您现在的位置是:首页 >学无止境 >flink日志实时采集写入Kafka/ElasticSearch网站首页学无止境
flink日志实时采集写入Kafka/ElasticSearch
简介flink日志实时采集写入Kafka/ElasticSearch
背景
由于公司想要基于flink的日志做实时预警功能,故需要实时接入,并刷入es进行分析。
注意点
日志接入必须异步,不能影响服务性能
kafka集群宕机,依旧能够提交flink任务且运行任务
kafka集群挂起恢复,可以依旧续写实时运行日志
自定义Appender
在类上加上@Plugin注解,标记为自定义appender
@Plugin(name = "KafkaAppender", category = "Core", elementType = "appender", printObject = true)
public final class KafkaAppender extends AbstractAppender {}
在类加上@PluginFactory和@PluginAttribute来配合log4j.properties来传递参数
@PluginFactory
public static KafkaAppender createAppender(
/** 发送到的Topic */
@PluginAttribute("topic") String topic,
/** Kafka地址 */
@PluginAttribute("kafkaBroker") String kafkaBroker,
/** 设置的数据格式Layout */
@PluginElement("Layout") Layout<? extends Serializable> layout,
@PluginAttribute("name") String name,
@PluginAttribute("append") boolean append,
/** 日志等级 */
@PluginAttribute("level") String level,
/** 设置打印包含的包名,前缀匹配,逗号分隔多个 */
@PluginAttribute("includes") String includes,
/** 设置打印不包含的包名,前缀匹配,同时存在会被排除,逗号分隔多个 */
@PluginAttribute("excludes") String excludes) {
return new KafkaAppender(name, topic, kafkaBroker, null, layout, append, level, includes, excludes);
}
在append中对每一条日志进行处理
@Override
public void append(LogEvent event) {
if (event.getLevel().isMoreSpecificThan(this.level)) {
if (filterPackageName(event)) {
return;
}
try {
if (producer != null) {
CompletableFuture.runAsync(() -> {
producer.send(new ProducerRecord<String, String>(topic, getLayout().toSerializable(event).toString()));
}, executorService);
}
} catch (Exception e) {
LOGGER.error("Unable to write to kafka for appender [{}].", this.getName(), e);
LOGGER.error("Unable to write to kafka in appender: " + e.getMessage(), e);
} finally {
}
}
}
源码地址https://gitee.com/czshh0628/realtime-log-appender
log4j配置文件
日志接入kafka
在flink的conf目录的log4j.properties里添加如下配置
# 自定义的Kafka配置
rootLogger.appenderRef.kafka.ref=KafkaAppender
appender.kafka.type=KafkaAppender
appender.kafka.name=KafkaAppender
# 日志发送到的Topic
appender.kafka.topic=cdc
# Kafka Broker
appender.kafka.kafkaBroker=xxx:9092,xxx:9092
# kerberos认证
http://appender.kafka.keyTab=xxx
http://appender.kafka.principal=xxx
# 发送到Kafka日志等级
appender.kafka.level=info
# 过滤指定包名的文件
appender.kafka.includes=com.*,org.apache.hadoop.yarn.client.*,org.*
## kafka的输出的日志pattern
appender.kafka.layout.type=PatternLayout
appender.kafka.layout.pattern={"logFile":"${sys:log.file}","taskId":"${sys:taskId}","taskVersion":"${sys:taskVersion}","logTime":"%d{yyyy-MM-dd HH:mm:ss,SSS}","logMsg":"%-5p %-60c %x - %m","logThrow":"%throwable"}
日志接入elasticsearch
# 自定义的es的配置
rootLogger.appenderRef.es.ref=EsAppender
appender.es.type=EsAppender
appender.es.name=EsAppender
appender.es.hostname=bigdata
appender.es.port=9200
appender.es.index=flink_logs
appender.es.fetchSize=100
appender.es.fetchTime=5000
appender.es.level=info
appender.es.includes=com.*,org.apache.hadoop.yarn.client.*,org.*
appender.es.layout.type=PatternLayout
appender.es.layout.pattern={"logFile":"${sys:log.file}","taskId":"${sys:taskId}","taskVersion":"${sys:taskVersion}","logTime":"%d{yyyy-MM-dd'T'HH:mm:ss,SSS'Z'}","logMsg":"%-5p %-60c %x - %m","logThrow":"%throwable"}
启动脚本
bin/flink run -m yarn-cluster -p 1 -yjm 1024 -ytm 1024 -ys 1 -yD env.java.opts="-DtaskId=1000 -DtaskVersion=1.0" -c czs.study.flinkcdc.mysql.MySqlCdcStream test.jar
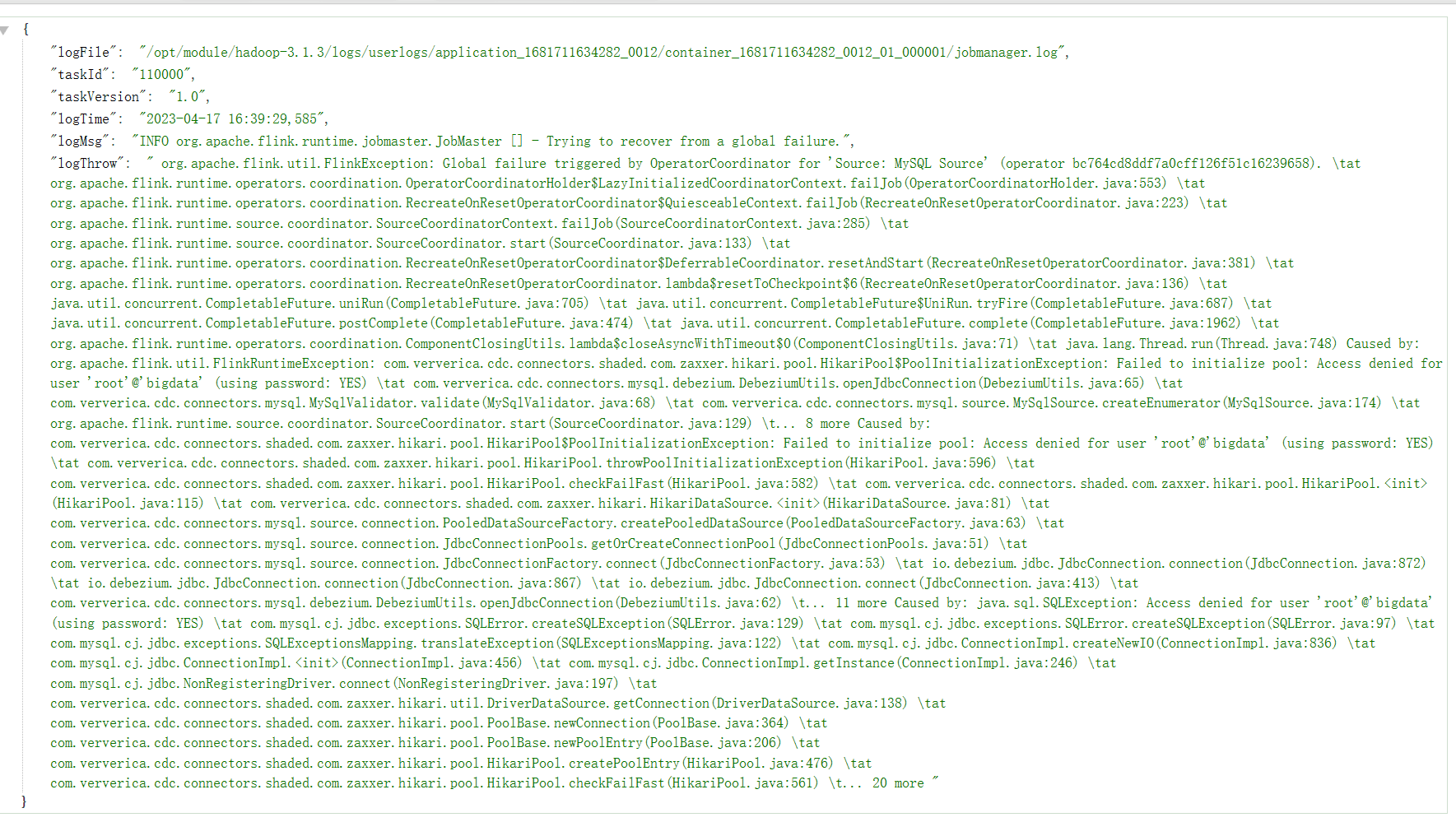
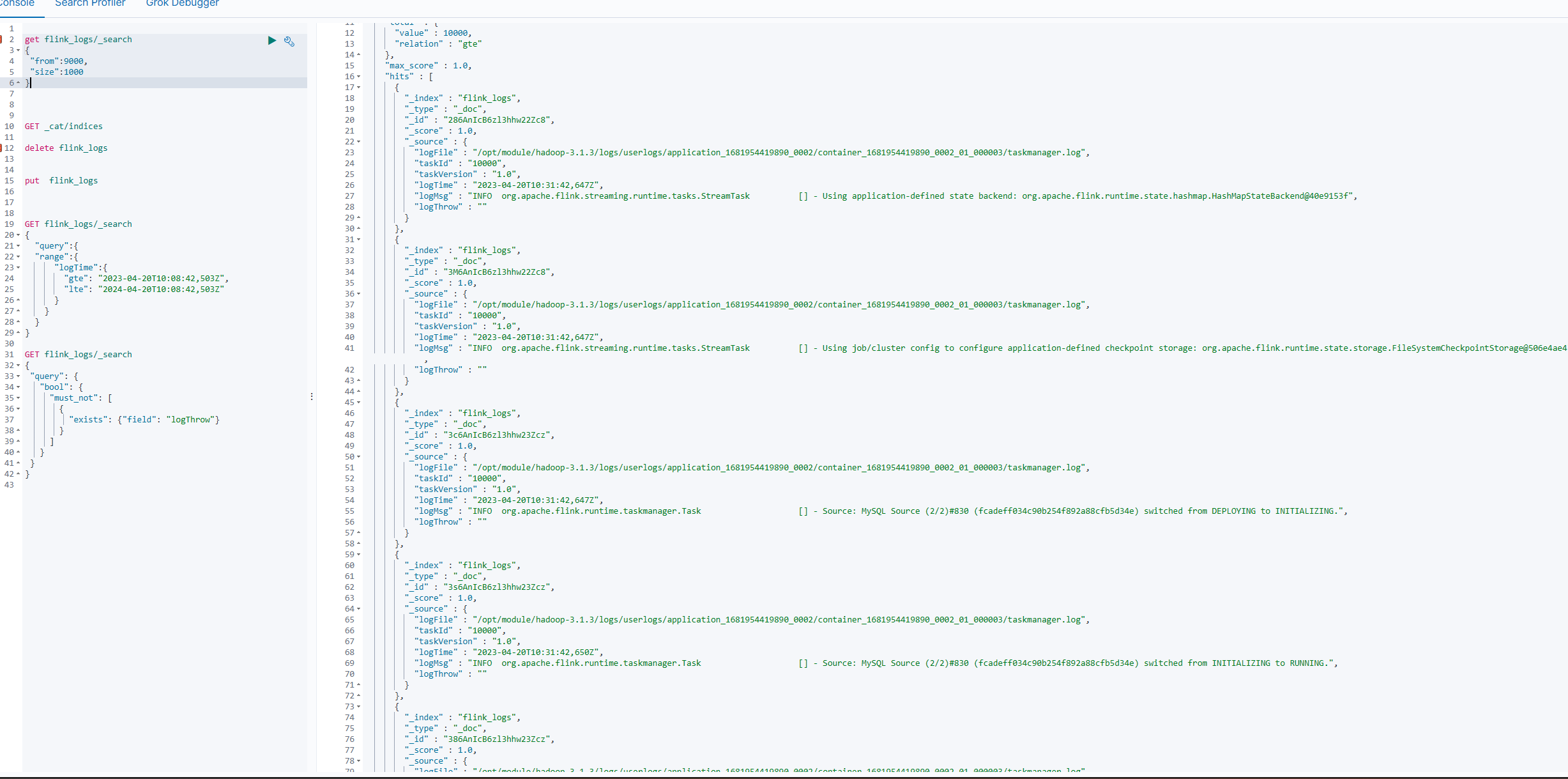
实现效果

风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结