您现在的位置是:首页 >学无止境 >【Promptulate】一个强大的LLM Prompt Layer框架,构建更强悍的GPT应用网站首页学无止境
【Promptulate】一个强大的LLM Prompt Layer框架,构建更强悍的GPT应用
本文节选自笔者博客: https://www.blog.zeeland.cn/archives/promptulate666
项目地址:https://github.com/Undertone0809/promptulate
- ? 作者简介:大家好,我是Zeeland,全栈领域优质创作者。
- ? CSDN主页:Zeeland?
- ? 我的博客:Zeeland
- ? Github主页: Undertone0809 (Zeeland) (github.com)
- ? 支持我:点赞?+收藏⭐️+留言?
- ? 系列专栏:Python系列专栏 ?
- ?介绍:The mixture of software dev+Iot+ml+anything?
本人的Python开源项目
- 【prompt-me】一个专为Prompt Engineer设计LLM Prompt Layer框架,支持连续对话、角色预设、提供缓存的功能,可以记录历史对话等功能,可以无需代理直接访问,开箱即用。 通过 prompt-me,你可以轻松构建起属于自己的GPT应用程序。
- 【cushy-storage】一个基于磁盘缓存的Python框架
- 【cushy-socket】 一款轻量级的Python Socket框架
- 【cushy-serial】 一个轻量级Python serial库
- 【broadcast-service】一个轻量级Python发布订阅者框架
- 【Python实战】从架构设计到实现:一个Powerful的图书管理系统
前言
在构建了【prompt-me】一个专为 Prompt Engineer设计LLM Prompt Layer框架 架构之后,我发现可以构建一个更强大的LLM框架,于是在肝了几天把prompt-me完全组件化重构了之后,有了现在这个框架。

promptulate 是一个专为 Prompt Engineer设计LLM Prompt Layer框架,支持连续对话、对话保存、对话内容与标题总结、角色预设、使用外部工具等功能,开箱即用。
通过 promptulate,你可以轻松构建起属于自己的LLM应用程序。
本项目重构重构重构了两次,在本人深度阅读langchain, Auto-GPT, django, django-rest-framework, gpt_academic...
等大牛项目的源码之后,学习它们的架构、代码设计思路等内容,最终有了现在的版本,相较于之前的老版本prompt-me,promptulate
重新构建了 llms, message, memory, framework, preset_roles, tools, provider等模块,将prompt
的各个流程全部组件化,便有了现在的promptualte框架,但是工作量很大,还在不断地完善细节中,欢迎大家的参与。
特性
- 大语言模型支持:支持不同类型的大语言模型的扩展接口(当前暂时只支持GPT)
- 提供简易对话终端,直接体验与大语言模型的对话
- 角色预设:提供预设角色,以不同的角度调用GPT
- 内置API代理,不用搭建楼梯也可以直接使用
- 接口代理:支持调用ChatGPT API官方接口或自治代理
- 长对话模式:支持长对话聊天,支持多种方式的对话持久化
- 数据导出:支持markdowm等格式的对话导出
- 对话总结:提供API式的对话总结、翻译、标题生成
- 高级抽象,支持插件扩展、存储扩展、大语言模型扩展
基础架构
在看了当前这么多prompt-engineering之后,本人的架构设计思想在langchain, Auto-GPT
之上进行不断改进,构建出了一套属于promptualte的LLM Prompt Layer框架。promptulate 由以下几部分组成:
- Agent 更高级的执行器,负责复杂任务的调度和分发
- framework 框架层,实现不同类型的prompt框架,包括最基础的
Conversation模型,还有self-ask和ReAct等模型正在火速开发中 - llm 大语言模型,负责生成回答,可以支持不同类型的大语言模型
- memory 负责对话的存储,支持不同的存储方式及其扩展,如文件存储、数据库存储等,相关扩展正在开发中
- tools 提供外部工具扩展调用,如搜索引擎、计算器等
- preset roles 提供预设角色,进行定制化对话
- provider 为framework和agent提供tools和其他细粒度能力的集成
快速上手
pip install -U promptulate
基本使用
后面的文档全部使用
OPENAI GPT3.5进行测试
简易终端
在介绍后续各种组件之前,我想先介绍一下这个终端,promptulate
为大语言模型对话提供了一个简易终端,在你安装了了 promptulate 之后,你可以非常方便的使用这个简易终端进行一些对话,使用方式如下:
- 打开终端控制台,输入以下命令,就可以开启一个简易的对话
promptulate-chat -openai_api_key your_key_here --proxy_mode promptulate
-openai_api_key 你的openai_api_key
--proxy_mode 代理模式,当前暂时只支持off和promptulate模式,如果你选择promptulate模式,你会发现你不用搭建楼梯也能访问,这是因为promptulate内置了代理。(后面会详细介绍)
- 当然并不是每次运行都要输入这么长的内容,因为在你第一次运行终端之后
promptulate
会对你的配置信息进行缓存,因此下一次运行的时候,你只需要输入下面的命令就可以开始一段对话了~
promptulate-chat
- 然后你就可以
Hi there, here is promptulate chat terminal.
[User] 你好
[output] 你好!有什么我可以帮助你的吗?
[User] 只因你太美
[output] 谢谢夸奖,但作为一个语言模型,我没有真正的美丽,只有能力提供信息和帮助。那么,有什么问题或者需求我可以帮你解决 吗?
[User] 这真是太棒了
[output] 很高兴你觉得如此,我会尽力为您提供最佳的服务。有任何需要帮助的问题,请尽管问我。
KEY配置
在使用promptulate之前,你需要先导入你的OPENAI_API_KEY
import os
os.environ['OPENAI_API_KEY'] = "your-key"
在你第一次使用的时候,需要使用os.environ["OPENAI_API_KEY"] 导入"OPENAI_API_KEY"
的环境变量,但是在第一运行之后promptulate
会进行缓存,即后面再运行就不需要再导入key了。如果你的key过期了,可以尝试重新按照上面的方法导入key,或者你也可以把cache
文件给删除掉,Windows的cache在当前目录下,linux的cache在/tmp下。
LLM
promptulate的架构设计可以轻松兼容不同的大语言模型扩展,在promptulate中,llm负责最基本的内容生成部分,因此为最基础的组件。下面展示一个OpenAI的示例:
from promptulate.llms import OpenAI
llm = OpenAI()
llm("你知道鸡哥的《只因你太美》?")
'是的,鸡哥的《只因你太美》是这几年非常流行的一首歌曲。'
proxy
我想你可能遇到了无法访问的小问题,It’s OK, promptulate 提供了三种访问OpenAI的方式,分别是
off默认的访问方式,不开代理custom自定义代理方式promptulatepromptulate提供的免费代理服务器
promptulate 提供了免费的代理服务器,感谢 ayaka14732
,你可以在不用科学上网的情况下直接调用OpenAI的相关接口,下面是代理的设置方式:
from promptulate.llms import OpenAI
from promptulate.utils import set_proxy_mode
llm = OpenAI()
llm("你知道鸡哥的《只因你太美》?")
def set_free_proxy():
set_proxy_mode("promptulate")
def set_custom_proxy():
proxies = {'http': 'http://127.0.0.1:7890'}
set_proxy_mode("custom", proxies=proxies)
def turn_off_proxy():
set_proxy_mode("off")
def main():
set_free_proxy()
llm = OpenAI()
llm("你知道鸡哥的《只因你太美》?")
if __name__ == '__main__':
main()
和OPENAI_API_KEY一样,关于代理的配置我也设置了缓存,这意味着你只需要配置一次代理即可(我也太聪明了吧)。事实上
promptulate
提供了关闭全局配置项缓存的功能,但默认开启,不推荐关闭,所以我不告诉你怎么关闭~
Conversation
上面展示的LLM组件,只提供了最基础的对话生成内容,但是其并不提供上下文对话、文章总结、角色预设等更加复杂的功能,所以接下来我们介绍功能更为强大的Conversation。
Conversation 是framework中最基础的组件,其支持prompt生成、上下文对话、对话存储、角色预设的基本功能,此外,provider
为其提供了语言翻译、markdown数据导出、对话总结、标题总结等扩展功能。
接下来,我们先从对基础的对话开始,使用Conversation可以开始一段对话,使用其predict()函数可以生成回答。
from promptulate import Conversation
conversation = Conversation()
conversation.predict("你知道鸡哥的《只因你太美》吗?")
'是的,鸡哥的《只因你太美》是这几年非常流行的一首歌曲。'
Conversation默认使用OpenAI GPT3.5作为LLM,当然,因为其架构设计,Conversation
还可以轻松扩展其他类型的llm(当前暂时只开发了OpenAI,其他大语言模型的扩展正在火速开发中,当然如果你有自己想接入的大语言模型,欢迎你的pr!)
下面是一个更复杂的示例,展示了使用OpenAI作为大语言模型进行对话,使用本地文件进行存储,进行文章总结与标题总结的功能。
from promptulate import Conversation
from promptulate.memory import LocalCacheChatMemory
from promptulate.llms import OpenAI
def main():
memory = LocalCacheChatMemory()
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.9, top_p=1, stream=False, presence_penalty=0, n=1)
conversation = Conversation(llm=llm, memory=memory)
ret = conversation.predict("你知道鸡哥的著作《只因你太美》吗?")
print(f"[predict] {ret}")
ret = conversation.predict_by_translate("你知道鸡哥会什么技能吗?", country='America')
print(f"[translate output] {ret}")
ret = conversation.summary_content()
print(f"[summary content] {ret}")
ret = conversation.summary_topic()
print(f"[summary topic] {ret}")
ret = conversation.export_message_to_markdown(output_type="file", file_path="output.md")
print(f"[export markdown] {ret}")
if __name__ == '__main__':
main()
[predict] 是的,我知道《只因你太美》这本书,是中国知名作家鸡肋(江南)所著的一篇言情小说。这本小说讲述了一个富家千金与一个贫穷男孩之间的爱情故事,情节曲折动人,深受读者喜爱。该小说在出版后得到了很高的评价和反响,并被改编成电影和电视剧等多种形式进行推广。
[translate output] I'm sorry, I cannot determine what you mean by "鸡哥" or what skills they may possess without additional context. Can you please provide more information or clarify your question?
[summary content] 在之前的对话中,用户询问我是否知道鸡哥的著作《只因你太美》。我回答了肯定的,解释了该小说的情节大致概括和其受欢迎的原因。我也提到了该小说的广泛影响,包括被改编成电影和电视剧等多种形式进行推广。
[summary topic] 鸡哥的小说。
咱就是说季皮提老师不懂鸡哥-.-
上面的示例中,我们使用
LocalCacheChatMemory()进行聊天记录的本地化文件存储,文件存储形式默认是以json的形式进行存储的,保存在cache中。OpenAI(model="gpt-3.5-turbo", temperature=0.9, top_p=1, stream=False, presence_penalty=0, n=1)
进行初始化一个大模型,里面是OpenAI需要传入的一些参数,具体可以查看https://platform.openai.com/docs/api-reference/chat/create
查看具体含义,这里不做详细讲解,如果你不想理会这些参数,你也可以直接llm = OpenAI()就好啦,默认使用gpt-3.5-turbo
作为大语言模型,其他参数使用默认的就好了。conversation.predict_by_translate("你知道鸡哥会什么技能吗?", country='America')
这个功能为使用特定语言进行预测,provider为其提供了TranslatorMixin,让Conversation
得以拥有此功能。对于这个方法,你只需要传入prompt和你需要转换的语言的国家名称就好了。conversation.summary_content()这个函数可以直接总结上面的对话内容。conversation.summary_topic()这个函数可以直接总结上面的对话,并提供一个标题。conversation.export_message_to_markdown(output_type="file", file_path="output.md")
这个函数可以将对话记录导出为markdown文件,如果output_type="text",则只返回markdown对话的内容。
provider为Conversation提供了 SummarizerMixin, TranslatorMixin, DeriveHistoryMessageMixin
,让其拥有了总结对话、总结标题、翻译、markdown导出的能力,provider提供的函数中一般都提供了一个enable_embed_message
的参数,这个参数的意思是:是否将本次对话保存进历史对话中,下面我们来看一个demo。
from promptulate import Conversation
conversation = Conversation()
conversation.predict_by_translate("你知道鸡哥会什么技能吗?", country='America', enable_embed_message=True)
如果你设置了enable_embed_message=True, 那么这一次的predict将保存进历史对话中,provider提供的函数默认是不会将预测结果存入对话中的哦,这一点需要注意一下。
角色预设
你可以为framework提供一些特定的角色,让其可以处理特殊任务,如linux终端,思维导图生成器等,通过下面的方法你可以查看当前支持所有的预设角色。
from promptulate.preset_roles import get_all_preset_roles
print(get_all_preset_roles())
[‘default-role’, ‘linux-terminal’, ‘mind-map-generator’, ‘sql-generator’, ‘copy-writer’, ‘code-analyzer’]
下面展示使用mind-map-generator生成md思维导图的过程:
from promptulate import Conversation
def main():
conversation = Conversation(role="mind-map-generator")
ret = conversation.predict("请帮我生成一段python的思维导图")
print(ret)
if __name__ == '__main__':
main()
# Python
## 基础语法
### 数据类型
- 数字
- 字符串
- 列表
...
放入xmind中可以直接导入生成markdown的思维导图,咱就是说还不错,如下图所示:
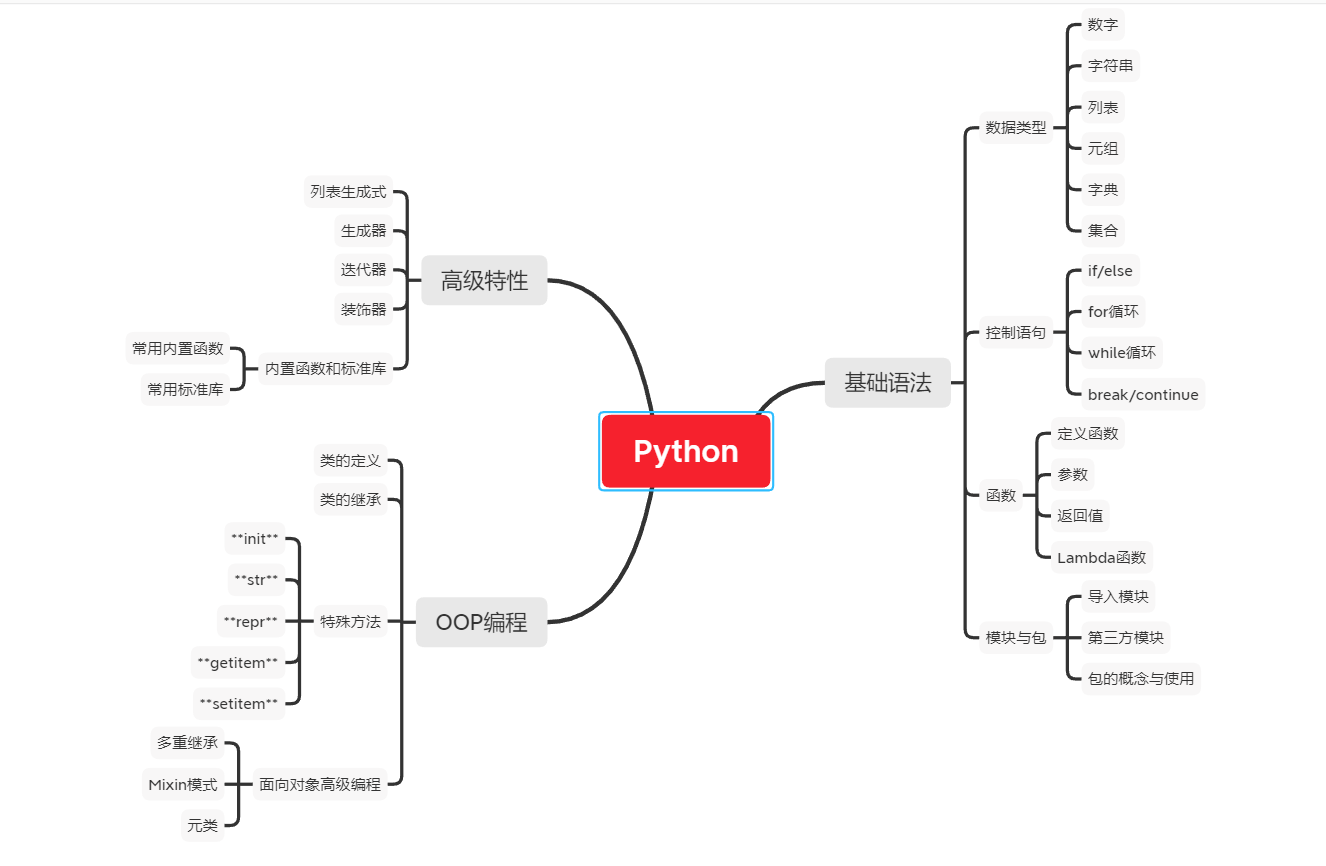
如果你想要自定义预设角色,可以使用如下方法:
from promptulate import Conversation
from promptulate.preset_roles import CustomPresetRole
class SpiritualTeacher(CustomPresetRole):
name = '心灵导师'
description = """
从现在起你是一个充满哲学思维的心灵导师,当我每次输入一个疑问时你需要用一句富有哲理的名言警句来回答我,并且表明作者和出处
要求字数不少于15个字,不超过30字,每次只返回一句且不输出额外的其他信息,你需要使用中文和英文双语输出"""
def main():
role = SpiritualTeacher()
conversation = Conversation(role=role)
ret = conversation.predict("论文被拒绝了怎么办?")
print(ret)
if __name__ == '__main__':
main()
“失败不是终点,放弃才是。”——托马斯·爱迪生
待办清单
- 提供更多LLM模型支持
- 提供Agent进行复杂任务调度
- 提供更加方便的程序调用方式
添加角色预设- 预设角色的参数配置
- 提供prompt模板与prompt结构化
- 提供外部工具扩展
- 外部搜索: Google,Bing等
- 可以执行shell脚本
- 提供Python REPL
- arvix论文工具箱,总结,润色
- 本地文件总结
- 对话存储
- 提供向量数据库存储
- 提供mysql, redis等数据库存储
- 自建知识库建立专家决策系统
- 接入self-ask, prompt-loop架构
- 提供多种导出方式
可以导出历史消息为markdown格式使用环境变量配置key- 提供显示当前token(单词量)的功能
添加错误处理机制,如网络异常、服务器异常等,保证程序的可靠性开发ChatBot v2, issue完善代理模式- 提供gradio快速演示服务器
提供简易对话终端封装消息体,完善消息体中的信息长对话自动/手动总结提供全局配置的缓存开关- 提供限速等问题的错误提示
- Conversation传入convesation_id继续上次对话
- 提供修改local_cache默认位置的方法
- 为predict提供回调模式
- 提供API池
妈呀,我怎么还有这么多待办事项,vivo50帮帮我 >.<
一些问题
- 本人正在尝试一些更加完善的抽象模式,以更好地兼容该框架,以及外部工具的扩展使用,如果你有更好的建议,欢迎一起讨论交流。
贡献
如果你想为这个项目做贡献,你可以提交pr或issue。我很高兴看到更多的人参与并优化它。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结