您现在的位置是:首页 >技术杂谈 >【大数据之Hadoop】二十五、生产调优-HDFS核心参数网站首页技术杂谈
【大数据之Hadoop】二十五、生产调优-HDFS核心参数
1 NameNode内存生产配置
Hadoop3.x系列的NameNode内存是动态分配的,可以用jmap -heap 进程号 查看分配的内存。
在hadoop102中NameNode和DataNode的内存都是自动分配的,且相等。
根据经验:
NameNode最小值为1G,每增加1百万个物理块则增加1G内存。
DataNode最小值为4G,物理块的数量或者副本的数量增加都要增大DataNode的值,一个DataNode上的副本总数低于4百万则调为4G,超过4百万时每增加1百万的副本则增加1G内存。
配置文件:hadoop-env.sh
exportHDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx1024m"
exportHDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m"
2 NameNode心跳并发配置
集群中有NameNode,DataNode需要向NameNode汇报注册相关信息,同时客户端也会向NameNode进行请求执行任务,所以NameNode需要准备多少个线程连接DataNode的汇报。
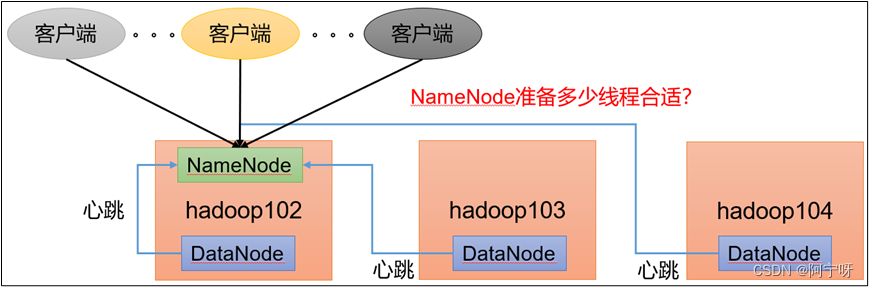
根据经验:dfs.namenode.handler.count=20xln(集群规模,即DataNode台数),比如此时台数为3,则应该设置20xln3=21。
配置文件:hdfs-site.xml
<--The number of Namenode RPC serverthreads that listen to requests from clients. Ifdfs.namenode.servicerpc-address is not configured then Namenode RPC server threadslisten to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大该参数。默认值是10。
-->
<property>
<name>dfs.namenode.handler.count</name>
<value>21</value>
</property>
3 开启回收站配置
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
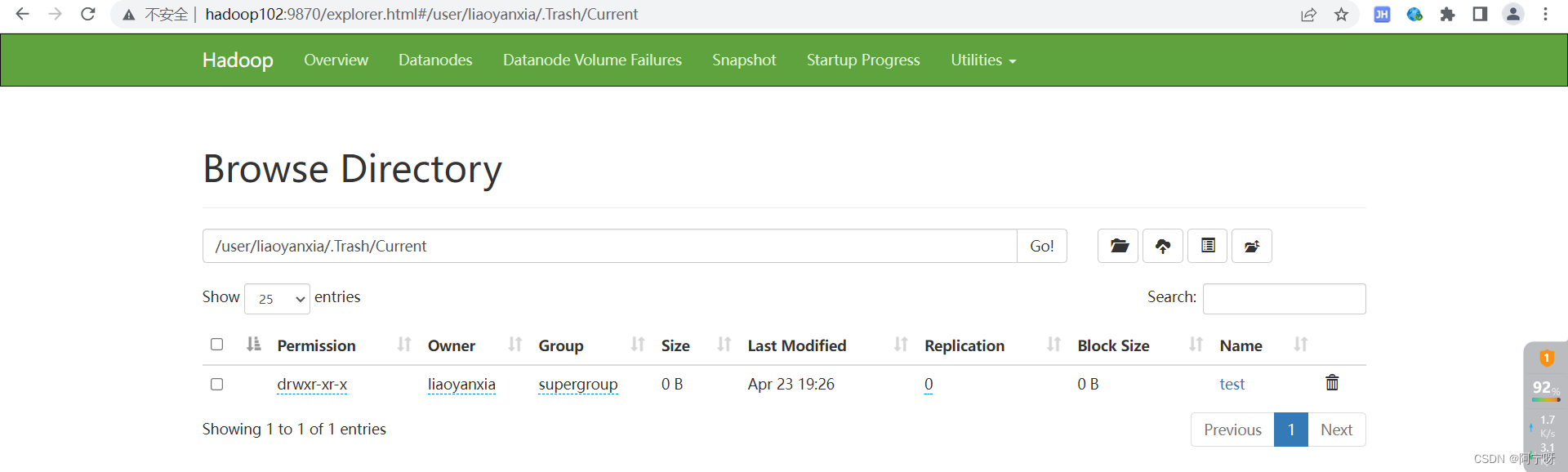
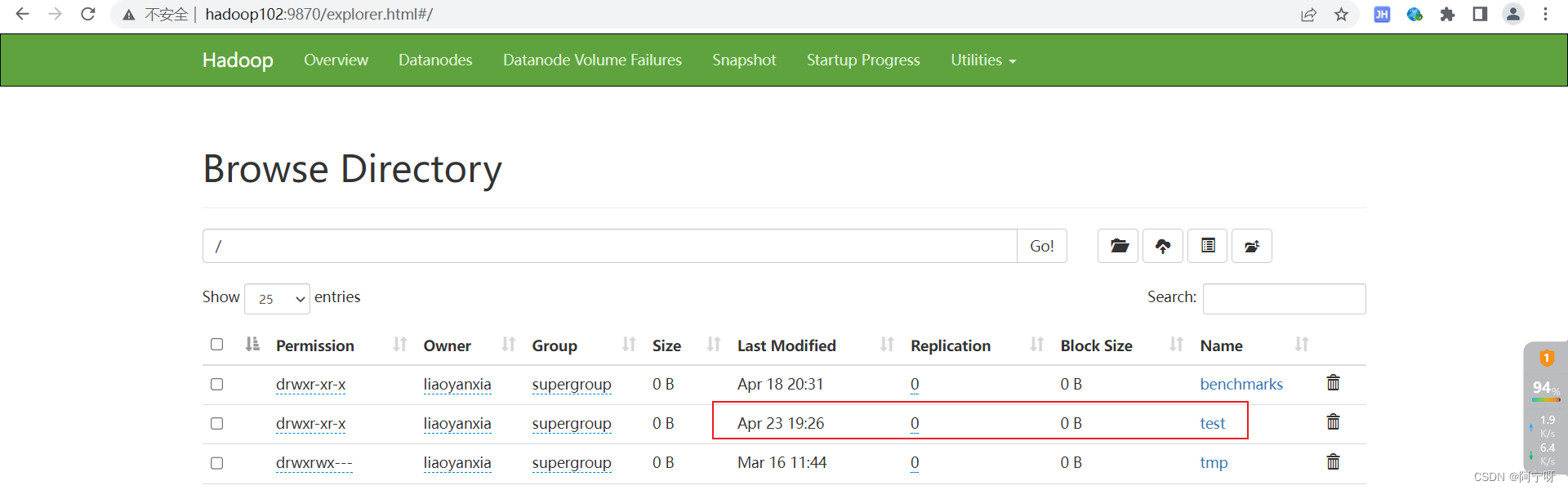
注意:从HDFS文件系统的网页上直接删除的文件和通过程序删除的文件不会回收到回收站。
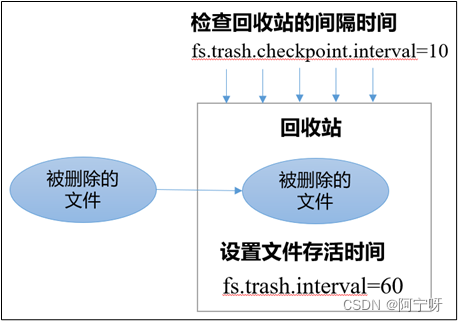
参数说明:
(1)文件存活时间fs.trash.interval ,默认为0即禁用回收站,数值单位为分钟。
(2)检查回收站的间隔时间fs.trash.checkpoint.interval,默认为0即该值与文件存活时间fs.trash.interval 相等。
(3)要求:检查回收站的时间间隔要<=文件存活时间,即fs.trash.checkpoint.interval <= fs.trash.interval。
通过程序删除文件需要调用moveToTrash()才会回收到回收站。
Trash trash = New Trash(conf);
trash.moveToTrash(path);
通过命令行hadoop fs -rm 删除的文件会回收到回收站。

恢复回收站的数据:把回收站里的文件移出来。







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结