您现在的位置是:首页 >其他 >数据结构学习分享之堆的详解以及TopK问题网站首页其他
数据结构学习分享之堆的详解以及TopK问题
?博主CSDN主页:杭电码农-NEO?
⏩专栏分类:数据结构学习分享⏪
?代码仓库:NEO的学习日记?
?关注我?带你了解更多数据结构的知识
??

数据结构第七课
1. 前言?
本章就给大家带来久违的堆的知识,如果你还不知道数的相关知识,或者什么是完全二叉树,请跳转树的介绍,本章的堆结构需要树的知识做铺垫.数据结构中的堆结构本质上就是一种完全二叉树,我们上一章说完全二叉树适合用数组的结构来实现.
这一章的关键就是向下调整和向上调整!
2. 堆的概念以及结构?
如果有一个关键码的集合K = { , , ,…, },把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足: <= 且 <= ( >= 且 >= ) i = 0,1,2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
画图理解,一个堆要么是大堆要么是小堆

3. 堆的实现?
这里我给大家带来的是小堆的实现,只要实现了小堆,小堆转换成大堆是很容易的,我们直接开始!
3.1 初始化结构?
我们前面说,堆这种结构用数组的形式来存储是比较好的,所以这里和顺序表有一些相似,也是动态的数组:
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>//实现小堆
typedef int HPDataType;
typedef struct HeapNode
{
HPDataType* a;//定义一个HPDataType类型的数组
int size;//存储元素个数
int capacity;//数组容量
}HN;
3.2 初始化函数?
这里和顺序表一样,这里不做过多解释,不太理解的朋友可以跳转顺序表讲解
void HeapInit(HN* hp)
{
assert(hp);
hp->a = NULL;
hp->size = hp->capacity = 0;
}
3.3 插入函数?
有意思的地方来了,我们说堆实际上是一个完全二叉树,所以我们插入数据以后,它也要是一个完全二叉树,所以这里在逻辑结构上,插入的元素应该插入的位置是在:
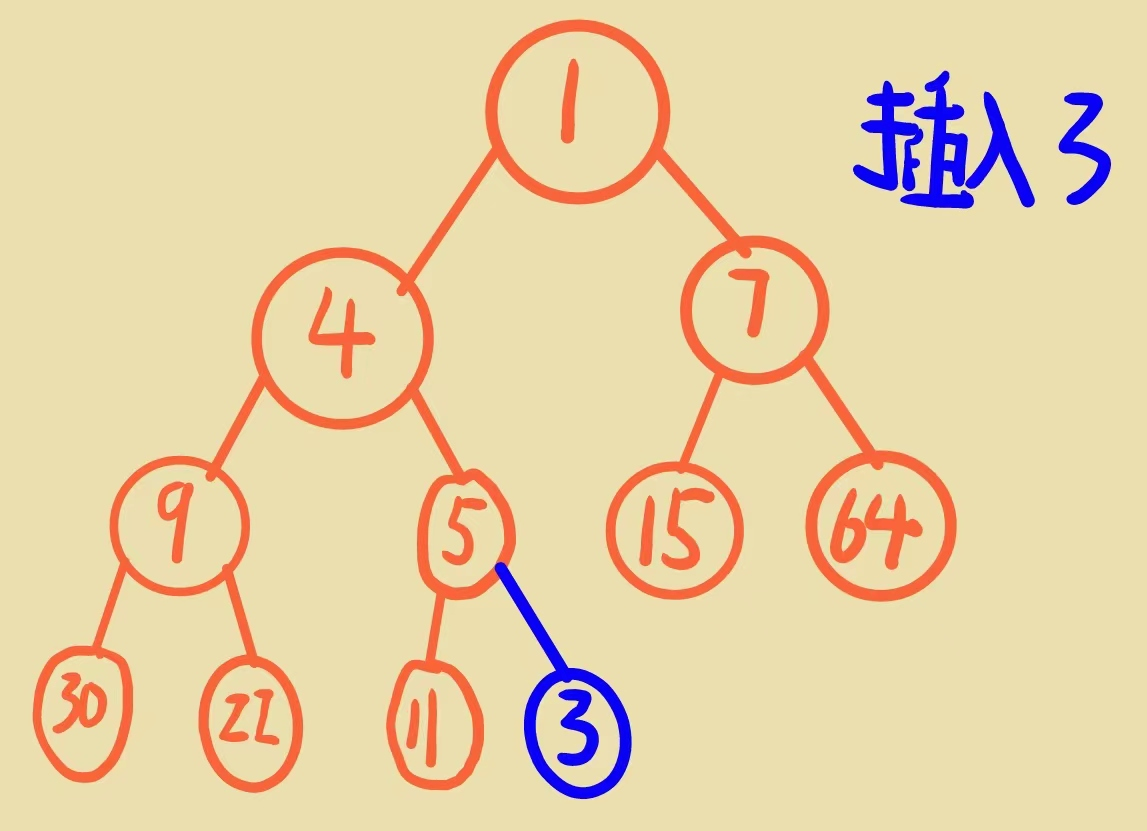
当我们知道了要插入数据实际上就是物理存储的数组中的最后一个位置的下一个位置,我们就可以来实现这段代码了:
void HeapPush(HN* hp, HPDataType x)
{
assert(hp);
if (hp->size == hp->capacity)//判断是否需要扩容,和顺序表一样
{
int newcapacity = hp->capacity == 0 ? 4 : hp->capacity * 2;
HPDataType* newnode = (HPDataType*)realloc(hp->a,sizeof(HPDataType) * newcapacity);
if (newnode == NULL)
{
printf("realloc fail
");
exit(-1);
}
hp->a = newnode;
hp->capacity = newcapacity;
}
hp->a[hp->size] = x;
hp->size++;
}
这段代码和顺序表的尾插没有什么区别,所以我就不再解释这段代码.
但是这段代码并不正确,因为它插入到末尾后有可能不符合我们小堆的概念,所以还需要下一步:向上调整!
3.4 向上调整函数?
我们刚刚写好的尾插函数只是将数据插入进去了,但是要满足我们的小堆结构的话,需要父亲比两个儿子都小,但是我们刚刚插入进入的数据三比5还要小,甚至比4还要小,所以这个地方就需要向上调整我们的数据,这个地方向上调整的路径是这样的:
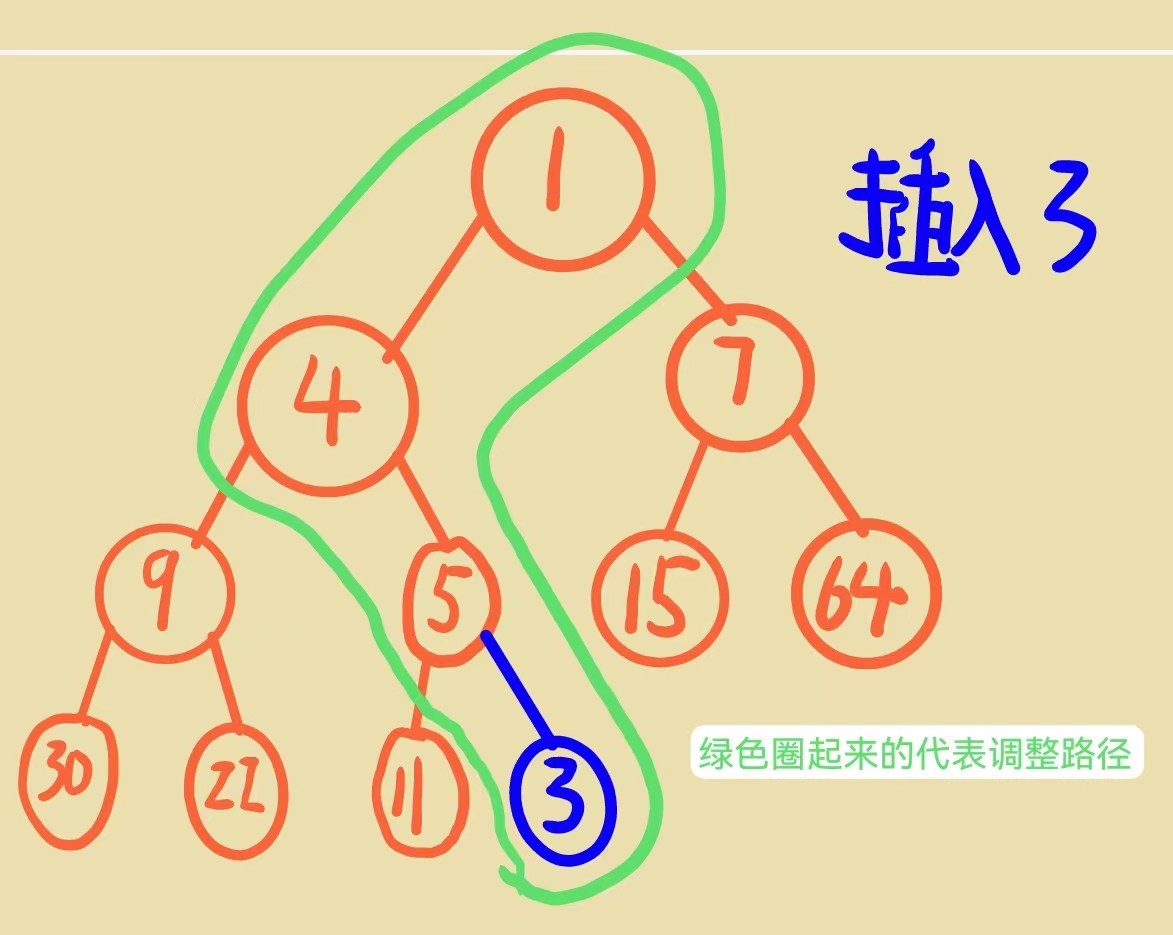
即儿子和父亲比较,如果儿子比父亲小,那么将父亲和儿子的值交换,依次往上走直到父亲比儿子大或者走到根节点的时候停止
并且我们在了解了二叉树的结构时学习到了一个公式,那就是:
- 父亲下标×2+1=左孩子的下标,父亲小标×2+2=右孩子下标
- 不管是左孩子还是右孩子,孩子下标÷2=父亲下标
有了基本思路我们直接上手:
void AdjustUp(int* a, int child)//小堆向上调整判断为a[child]>a[parent]
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])
{
swap(&a[child], &a[parent]);//交换它们两个的值
child = parent;//再将parent的下标给child,依次往后走!
parent = (child - 1) / 2;
}
else//不满足情况就跳出循环
{
break;
}
}
}
所以我们上面的尾插代码插入末尾数据后其实还远远不够,还需要向上调整!,这里我们修改尾插函数为:
void HeapPush(HN* hp, HPDataType x)
{
assert(hp);
if (hp->size == hp->capacity)
{
int newcapacity = hp->capacity == 0 ? 4 : hp->capacity * 2;
HPDataType* newnode = (HPDataType*)realloc(hp->a,sizeof(HPDataType) * newcapacity);
if (newnode == NULL)
{
printf("realloc fail
");
exit(-1);
}
hp->a = newnode;
hp->capacity = newcapacity;
}
hp->a[hp->size] = x;
hp->size++;
AdjustUp(hp->a, hp->size - 1);//把向上调整加上就完美了
}
调整过程为:
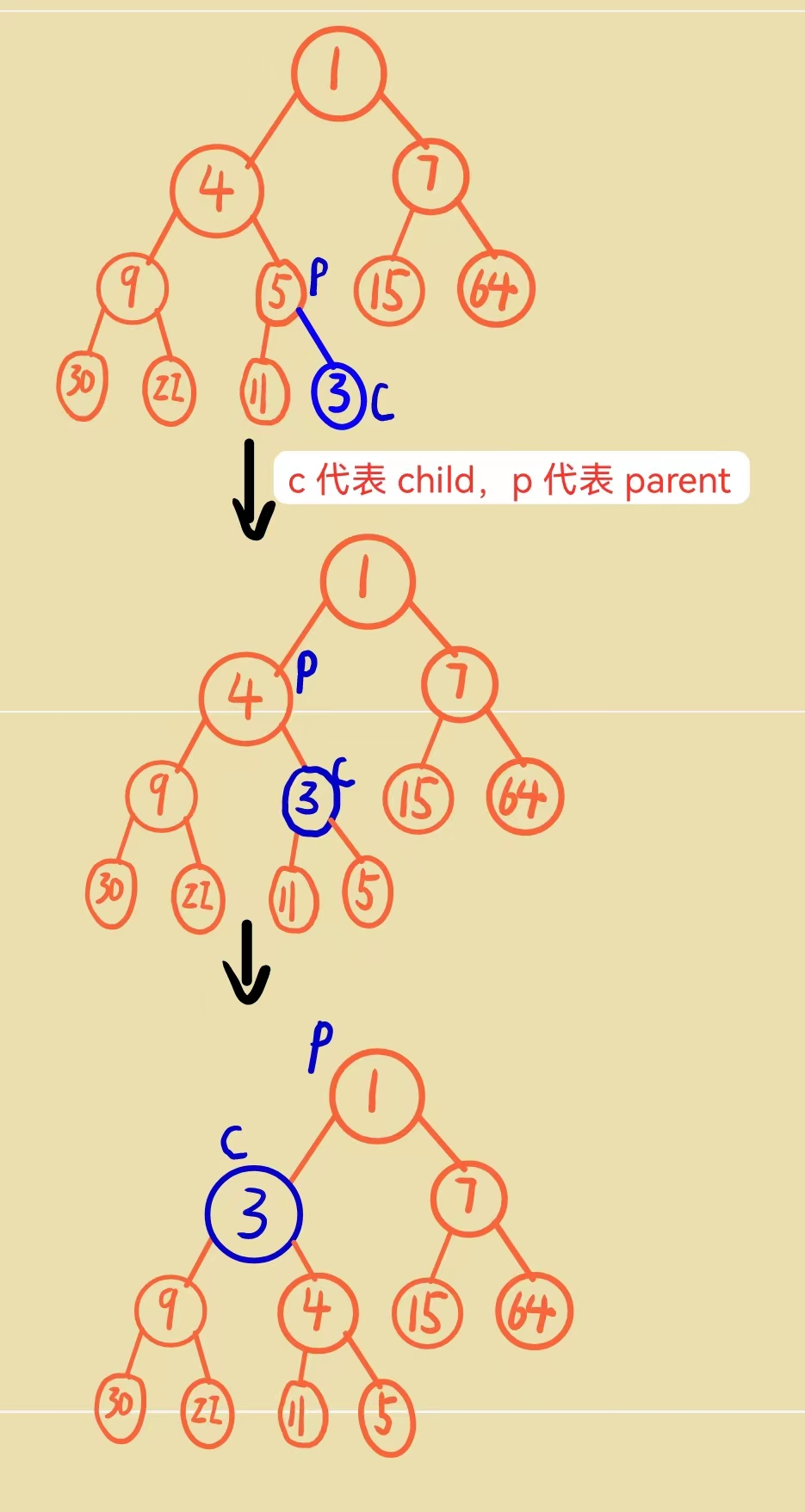 这里我们的插入就完美结束了!
这里我们的插入就完美结束了!
3.5 删除函数?
删除堆是删除堆顶的数据,这里使用的方法是将堆顶的数据根最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法,画图理解:
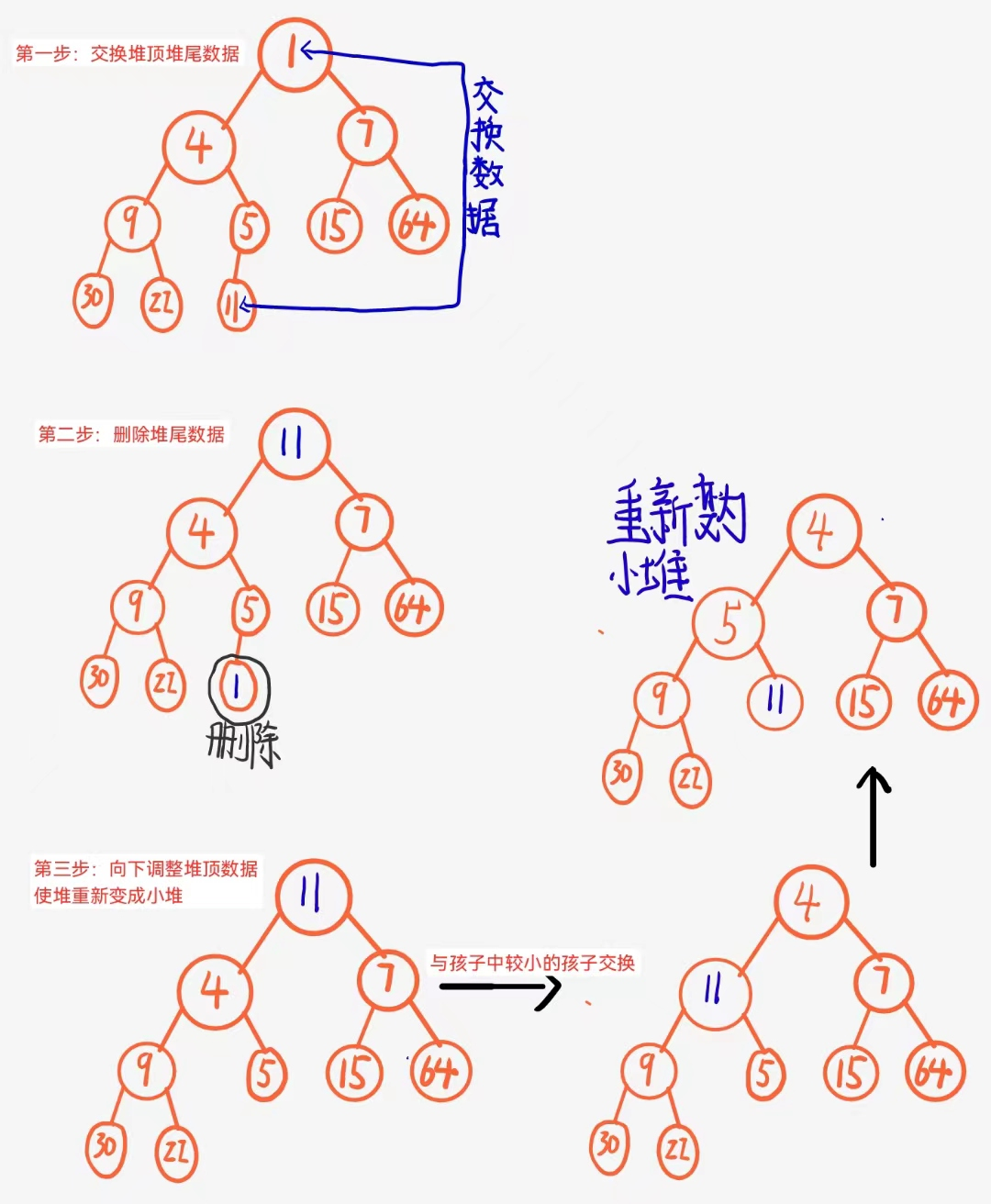
有了这种思路,完美现在来实现代码:
void HeapPop(HN* hp)
{
assert(hp);
assert(hp->a);
swap(&hp->a[hp->size - 1], &hp->a[0]);
hp->size--;
AdjustDown(hp->a, hp->size, 0);//向下调整函数
}
3.6 向下调整函数?
我们根据上面的思路来边写代码边解释:
void AdjustDown(int* a, int n, int parent)//小堆需要找到两个孩子中较小的内个,并且child小于parent就交换.
{
int child = parent * 2 + 1;//先默认为左孩子
while (child < n)
{
if (a[child+1] < a[child] && child + 1 < n)//找到两个孩子中最小的内个
{
child++;//这里我们将child默认为左孩子,但是如果右孩子小于左孩子,我们就将child+1指向右孩子
}
if (a[child] < a[parent])
{
swap(&a[child], &a[parent]);//交换两个值
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
这里设计比较巧妙的点是,我们先默认左孩子是较小的孩子节点,然后再去判断左右孩子哪个小,如果右孩子比左孩子小就将child+1指向右孩子,反之我们就不进入 i f 语句,child就是我们默认的左孩子
3.7 其他函数?
将我们最难理解并且也是最重要的向上调整和向下调整函数讲解了过后,剩下的就是一些歪瓜裂枣了,非常容易实现:
- 取堆顶元素
HPDataType HeapTop(HN* hp)
{
assert(hp);
assert(hp->a);
return hp->a[0];
}
- 堆的销毁
void HeapDestroy(HN* hp)
{
assert(hp);
free(hp->a);
hp->size = hp->capacity = 0;
}
- 判断堆是否为空
bool HeapEmpty(HN* hp)
{
assert(hp);
return hp->size == 0;//为空就返回true
}
4. TopK问题?
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。
4.1 思路分析?
最佳的方式就是用堆来解决,基本思路如下:
1. 用数据集合中前K个元素来建立堆:
- 前k个最大的元素,则建小堆
- 前k个最小的元素,则建大堆
2.用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
3. 将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
这里可能有人有疑问,为什么排前k个最大的数不建立大堆?要建立小堆.这是因为我们希望我们建立的K个元素的堆中就直接存放前K个最大的元素.建立的小堆的堆顶元素是这K个数中最小的元素,当N-K中其他元素大于堆顶元素时,就可以插入到堆中,然而如果我们建立大堆的话,假如100和90和80都是前K个大的数,当90在堆中时,80就不能入堆了,因为90大于80,堆顶元素肯定大于或者等于90.然而当100在堆中时,90肯定也不能入堆了 所以建立大堆是行不通的
画图理解:
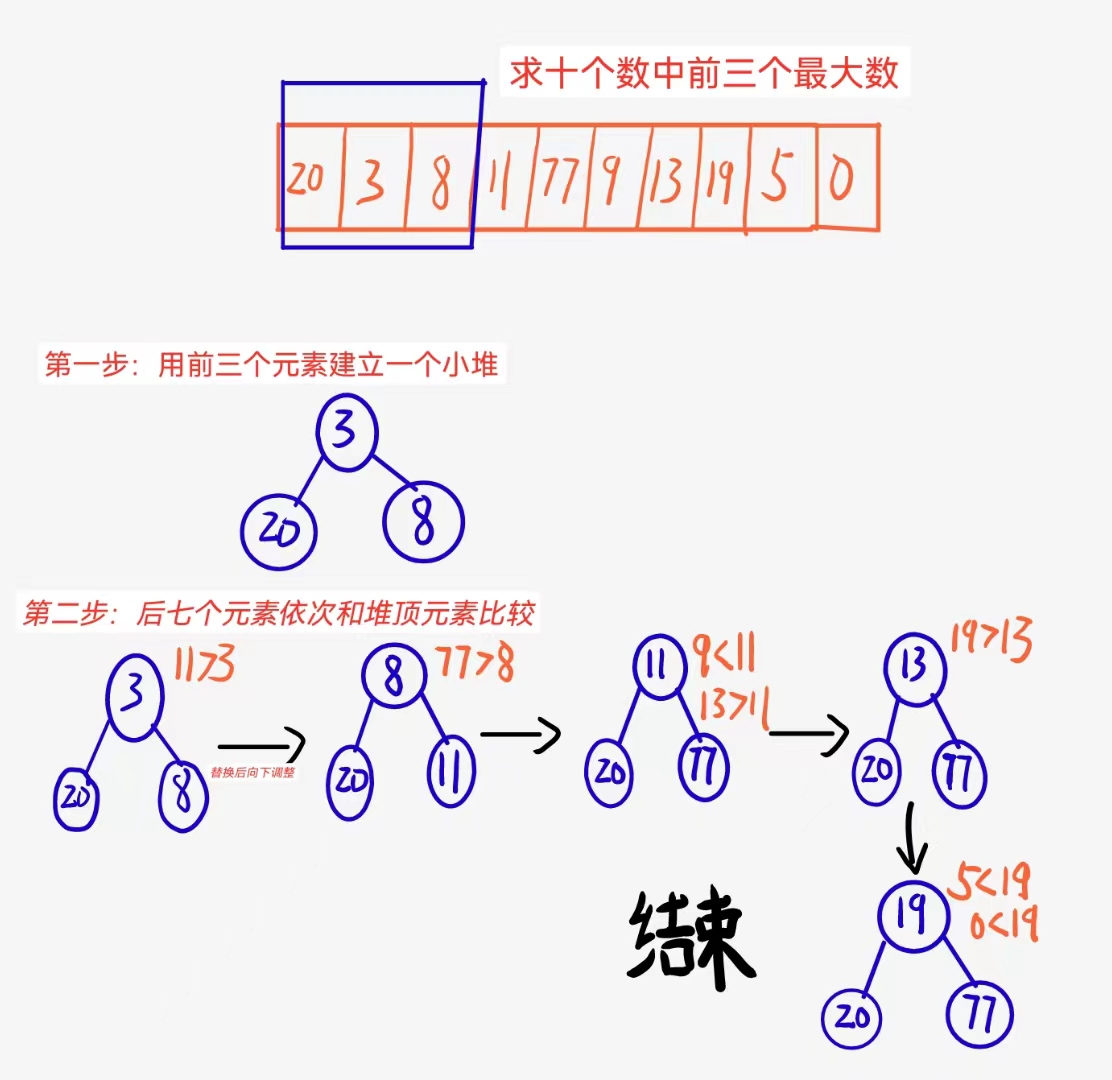 事实上这里的77 19 20就是这十个数中前三大的!
事实上这里的77 19 20就是这十个数中前三大的!
4.2 代码实现?
这里我们有了思路后可以实现一下代码:
void TestTopk()//topk问题,找出n个数中的前k个最大数
{
int n = 10000;
int* a = (int*)malloc(sizeof(int) * n);
srand(time(0));
for (size_t i = 0; i < n; ++i)
{
a[i] = rand() % 1000000;//生成一百万以内的随机数
}
a[5] = 1000000 + 1;
a[1231] = 1000000 + 2;
a[531] = 1000000 + 3;
a[5121] = 1000000 + 4;
a[115] = 1000000 + 5;
a[2335] = 1000000 + 6;
a[9999] = 1000000 + 7;
a[76] = 1000000 + 8;
a[423] = 1000000 + 9;
a[3144] = 1000000 + 10;
PrintTopK( a, n, 10);
}
这里我们先随机生成一万个一百万以内的数字,然后再在10个随机位置下标给上大于一百万的数.这样我们自己设计的十个数肯定就是这一万个数中的前10个最大的数 然后我们再调用TopK函数来实现它:
void PrintTopK(int* a, int n, int k)
{
HN hp;//创建并初始化堆
HeapInit(&hp);
//第一步:创建一个k个数的小堆
for (int i = 0; i < k; i++)//将数组前10个数建立为小堆
{
HeapPush(&hp, a[i]);
}
//第二步:剩下的n-k个数和堆顶的数据比较,比堆顶大就替换它
for (int i = k; i < n; i++)
{
if (a[i] > HeapTop(&hp))
{
HeapPop(&hp);
HeapPush(&hp, a[i]);//这里直接调用Push函数就不要再写向下调整了,因为此函数中以及包含了向下调整
//hp.a[0] = a[i];//如果是这种写法就要加上向下调整
//AdjustDown(hp.a, hp.size, 0);
}
}
HeapPrint(&hp);
HeapDestroy(&hp);
}
大家可以自己去写一下,最后会发现,打印的数据就是我们设计好的数据!
这里我们就把大名鼎鼎的TopK问题给解决了!
4.3 算法效率?
先给结论:TopK问题用堆结构解决的时间复杂度为O(K+(N-K)log2k)
首先,建立小堆的时间复杂度为O(K),再将剩余元素与堆顶元素进行比较,一共要比较(N-K)次,而每一次比较替换堆顶元素后,需要向下调整,最坏的情况是调整到最下面的叶子节点,所以最坏调整数的高度次,然而数的高度等于log2K,这里的K代表堆中元素个数,所以综上所述:TopK问题的解决使用到的时间复杂度为O(K+(N-K)log2k)
并且在现实运用中,N总是远远大于K的,所以这个地方的时间复杂度在一些情况下可以接近O(N)!这个效率可想而知是很优的!
5. 总结?
堆这个地方的知识还远远没有结束,这只是冰山一角,还有非常经典的堆排序不放在这里讲解,我后面会专门出一个专栏来讲解插入排序,希尔排序,堆排序等等排序方式.
其实堆主要就围绕向上调整和向下调整这两个步骤讲解,其他的思路和顺序表大相径庭.我们这一章实现的是小堆,如果你想要实现大堆也很简单,只需要在向上调整中,和向下调整中修改几个大小于符号就可以实现大堆.比如在向上调整中,大堆应该是儿子大于父亲才交换,在向下调整中,要选取两个孩子中较大的孩子…这个就留给那么自己实现了
? 我的码云:gitee-杭电码农-NEO?






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结