您现在的位置是:首页 >学无止境 >Tips for Deep Learning网站首页学无止境
Tips for Deep Learning
目录
Good Results on Training Data?
Recipe of Deep Learning
我们要做的第一件事是,提高model在training set上的正确率,然后要做的事是,提高model在testing set上的正确率。

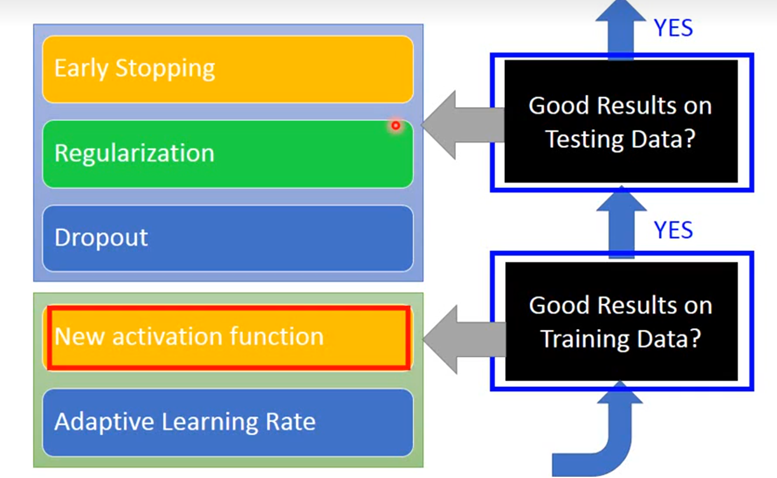
Good Results on Training Data?
这一部分主要讲述如何在Training data上得到更好的performance,分为两个部分,New activation function和Adaptive Learning Rate。
New activation function
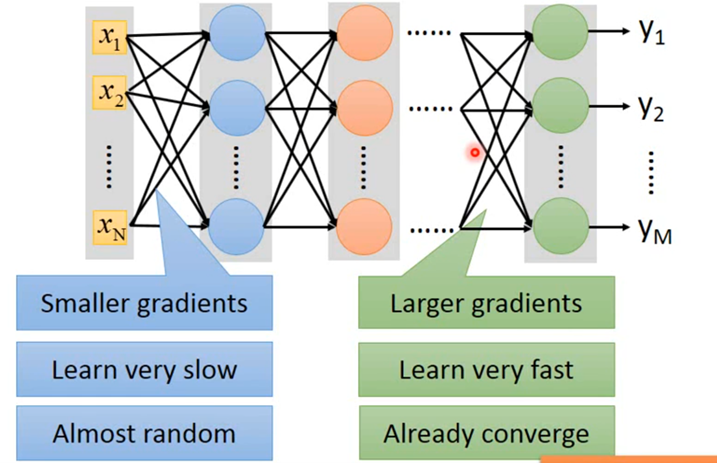
- Vanishing Gradient Problem
当你把network叠得很深的时候,在靠近input的地方,这些参数的gradient(即对最后loss function的微分)是比较小的;而在比较靠近output的地方,它对loss的微分值会是比较大的。
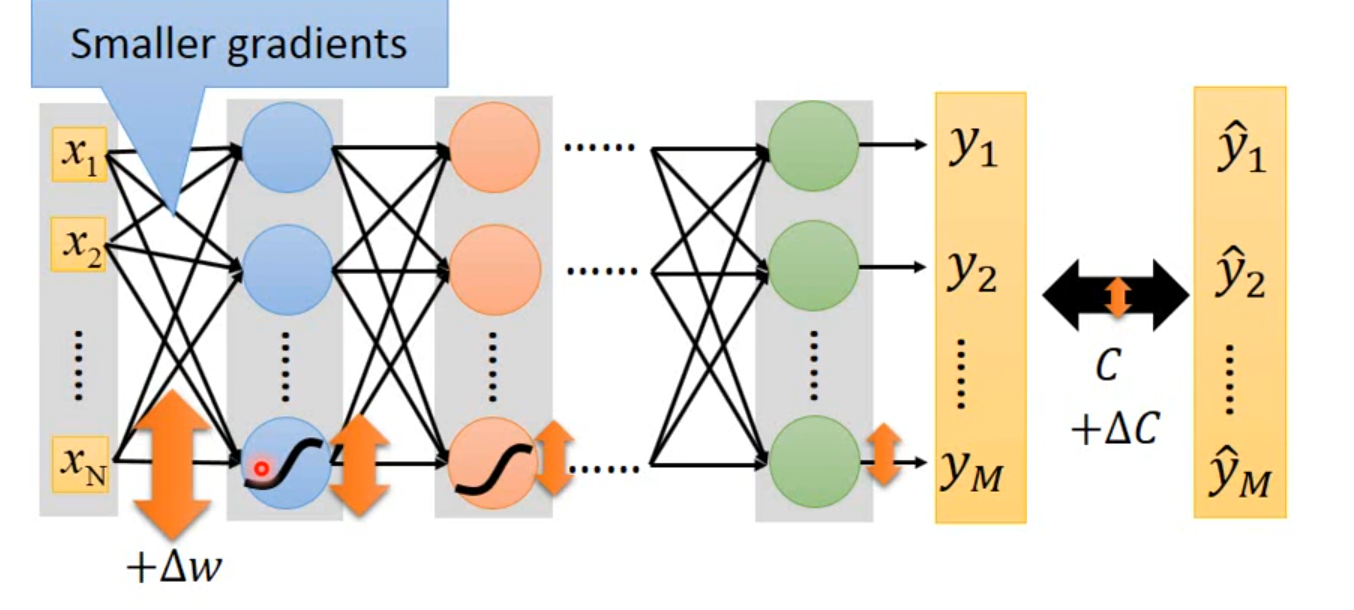
Δw通过sigmoid function之后,得到output是会变小的
-
ReLU


优点:
跟sigmoid function比起来,ReLU的运算快很多。
ReLU的想法结合了生物上的观察。
无穷多bias不同的sigmoid function叠加的结果会变成ReLU。
ReLU可以处理Vanishing gradient的问题。

-
Maxout
Maxout就是让network自动去学习它的activation function。ReLU就是特殊的Maxout。

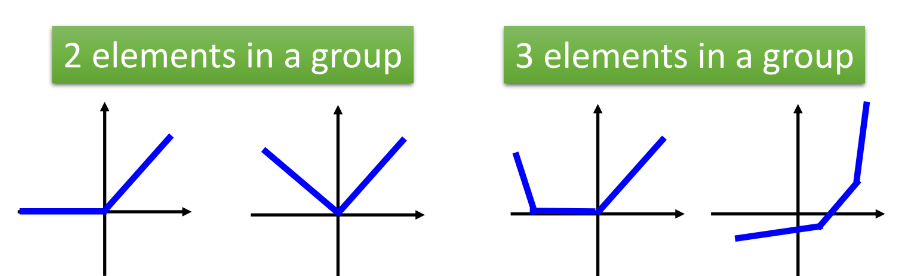
Maxout中的激活函数可以被分段为多个线性的凸函数,多少段取决于之前我们分组后一组元素的个数。
- How to train Maxout
由于我们有很多很多笔training data,所以network的structure在训练中不断地变换,实际上最后每一个weight参数都会被train到。

Adaptive learning rate
- Adagrad

- RMSProp
用一个α来调整对不同gradient的使用程度,比如把α的值设的小一点,意思就是更倾向于相信新的gradient所告诉的error surface的平滑或陡峭程度,而比较无视于旧的gradient所提供给的information。

- Momentum
每次移动的方向,不再只有考虑gradient,而是现在的gradient加上前一个时间点移动的方向。

- Adam

Good Results on Testing Data?
这一部分主要讲述如何在Testing data上得到更好的performance,分为三个模块,Early Stopping、Regularization和Dropout。
Early Stopping
假如我们知道testing set上的loss变化,我们应该停在testing set最小的地方(如图所示)。但是我们不知道你的testing set上的error是,所以我们会用validation来代替。

Regularization
在update参数的时候,其实是在update之前就已近把参数乘以一个小于1的值(η、λ都是很小的值),这样每次都会让weight小一点。最后会慢慢变小趋近于0,但是会与后一项梯度的值达到平衡,使得最后的值不等于0,L2的Regularization又叫做Weight Decay。

每一次更新时参数时,我们一定要去减一个ηλsgn(wt)![]() (w值是正的,就是减去一个值;若w是负的,就是加上一个值,让参数变大)。
(w值是正的,就是减去一个值;若w是负的,就是加上一个值,让参数变大)。
L2、L1都可以让参数变小,但是有所不同的,若w是一个很大的值,L2乘以一个小于1的值,L2下降的很快,很快就会变得很小,在接近0时,下降的很慢,会保留一些接近0的值;L1的话,减去一个固定的值(比较小的值),所以下降的很慢。
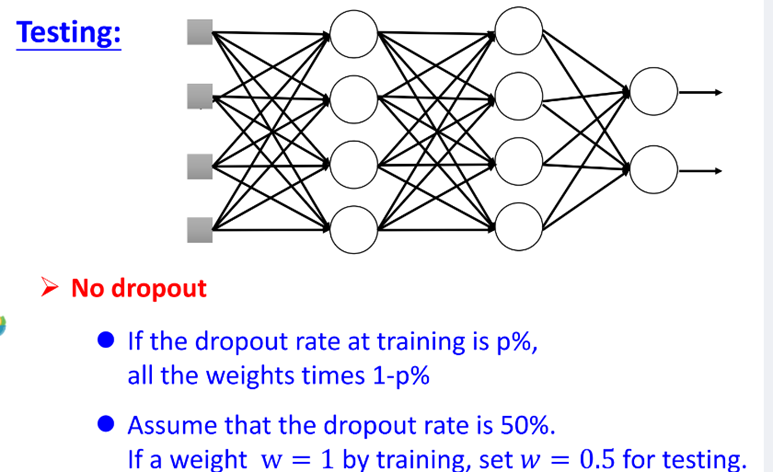
Dropout
在train的时候,每一次update参数之前,对network里面的每个neural(包括input),做sample(抽样)。 每个neural会有p%会被丢掉,跟着的weight也会被丢掉。 testing的时候不做dropout,所有的neuron都要被用到,假设在training的时候,dropout rate是p%,从training data中被learn出来的所有weight都要乘上(1-p%)才能被当做testing的weight使用。
testing的时候不做dropout,所有的neuron都要被用到,假设在training的时候,dropout rate是p%,从training data中被learn出来的所有weight都要乘上(1-p%)才能被当做testing的weight使用。








站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结