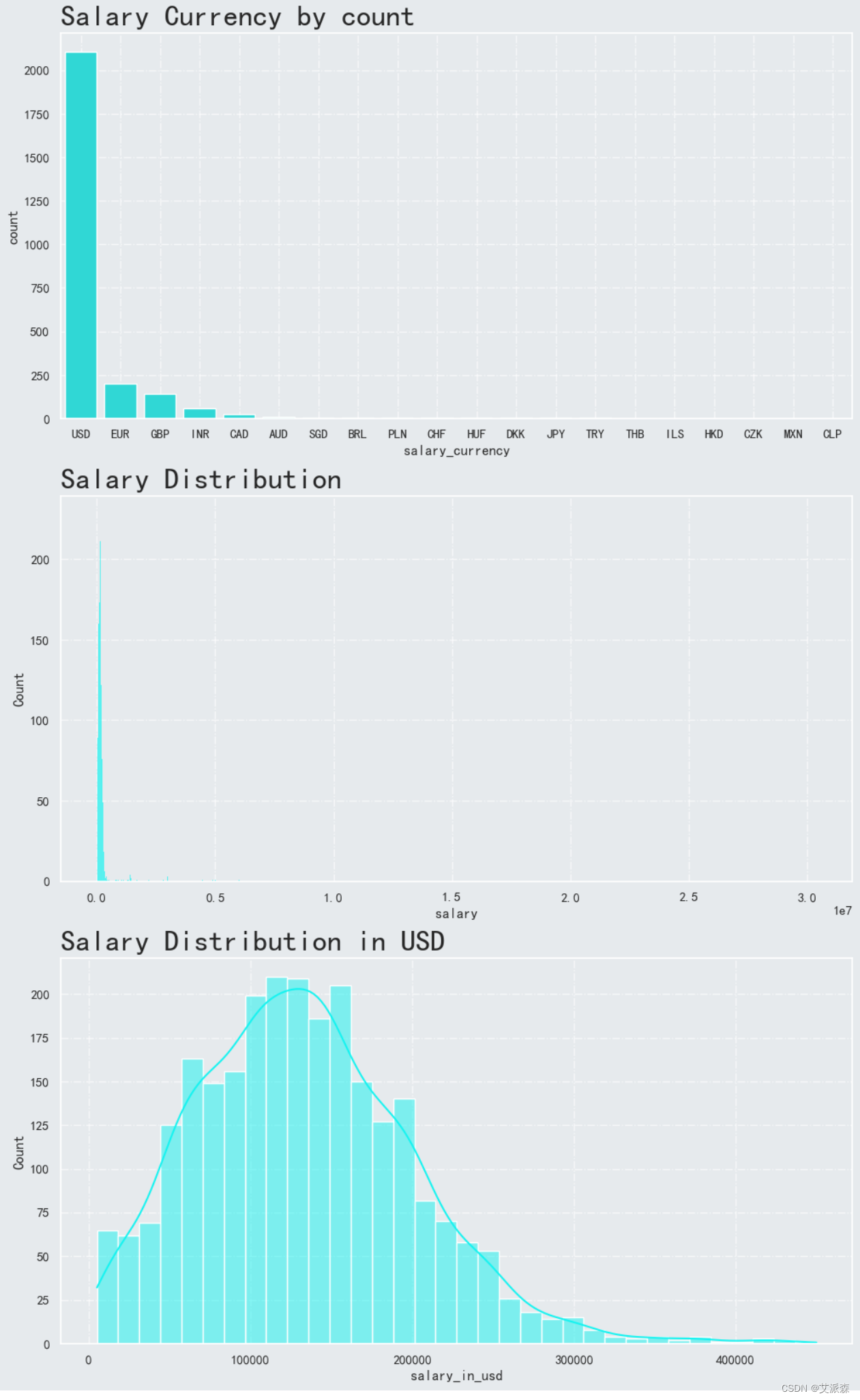
从结果中我们发现,Salary Currency和Salary Distribution这两列数值分布及其不均衡,故我们最后建模的时候应该使用salary_in_usd这一列变量作为目标变量。
4.4特征工程
首先备份一下前面的数据,并统计job_title这一列值情况
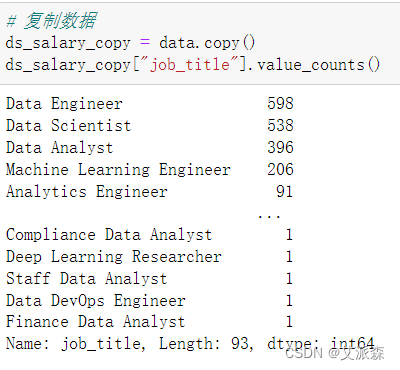
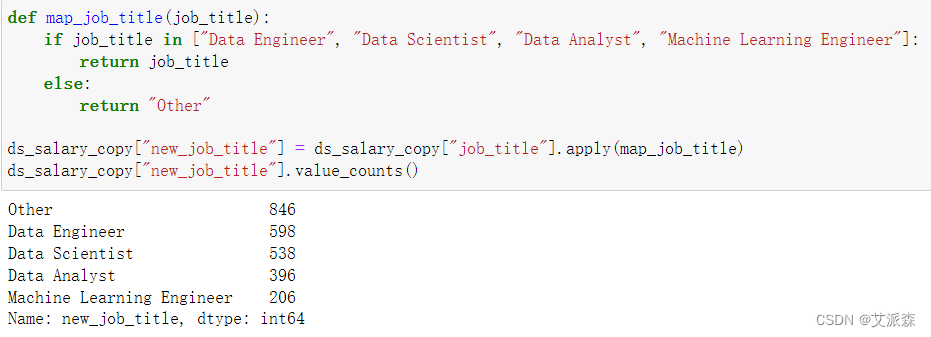
我们发现值基本上都是前四种,所以我们将除了前四的均标记为other
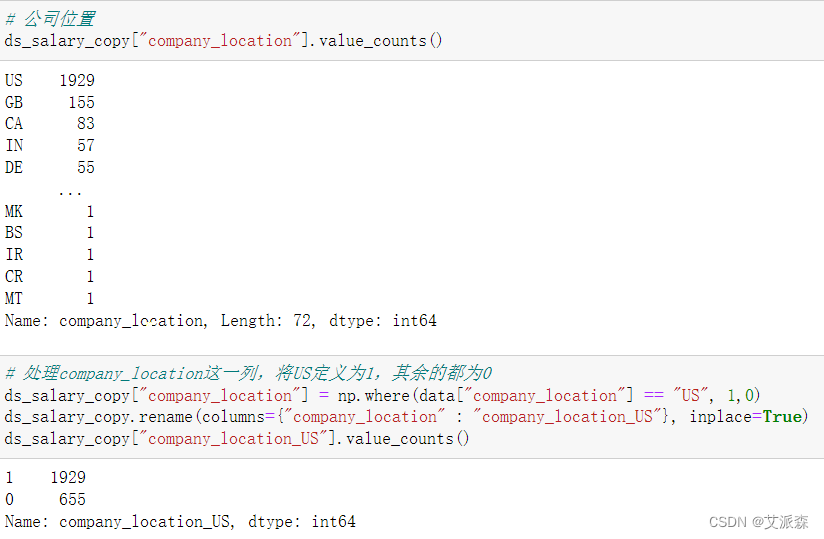
我们发现公司位置这一变量的值分布也不均衡,所以我们将除了US以外的都标记为0,US标记为1。
同理employee_residence也需要上面的处理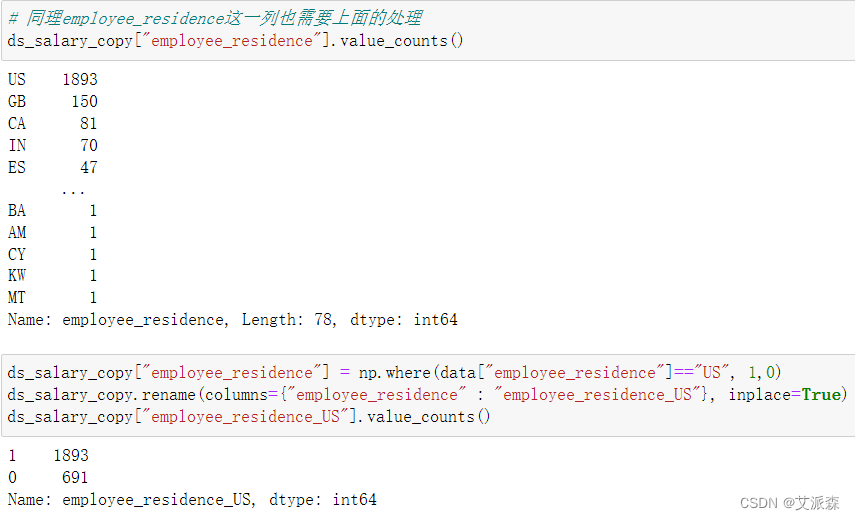
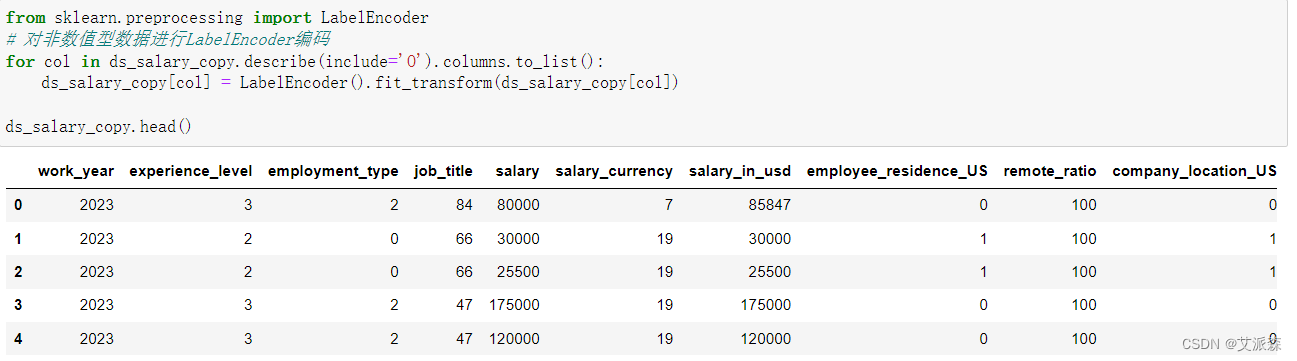
然后我们需要对非数值型变量进行编码转化,这里使用LabelEncoder方法。
最后我们需要选取特征变量和目标变量,并拆分原始数据集为训练集和测试集。
4.5模型构建
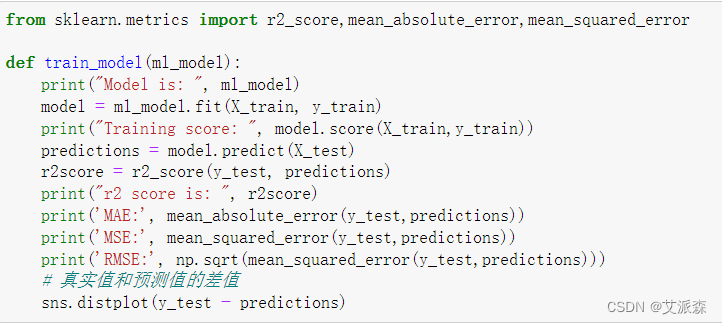
在构建模型之前,我们先定义一个评估模型指标的函数,便于直接调用
构建多元线性回归模型
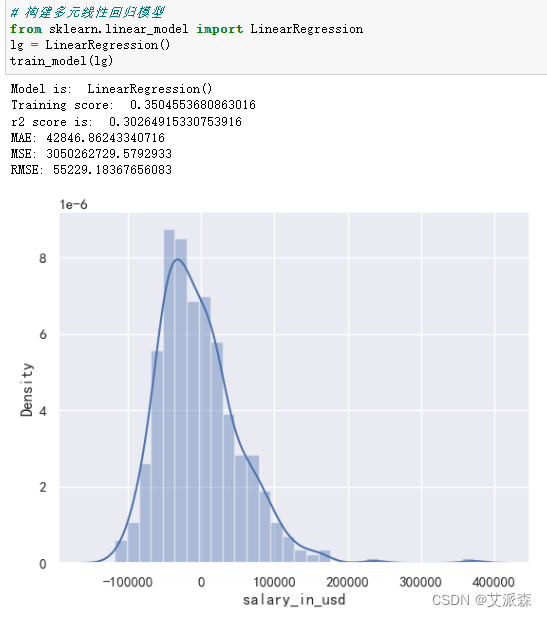
构建决策树模型
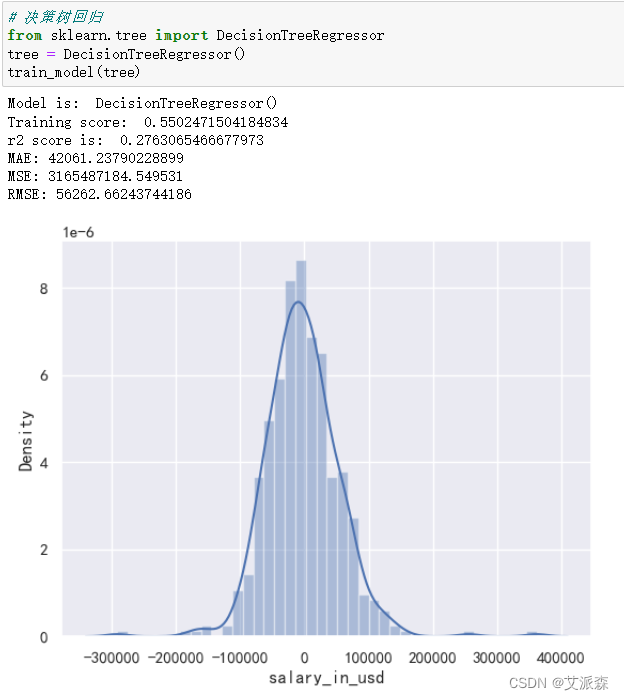
构建GBDT梯度提升决策树模型
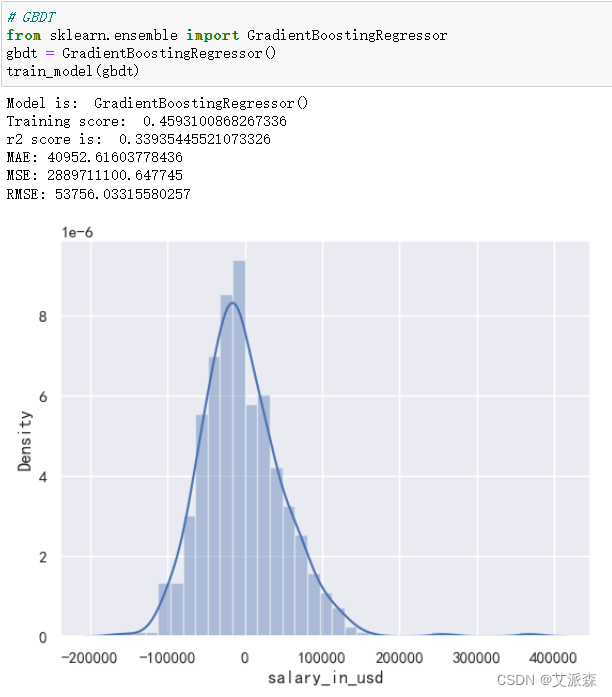
通过三个模型的对比,我们最后选择使用GBDT梯度提升决策树模型。
4.6重要特征排序
这里我们使用前面构建的GBDT模型打印出各特征重要性系数并可视化展现出来。
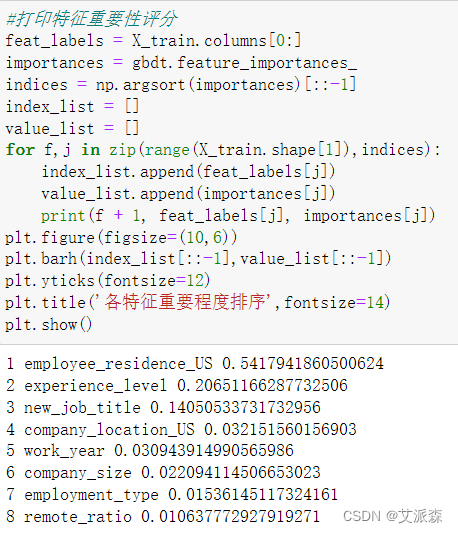
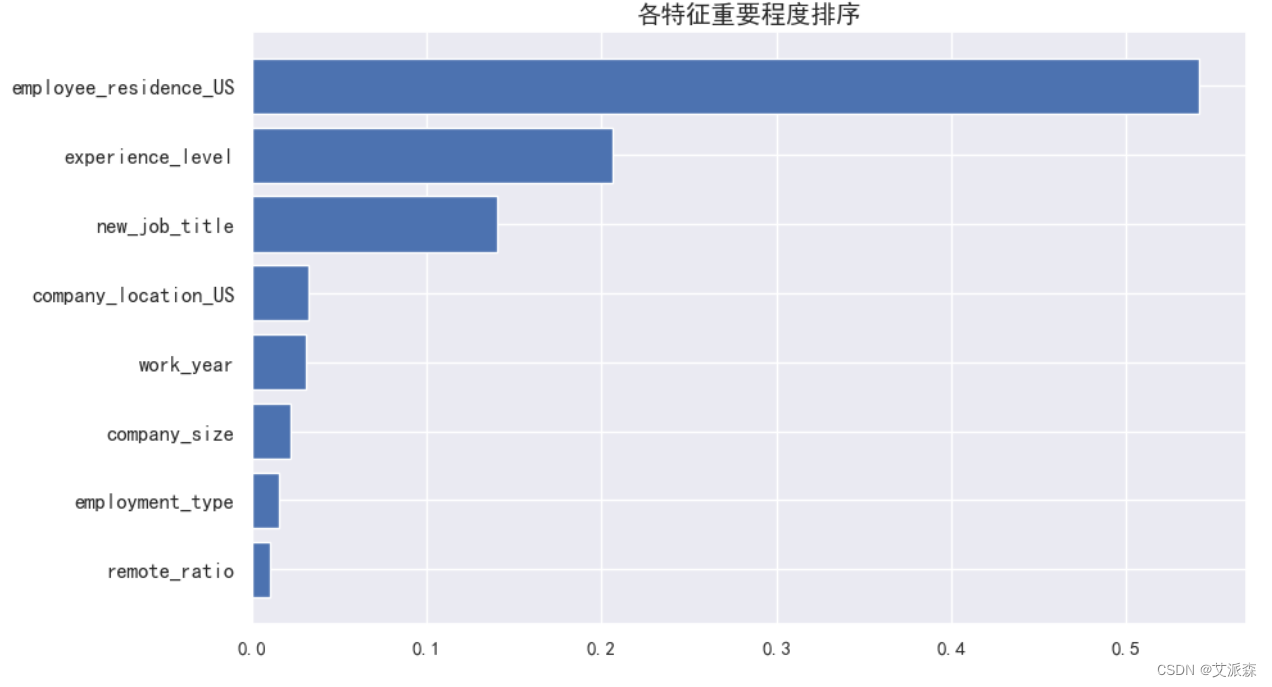 从结果可以发现,员工的工作居住地对薪资的影响程度最大,其次是经验水平和岗位类型。
从结果可以发现,员工的工作居住地对薪资的影响程度最大,其次是经验水平和岗位类型。
4.7模型预测
这里我们使用前两百个预测值和真实值进行对比并可视化展示
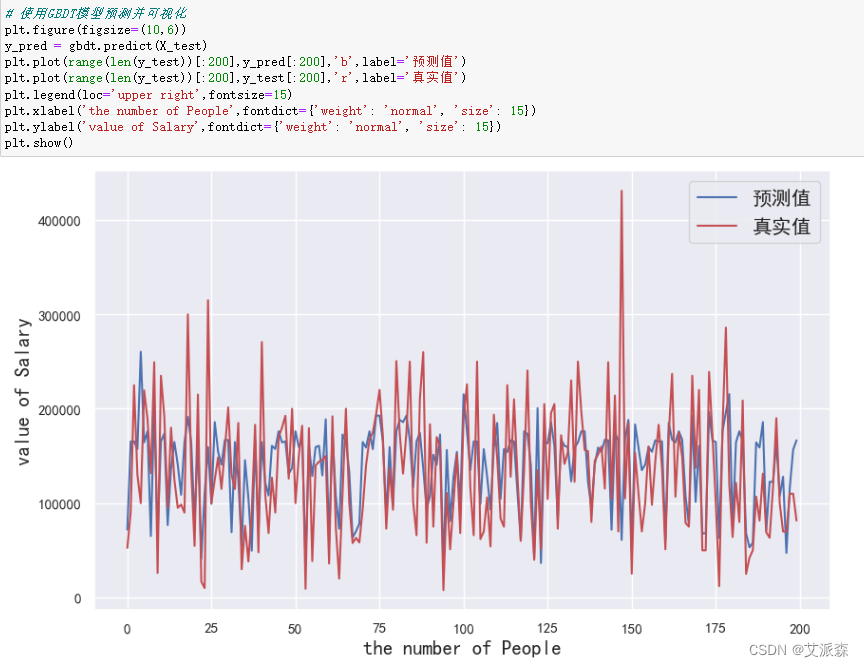
可以发现模型拟合的效果一般,还有待提高。
5.实验总结
本次实验我们通过分析数据科学相关岗位的薪资情况,发现了很多规律,建立了GBDT提升决策树模型来预测薪资,也找出了影响薪资的最大因素,唯一不足的就是最后模型的拟合效果不太好,这可能与原始数据集质量有关,也可能是我们预处理的时候没到位导致的。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
data = pd.read_csv('ds_salaries.csv')
data.head()
data.shapea
data.info()
data.describe()
data.describe(include='O')
data.isnull().sum()
any(data.duplicated())
data.drop_duplicates(inplace=True)
data.shape
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font="SimHei")
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
# Work Year
sns.countplot(x=data.work_year, color="#14F3F0")
plt.title("Work Year", loc="left", size=25)
plt.show()
# Experience Level
sns.countplot(x=data.experience_level, color="#14F3F0")
plt.grid(axis="y", linestyle="-.", alpha=0.7)
plt.title("Experience Level", loc="left", size=25)
plt.show()
# Employment type
sns.countplot(x=data.employment_type, color="#14F3F0")
plt.grid(axis="y", linestyle="-.", alpha=0.7)
plt.title("Employment Type", size=25, weight="bold", loc="left")
plt.show()
# Jobtitle
top10_jobs = data.job_title.value_counts().iloc[:10]
sns.barplot(x=top10_jobs.values, y=top10_jobs.index, color="#14F3F0", orient="h")
plt.grid(axis="x", linestyle="-.", alpha=0.7)
plt.title("10 Most common Jobtitle", size=25, weight="bold", loc="left")
plt.show()
# 绘制job_title词云图
Jobtitels = data.groupby("job_title").size().reset_index(name="count").sort_values(by="count", ascending=False)
Jobtitels = pd.DataFrame(Jobtitels)
from wordcloud import WordCloud, STOPWORDS
font_path = r"C:UsersOlegi MegiDesktopDataanalyticsFontsarial.ttf"
stopwords = set(STOPWORDS)
background = "#E6EAED"
def show_wordcloud(data, title = None):
wordcloud = WordCloud(
background_color=background,
stopwords=stopwords,
max_words=300,
max_font_size=40,
scale=3,
random_state=1,
font_path=font_path
).generate_from_frequencies(data.set_index('job_title')['count'].to_dict())
fig, ax = plt.subplots(1,1, figsize=(14, 14))
ax.set_facecolor(background)
plt.axis('off')
if title:
fig.suptitle(title, fontsize=20)
fig.subplots_adjust(top=2.3)
plt.imshow(wordcloud)
plt.show()
show_wordcloud(Jobtitels)
# Salary
fig = plt.figure(figsize=(12, 20), facecolor=background)
gs = fig.add_gridspec(3,1)
ax0 = fig.add_subplot(gs[0,0])
ax1 = fig.add_subplot(gs[1,0])
ax2 = fig.add_subplot(gs[2,0])
for ax in fig.axes:
ax.set_facecolor(background)
sns.countplot(x=data["salary_currency"], order=data["salary_currency"].value_counts().index,
color="#14F3F0", ax=ax0)
sns.histplot(x=data["salary"], color="#14F3F0", ax=ax1)
sns.histplot(x=data["salary_in_usd"], kde=True, color="#14F3F0", ax=ax2)
ax0.set_title("Salary Currency by count", size=25, weight="bold", loc="left")
ax1.set_title("Salary Distribution", size=25, weight="bold", loc="left")
ax2.set_title("Salary Distribution in USD", size=25, weight="bold", loc="left")
for ax in fig.axes:
ax.grid(True, linestyle="-.", alpha=0.7)
plt.show()
特征工程
# 复制数据
ds_salary_copy = data.copy()
ds_salary_copy["job_title"].value_counts()
def map_job_title(job_title):
if job_title in ["Data Engineer", "Data Scientist", "Data Analyst", "Machine Learning Engineer"]:
return job_title
else:
return "Other"
ds_salary_copy["new_job_title"] = ds_salary_copy["job_title"].apply(map_job_title)
ds_salary_copy["new_job_title"].value_counts()
# 公司位置
ds_salary_copy["company_location"].value_counts()
# 处理company_location这一列,将US定义为1,其余的都为0
ds_salary_copy["company_location"] = np.where(data["company_location"] == "US", 1,0)
ds_salary_copy.rename(columns={"company_location" : "company_location_US"}, inplace=True)
ds_salary_copy["company_location_US"].value_counts()
# 同理employee_residence这一列也需要上面的处理
ds_salary_copy["employee_residence"].value_counts()
ds_salary_copy["employee_residence"] = np.where(data["employee_residence"]=="US", 1,0)
ds_salary_copy.rename(columns={"employee_residence" : "employee_residence_US"}, inplace=True)
ds_salary_copy["employee_residence_US"].value_counts()
from sklearn.preprocessing import LabelEncoder
# 对非数值型数据进行LabelEncoder编码
for col in ds_salary_copy.describe(include='O').columns.to_list():
ds_salary_copy[col] = LabelEncoder().fit_transform(ds_salary_copy[col])
ds_salary_copy.head()
# 选取特征变量
features = ["work_year", "experience_level", "employment_type", "employee_residence_US", "remote_ratio",
"company_location_US", "company_size", "new_job_title"]
X = ds_salary_copy[features]
# 选取目标变量
y = ds_salary_copy.salary_in_usd
# 对数据集进行拆分
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
print('训练集大小',X_train.shape[0])
print('测试集大小',X_test.shape[0])
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
def train_model(ml_model):
print("Model is: ", ml_model)
model = ml_model.fit(X_train, y_train)
print("Training score: ", model.score(X_train,y_train))
predictions = model.predict(X_test)
r2score = r2_score(y_test, predictions)
print("r2 score is: ", r2score)
print('MAE:', mean_absolute_error(y_test,predictions))
print('MSE:', mean_squared_error(y_test,predictions))
print('RMSE:', np.sqrt(mean_squared_error(y_test,predictions)))
# 真实值和预测值的差值
sns.distplot(y_test - predictions)
# 构建多元线性回归模型
from sklearn.linear_model import LinearRegression
lg = LinearRegression()
train_model(lg)
# 决策树回归
from sklearn.tree import DecisionTreeRegressor
tree = DecisionTreeRegressor()
train_model(tree)
# GBDT
from sklearn.ensemble import GradientBoostingRegressor
gbdt = GradientBoostingRegressor()
train_model(gbdt)
#打印特征重要性评分
feat_labels = X_train.columns[0:]
importances = gbdt.feature_importances_
indices = np.argsort(importances)[::-1]
index_list = []
value_list = []
for f,j in zip(range(X_train.shape[1]),indices):
index_list.append(feat_labels[j])
value_list.append(importances[j])
print(f + 1, feat_labels[j], importances[j])
plt.figure(figsize=(10,6))
plt.barh(index_list[::-1],value_list[::-1])
plt.yticks(fontsize=12)
plt.title('各特征重要程度排序',fontsize=14)
plt.show()
# 使用GBDT模型预测并可视化
plt.figure(figsize=(10,6))
y_pred = gbdt.predict(X_test)
plt.plot(range(len(y_test))[:200],y_pred[:200],'b',label='预测值')
plt.plot(range(len(y_test))[:200],y_test[:200],'r',label='真实值')
plt.legend(loc='upper right',fontsize=15)
plt.xlabel('the number of People',fontdict={'weight': 'normal', 'size': 15})
plt.ylabel('value of Salary',fontdict={'weight': 'normal', 'size': 15})
plt.show()






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结