您现在的位置是:首页 >学无止境 >机器学习模型的评估网站首页学无止境
机器学习模型的评估
(1)数据划分
将可用数据划分为三部分:训练集、验证集和测试集。在训练数据上训练模型。在验证数据上评估模型。模型准备上线之前,在测试数据上最后测试一次
不将数据划分为两部分,即训练集和测试集?在训练数据上进行训练,在测试数据上进行评估的原因:
原因在于开发模型时总是需要调节模型配置,比如确定层数或每层大小[这些叫作模型的超参数(hyperparameter),以便与参数(权重)区分开]。这个调节过程需要使用模型在验证数据上的表现作为反馈信号。该过程本质上是一种学习过程:在某个参数空间中寻找良好的模型配置。因此,基于模型在验证集上的表现来调节模型配置,很快会导致模型在验证集上过拟合,即使你并没有在验证集上直接训练模型。
造成这一现象的核心原因是信息泄露(information leak)。每次基于模型在验证集上的表现来调节模型超参数,都会将验证数据的一些信息泄露到模型中。如果对每个参数只调节一次,那么泄露的信息很少,验证集仍然可以可靠地评估模型。但如果多次重复这一过程(运行一次实验,在验证集上评估,然后据此修改模型),那么会有越来越多的验证集信息泄露到模型中。
针对数据较少的三种经典评估方法
(1)简单的留出验证
留出一定比例的数据作为测试集。在剩余的数据上训练模型,然后在测试集上评估模型。
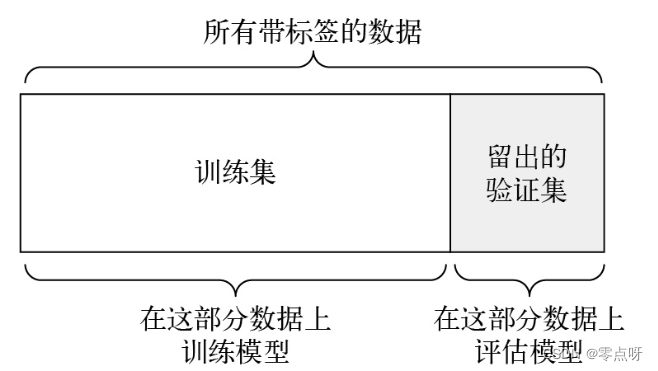
**缺点:**如果可用的数据很少,那么可能验证集包含的样本就很少,无法在统计学上代表数据。
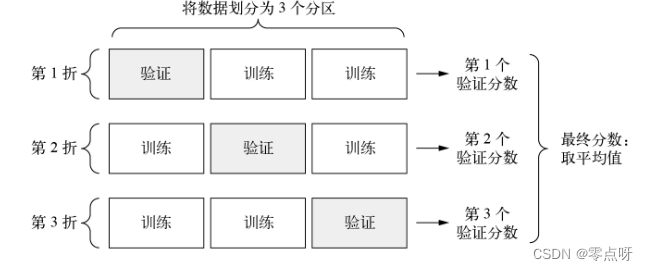
(2)K折交叉验证
K折交叉验证是指将数据划分为K个大小相等的分区。对于每个分区i,在剩余的K-1个分区上训练模型,然后在分区i上评估模型。最终分数等于K个分数的平均值。
(3)带有打乱数据的重复K折交叉验证
多次使用K折交叉验证,每次将数据划分为K个分区之前都将数据打乱。最终分数是每次K折交叉验证分数的平均值。
(2)改进模型拟合
在这一阶段,通常会遇到以下3种常见问题:
- 训练不开始:训练损失不随着时间的推移而减小。
- 训练开始得很好,但模型没有真正泛化:模型无法超越基于常识的基准。
- 训练损失和验证损失都随着时间的推移而减小,模型可以超越基准,但似乎无法过拟合,这表示模型仍然处于欠拟合状态。
改进的方法
(1)调节关键的梯度下降参数
当出现有时训练不开始,或者过早停止。损失保持不变时。
- 降低或提高学习率。学习率过大,可能会导致权重更新大大超出正常拟合的范围,学习率过小,则可能导致训练过于缓慢,以至于几乎停止。
- 增加批量大小。如果批量包含更多样本,那么梯度将包含更多信息且噪声更少(方差更小)。
(2)提高泛化能力
- 数据集管理
- 模型正则化
- 缩减模型容量:模型的容量越大,它拟合训练数据的速度就越快(得到很小的训练损失),但也更容易过拟合(导致训练损失和验证损失有很大差异)。
- 添加权重正则化:强制让模型权重只能取较小的值,从而限制模型的复杂度,这使得权重值的分布更加规则.其实现方法是向模型损失函数中添加与较大权重值相关的成本(cost)。这种成本有两种形式:
- L1正则化:添加的成本与权重系数的绝对值(权重的L1范数)成正比。
- L2正则化:添加的成本与权重系数的平方(权重的L2范数)成正比。神经网络的L2正则化也叫作权重衰减(weight decay)。不要被不同的名称迷惑,权重衰减与L2正则化在数学上是完全相同的。
- 添加dropout:
dropout是神经网络最常用且最有效的正则化方法之一.对某一层使用dropout,就是在训练过程中随机舍弃该层的一些输出特征(将其设为0),dropout比率(dropout rate)是指被设为0的特征所占的比例,它通常介于0.2~0.5。比方说,某一层在训练过程中对给定输入样本的返回值应该是向量[0.2, 0.5, 1.3, 0.8,1.1]。使用dropout之后,这个向量会有随机几个元素变为0,比如变为[0, 0.5, 1.3, 0,1.1]。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结