您现在的位置是:首页 >学无止境 >【STL】vector的模拟实现网站首页学无止境
【STL】vector的模拟实现
目录
前言
从vector开始就要开始使用类模板进行泛型编程,使该容器能够存储各种的类型。
由于都是开辟连续空间的容器,因此实际上实现的操作与string相似。主要的难点还是在于结合模板进行使用和迭代器失效的问题。
若你对vector还不了解,不妨看看上一篇文章【STL】vector的使用,再来学习模拟实现。
结构解析
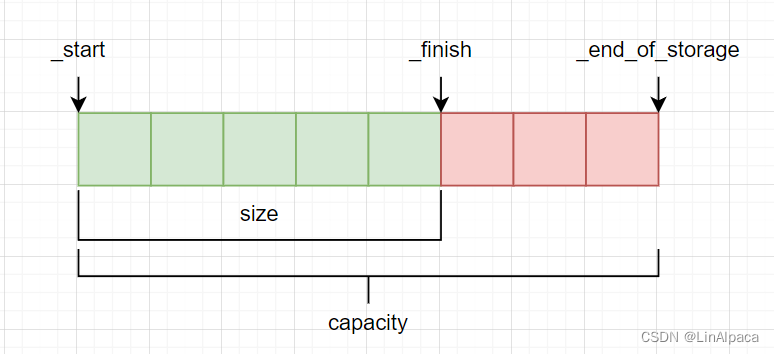
vector 使用的数据结构为线性连续空间,为了方便管理我们使用一个迭代器 _start 指向当前空间的起始地址,再使用两个迭代器 _finish 和 _end_of_storage 分别指向当前该空间已被使用的下一位和整块空间的尾端。
即当 _finish 等于 _end_of_storage 时则表示当前空间已满,若要再次插入则需要进行扩容。
namespace Alpaca
{
template <class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
private:
iterator _start = nullptr; //起始位置
iterator _finish = nullptr; //数据结束位置
iterator _end_of_storage = nullptr; //内存空间结束位置
};
}
构造析构
构造
vector 的构造函数我们可以分成三种。
- 默认构造
- 初始化成n个val
- 据迭代器区间构造
默认构造
由于在定义成员变量的时候,就给三个变量定好了缺省值,因此默认构造可以啥都不写。(doge
vector()
{}初始化成 n 个 val
若以 n 个值进行初始化,就需要为 vector 申请内存空间了,之后再将值添加进 vector 即可。
我们需要知道,vector 中存储的不止有 int 类型还可以存 string、double 甚至 vector,因此我们便不知道该使用什么值给 val 做缺省。因此,我们不妨使用一个匿名对象去调用传入类型的默认构造函数而构建一个形参,从而达到缺省的效果。而其中扩容和尾插的函数会在下文进行讲解。
vector(size_t n, const T& val = T())
{
reserve(n);
for (size_t i = 0; i < n; i++)
{
push_back(val);
}
}但是,之前不是说匿名对象的生命周期只在生命的这一行吗?明明类型是引用而它却仍能在下方的函数使用。
这是因为当我们使用一个 const 引用类型接收匿名对象,就会延长其生命周期与 const 引用相同。我们可以使用下面这份代码验证一下。
class A
{
public:
A()
{
cout << "A()" << endl; //输出A()表示调用构造
}
~A()
{
cout << "~A()" << endl; //输出~A()表示调用析构
}
};
int main()
{
A();
const A& a3 = A();
} 
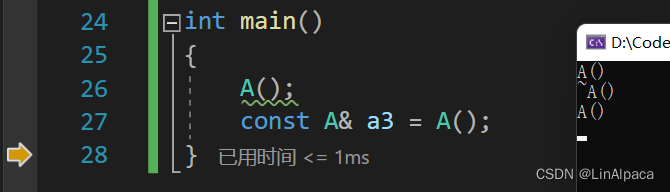
可以清楚的看到,第一个匿名对象当该行结束时就自动调用析构函数,而第二个匿名对象则是到 main 函数结束后才调用析构函数。
以迭代器区间构造
通过传入一个迭代器区间,以区间中的内容对 vector 进行初始化,值得注意的是这里不能直接使用 vector 的 iterator,而是要再使用一个模板,使这个函数变成函数模板。如此便可以使得任意的迭代器区间都能够使用这个函数进行初始化。
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{
reserve(last - first); //申请空间
while (first != last)
{
push_back(*first);
++first;
}
}当这个函数写好的时候,我们就会发现若我们使用上面那个构造函数进行初始化的时候,便会出现错误。
![]()
这是因为,上面我们写的函数中 n 的类型是 size_t,而平时我们都是直接传整型过去的,其中发生了类型转换。虽然我们新写的这个函数虽然并非是为其而写,但现实却是调用这个函数的时候并不会发生类型转换。
因此实际就调用了这个消耗少的函数,从而发生了对 int 类型的解引用,才报错非法的间接寻址。
解决方式也很简单,再重载一个 n 是 int 类型的函数就行了。
vector(int n, const T& val = T())
{
reserve(n);
for (int i = 0; i < n; i++)
{
push_back(val);
}
}拷贝构造
传入一个vector作为参数便是该类的拷贝构造,只需提前申请空间,之后再进行拷贝即可。
vector(const vector<T>& v)
{
_start = new T[v.capacity()]; //申请空间
for (size_t i = 0; i < v.size(); i++) //拷贝
{
_start[i] = v._start[i];
}
_finish = _start + v.size(); //更新边界值
_end_of_storage = _start + v.capacity();
}但这里千万不能使用 memcpy 进行拷贝,内置类型倒还好,一旦是自定义类型作为模板参数,就会引发两次析构的情况,从而导致程序崩溃。 所以,在构造的时候需要通过赋值的方法进行深拷贝。
析构
析构函数就是起一个善后的作用,首先先将原来申请的空间释放,再将成员变量全部置空即可。
~vector()
{
delete[] _start;
_start = _finish = _end_of_storage = nullptr;
}运算符重载
赋值重载
与上面的拷贝构造类似,但此时的 vector 已经开辟好了,因此当前空间是否足够要经过判断。
接着拷贝数据,再更新边界值便完成拷贝。
vector& operator =(const vector<T>& v)
{
if (capacity() < v.capacity()) //判断是否需要扩容
{
reserve(v.capacity());
}
for (int i = 0; i < v.size(); i++) //拷贝数据
{
_start[i] = v._start[i];
}
_finish = _start + v.size(); //更新边界值
_end_of_storage = _start + v.capacity();
return *this;
}下标访问
为了支持 const 的情况,让下标访问只读而无法写入,因此需要写两份 [ ] 运算符重载。
对边界进行判断后,再返回解引用的内容。不同类型的 vector 便会调用不同的函数。
T& operator [](size_t pos)
{
assert(pos>=0 && pos < size());
return _start[pos];
}
const T& operator[](size_t pos) const
{
assert(pos>=0 && pos < size());
return _start[pos];
}迭代器
vector 维护的是一个连续线性空间,因此不论其中存储的元素为什么类型,使用原生指针都可以满足作为 vector 迭代器的条件。
例如 ++、--、* 等操作,指针天生便具备。所以我们使用原生指针作为 vector 的迭代器。
typedef T* iterator;
typedef const T* const_iterator;
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}对于边界值的选择也一直都是左开右闭,实际上 begin 和 end 就是 _start 和 _finish 指向的位置,直接将迭代器返回即可。
const迭代器
可以看到,我们不仅定义了普通迭代器,还定义了一个 const 迭代器,为了维持它的特性,我们需要再实现一个被 const 修饰的 begin 和 end 函数返回 const 迭代器给用户。
const_iterator begin() const
{
return _start;
}
const_iterator end() const
{
return _finish;
}有了迭代器区间后,我们便可以自由地使用范围 for 了。

容量操作
内存的管理,对于一个容器来说是至关重要的,因此需要注意实现的细节。
查看大小和容量
由于 _finish 和 _end_of_storage 都是指向结束位置的下一位,因此与 _start 框定了左闭右开的范围,因此使用 _finish 减去 _start 就是该范围的长度大小。
size_t size() const
{
return _finish - _start;
}
size_t capacity() const
{
return _end_of_storage - _start;
}容量修改
在前面,每次扩容我们都调用 reserve 这个接口,正是因为这个函数只扩大容量而不增加元素个数。
在实现的时候我们需要注意:
- 传入值只有大于容量才处理
- 异地开辟避免数据丢失
- 拷贝时使用深拷贝
void reserve(size_t n)
{
if (n >= capacity())
{
iterator tmp = new T[n]; //异地开辟避免申请失败导致数据丢失
int len = size();
if (_start)
{
for (int i = 0; i < len; i++) //进行深拷贝
{
tmp[i] = _start[i];
}
delete[] _start;
}
_start = tmp; //更新成员变量
_finish = tmp + len;
_end_of_storage = tmp + n;
}
}之后我们再来看 resize 这个接口,根据传入值的不同便有三种情况
- n 小于元素个数
- n 大于元素个数小于当前容量
- n 大于元素个数且大于当前容量
需要根据不同的情况进行不同的操作,第一种情况只需直接修改迭代器指向即可,而二三种则需要判断是否扩容后再将传入值填充到容器之中。因此可以将二三种写在一起,填充的操作是相同的,只需特判是否需要扩容即可。
void resize(int n, T val = T())
{
if (n < size()) //n小于元素个数时,减少元素个数至n
{
_finish = _start + n;
}
else
{
if (n > capacity()) //n大于元素个数且大于当前容量
{
reserve(n); //扩容至n
}
while (_finish != _start + n) //再进行值的拷贝
{
*_finish = val;
++_finish;
}
}
}数据修改
尾插尾删
尾插这个操作我们写过无数遍了,首先判断容量是否足够让我们插入一个数据,足够则继续运行,否则扩容。
_finish 指针指向的就是下一个元素插入的位置,因此直接赋值,最后 _finish 迭代即可。
void push_back(const T& x)
{
if (_finish >= _end_of_storage) //判断容量
{
reserve(capacity() == 0 ? 4 : capacity() * 2);
}
*_finish = x; //赋值
_finish++; //迭代
}
void pop_back()
{
assert(!empty());
--_finish;
}而尾删操作就更加简单了,首先判断 vector 之中是否还有元素,否则无法删除。若能够删除只需 _finish -- 即可。
下次再次插入元素时便会直接覆盖掉该空间的数据。
指定位置插入和删除
insert
insert 有很多种重载,这里就讲讲其中的两个。
插入一个值
虽说是任意位置插入,但是仍要判断选择的位置是否越界,其中 pos 可以等于 _finish ,此时就相当于尾插。
都讲到 insert 了那就不得不讲到迭代器失效的问题了,在上一篇 vector 的使用时,我们就讲过,vector 中涉及扩容操作后,在异地开辟空间,因此此时的迭代器指向的空间已被释放,其中的指针自然也就成了野指针。
为了解决这个问题,我们不妨在扩容之前将 pos 的相对位置记录下来,扩容后再用 _start 加上相对位置再次找到 pos 。
iterator insert(iterator pos, const T& val)
{
assert(pos >= _start); //判断越界
assert(pos <= _finish);
if (size() == capacity()) //判断容量
{
size_t sz = pos - _start; //解决扩容带来的迭代器失效
reserve(capacity() == 0 ? 4 : capacity() * 2);
pos = _start + sz;
}
iterator it = _finish - 1; //移位
while (it >= pos)
{
*(it + 1) = *it;
it--;
}
*pos = val; //赋值
_finish++; //迭代
return pos; //返回插入位置的迭代器
}之后再像原来那样,先移位再在插入点进行赋值,最后进行迭代即可,不要忘记返回插入点的迭代器,否则外部使用的迭代器就失效了。
插入一个迭代器区间
像前面讲的以迭代器区间为参数的构造函数,在这里我们也要写成一个模板函数,因为你无法判断传入的是什么迭代器。
之后我们可以复用上面写过的 insert 将区间内的数据一个一个插入到原数组之中。
template <class InputIterator>
void insert(iterator pos, InputIterator first, InputIterator last)
{
for (; first != last; ++first)
{
pos = insert(pos, *first);
++pos;
}
}这里提一嘴,由于使用 insert 的同时,往往伴随着数据的挪动,不建议经常使用。
erase
这里我实现了两种 erase,一种是删除单个位置,另一种是删除一段区间。
第一种首先判断边界再挪动数据、限定边界即可。由于挪动后下一位的位置恰好就在 pos 的位置,因此最后直接返回 pos。
iterator erase(iterator pos)
{
assert(pos >= _start); //判断边界
assert(pos < _finish);
iterator it = pos + 1; //挪动数据
while (it != _finish)
{
*(it - 1) = *it;
it++;
}
_finish--; //更新边界值
return pos; //返回迭代器
}
iterator erase(iterator first, iterator last)
{
assert(first >= begin()); //判断边界
assert(last <= end());
while (last != _finish) //last!=_finish时则代表后面还有数据,需要往前拷贝
{
*first = *last;
++first;
++last;
}
_finish = first; //此时first所在位置即更新后_finish的位置
return _finish;
}第二种 erase 先判断边界自然是不用说, 若在 last 之后仍存在数据,需要将其向前拷贝。
显然,我们可以用一个循环解决这个问题,当 last 不等于 _finish 的话就说明 last 之后有数据,否则直接跳过即可。由于删除区间也是左闭右开,所以 last 当前位置的元素也要保留。便可从 last 开始将值拷贝到 first 的位置,然后二者都加加。最后 first 到达的位置便是新的 _finish 的位置。

清空 判空
这两个函数一个是 clear 一个是 empty ,清空只需要更改迭代器,使得 _finish 与 _start 相同。
反之判空只要判断 _strat 是否与 _finish 相同即可。
void clear()
{
_finish = _start;
}
bool empty()
{
return _start == _finish;
}交换
与 string 那时一样,交换时不能只是简单的浅拷贝,也不能冗余地进行构造再赋值,只需交换成员变量即可。
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_end_of_storage, v._end_of_storage);
}之后便可以借助这个 swap 函数简化我们的赋值重载。
vector& operator =(vector<T> v)
{
swap(v);
return *this;
}本质上就是传参的时候,由于不是传引用传参,因此会调用拷贝构造构建形参,我们便可以将这个形参的指针与当前 vector 的指针交换。函数结束后,形参销毁便自动回收原来的空间。
源码
还想看看源码的可以来这里
好了,今天 vector 的模拟实现到这里就结束了,如果这篇文章对你有用的话还请留下你的三连加关注。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结