您现在的位置是:首页 >其他 >Java 将增加虚拟线程,挑战 Go 协程网站首页其他
Java 将增加虚拟线程,挑战 Go 协程
Java19 正式发布,带来了一个 Java 开发者垂涎已久的新特性 —— 虚拟线程。在 Java 有这个新特性之前,Go 语言的协程风靡已久,在并发编程领域可以说是叱咤风云。随着国内 Go 语言的快速发展与推广,协程好像成为了一个世界上最好语言的必备特性之一。Java19 虚拟线程就是来弥补这个空白的。本文将通过对虚拟线程的介绍,以及与 Go 协程的对比来带大家尝鲜 Java19 虚拟线程。
本文要点:
- Java 线程模型
- 平台线程与虚拟线程性能对比
- Java 虚拟线程与 Go 协程对比
- 如何使用虚拟线程
Java 线程模型
java 线程 与 虚拟线程
我们常用的 Java 线程与系统内核线程是一一对应的,系统内核的线程调度程序负责调度 Java 线程。为了增加应用程序的性能,我们会增加越来越多的 Java 线程,显然系统调度 Java 线程时,会占据不少资源去处理线程上下文切换。

近几十年来,我们一直依赖上述多线程模型来解决 Java 并发编程的问题。为了增加系统的吞吐量,我们要不断增加线程的数量,但机器的线程是昂贵的、可用线程数量也是有限的。即使我们使用了各种线程池来最大化线程的性价比,但是线程往往会在 CPU、网络或者内存资源耗尽之前成为我们应用程序的性能提升瓶颈,不能最大限度的释放硬件应该具有的性能。

为了解决这个问题 Java19 引入了虚拟线程(Virtual Thread)。在 Java19 中,之前我们常用的线程叫做平台线程(platform thread),与系统内核线程仍然是一一对应的。其中大量(M)的虚拟线程在较小数量(N)的平台线程(与操作系统线程一一对应)上运行(M:N 调度)。多个虚拟线程会被 JVM 调度到某一个平台线程上执行,一个平台线程同时只会执行一个虚拟线程。
创建 Java 虚拟线程
新增线程相关 API
Thread.ofVirtual() 和 Thread.ofPlatform() 是创建虚拟和平台线程的新 API:
//输出线程ID 包括虚拟线程和系统线程 Thread.getId() 从jdk19废弃
Runnable runnable = () -> System.out.println(Thread.currentThread().threadId());
//创建虚拟线程
Thread thread = Thread.ofVirtual().name("testVT").unstarted(runnable);
testVT.start();
//创建虚平台线程
Thread testPT = Thread.ofPlatform().name("testPT").unstarted(runnable);
testPT.start();
使用 Thread.startVirtualThread(Runnable) 快速创建虚拟线程并启动:
//输出线程ID 包括虚拟线程和系统线程
Runnable runnable = () -> System.out.println(Thread.currentThread().threadId());
Thread thread = Thread.startVirtualThread(runnable);
Thread.isVirtual() 判断线程是否为虚拟线程:
//输出线程ID 包括虚拟线程和系统线程
Runnable runnable = () -> System.out.println(Thread.currentThread().isVirtual());
Thread thread = Thread.startVirtualThread(runnable);
Thread.join 和 Thread.sleep 等待虚拟线程结束、使虚拟线程 sleep:
Runnable runnable = () -> System.out.println(Thread.sleep(10));
Thread thread = Thread.startVirtualThread(runnable);
//等待虚拟线程结束
thread.join();
Executors.newVirtualThreadPerTaskExecutor() 创建一个 ExecutorService,该 ExecutorService 为每个任务创建一个新的虚拟线程:
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
executor.submit(() -> System.out.println("hello"));
}
支持与使用线程池和 ExecutorService 的现有代码互相替换、迁移。
注意:
因为虚拟线程在 Java19 中是预览特性,所以本文出现的代码需按以下方式运行:
- 使用
javac --release 19 --enable-preview Main.java编译程序,并使用java --enable-preview Main运行; - 或者使用
java --source 19 --enable-preview Main.java运行程序;
是骡子是马
既然是为了解决平台线程的问题,那我们就直接测试平台线程与虚拟线程的性能。
测试内容很简单,并行执行一万个 sleep 一秒的任务,对比总的执行时间和所用系统线程数量。
为了监控测试所用系统线程的数量,编写如下代码:
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
scheduledExecutorService.scheduleAtFixedRate(() -> {
ThreadMXBean threadBean = ManagementFactory.getThreadMXBean();
ThreadInfo[] threadInfo = threadBean.dumpAllThreads(false, false);
System.out.println(threadInfo.length + " os thread");
}, 1, 1, TimeUnit.SECONDS);
调度线程池每一秒钟获取并打印系统线程数量,便于观察线程的数量。
public static void main(String[] args) {
//记录系统线程数
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
scheduledExecutorService.scheduleAtFixedRate(() -> {
ThreadMXBean threadBean = ManagementFactory.getThreadMXBean();
ThreadInfo[] threadInfo = threadBean.dumpAllThreads(false, false);
System.out.println(threadInfo.length + " os thread");
}, 1, 1, TimeUnit.SECONDS);
long l = System.currentTimeMillis();
try(var executor = Executors.newCachedThreadPool()) {
IntStream.range(0, 10000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
System.out.println(i);
return i;
});
});
}
System.out.printf("耗时:%d ms", System.currentTimeMillis() - l);
}
首先我们使用 Executors.newCachedThreadPool() 来执行 10000 个任务,因为 newCachedThreadPool 的最大线程数量是 Integer.MAX_VALUE,所以理论上至少会创建大几千个系统线程来执行。
输出如下(多余输出已省略):
//output
1
7142
3914 os thread
Exception in thread "main" java.lang.OutOfMemoryError: unable to create native thread: possibly out of memory or process/resource limits reached
at java.base/java.lang.Thread.start0(Native Method)
at java.base/java.lang.Thread.start(Thread.java:1560)
at java.base/java.lang.System$2.start(System.java:2526)
从上述输出可以看到,最高创建了 3914 个系统线程,然后继续创建线程时异常,程序终止。我们想通过大量系统线程提高系统的性能是不现实的,因为线程昂贵,资源有限。
现在我们使用固定大小为 200 的线程池来解决不能申请太多系统线程的问题:
public static void main(String[] args) {
//记录系统线程数
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
scheduledExecutorService.scheduleAtFixedRate(() -> {
ThreadMXBean threadBean = ManagementFactory.getThreadMXBean();
ThreadInfo[] threadInfo = threadBean.dumpAllThreads(false, false);
System.out.println(threadInfo.length + " os thread");
}, 1, 1, TimeUnit.SECONDS);
long l = System.currentTimeMillis();
try(var executor = Executors.newFixedThreadPool(200)) {
IntStream.range(0, 10000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
System.out.println(i);
return i;
});
});
}
System.out.printf("耗时:%dms
", System.currentTimeMillis() - l);
}
输出如下:
//output
1
9987
9998
207 os thread
耗时:50436ms
使用固定大小线程池后没有了创建大量系统线程导致失败的问题,能正常跑完任务,最高创建了 207 个系统线程,共耗时 50436ms。
再来看看使用虚拟线程的结果:
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
scheduledExecutorService.scheduleAtFixedRate(() -> {
ThreadMXBean threadBean = ManagementFactory.getThreadMXBean();
ThreadInfo[] threadInfo = threadBean.dumpAllThreads(false, false);
System.out.println(threadInfo.length + " os thread");
}, 10, 10, TimeUnit.MILLISECONDS);
long l = System.currentTimeMillis();
try(var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
System.out.println(i);
return i;
});
});
}
System.out.printf("耗时:%dms
", System.currentTimeMillis() - l);
}
使用虚拟线程的代码和使用固定大小的只有一词只差,将 Executors.newFixedThreadPool(200) 替换为 Executors.newVirtualThreadPerTaskExecutor()。
输出结果如下:
//output
1
9890
15 os thread
耗时:1582ms
由输出可见,执行总耗时 1582 ms,最高使用系统线程 15 个。结论很明显,使用虚拟线程比平台线程要快很多,并且使用的系统线程资源要更少。
如果我们把刚刚这个测试程序中的任务换成执行了一秒钟的计算(例如,对一个巨大的数组进行排序),而不仅仅是 sleep 1 秒钟,即使我们把虚拟线程或者平台线程的数量增加到远远大于处理器内核数量都不会有明显的性能提升。因为虚拟线程不是更快的线程,它们运行代码的速度与平台线程相比并无优势。虚拟线程的存在是为了提供更高的吞吐量,而不是速度(更低的延迟)。
如果你的应用程序符合下面两点特征,使用虚拟线程可以显著提高程序吞吐量:
- 程序并发任务数量很高。
- IO 密集型、工作负载不受 CPU 约束。
虚拟线程有助于提高服务端应用程序的吞吐量,因为此类应用程序有大量并发,而且这些任务通常会有大量的 IO 等待。
Java vs Go
使用方式对比
Go 协程对比 Java 虚拟线程
定义一个 say () 方法,方法体是循环 sleep 100ms,然后输出 index,将这个方法使用协程执行。
Go 实现:
package main
import (
"fmt"
"time"
)
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
func main() {
go say("world")
say("hello")
}
Java 实现:
public final class VirtualThreads {
static void say(String s) {
try {
for (int i = 0; i < 5; i++) {
Thread.sleep(Duration.ofMillis(100));
System.out.println(s);
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws InterruptedException {
var worldThread = Thread.startVirtualThread(
() -> say("world")
);
say("hello");
// 等待虚拟线程结束
worldThread.join();
}
}
可以看到两种语言协程的写法很相似,总体来说 Java 虚拟线程的写法稍微麻烦一点,Go 使用一个关键字就能方便的创建协程。
Go 管道对比 Java 阻塞队列
在 Go 语言编程中,协程与管道的配合相得益彰,使用协程计算数组元素的和(分治思想):
Go 实现:
package main
import "fmt"
func sum(s []int, c chan int) {
sum := 0
for _, v := range s {
sum += v
}
c <- sum // send sum to c
}
func main() {
s := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(s[:len(s)/2], c)
go sum(s[len(s)/2:], c)
x, y := <-c, <-c // receive from c
fmt.Println(x, y, x+y)
}
Java 实现:
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.Executors;
public class main4 {
static void sum(int[] s, int start, int end, BlockingQueue<Integer> queue) throws InterruptedException {
int sum = 0;
for (int i = start; i < end; i++) {
sum += s[i];
}
queue.put(sum);
}
public static void main(String[] args) throws InterruptedException {
int[] s = {7, 2, 8, -9, 4, 0};
var queue = new ArrayBlockingQueue<Integer>(1);
Thread.startVirtualThread(() -> {
sum(s, 0, s.length / 2, queue);
});
Thread.startVirtualThread(() -> {
sum(s, s.length / 2, s.length, queue);
});
int x = queue.take();
int y = queue.take();
System.out.printf("%d %d %d
", x, y, x + y);
}
}
因为 Java 中没有数组切片,所以使用数组和下标来代替。Java 中没有管道,用与管道相似的 BlockingQueue 来代替,可以实现功能。
协程实现原理对比
GO G-M-P 模型
Go 语言采用两级线程模型,协程与系统内核线程是 M:N 的,这一点与 Java 虚拟线程一致。最终 goroutine 还是会交给 OS 线程执行,但是需要一个中介,提供上下文。这就是 G-M-P 模型。
-
G: goroutine, 类似进程控制块,保存栈,状态,id,函数等信息。G 只有绑定到 P 才可以被调度。
-
M: machine, 系统线程,绑定有效的 P 之后,进行调度。
-
P: 逻辑处理器,保存各种队列 G。对于 G 而言,P 就是 cpu 核心。对于 M 而言,P 就是上下文。
-
sched: 调度程序,保存 GRQ(全局运行队列),M 空闲队列,P 空闲队列以及 lock 等信息。

队列
Go 调度器有两个不同的运行队列:
- GRQ,全局运行队列,尚未分配给 P 的 G(在 Go1.1 之前只有 GRO 全局运行队列,但是因为全局队列加锁的性能问题加上了 LRQ,以减少锁等待)。
- LRQ,本地运行队列,每个 P 都有一个 LRQ,用于管理分配给 P 执行的 G。当 LRQ 中没有待执行的 G 时会从 GRQ 中获取。
hand off 机制
当 G 执行阻塞操作时,G-M-P 为了防止阻塞 M,影响 LRQ 中其他 G 的执行,会调度空闲 M 来执行阻塞 M LRQ 中的其他 G:
- G1 在 M1 上运行,P 的 LRQ 有其他 3 个 G;
- G1 进行同步调用,阻塞 M;
- 调度器将 M1 与 P 分离,此时 M1 下只运行 G1,没有 P。
- 将 P 与空闲 M2 绑定,M2 从 LRQ 选择其他 G 运行。
- G1 结束堵塞操作,移回 LRQ。M1 会被放置到空闲队列中备用。
work stealing 机制
G-M-P 为了最大限度释放硬件性能,当 M 空闲时会使用任务窃取机制执行其他等待执行的 G:
- 有两个 P,P1,P2。
- 如果 P1 的 G 都执行完了,LRQ 为空,P1 就开始任务窃取。
- 第一种情况,P1 从 GRQ 获取 G。
- 第二种情况,P1 从 GRQ 没有获取到 G,则 P1 从 P2 LRQ 中窃取 G。
hand off 机制是防止 M 阻塞,任务窃取是防止 M 空闲。
Java 虚拟线程调度
基于操作系统线程实现的平台线程,JDK 依赖于操作系统中的线程调度程序来进行调度。而对于虚拟线程,JDK 有自己的调度器。JDK 的调度器没有直接将虚拟线程分配给系统线程,而是将虚拟线程分配给平台线程(这是前面提到的虚拟线程的 M:N 调度)。平台线程由操作系统的线程调度系统调度。
JDK 的虚拟线程调度器是一个在 FIFO 模式下运行的类似 ForkJoinPool 的线程池。调度器的并行数量取决于调度器虚拟线程的平台线程数量。默认情况下是 CPU 可用核心数量,但可以使用系统属性 jdk.virtualThreadScheduler.parallelism 进行调整。注意,这里的 ForkJoinPool 与 ForkJoinPool.commonPool() 不同,ForkJoinPool.commonPool() 用于实现并行流,并在 LIFO 模式下运行。
ForkJoinPool 和 ExecutorService 的工作方式不同,ExecutorService 有一个等待队列来存储它的任务,其中的线程将接收并处理这些任务。而 ForkJoinPool 的每一个线程都有一个等待队列,当一个由线程运行的任务生成另一个任务时,该任务被添加到该线程的等待队列中,当我们运行 Parallel Stream,一个大任务划分成两个小任务时就会发生这种情况。
为了防止线程饥饿问题,当一个线程的等待队列中没有更多的任务时,ForkJoinPool 还实现了另一种模式,称为任务窃取, 也就是说:饥饿线程可以从另一个线程的等待队列中窃取一些任务。这和 Go G-M-P 模型中 work stealing 机制有异曲同工之妙。
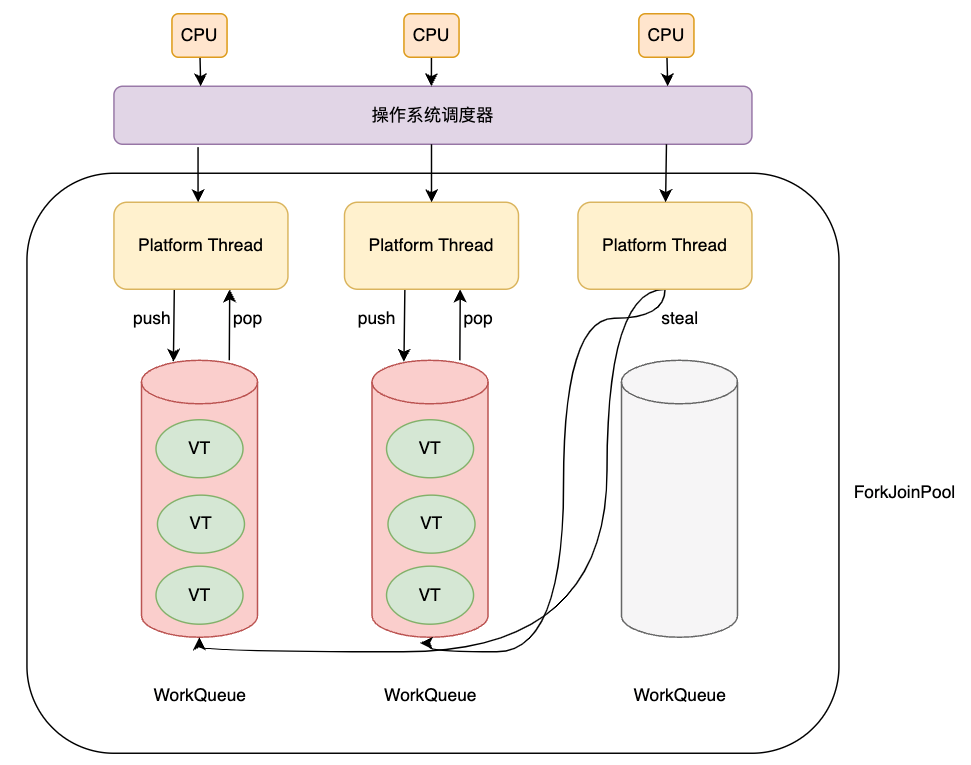
虚拟线程的执行
通常,当虚拟线程执行 I/O 或 JDK 中的其他阻止操作(如 BlockingQueue.take() 时,虚拟线程会从平台线程上卸载。当阻塞操作准备完成时(例如,网络 IO 已收到字节数据),调度程序将虚拟线程挂载到平台线程上以恢复执行。
JDK 中的绝大多数阻塞操作会将虚拟线程从平台线程上卸载,使平台线程能够执行其他工作任务。但是,JDK 中的少数阻塞操作不会卸载虚拟线程,因此会阻塞平台线程。因为操作系统级别(例如许多文件系统操作)或 JDK 级别(例如 Object.wait())的限制。这些阻塞操作阻塞平台线程时,将通过暂时增加平台线程的数量来补偿其他平台线程阻塞的损失。因此,调度器的 ForkJoinPool 中的平台线程数量可能会暂时超过 CPU 可用核心数量。调度器可用的平台线程的最大数量可以使用系统属性 jdk.virtualThreadScheduler.maxPoolSize 进行调整。这个阻塞补偿机制与 Go G-M-P 模型中 hand off 机制有异曲同工之妙。
在以下两种情况下,虚拟线程会被固定到运行它的平台线程,在阻塞操作期间无法卸载虚拟线程:
- 当在
synchronized块或方法中执行代码时。 - 当执行
native方法或 foreign function 时。
虚拟线程被固定不会影响程序运行的正确性,但它可能会影响系统的并发度和吞吐量。如果虚拟线程在被固定时执行 I/O 或 BlockingQueue.take() 等阻塞操作,则负责运行它的平台线程在操作期间会被阻塞。(如果虚拟线程没有被固定,那会执行 I/O 等阻塞操作时会从平台线程上卸载)
如何卸载虚拟线程
我们通过 Stream 创建 5 个未启动的虚拟线程,这些线程的任务是:打印当前线程,然后休眠 10 毫秒,然后再次打印线程。然后启动这些虚拟线程,并调用 jion() 以确保控制台可以看到所有内容:
public static void main(String[] args) throws Exception {
var threads = IntStream.range(0, 5).mapToObj(index -> Thread.ofVirtual().unstarted(() -> {
System.out.println(Thread.currentThread());
try {
Thread.sleep(10);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread());
})).toList();
threads.forEach(Thread::start);
for (Thread thread : threads) {
thread.join();
}
}
//output
src [main] ~/Downloads/jdk-19.jdk/Contents/Home/bin/java --enable-preview main7
VirtualThread[#23]/runnable@ForkJoinPool-1-worker-3
VirtualThread[#22]/runnable@ForkJoinPool-1-worker-2
VirtualThread[#21]/runnable@ForkJoinPool-1-worker-1
VirtualThread[#25]/runnable@ForkJoinPool-1-worker-5
VirtualThread[#24]/runnable@ForkJoinPool-1-worker-4
VirtualThread[#25]/runnable@ForkJoinPool-1-worker-3
VirtualThread[#24]/runnable@ForkJoinPool-1-worker-2
VirtualThread[#21]/runnable@ForkJoinPool-1-worker-4
VirtualThread[#22]/runnable@ForkJoinPool-1-worker-2
VirtualThread[#23]/runnable@ForkJoinPool-1-worker-3
由控制台输出,我们可以发现,VirtualThread [#21] 首先运行在 ForkJoinPool 的线程 1 上,当它从 sleep 中返回时,继续在线程 4 上运行。
sleep 之后为什么虚拟线程从一个平台线程跳转到另一个平台线程?
我们阅读一下 sleep 方法的源码,会发现在 Java19 中 sleep 方法被重写了,重写后的方法里还增加了虚拟线程相关的判断:
public static void sleep(long millis) throws InterruptedException {
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (currentThread() instanceof VirtualThread vthread) {
long nanos = MILLISECONDS.toNanos(millis);
vthread.sleepNanos(nanos);
return;
}
if (ThreadSleepEvent.isTurnedOn()) {
ThreadSleepEvent event = new ThreadSleepEvent();
try {
event.time = MILLISECONDS.toNanos(millis);
event.begin();
sleep0(millis);
} finally {
event.commit();
}
} else {
sleep0(millis);
}
}
深追代码发现,虚拟线程 sleep 时真正调用的方法是 Continuation.yield:
@ChangesCurrentThread
private boolean yieldContinuation() {
boolean notifyJvmti = notifyJvmtiEvents;
// unmount
if (notifyJvmti) notifyJvmtiUnmountBegin(false);
unmount();
try {
return Continuation.yield(VTHREAD_SCOPE);
} finally {
// re-mount
mount();
if (notifyJvmti) notifyJvmtiMountEnd(false);
}
}
也就是说 Continuation.yield 会将当前虚拟线程的堆栈由平台线程的堆栈转移到 Java 堆内存,然后将其他就绪虚拟线程的堆栈由 Java 堆中拷贝到当前平台线程的堆栈中继续执行。执行 IO 或 BlockingQueue.take() 等阻塞操作时会跟 sleep 一样导致虚拟线程切换。虚拟线程的切换也是一个相对耗时的操作,但是与平台线程的上下文切换相比,还是轻量很多的。
其他
虚拟线程与异步编程
响应式编程解决了平台线程需要阻塞等待其他系统响应的问题。使用异步 API 不会阻塞等待响应,而是通过回调通知结果。当响应到达时,JVM 将从线程池中分配另一个线程来处理响应。这样,处理单个异步请求会涉及多个线程。
在异步编程中,我们可以降低系统的响应延迟,但由于硬件限制,平台线程的数量仍然有限,因此我们的系统吞吐量仍有瓶颈。另一个问题是,异步程序在不同的线程中执行,很难调试或分析它们。
虚拟线程通过较小的语法调整来提高代码质量(降低编码、调试、分析代码的难度),同时具有响应式编程的优点,能大幅提高系统吞吐量。
不要池化虚拟线程
因为虚拟线程非常轻量,每个虚拟线程都打算在其生命周期内只运行单个任务,所以没有池化虚拟线程的必要。
虚拟线程下的 ThreadLocal
public class main {
private static ThreadLocal<String> stringThreadLocal = new ThreadLocal<>();
public static void getThreadLocal(String val) {
stringThreadLocal.set(val);
System.out.println(stringThreadLocal.get());
}
public static void main(String[] args) throws InterruptedException {
Thread testVT1 = Thread.ofVirtual().name("testVT1").unstarted(() ->main5.getThreadLocal("testVT1 local var"));
Thread testVT2 = Thread.ofVirtual().name("testVT2").unstarted(() ->main5.getThreadLocal("testVT2 local var"));
testVT1.start();
testVT2.start();
System.out.println(stringThreadLocal.get());
stringThreadLocal.set("main local var");
System.out.println(stringThreadLocal.get());
testVT1.join();
testVT2.join();
}
}
//output
null
main local var
testVT1 local var
testVT2 local var
虚拟线程支持 ThreadLocal 的方式与平台线程相同,平台线程不能获取到虚拟线程设置的变量,虚拟线程也不能获取到平台线程设置的变量,对虚拟线程而言,负责运行虚拟线程的平台线程是透明的。但是由于虚拟线程可以创建数百万个,在虚拟线程中使用 ThreadLocal 请三思而后行。如果我们在应用程序中创建一百万个虚拟线程,那么将会有一百万个 ThreadLocal 实例以及它们引用的数据。大量的对象可能会给内存带来较大的负担。
使用 ReentrantLock 替换 Synchronized
因为 Synchronized 会使虚拟线程被固定在平台线程上,导致阻塞操作不会卸载虚拟线程,影响程序的吞吐量,所以需要使用 ReentrantLock 替换 Synchronized:
befor:
public synchronized void m() {
try {
// ... access resource
} finally {
//
}
}
after:
private final ReentrantLock lock = new ReentrantLock();
public void m() {
lock.lock(); // block until condition holds
try {
// ... access resource
} finally {
lock.unlock();
}
}
如何迁移
-
直接替换线程池为虚拟线程池。如果你的项目使用了
CompletableFuture你也可以直接替换执行异步任务的线程池为Executors.newVirtualThreadPerTaskExecutor()。 -
取消池化机制。虚拟线程非常轻量级,无需池化。
-
synchronized改为ReentrantLock,以减少虚拟线程被固定到平台线程。
总结
本文描述了 Java 线程模型、Java 虚拟线程的使用、原理以及适用场景,也与风靡的 Go 协程做了比较,也能找到两种实现上的相似之处,希望能帮助你理解 Java 虚拟线程。Java19 虚拟线程是预览特性,很有可能在 Java21 成为正式特性,未来可期。笔者水平有限,如有写的不好的地方还请大家批评指正。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结