您现在的位置是:首页 >技术交流 >代码随想录训练营Day6哈希表part01,哈希表理论基础 ● 242.有效的字母异位词 ● 349. 两个数组的交集 ● 202. 快乐数● 1. 两数之和网站首页技术交流
代码随想录训练营Day6哈希表part01,哈希表理论基础 ● 242.有效的字母异位词 ● 349. 两个数组的交集 ● 202. 快乐数● 1. 两数之和
哈希表理论基础
哈希表有三种数据结构,分别是数据、set、map,不同的数据结构都有着不同的功能,详情请参考代码随想录
242.有效的字母异位词
题目链接:力扣题目链接
文章链接:代码随想录 (programmercarl.com)
视频链接:学透哈希表,数组使用有技巧!Leetcode:242.有效的字母异位词
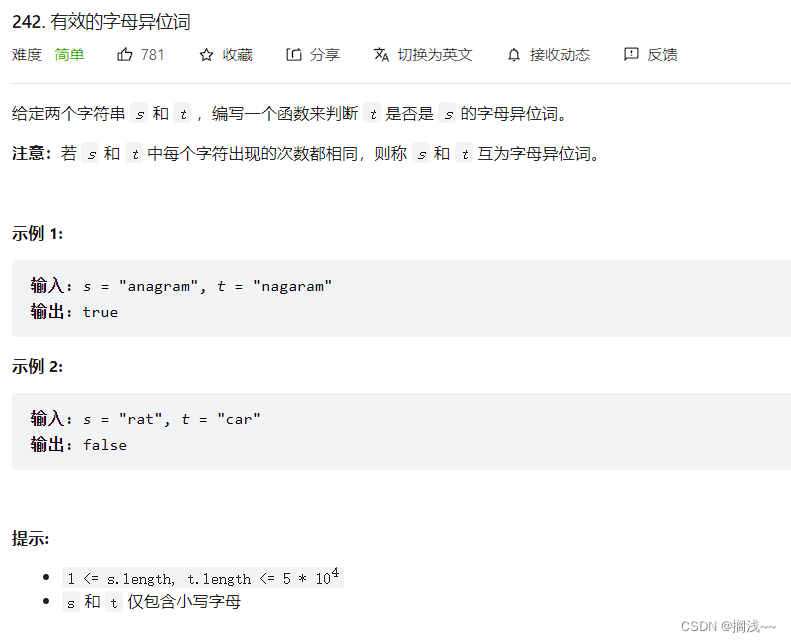
此题是一道很经典的用数组哈希结构的题型,由于26个字母的ASCII码值连续,所以用数组显得十分方便。
字母异位词,意思就是字母个数相同但位置不同的字符串(然而在leetcode上,即使是完全相同的两个字符串也能互为字母异位词,很奇怪)。
用数组考虑,我们可以首先定义一个26大小的数组hass,且初始化所有元素为0,然后遍历第一个字符串,出现的字母就让hass数组对应元素加一,再遍历第二个字符串,出现的字母就让hass数组对应元素减一,最后如果hass存在不为0的元素,则不为字母异位词,return false,反之则return ture。
代码如下:
class Solution {
public:
bool isAnagram(string s, string t) {
int hass[26]={0};
for(int i=0;i<s.size();i++)
{
hass[s[i]-'a']++;
}
for(int i=0;i<t.size();i++)
{
hass[t[i]-'a']--;
}
for(int i=0;i<26;i++)
{
if(hass[i]!=0)
{
return false;
}
}
return true;
}
};349. 两个数组的交集
题目链接:力扣题目链接
文章链接:代码随想录 (programmercarl.com)
视频链接:学透哈希表,set使用有技巧!Leetcode:349. 两个数组的交集

由于这道题对于nums1、nums2 的长度有了限制,所以我的第一想法依旧是适用数组解决,首先定义一个hass[1001]的数组,接着通过循环将hass[nums1[i]]=1,只要再遍历一遍nums2,如果hass[nums2[i]]==1,那么就说明两个数组都有,将结果存入新建立的数组result中。
正准备写时,突然发现一个巨大的漏洞,这个方法将元素作为下标,而此题并没有将元素限制为非整数,如果存在负数,或者非整数,都不能在下标中表达,这个思路就此作罢。
看完讲解,了解到哈希结构的另一种结构,set结构,set分为三种,set、multiset、unordered_set,具体区别如图:
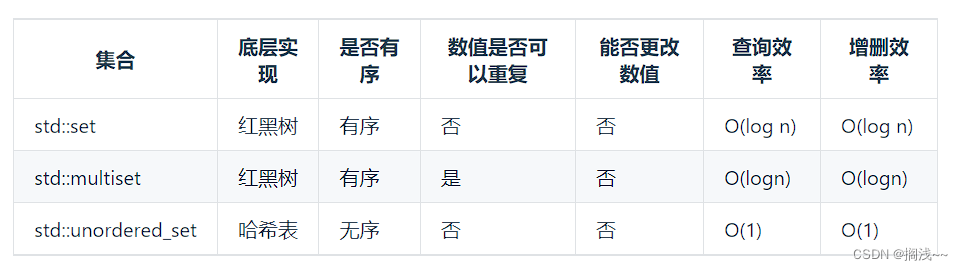
这道题只需要求交集,交集中不存在重复的元素,同时不需要有序排列,可以使用unordered_set。代码如下:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result;//unordered_set可以自动去重
unordered_set<int> nums_set(nums1.begin(),nums1.end());//讲nums1中的元素存入nums_set中
for(int num:nums2)//一种新的遍历方式,马上讲解
{
if(nums_set.find(num)!=nums_set.end())set。find()的用法
{
result.insert(num);//set.insert()的用法
}
}
return vector<int>(result.begin(),result.end());
}
};for(int num:nums2)是 C++11引入的范围-based for 循环语句,也称为foreach 循环。
这段代码的意思是对一个容器(如数组、向量、列表等)进行遍历,其中nums2是一个容器,num 是循环迭代的变量名,表示容器中的每个元素的值。在循环的每次迭代中,num 会被赋值为容器中的下一个元素,直到遍历完所有元素。
nums_set.find(xx),就是在nums_set里面寻找xx,如果找到元素,则返回指向该元素的迭代器,否则返回指向集合末尾的迭代器。所以只要nums_set.find(num)!=nums_set.end(),就意味着找到了。
result.insert(xx),就是在result里插入一个元素xx.
之所以先讲result定义为一个unordered_set类型的,最后返回时再转化为vector类型的,看似多此一举,实际上是运用了unordered_set去重的功能。

这道题也是一个运用set的经典题,题目中说了要么这个数变为1,要么无限循环,而无限循环代表从某个sum开始,sum会重复出现。
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
代码如下:
class Solution {
public:
int getsum(int n)//构建一个求位数平方和的函数
{
int sum=0;
while(n!=0)
{
sum+=(n%10)*(n%10);
n=n/10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> set;
while(1)
{
int s=getsum(n);
if(s==1)
{
return true;
}
if(set.find(s)!=set.end())//说明set里找到了s
{
return false;
}
set.insert(s);
n=s;
}
}
};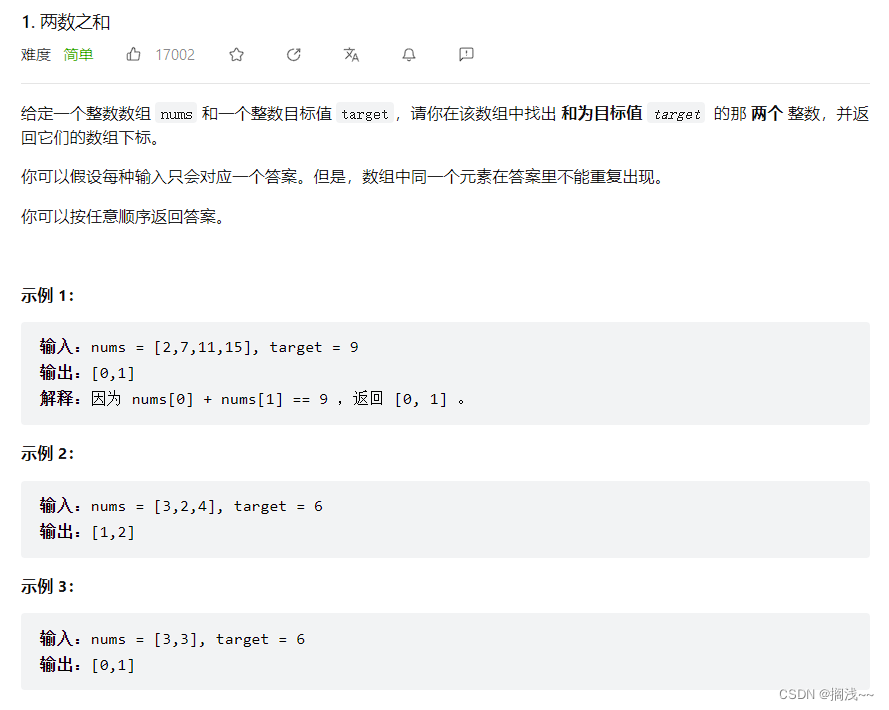
这道题需要运用到哈希结构的第三种结构map,map有三类,分别为map、multimap、unordered_map,具体区别如下:

因为本题,我们不仅要知道元素有没有遍历过,还有知道这个元素对应的下标,需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适。
代码如下:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
map<int,int> a;
vector<int> b(2,-1);
for(int i=0;i<nums.size();i++)
{
if(a.count(target-nums[i])>0)
{
b[0]=a[target-nums[i]];
b[1]=i;
break;
}
a[nums[i]]=i;
}
return b;
}
};Day6 打卡成功,耗时4小时。再接再厉!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结