您现在的位置是:首页 >技术交流 >【C++】CUDA期末复习指南下(详细)网站首页技术交流
【C++】CUDA期末复习指南下(详细)
🍎 博客主页:🌙@披星戴月的贾维斯
🍎 欢迎关注:👍点赞🍃收藏🔥留言
🍇系列专栏:🌙 C/C++专栏
🌙请不要相信胜利就像山坡上的蒲公英一样唾手可得,但是请相信,世界上总有一些美好值得我们全力以赴,哪怕粉身碎骨!🌙
🍉一起加油,去追寻、去成为更好的自己!

文章目录
提示:以下是本篇文章正文内容,下面案例可供参考
前言
上期CUDA期末复习指南我们主要讲了GPU的串行/并行以及一些背诵的知识点,这篇博客我们继续介绍cuda的函数以及cuda编程,常考的CUDA函数和编程题博主在这里为大家总结一下,希望对大家有所帮助。
🍎1、cuda常考函数
在上一节我们已经讲到了cudaFreeHost这个函数,是用来释放固定主机内存的。我们直接承接上一篇的内容
8. cudaSetDevice
cudaSetDevice 函数用于设置当前线程要使用的 CUDA 设备。它的函数原型为
cudaError_t cudaSetDevice (
int device
);
其中, device 参数表示要使用的 CUDA 设备的编号,编号从 0 开始。
使用方法如下代码:
int main()
{
int device = 0;
cudaSetDevice(device);
return 0;
}
- cudaDeviceReset(这个函数用得较少)
cudaDeviceReset 是 CUDA 运行时 API 中的一个函数,用于重置当前设备的状态。该函数执行后,会清除当前设备上的所有运行时状态,并释放所有与该设备有关的资源。它的函数原型为:
cudaError_t cudaDeviceReset(void); // 该函数不接受任何参数
- cudaHostAlloc
cudaHostAlloc 是 CUDA 中用于在主机(Host)上分配内存的函数。与普通的 malloc 或 new不同,通过 cudaHostAlloc 分配的主机内存可以与设备(Device)之间进行零拷贝(Zerocopy)操作,这意味着可以在主机和设备之间非常高效地共享数据。它的函数原型为:
cudaError_t cudaHostAlloc(
void **ptr,
size_t size,
unsigned int flags
);
其中, ptr 为分配的内存的指针所存放的地址; size :分配的内存的大小,以字节为单位;flags :分配内存的标志,可以是以下任意组合:
cudaHostAllocDefault :默认标志,表示按照系统的最佳准则分配主机内存。
cudaHostAllocPortable :可以在不同 CUDA 设备之间交换的可移植内存。
cudaHostAllocMapped :将主机内存映射到设备内存,以实现零拷贝操作。
cudaHostAllocWriteCombined :对写缓冲区进行优化的内存,用于使用
cudaMemcpyAsync 在主机和设备之间高效地复制内存。
使用方法如下代码:
int main()
{
int n = 1024;
float *data;
HANDLE_ERROR( cudaHostAlloc((void**)&data, n * sizeof(float),
cudaHostAllocMapped) );
// ... 使用 data 在主机和设备之间进行零拷贝操作 ...
cudaFreeHost(data);
return 0;
}
- cudaHostGetDevicePointer
cudaHostGetDevicePointer 函数是 CUDA 主机内存和设备内存之间数据传输的重要函数之一。
该函数的作用是将主机内存指针映射到设备内存地址空间中,并返回设备内存的指针。这样,就可
以在主机内存和设备内存之间直接传递数据,从而避免了在主机内存和设备内存之间复制数据的开
销,提高了程序运行效率。它的函数原型为:
cudaError_t cudaHostGetDevicePointer(
void **pDevice,
void *pHost,
unsigned int flags // 此处需要被置为0
);
其中, pDevice 是指向设备内存指针的指针; pHost 是主机内存指针; flags 是标志位,用于控制映射的行为。
与 cudaHostAlloc 搭配使用方法如下:
int main()
{
float *h_ptr, *d_ptr;
size_t size = N * sizeof(float);
// 分配 CUDA 主机内存
HANDLE_ERROR( cudaHostAlloc(&h_ptr, size, cudaHostAllocDefault) );
// 在设备上分配内存
HANDLE_ERROR( cudaMalloc((void**)&d_ptr, size) );
// 映射设备内存
HANDLE_ERROR( cudaHostGetDevicePointer(&d_ptr, h_ptr, 0) );
// 将数据从主机内存复制到设备内存
HANDLE_ERROR( cudaMemcpy(d_ptr, h_ptr, size, cudaMemcpyHostToDevice) );
// 对设备上的数据进行操作
SomeKernel<<<(N+255)/256, 256>>>(d_ptr, N);
// 将数据从设备内存复制到主机内存
HANDLE_ERROR( cudaMemcpy(h_ptr, d_ptr, size, cudaMemcpyDeviceToHost) );
// 释放内存
HANDLE_ERROR( cudaFree(d_ptr) );
HANDLE_ERROR( cudaFreeHost(h_ptr) );
return 0;
}
- cudaGetErrorString
cudaGetErrorString 是一个 CUDA 函数,它可以将 CUDA 错误码转换为可读字符串,方便开发者调试和查错。它的函数原型为:
cudaError_t cudaGetErrorString(
cudaError_t error,
const char **pStr);
其中, error 为要转换为字符串的 CUDA 错误码; **pStr 为指向指针的指针,用于存储转换后的字符串。用法如下:
使用方法如下:
cudaError_t err = cudaMalloc(&devPtr, size);
if (err != cudaSuccess)
{
printf("CUDA error: %s
", cudaGetErrorString(err));
}
- cudaMemcpyToSymbol
cudaMemcpyToSymbol 将 count 个字节从 src 指向的内存复制到 symbol 指向的内存中,这个变量存放在设备的 全局内存或常量内存中。
使用方法如下:
__constant__ Sphere s[SPHERES]; // 在全局处定义
int main()
{
Sphere *temp_s = (Sphere*)malloc( sizeof(Sphere) * SPHERES);
// 在局部动态拷贝
HANDLE_ERROR( cudaMemcpyToSymbol( s, temp_s, sizeof(Sphere) * SPHERES));
return 0;
}
- cudaEventCreate(重点)
cudaEventCreate 是一个CUDA运行时API函数,用于创建CUDA事件。CUDA事件可以被用于测量GPU程序的执行时间、在异步操作间同步数据等。它的函数原型为:
cudaError_t cudaEventCreate (
cudaEvent_t* event
);
其中, event 是一个指向 cudaEvent_t 类型对象的指针。
使用方法如下:
int main()
{
cudaEvent_t start, stop;
cudaEventcreate(&start);
cudaEventcreate(&stop);
}
- cudaEventRecord
cudaEventRecord 是一个 CUDA 运行时函数,用于记录一个调用 cudaEventCreate 创建的CUDA 事件的时间点。通常情况下,它用作测量时间间隔或异步操作的同步。 - cudaEventSynchronize、
cudaEventSynchronize 函数用于等待一个事件完成,并阻塞当前主机线程,直到该事件完成为止。它接收一个事件作为参数,并会一直等待该事件完成,直到可以安全地使用该事件依赖的所有CUDA 内存和其他资源。 - cudaEventElapsedTime
cudaEventElapsedTime 函数用于计算两个事件记录的时间间隔,该函数返回两个事件之间的时间间隔(以毫秒为单位)。 - cudaEventDestroy
cudaEventDestroy 函数用于销毁一个 CUDA 事件对象,释放与之关联的资源。
使用方法如下:
int main()
{
cudaEvent_t start, stop;
HANDLE_ERROR( cudaEventCreate(&start) );
HANDLE_ERROR( cudaEventCreate(&stop) );
// 记录开始时间点
HANDLE_ERROR( cudaEventRecord(start, 0) );
// 执行核函数
myKernel <<< gridSize, blockSize>>>(...);
// 记录结束时间点
HANDLE_ERROR( cudaEventRecord(stop, 0) );
// 等待GPU操作完成
HANDLE_ERROR( cudaEventSynchronize(stop) );
float elapsedTime;
// 计算两个时间点之间经过的时间间隔
HANDLE_ERROR( cudaEventElapsedTime(&elapsedTime, start, stop) );
printf("Execution time: %f ms
", elapsedTime);
// 销毁已经创建的事件对象
HANDLE_ERROR( cudaEventDestroy(start) );
HANDLE_ERROR( cudaEventDestroy(stop) );
return 0;
}
- atomicAdd
atomicAdd 是 CUDA 提供的一种原子操作函数,用于在 GPU 全局内存中进行原子加操作。它的、作用是确保在并发情况下,对该内存地址执行原子加操作,以避免数据争用的问题,使得并发访问的结果能够正确累加。
🍎2、CUDA编程
🍇一个典型的CUDA程序的基本框架
1、头文件包含
2、常量定义
3、C++自定义函数和CUDA核函数声明
4、int main (void)
{
定义主机和设备变量/数组。
分配主机和设备内存
初始化主机中的数据
将某些数据从主机复制到设备
调用核函数在设备中计算
将计算结果从设备中拷贝回主机变量/数组。
释放主机/设备内存
}
C++自定义函数和CUDA核函数实现(定义)
🍇简单的CUDA加法
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
//定义global类型的函数
__global__ void add(int *const c, int const a, int const b)
{
*c = a + b;
}
int main ()
{
int c;
int *dev_c;
//申请显存
cudaMalloc((void**)&dev_c, sizeof(int));
//调用核函数
add<<<1, 1 >>>add(dev_c, 2, 7);
//把在dev_c的结果拷贝回cpu变量c中
cudaMemcpy(&c, dev_c, sizeof(int), cudaMemcpyDeviceToHost);
printf("%d
", c);
//释放显存
cudaFree(dev_c);
return 0;
}
🍇获取计算机线程块的分配
一个简短内核程序输出线程块、线程、线程束和线程全局标号到屏幕上,了解线程块的分配。
#include<stdio.h>
#include<stdlib.h>
__global__ void what_is_my_id(unsigned int* const block, unsigned int* const thread,
unsigned int* const warp, unsigned int* const calc_thread){
const unsigned int thread_idx = blockIdx.x * blockDim.x + threadIdx.x;
//其中这个thread_idx是当前线程的坐标
block[thread_idx] = blockIdx.x;//当前线程位于的线程块
thread[thread_idx] = threadIdx.x;//当前线程的索引
warp[thread_idx] = threadIdx.x / warpSize;//当前线程的宽度
calc_thread[thread_idx] = thread_idx;//当前线程在整个网格中的索引
}
#define ARRAY_SIZE 128
#define ARRAY_SIZE_IN_BYTES (sizeof(unsigned int) * (ARRAY_SIZE))
unsigned int cpu_block[ARRAY_SIZE];
unsigned int cpu_thread[ARRAY_SIZE];
unsigned int cpu_warp[ARRAY_SIZE];
unsigned int cpu_calc_thread[ARRAY_SIZE];
int main ()
{
//确定调用核函数的多少
const unsigned int num_blocks = 2;
const unsigned int num_threads = 64;
//定义gpu线程块数组
unsigned int* gpu_block;
unsigned int* gpu_thread;
unsigned int* gpu_warp;
unsigned int* gpu_calc_thread;
//申请显存
cudaMalloc((void **)&gpu_block, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_thread, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_warp, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_calc_thread, ARRAY_SIZE_IN_BYTES);
//调用核函数
what_is_my_id<<<num_blocks, num_threads>>>(gpu_block, gpu_thread,gpu_warp,gpu_calc_thread);
//再把显存内容拷贝回cpu的数组
cudaMemcpy(cpu_block, gpu_block,ARRAY_SIZE_IN_BYTES,cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_thread, gpu_thread,ARRAY_SIZE_IN_BYTES,cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_warp, gpu_warp,ARRAY_SIZE_IN_BYTES,cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_calc_thread, gpu_calc_thread,ARRAY_SIZE_IN_BYTES,cudaMemcpyDeviceToHost);
//释放指针
cudaFree(gpu_block);
cudaFree(gpu_thread);
cudaFree(gpu_warp);
cudaFree(gpu_calc_thread);
//打印数据
for(int i = 0; u < ARRAY_SIZE; i++)
{
printf("calculated Thread % 3u - Block:" ....)
}
return 0;
}
🍇在GPU任意长度的矢量求和
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
#define N (65536 * 128 * 10)
__global__ void add(int* a, int *b, int *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
while(tid < N)
{
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x;//加一个步长
//这样我们就能从当前线程跳到下一个线程执行c[tid] = a[tid] + b[tid];这个操作
}
}
int main (void)
{
int *a, *b, *c;
int *dev_a, *dev_b, *dev_c;
//申请内存
a = (int*)malloc(N * sizeof(int));
b = (int*)malloc(N * sizeof(int));
c = (int*)malloc(N * sizeof(int));
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_c, N * sizeof(int)));
//初始化a 和 b数组
for(int i = 0; i < N; i ++)
{
a[i] = i;
b[i] = 2 * i;
}
//先拷贝a和b数组的内容到显存
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice));
//调用核函数
add<<<128, 128>>>(dev_a, dev_b, dev_c);
//把答案放回c数组
HANDLE_ERROR(cudaMemcpy(c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost));
//输出答案
bool success = true;
for(int i = 0; i < N; i++)
{
if(a[i] + b[i] != c[i])
{
success = false;
printf("error %d + %d != %d", a[i], b[i], c[i]);
}
}
if(success) printf("we did it");
//释放空间
HANDLE_ERROR(cudaFree(dev_a));
HANDLE_ERROR(cudaFree(dev_a));
HANDLE_ERROR(cudaFree(dev_a));
free(a);
free(b);
free(c);
return 0;
}
🍇点积运算
矢量的点积运算(Dot Product,也称为内积)。这个计算包含两个步骤。首先把两个输入矢量中相应的元素相乘,类似矩阵加法,不过使用的乘法操作。其次把计算出来的值相加起来得到一个标量输出值(单个数值)。
(x1,x2,x3,x4)·(y1,y2,y3,y4) = x1y1+x2y2+x3y3+x4y4
先像矢量加法那样,每个线程将两个相应的元素相乘,每个线程保存计算的乘积的求和。
代码示例:
#include"../common/book.h"
#define imin (a,b) (a < b ? a:b)
const int N = 33 * 1024;
const int threadsPerblock = 256; //一个线程块内的最大线程数量
const int blocksPerGrid = imin(32, (N +threadsPerblock - 1) / threadsPerblock);
__global__ void dot(float *a, float *b, float * c)
{
__shared__ float cache[threadsPerblock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx;//缓存的索引被线程的索引赋值
float temp = 0;
//每个线程中计算的所有乘积结果累加,
//最后设置了共享内存缓冲区相应位置上的值为累加结果
while(tid < N){
temp += a[tid] * b[tid];
//递增步长
tid += blockDim.x * gridDim.x;//tid是跳到下一个线程块的同一个位置
}
cache[cacheIndex] = temp;
__syncthreads();
int i = blockDim.x / 2; // i等于一个线程块内的线程数/2, =128
//基本思想是,每个线程将cache[]中的两个值相加,结果保存回cache[]。
//由于每个线程都将两个值合并成一个值,得到结果数量就减半。
//下一个循环,只需要之前一半个数的线程。、
//这种操作执行log2(threadsPerBlock)步骤后,就能够得到cache中的总和。
while(i != 0){
if(cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
//最后一个线程块所有线程的求和结果放在了cacheIndex==0的位置,
//因此只需要cacheIndex==0的线程把这个线程块求和结果保存到c这个数组变量中去。
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
}
int main ()
{
int *a, *b, *partial_c;
int *dev_a, *dev_b, *dev_c;
a = (int*)malloc(N * sizeof(int));
b = (int*)malloc(N * sizeof(int));
partial_c = (int*)malloc(N * sizeof(int));
cudaMalloc((void**)&dev_a, N * sizeof (int));
cudaMalloc((void**)&dev_b, N * sizeof (int));
cudaMalloc((void**)&dev_b, N * sizeof (int));
for(int i = 0; i < 32 * 256; i++)
{
a[i] = i;
b[i] = 2 * i;
}
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice));
dot<<<blocksPerGrid, threadsPerBlock>>>(dev_a, dev_b, dev_c);
HANDLE_ERROR(cudaMemcpy(partial_c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost));
int c = 0;
for(int i = 0; i < blocksPerGrid; i++){
c += partial_c[i];
}
printf("%d
", c);
HANDLE_ERROR(cudaFree(dev_a));
HANDLE_ERROR(cudaFree(dev_b));
HANDLE_ERROR(cudaFree(dev_c));
free(a);
free(b);
free(partial_c);
return 0;
}
🍇常量内存光线跟踪
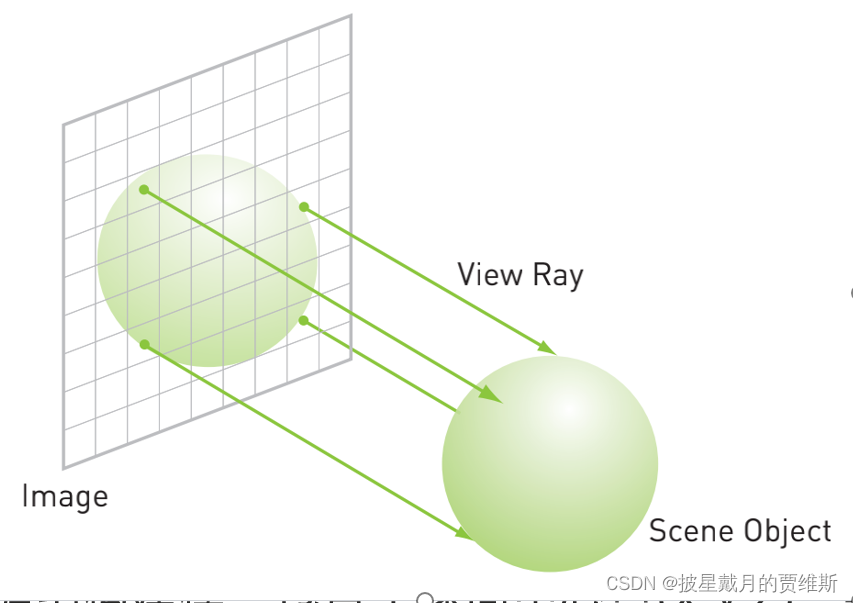
以光线跟踪为例,从三维对象场景中生产二维图像的一种方式。需要判断图像中的每个像素的颜色和强度。
一组包含球状物体的场景,从每个像素发射一道光线,跟踪这些光线会命中哪些球面,当一道光线穿过多个球面时,只有最接近的球面才有机会被看到。
对球面进行数据结构建模,包含了球面中心点(x,y,z),半径radius,颜色值(r,g,b)
代码示例:
#include"cuad.h"
#include"../common/book.h"
#include"../common/cpu_bitmap.h"
#define Dim 1024
#define rnd(x) (x * rand() / RAND_MAX)
#define INF 2e10f
struct Sphere{
float r, g, b;//颜色值(r,g,b)
float radius; //球的半径
float x, y, z;//球面中心点(x,y,z)
//(ox,oy)像素的光线
__device__ float hit(float ox, float oy, float * n){
float dx = ox - x;
float dy = oy - y;
if(dx * dx + dy * dy < radius * radius){
float dz = sqrtf(radius * radius - dx* dx - dy * dy);
*n = dz / sqrtf(radius * radius);
return dz + z;
}
return -INF;
}
};
//使用全局变量 s
//初始化球面变量数组s
struct DataBlock{
unsigned char *dev_bitmap;
Sphere *s;
};
int main()
{
DataBlock data;
//记录起始时间
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
CPUBitmap bitmap(DIM, DIM, &data);
unsigned char *dev_bitmap;
Sphere *s;
//在GPU上分配内存以计算输出位图
cudaMalloc((void **)&dev_bitmap, bitmap.image_size());
//为Sphere数据集分配内存
cudaMalloc((void **)&s, sizeof(Sphere)*SPHERES);
//在CPU上分配Shpere的临时内存,对其初始化,并复制到GPU内存中,然后释放CPU的临时内存
Sphere *temp_s = (Sphere *)malloc(sizeof(Sphere)*SPHERES);
for (int i = 0; i < SPHERES; i++)
{
temp_s[i].r = rnd(1.0f);
temp_s[i].g = rnd(1.0f);
temp_s[i].b = rnd(1.0f);
temp_s[i].x = rnd(1000.0f) - 500;
temp_s[i].y = rnd(1000.0f) - 500;
temp_s[i].z = rnd(1000.0f) - 500;
temp_s[i].radius = rnd(100.0f) + 20;
}
cudaMemcpy(s, temp_s, sizeof(Sphere)*SPHERES, cudaMemcpyHostToDevice);
free(temp_s);
//从球面数据中生成一张位图,这个没有教
//dim3 grids(DIM / 16, DIM / 16);
//dim3 blocks(16, 16);
//kernal << <grids, blocks >> >(s,dev_bitmap);
//将位图从GPU复制到CPU中
//cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost);
// get stop time, and display the timing results
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime,start, stop);
printf("Time to generate: %3.1f ms
", elapsedTime);
cudaEventDestroy(start);
cudaEventDestroy(stop);
//释放GPU内存
cudaFree(dev_bitmap);
cudaFree(s);
//显示
bitmap.display_and_exit();
return 0;
}
🍇GPU使用一维纹理内存的热传导模拟计算
#include "cuda.h"
#include "book.h"
#define DIM 1024
#define SPEED 0.25f
#define PI 3.1415926535897932f
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
//声明纹理内存变量的引用,这些变量将位于GPU上
texture<float> texConstSrc;
texture<float> texIn;
texture<float> texOut;
//更新函数中需要的全局变量
struct DataBlock
{
unsigned char *output_bitmap;
float *dev_inSrc;
float *dev_outSrc;
float *dev_constSrc;
CPUAnimBitmap *bitmap;
cudaEvent_t start, stop;
float totalTime;
float frames;
};
__global__ void copy_const_kernal(float *iptr)
{
//将threadIdx/blockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x*blockDim.x;
int y = threadIdx.y + blockIdx.y*blockDim.y;
int offset = x + y*blockDim.x*gridDim.x;
float c = tex1Dfetch(texConstSrc, offset);
if (c != 0)iptr[offset] = c;
}
__global__ void blend_kernal(float *dst, bool dstOut)
{
//将threadIdx/blockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x*blockDim.x;
int y = threadIdx.y + blockIdx.y*blockDim.y;
int offset = x + y*blockDim.x*gridDim.x;
int left = offset - 1;
int right = offset + 1;
if (x == 0)left++;
if (x == DIM - 1)right--;
int top = offset - DIM;
int bottom = offset + DIM;
if (y == 0)top += DIM;
if (y == DIM - 1)bottom -= DIM;
float t, b, l, r, c;
if (dstOut)
{
t = tex1Dfetch(texIn,top);
b = tex1Dfetch(texIn, bottom);
l = tex1Dfetch(texIn, left);
r = tex1Dfetch(texIn, right);
c = tex1Dfetch(texIn, offset);
}
else
{
t = tex1Dfetch(texOut, top);
b = tex1Dfetch(texOut, bottom);
l = tex1Dfetch(texOut, left);
r = tex1Dfetch(texOut, right);
c = tex1Dfetch(texOut, offset);
}
dst[offset] = c + SPEED*(t + b + l + r - 4 * c);
}
void anim_gpu(DataBlock *d, int ticks)
{
cudaEventRecord(d->start, 0);
dim3 grids(DIM / 16, DIM / 16);
dim3 blocks(16, 16);
CPUAnimBitmap *bitmap = d->bitmap;
//由于tex是全局并且是有界的,因此我们必须通过一个标志来来选择每次迭代中哪个是输入/输出
volatile bool dstOut = true;
for (int i = 0; i < 90; i++)
{
float *in, *out;
if (dstOut)
{
in = d->dev_inSrc;
out = d->dev_outSrc;
}
else
{
in = d->dev_outSrc;
out = d->dev_inSrc;
}
copy_const_kernal << <grids, blocks >> > (in);
blend_kernal << <grids, blocks >> > (out,dstOut);
dstOut = !dstOut;
}
//将float数值映射成颜色,以便用图像显示它
float_to_color << <grids, blocks >> >(d->output_bitmap, d->dev_inSrc);
cudaMemcpy(bitmap->get_ptr(), d->output_bitmap, bitmap->image_size(), cudaMemcpyDeviceToHost);
cudaEventRecord(d->stop, 0);
cudaEventSynchronize(d->stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, d->start, d->stop);
d->totalTime += elapsedTime;
++d->frames;
printf("Average Time per frame:%3.1fms
", d->totalTime / d->frames);
}
void anim_exit(DataBlock *d)
{
cudaUnbindTexture(texIn);
cudaUnbindTexture(texOut);
cudaUnbindTexture(texConstSrc);
cudaFree(d->dev_constSrc);
cudaFree(d->dev_inSrc);
cudaFree(d->dev_outSrc);
cudaEventDestroy(d->start);
cudaEventDestroy(d->stop);
}
🍇统计直方图(普通版本)
#include "../common/book.h"
#define Size (100*1024*1024)
int main()
{
unsigned char *buffer = (unsigned char*)big_random_block(Size);
clock_t start, stop;
start = clock();
unsigned int histo[256];
for(int i = 0; i < 256; i++)
histo[i] = 0;
for(int i = 0; i < Size; i++)
histo[buffer[i]]++;
stop = clock();
float elapsedTime = (float)(stop - start) / (float)CLOCKS_PER_SEC * 1000.0f;
printf("Time to generate: %3.lf ms
", elapsedTime);
long histoCount = 0;
for(int i = 0; i < 256; i++){
histoCount += histo[i];
}
printf("Histogram Sum: %ld
", histoCount);
free(buffer);
return 0;
}
🍇GPU原子递增操作统计直方图
代码示例:
#include "../common/book.h"
#define Size (100*1024*1024)
__global__ void histo_kernel(unsigned char *buffer,long size,unsigned int *histo){
int i = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
while(i < size){
atomicAdd(&histo[buffer[i]], 1);
i += stride;//步长
}
}
int main (void)
{
unsigned char *buffer = (unsigned char*)big_random_block(Size);
//捕获开始时间
//在这里启动计时器,这样我们就包括了
//所有的操作都在gpu下进行
cudaEvent_t start, stop;
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
HANDLE_ERROR(cudaEventRecord(start, 0));
//向gpu申请内存为文件数据
unsigned char *dev_buffer;
unsigned int *dev_histo;
HANDLE_ERROR(cudaMalloc((void**)&dev_buffer, Size));
HANDLE_ERROR(cudaMemcpy(dev_buffer, buffer, Size, cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMalloc((void**)&dev_histo, 256*sizeof(int)));
HANDLE_ERROR(cudaMemset(dev_histo, 0, 256*sizeof(int)));
cudaDeviceProp prop;
HANDLE_ERROR(cudaGetDeviceProperties(&prop, 0));
int blocks = prop.multiProcessorCount;
histo_kernel<<<blocks*2, 256>>>(dev_buffer, Size, dev_histo);
unsigned int histo[256];
HANDLE_ERROR(cudaMemcpy(histo, dev_histo, 256 * sizeof(int), cudaMemcpyDeviceToHost));
//获取终止时间
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
printf("Time to generate: %3.lf ms
", elapsedTime);
long histoCount = 0;
for(int i = 0; i < 256; i++){
histoCount += histo[i];
}
printf("Histogram Sum: %ld
", histoCount);
for(int i=0; i < Size; i++)
{
histo[buffer[i]]--;
}
for(int i = 0; i < 256; i++){
if(histo[i] != 0)
printf("Failure at %d! off by %d
", i, histo[i]);
}
HANDLE_ERROR(cudaEventDestroy(start));
HANDLE_ERROR(cudaEventDestroy(stop));
cudaFree(dev_histo);
cudaFree(dev_buffer);
free(buffer);
return 0;
}
🍎总结
本文总共总结多个常考的函数和编程题,希望对大家学习和复习CUDA有所帮助,感谢大家的支持,一起进步!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结