您现在的位置是:首页 >技术教程 >Docker跨主机网络通信网站首页技术教程
Docker跨主机网络通信
常见的跨主机通信方案主要有以下几种:
| 形式 | 描述 |
|---|---|
| Host模式 | 容器直接使用宿主机的网络,这样天生就可以支持跨主机通信。这样方式虽然可以解决跨主机通信的问题,但应用场景很有限,容易出现端口冲突,也无法做到隔离网络环境,一个容器崩溃很可能引起整个宿主机的崩溃。 |
| 端口绑定 | 通过绑定容器端口到宿主机端口,跨主机通信时使用:主机IP:端口的方式访问容器中的服务。显然,这种方式仅能支持网络栈的4层及以上的应用,并且容器与宿主机紧耦合,很难灵活的处理问题,可扩展性不佳。 |
| 定义容器网络 | 使用Open vSwitch或Flannel等第三方SDN工具,为容器构建可以跨主机通信的网络环境。 这类方案一般要求各个主机上的Dockero网桥的cidr不同,以避免出现IP冲突的问题,限制容器在宿主机上可获取的IP范围。并且在容器需要对集群外提供服务时,需要比较复杂的配置,对部署实施人员的网络技能要求比较高。 |
容器网络发展到现在,形成了两大阵营:
Docker的CNMGoogle、Coreos、Kuberenetes主导的CNI
CNM和CNI是网络规范或者网络体系,并不是网络实现因此并不关心容器网络的实现方式( Flannel或者Calico等), CNM和CNI关心的只是网络管理
| 网络类型 | 描述 |
|---|---|
| CNM (Container Network Model) | CNM的优势在于原生,容器网络和Docker容器,生命周期结合紧密;缺点是被Docker “绑架”。支持CNM网络规范的容器网络实现包括:Docker Swarm、overlay、Macvlan & IP networkdrivers、 Calico、Contiv、 Weave等。 |
| CNI ( Container Network Interface) | CNI的优势是兼容其他容器技术(如rkt)及上层编排系统(Kubernetes&Mesos),而且社区活跃势头迅猛;缺点是非Docker原生。支持CNI网络规范的容器网络实现包括:Kubernetes、 Weave、Macvlan、Calico、Flannel、ContivMesos CNI等。 |
但从 网络实现角度,又可分为:
| 网络实现角度 | 描述 |
|---|---|
| 隧道方案 | 隧道方案在laas层的网络中应用也比较多,它的主要缺点是随着节点规模的增长复杂度会提升,而且出了网络问题后跟踪起来比较麻烦,大规模集群情况下这是需要考虑的一个问题。 |
| 路由方案 | 一般是基于3层或者2层实现网络隔离和跨主机容器互通的,出了问题也很容易排查。 Calico :基于BGP协议的路由方案,支持很细致的ACL控制,对混合云亲和度比较高。 Macvlan:从逻辑和Kernel层来看,是隔离性和性能最优的方案。基于二层隔离,所以需要一层路由器支持,大多数云服务商不支持,所以混合云上比较难以实现。 |
Docker主机之间容器通信解决方案:
- 桥接宿主机网络
- 端口映射
- docker网络驱动:
- 1、 Overlay:基于VXLAN封装实现Docker原生Overlay网络。
- 2、Macvlan:Docker主机网卡接口逻辑上分为多个子接口,每个子接口标识一个VLAN。容器接口直接连接Docker主机网卡接口,通过路由策略转发到另一台Docker主机。
第三方网络项目:
- 隧道方案:
- Flannel:支持UDP和VXLAN封装传输方式
- Weave:支持UDP(sleeve模式)和VXLAN(优先fastdp模式)
- OpenvSwitch:支持VXLAN和GRE协议
- 路由方案:
- Calico:支持BGP协议和IPIP隧道。每台宿主机作为虚拟路由,通过BGP协议实现不同主机容器间通信。
1、overlay网络模式
在早期的docker版本中,是不支持跨主机通信网络驱动的,也就是说如果容器部署在不同的节点(公网或局域网里不同的主机)上面,只能通过暴露端口到宿主机上,在通过宿主机之间进行通信。随着docker swarm集群的推广,docker有了自己的跨主机通信的网络驱动,名叫overlay,overlay网络模型是swarm集群容器通信的载体,将服务加入到同一个网段的overlay网络上,服务与服务之间就能够通信。所以,Overlay网络实际上是目前最主流的容器跨节点数据传输和路由方案。
内置跨主机的网络通信一直是Docker备受期待的功能,在1.9版本之前,社区中就已经有许多第三方的工具或方法尝试解决这个问题,例如Macvlan、Pipework、Flannel、Weave等。虽然这些方案在实现细节上存在很多差异,但其思路无非分为两种: 二层VLAN网络和Overlay网络
简单来说,二层VLAN网络解决跨主机通信的思路是把原先的网络架构改造为互通的大二层网络,通过特定网络设备直接路由,实现容器点到点的之间通信。这种方案在传输效率上比Overlay网络占优,然而它也存在一些固有的问题。这种方法需要二层网络设备支持,通用性和灵活性不如后者。由于通常交换机可用的VLAN数量都在4000个左右,这会对容器集群规模造成限制,远远不能满足公有云或大型私有云的部署需求; 大型数据中心部署VLAN,会导致任何一个VLAN的广播数据会在整个数据中心内泛滥,大量消耗网络带宽,带来维护的困难。相比之下,Overlay网络是指在不改变现有网络基础设施的前提下,通过某种约定通信协议,把二层报文封装在IP报文之上的新的数据格式。这样不但能够充分利用成熟的IP路由协议进程数据分发;而且在Overlay技术中采用扩展的隔离标识位数,能够突破VLAN的4000数量限制支持高达16M的用户,并在必要时可将广播流量转化为组播流量,避免广播数据泛滥。
因此,Overlay网络实际上是目前最主流的容器跨节点数据传输和路由方案。
按照实现原理即可分为直接路由方式、桥接方式(例如pipework)、Overlay隧道方式(如flannel、ovs+gre)等。
(1) 直接路由
通过在Docker主机上添加静态路由实现跨宿主机通信:

容器在两个跨主机进行通信的时候,是使用overlay network这个网络模式进行通信;如果使用host也可以实现跨主机进行通信,直接使用这个物理的ip地址就可以进行通信。overlay它会虚拟出一个网络比如10.0.2.3这个ip地址。在这个overlay网络模式里面,有一个类似于服务网关的地址,然后把这个包转发到物理服务器这个地址,最终通过路由和交换,到达另一个服务器的ip地址。
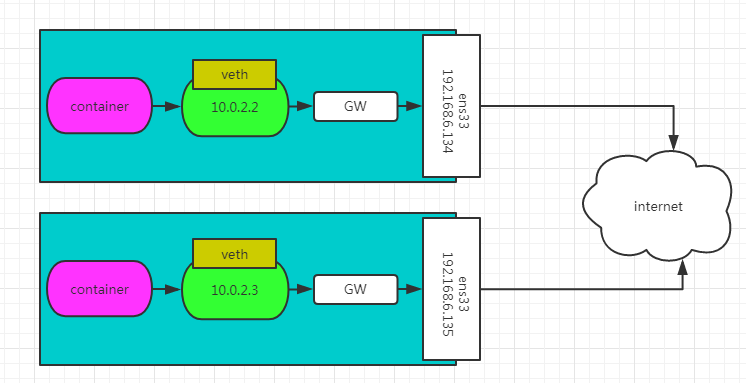
实验:
如下图所示,我们有两个物理主机1和主机2,我们在宿主机上启动一个centos容器,启动成功之后,两个容器分别运行在两个宿主机上,默认的IP地址分配如图所示。这也是docker自身的默认网络。
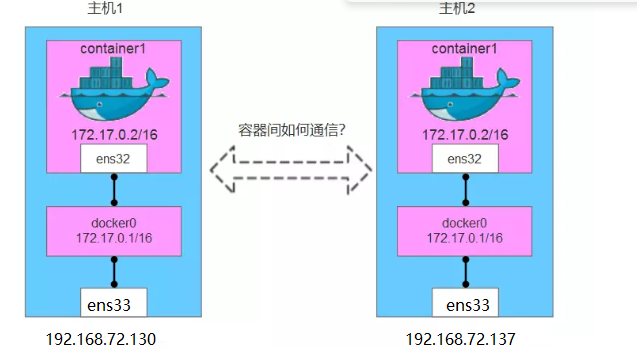
此时两台主机上的Docker容器可以通过各自主机中添加路由的方式来实现两个centos容器之间的通信。由于使用容器的IP进行路由,就需要便面不同主机上的容器使用相同的IP,为此我们应该为不同的主机分配不同的子网来保证。于是我们构造两个容器之间通信的路由方案:

各项配置如下:
-
主机1的IP地址为:192.168.72.130
-
主机2的IP地址为:192.168.72.137
-
为主机1上的Docker容器分配的子网:10.0.128.0/24
-
为主机2上的Docker容器分配的子网:10.0.129.0/24
这样配置之后,两恶搞主机山过的Docker容器就肯定不会使用相同的IP地址从而避免了IP冲突。之后我们需要定义路由规则: -
所有目的地址为10.0.128.0/24的包都被转发到主机1上
-
所有目的地址为10.0.129.0/24的包都被转发到主机2上
综上所述:数据包在两个容器间的通信过程如下:
从主机1的容器发往主机2的容器的数据包,首先发往container1的网关docker0,然后通过查找主机1的路由得知需要将数据包发给主机2,数据包到达主机2后再转发给主机2的docker0,最后将器数据包转发到container1里,反向原理相同。
实验环境:
| 操作系统 | 服务器地址 | container地址 |
|---|---|---|
| centos7 | 192.168.72.130 | 10.0.128.2 |
| centos7 | 192.168.91.137 | 10.0.129.2 |
由于docker默认的网关地址为172.17.0.0/24,我们需要配置两台主机的网段必须为10.0.128.2和10.0.129.2。有2种方式:
1) 将两台主机的ip地址改为静态ip地址
修改docker0的默认网段
修改方式有两种:
1、创建一个docker网桥
主机1:
[root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.72.130
NETMASK=255.255.255.0
GATEWAY=192.168.72.2
DNS1=114.114.114.114
:wq
[root@localhost ~]# systemctl restart network
主机2:
[root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.72.137
NETMASK=255.255.255.0
GATEWAY=192.168.72.2
DNS1=114.114.114.114
:wq
[root@localhost ~]# systemctl restart network2) 修改docker0的默认网段
修改方式有两种:
1、创建一个docker网桥
主机1:
docker network create --driver bridge --subnet 10.0.128.0/24 --gateway=10.0.128.1 mynetwork
主机2:
docker network create --driver bridge --subnet 10.0.129.0/24 --gateway=10.0.129.1 mynetwork2.修改docker0的网段(我们选用这种)
1、编辑 /etc/docker/daemon.json
主机1:
{
"bip":"10.0.128.1/24"
}
:wq
主机2:
{
"bip":"10.0.129.1/24"
}
2、将我们设置的参数生效并重启docker
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# systemctl start docker
3、查看两个主机的IP地址是否改变。
主机1:
[root@localhost ~]# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 10.0.128.1 netmask 255.255.255.0 broadcast 10.128.0.255
ether 02:42:3c:c9:45:0d txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
主机2:
[root@localhost ~]# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 10.0.129.1 netmask 255.255.255.0 broadcast 10.129.0.255
ether 02:42:e2:09:e3:ec txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 02) 添加路由规则
1.查看路由表
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.72.2 0.0.0.0 UG 100 0 0 ens33
10.128.0.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
192.168.72.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
默认只有自己本身的路由,如果需要访问10.0.129.0/24网段,需要添加路由。
2.添加路由规则
2.1.主机1添加路由规则
route add -net 10.0.129.0/24 gw 192.168.72.137
gw表示下一跳地址,这里的地址就是主机2的IP地址
2.2.主机2添加路由规则
route add -net 10.0.128.0/24 gw 192.168.72.130
2.3路由持久化(防止主机重启路由丢失)
vi /etc/rc.local
主机1:route add -net 10.0.129.0/24 gw 192.168.72.137
主机2:route add -net 10.0.128.0/24 gw 192.168.72.130
3.进行ping测试
主机1ping主机2
[root@localhost ~]# ping 10.0.129.1
PING 10.0.129.1 (10.0.129.1) 56(84) bytes of data.
64 bytes from 10.0.129.1: icmp_seq=1 ttl=64 time=0.852 ms
64 bytes from 10.0.129.1: icmp_seq=2 ttl=64 time=4.89 ms
64 bytes from 10.0.129.1: icmp_seq=3 ttl=64 time=1.28 ms
主机2ping主机1
[root@localhost ~]# ping 10.0.128.1
PING 10.0.128.1 (10.0.128.1) 56(84) bytes of data.
64 bytes from 10.0.128.1: icmp_seq=1 ttl=64 time=0.824 ms





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结