您现在的位置是:首页 >技术杂谈 >Linux环境:Ollama运行大模型和部署WebUI网站首页技术杂谈
Linux环境:Ollama运行大模型和部署WebUI
个人安装大模型经验总结
演示环境参考:腾讯云高性能服务器Linux
- Ubuntu 20.04
- Driver 525.105.17
- Python 3.8
- CUDA 12.0
- cuDNN 8
1.环境
1.1 Docker (需加速或镜像)
有些云服务器默认安装了docker,如果没有docker参考以下:
官网
wget -qO- https://get.docker.com/ | sh
或
curl -fsSL https://get.docker.com | sh
镜像加速参考:
Docker-hub: 🎉Docker镜像加速,Docker加速,国内Docker加速。 支持多种仓库加速。 最新!最全!多种方法! docker镜像
- 科大镜像:https://docker.mirrors.ustc.edu.cn/
- 网易:https://hub-mirror.c.163.com/
- 阿里云:https://<你的ID>.mirror.aliyuncs.com
- 七牛云加速器:https://reg-mirror.qiniu.com
1.2 anaconda(推荐)(可选)
安装conda(服务器使用Miniconda) Download Now | Anaconda
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh |sh
或
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh |sh
环境变量
echo 'export PATH="$HOME/miniconda3/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
2.安装ollama
2.1 Linux安装命令
curl -fsSL https://ollama.com/install.sh | sh
默认端口:
loclahost:11434
ubuntu@VM-0-11-ubuntu:~$ ollama
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
2.2 安装模型
ollama run deepseek-r1:14b
对话

2.3 放通端口
暂停服务
sudo systemctl stop ollama
修改
sudo nano /etc/systemd/system/ollama.service
在 [Service] 部分添加以下行:
Environment="OLLAMA_HOST=0.0.0.0:11434"
随后快捷键ctrl+X退出并保存 输入y确定 回车确定文件名
使 Ollama 监听所有网络的 11434 端口。
重启ollama
sudo systemctl daemon-reload
sudo systemctl start ollama
2.4 防火墙
sudo ufw allow 11434
同时服务器设置端口规则


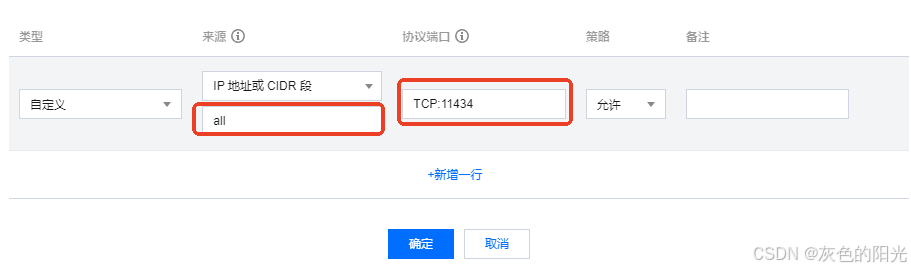
2.5 常驻服务 (可选)
ollama有keep_alive参数用来控制模型在内存中保留的时间。
keep_alive 参数可以设置为:
- 一个持续时间字符串(例如 “10m” 或 “24h”)
- 一个以秒为单位的数字(例如 3600)
- 任何负数,这将使模型无限期地保留在内存中(例如 -1 或 “-1m”)
- ‘0’ 这将使模型在生成响应后立即卸载
方法一:执行请求时设置 keep_alive 为 -1
curl http://localhost:11434/api/generate -d '{"model": "llama3", "keep_alive": -1}'
方法二:在 /etc/systemd/system/ollama.service 中加入 Environment="OLLAMA_KEEP_ALIVE=-1"
修改后执行命令:
sudo systemctl daemon-reload
sudo systemctl enable ollama
2.6 Ollama 安装和常用系统参数设置参考
- OLLAMA_MODELS:模型文件存放目录,默认目录为当前用户目录(Windows 目录:
C:Users%username%.ollamamodels,MacOS 目录:~/.ollama/models,Linux 目录:/usr/share/ollama/.ollama/models),如果是 Windows 系统建议修改(如:D:OllamaModels),避免 C 盘空间吃紧 - OLLAMA_HOST:Ollama 服务监听的网络地址,默认为127.0.0.1,如果允许其他电脑访问 Ollama(如:局域网中的其他电脑),建议设置成0.0.0.0,从而允许其他网络访问
- OLLAMA_PORT:Ollama 服务监听的默认端口,默认为11434,如果端口有冲突,可以修改设置成其他端口(如:8080等)
- OLLAMA_ORIGINS:HTTP 客户端请求来源,半角逗号分隔列表,若本地使用无严格要求,可以设置成星号,代表不受限制
- OLLAMA_KEEP_ALIVE:大模型加载到内存中后的存活时间,默认为5m即 5 分钟(如:纯数字如 300 代表 300 秒,0 代表处理请求响应后立即卸载模型,任何负数则表示一直存活);我们可设置成24h,即模型在内存中保持 24 小时,提高访问速度
- OLLAMA_NUM_PARALLEL:请求处理并发数量,默认为1,即单并发串行处理请求,可根据实际情况进行调整
- OLLAMA_MAX_QUEUE:请求队列长度,默认值为512,可以根据情况设置,超过队列长度请求被抛弃
- OLLAMA_DEBUG:输出 Debug 日志标识,应用研发阶段可以设置成1,即输出详细日志信息,便于排查问题
- OLLAMA_MAX_LOADED_MODELS:最多同时加载到内存中模型的数量,默认为1,即只能有 1 个模型在内存中
3.安装webui(例:MaxKB,Open WebUI)(需要docker)
3.1 MaxKB
官方配置:
# Linux 操作系统
sudo docker run -d --name=maxkb --restart=always -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages cr2.fit2cloud.com/1panel/maxkb
# Windows 操作系统
docker run -d --name=maxkb --restart=always -p 8080:8080 -v C:/maxkb:/var/lib/postgresql/data -v C:/python-packages:/opt/maxkb/app/sandbox/python-packages cr2.fit2cloud.com/1panel/maxkb
推荐配置: 添加 --add-host=host.docker.internal:host-gateway
优点:1. 使容器中的webui通过访问host.docker.internal直接访问宿主机的端口服务,防止因网络波动导致的回答中断。
2.在后面的配置中,webui使用http://host.docker.internal:11434/访问ollama,对于频繁更改ip的环境配置更友好。
sudo docker run -d --name=maxkb --add-host=host.docker.internal:host-gateway --restart=always -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages cr2.fit2cloud.com/1panel/maxkb
第一次连接设置密码
http://目标服务器 IP 地址:8080
默认登录信息
用户名:admin
默认密码:MaxKB@123..
放通端口
sudo ufw allow 8080
模型接入
系统管理–>模型设置–>添加模型–>Ollama
https://maxkb.cn/docs/user_manual/model/ollama_model/
3.2 Open WebUI
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Open WebUI 与 Ollama 捆绑在一起的单个容器映像
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
连接:
http://localhost:3000
4. 本地下载(部分模型需要注册申请使用)(备选)
4.1 huggingface
国外: huggingface.co
pip install -U huggingface_hub
国内镜像:HF-Mirror (推荐)
export HF_ENDPOINT=https://hf-mirror.com
或写入 ~/.bashrc
echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.bashrc
source ~/.bashrc
默认模型存放路径:用户主文件夹/.cache/huggingface
如:/home/ubuntu/.cache/huggingface
4.2 modelscope (推荐)
pip install modelscope
默认模型存放路径:用户主文件夹/.cache/modelscope
如:/home/ubuntu/.cache/modelscope
4.3 git-lfs
sudo apt install git-lfs
git lfs install
4.4 本地模型使用ollama
模型目录中创建Modelfile参考
FROM ./vicuna-33b.Q4_0.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|reserved_special_token"
ollama 创建模型
$ ollama create vicuna:33b -f Modelfile
$ ollama run vicuna:33b






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结