您现在的位置是:首页 >技术杂谈 >[数据结构与算法]-初步认识链表特点和类别(头结点和头指针的解释)网站首页技术杂谈
[数据结构与算法]-初步认识链表特点和类别(头结点和头指针的解释)
?博客主页:Code_文晓
?本文专栏:数据结构与算法
?欢迎关注:感谢大家的点赞评论+关注,祝您学有所成!
前言:前两篇文章详细讲述了线性表中顺序表的特点和经典操作认识线性表+顺序表的经典操作,本篇文章来认识一下链表的简单特点和种类,后续文章会继续深入研究每种链表,本文为后续详细深入各种链表操作打下基础。
目录
一.链表的认识和定义
1.认识:链表是由许多相同数据类型的元素按照特定顺序排列而成的线性表,其特性是在计算机内存的位置是不连续与随机(Random)存储的,优点是数据的插入或删除都相当方便,有新数据加入就向系统要一块内存空间,数据删除后,就把空间还给系统,不需要移动大量数据。缺点是设计数据结构时较为麻烦,另外在查找数据时,也无法像静态数据一样可随机读取数据,必须按顺序找到该数据为止。
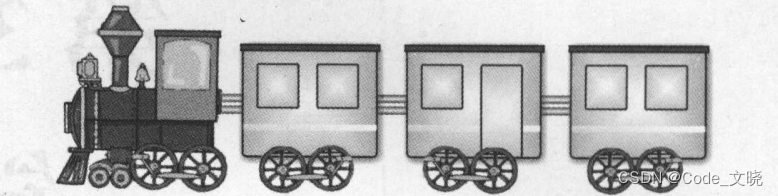
日常生活中有许多链表的抽象运用,例如可以把“单向链表”想象成火车,有多少人就只挂多少节的车厢,当假日人多需要较多车厢时可多挂些车厢,人少了就把车厢数量减少,做法十分弹性。游乐场中的摩天轮也是一种“环形链表”的应用,可以自由增加坐厢数量。

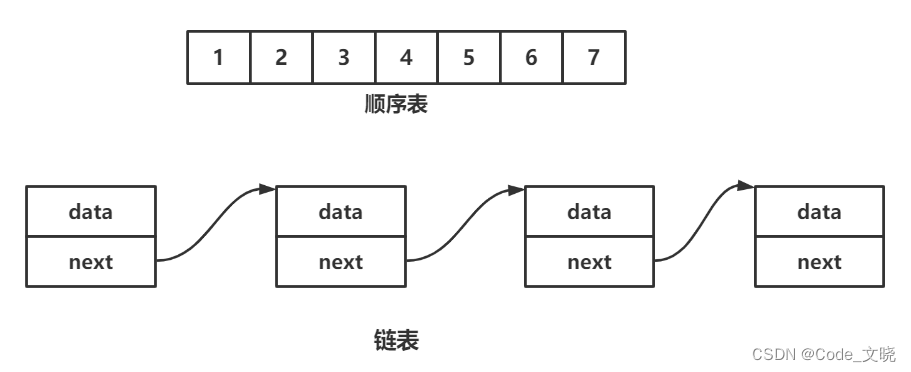
2.定义:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表 中的指针链接次序实现的 。
3.顺序表和链表存储结构的区别:
二.链表的分类
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1. 单向或者双向链表
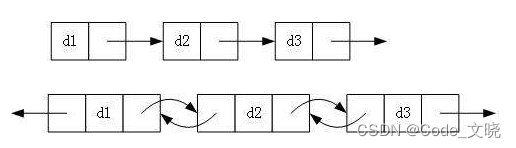
2. 带头或者不带头链表
3. 循环或者非循环链表
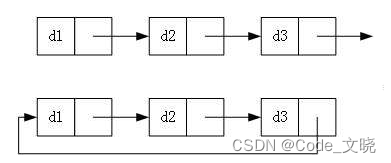
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
无头单向非循环链表和有头双向循环链表
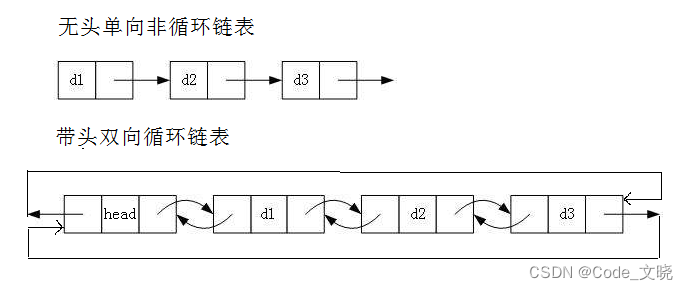
1. 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结 构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2. 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都 是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带 来很多优势,实现反而简单了,后面我们代码实现了就知道了。
三.头结点和头指针
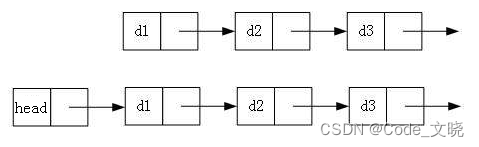
先看一下有无头结点的单链表图。
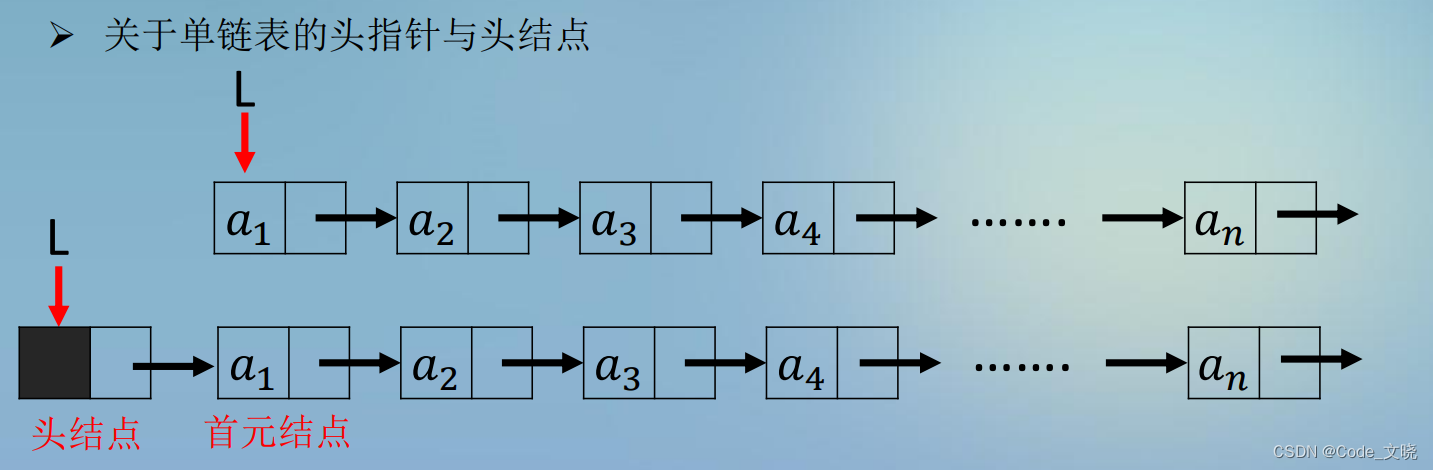
头指针:指针L就是头指针,指向链表第一个结点(为头结点或首元结点)的指针。(链表有头结点则头结点就是第一个结点,无头结点则首元结点就是第一个结点)
头结点定义:在链表第一个元素结点之前额外附加的一个结点。
头结点的数据域:可以不记录信息,也可以记录表长等信息(推荐前者),计算单链表长度时不计算头结点。
头结点的指针域:指向链表的第一个元素结点。
头结点和头指针的区分:不管带不带头结点,头指针都始终指向链表的第一个结点,而头结点是带头结点的链表中的第一个结点,结点内通常不存储信息。
如何判断空表?
无头结点:if(L==NULL)
带头结点:if(L->next==NULL)
引入头结点的优点:
1. 使对链表的第一个位置上的操作和在表的其他位置上的操作一致,无须特殊处理。
2. 无论链表是否为空,其头指针始终是一个指向头结点的非空指针,使得对空表和非空表的操作处理变得统一。
对头结点的思考:
尽管有的时候头结点的加入非常便捷,但是我们不能依赖于带头结点的链表操作。因为无论是LeetCode刷题还是去公司笔试的时候很多题目都是不带头结点的,所以我们一定要学会对不带头结点的链表的操作,之后遇到的题目中如果带头结点更方便解决,再手动增加头结点进行合理使用。
四.链表的存储方式
了解完链表的类型,再来说一说链表在内存中的存储方式。
顺序表、数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
如图所示,
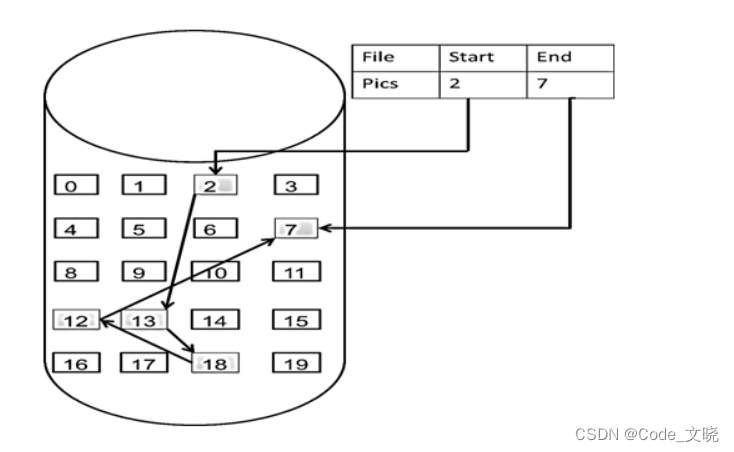
这个链表起始节点为2, 终止节点为7, 各个节点分布在内存的不同地址空间上,通过指针串联在一起。
总结:
本文介绍了链表的特点和定义以及常见的各种链表,对链表的结构有个大体的了解和认识。后续会更新各种链表的详细操作和原理的深入,可以点击本篇文章的专栏学习整个数据结构与算法的体系,如果觉得本篇文章对你有帮助,麻烦点个赞吧~






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结