您现在的位置是:首页 >技术交流 >R分析|正负内聚力在R中的复现:跟着Nature系列文章学习如何评价群落中物种协作和竞争以及网络稳定性网站首页技术交流
R分析|正负内聚力在R中的复现:跟着Nature系列文章学习如何评价群落中物种协作和竞争以及网络稳定性
一、引言
微生物相互作用网络分析已成为微生物生态学研究的核心问题,评判微生物互作网络稳定性的方法很多,包括网络的复杂性(节点和连接数)、网络模块性、平均聚类距离等。此外,网络的内聚力指数也被用来评价微生物互作网络的稳定性。Cristina M Herren等人2017年在The ISME Journal 提出网络的内聚力之后,被Nature climate change, Nature ecology & evolution 和Nature communications, PNAS等多篇顶刊引用。现今已被研究者广泛接纳,并成为Nature系列文章用来评价微生物群落特征分析的重要组成部分。
二、文献美图欣赏
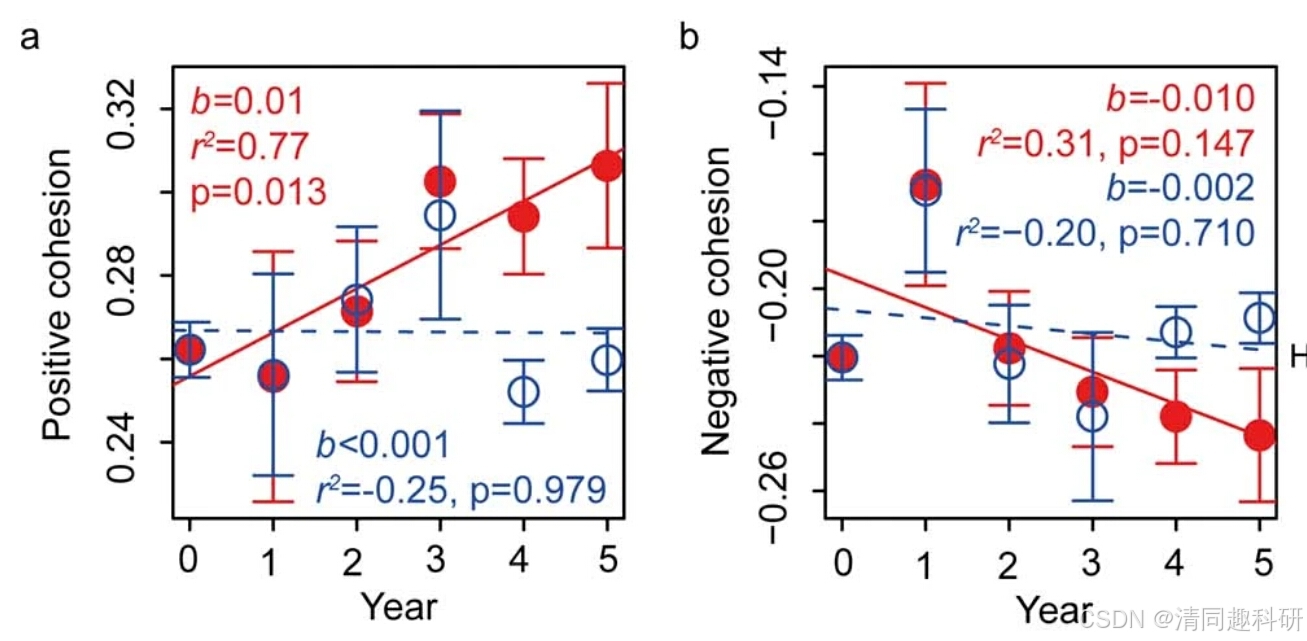
图片来源:Yuan, M.M. et al. Nat. Clim. Chang. 11, 343–348 (2021).
a, 群落正内聚力随时间的变化。b,群落负内聚力随时间的变化。在(a)和(b)中,实心红色圆圈和实线表示加热条件下的群落,空心蓝色圆圈和虚线表示对照条件下的群落。每个误差条对应于24个样本中的凝聚力标准差。
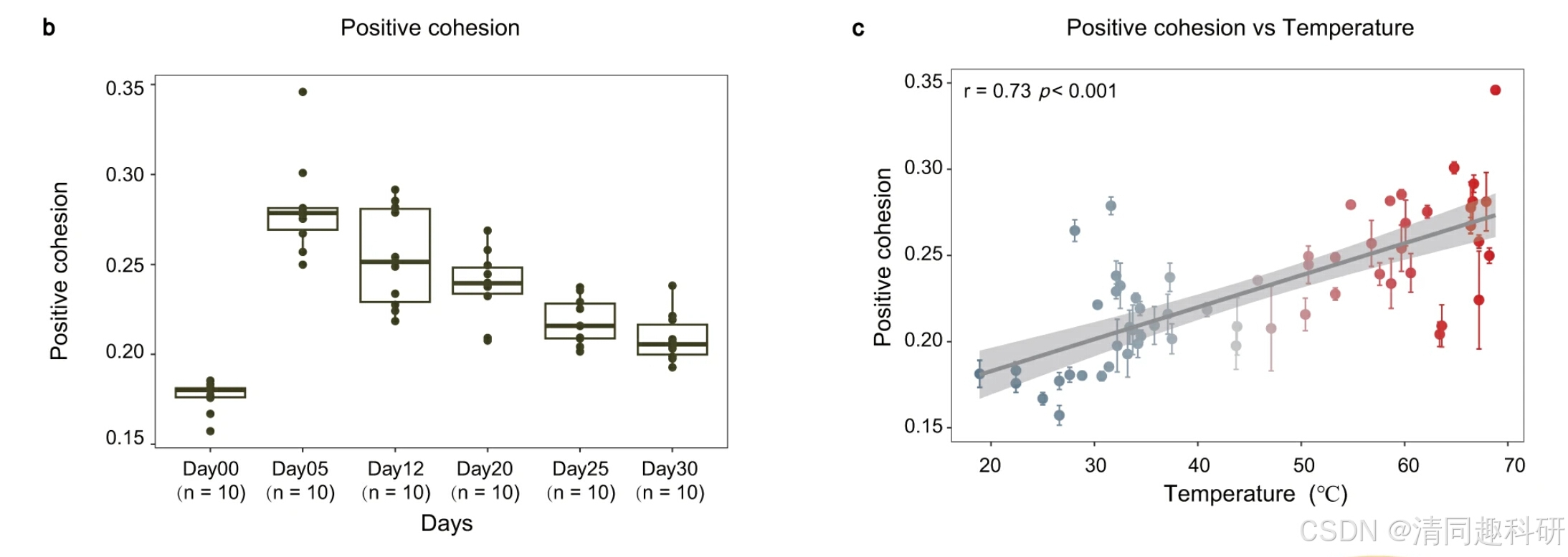
图片来源:Zhao, Y., et al. Nat Commun 14, 5394 (2023).
b 不同阶段正凝聚力的变化(每一天 n = 10 个生物独立样本)。c 正凝聚力与温度的关系(n = 60 个生物独立样本)。
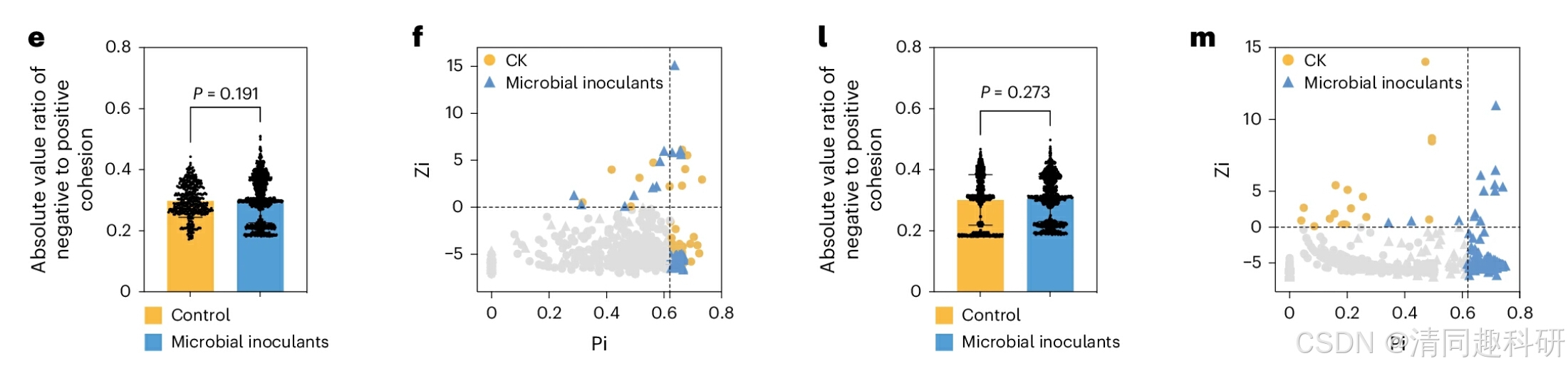
图片来源:Li, C., et al. Nat Ecol Evol 8, 1270–1284 (2024).
e, l,细菌共现网络的稳定性通过负凝聚力与正凝聚力的绝对值比率进行评估。
三、内聚力基本概念和算法基础
正内聚力(Positive cohesion)指的是微生物(网络节点)之间的协同/合作关系,其可能表现为资源共享、代谢产物的交叉喂养、共同的生境需求等。负内聚力(Negative cohesion)表现为微生物之间的竞争或抑制关系。在生物互作网络中,内聚力指数是按照物种丰度之间的显著正相关或负相关的总和进行计算:
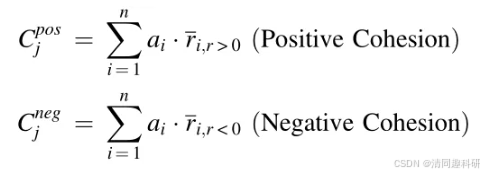
式中,ai为物种i在样本j中的丰度;Cjpos和Cjneg分别表示正、负凝聚力,物种i的正连通性(`ri,r>0)和负连通性(`ri,r<0)计算为其与网络中所有其它物种的所有显著正相关或负相关性的均值。负凝聚力和正凝聚力范围分别为[-1,0]和[0,1],绝对值越大表示相关性越强。
通过正内聚力和负内聚力可以计算微生物网络的稳定性 (Network stability)。
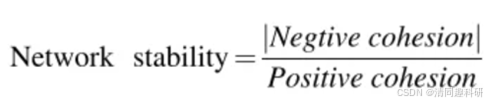
四、内聚力计算流程
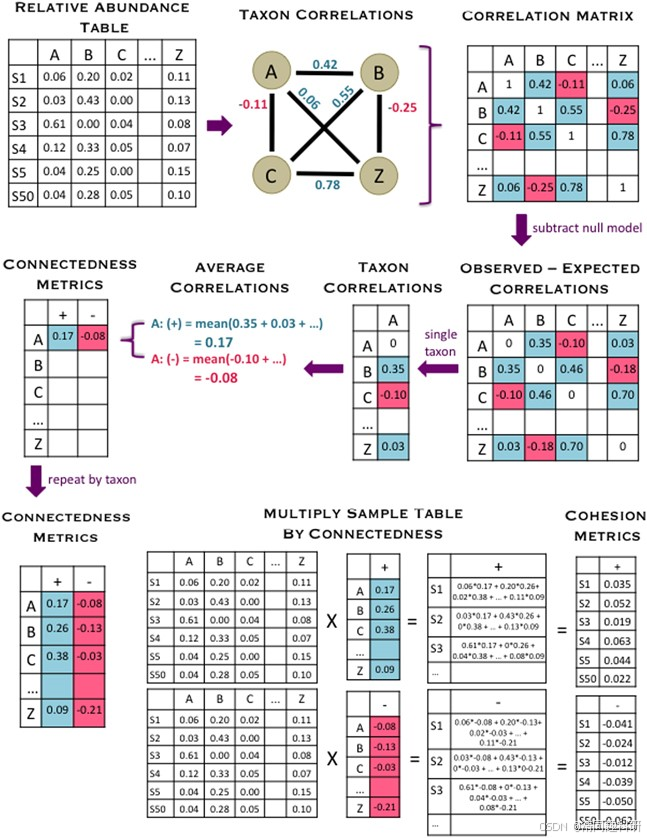
图片来源:Cristina M Herren, Katherine D McMahon, The ISME Journal, 11: 2426–2438 (2017).
该图展示了的内聚力指标计算的概述,过程从相对丰度表开始,最终得到内聚力值。相对丰度表显示了六个样本(S1 表示“样本 1”等)和一部分分类群(A、B、C 和 Z)。首先,计算所有分类群之间的成对相关性,并将其输入相关性矩阵。接着,我们使用一个虚拟模型来考虑微生物数据集的特征如何影响相关性,并从中减去这些值(。对于每个分类群,我们分别计算了修正后的正相关和负相关的平均值,并将这些值记录为正连接性和负连接性值。最终,通过将相对丰度表与连接性值相乘,获得了凝聚力值。因此,有两个对应于正值和负值的凝聚力指标。
五、示例数据和R代码
5.1 实例数据
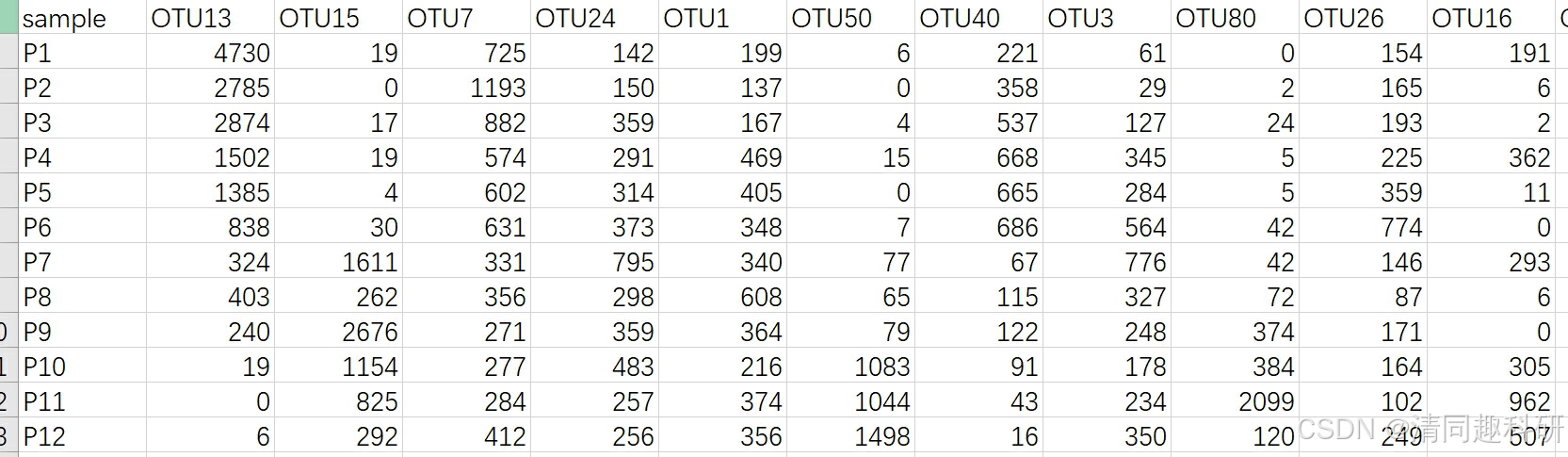
准备数据,只需要准备测序后获得的OTU(ASV表格)。data.csv
!!!注意,样本排列一定要按照下述格式,样本为行,物种为列
5.2 R代码
# 用户说明:将样本表(以绝对或相对丰度表示)读取为对象“b”。
# 如果使用自定义相关矩阵,请在指定的行读取该矩阵。
# 运行整个脚本,最后会为每个样本生成四个向量(两个连通度和两个内聚度)。
# 可调整的参数包括 pers.cutoff(保留分类的持续性阈值)、iter(虚拟模型的迭代次数)、tax.shuffle(是否使用分类洗牌或行洗牌随机化),
# 以及 use.custom.cors(是否使用预定的相关矩阵)
#清除所有变量
rm(list = ls())
#################### 创建必要的函数 ######################
# 计算向量中零的数量
zero <- function(vec){
num.zero <- length(which(vec == 0))
return(num.zero)
}
# 计算向量中负值的平均值
neg.mean <- function(vector){
neg.vals <- vector[which(vector < 0)]
n.mean <- mean(neg.vals)
if(length(neg.vals) == 0) n.mean <- 0
return(n.mean)
}
# 计算向量中正值的平均值
pos.mean <- function(vector){
pos.vals <- vector[which(vector > 0)]
p.mean <- mean(pos.vals)
if(length(pos.vals) == 0) p.mean <- 0
return(p.mean)
}
############## 工作流程选项 ########################
## 设置分类持续性阈值(最小存在比例),用于保留分析中的分类
pers.cutoff <- 0.10
## 设置虚拟模型的迭代次数(建议>=200)
iter <- 20
## 选择分类洗牌(tax.shuffle = T)或行洗牌(tax.shuffle = F)
tax.shuffle <- T
## 选择是否使用自定义相关矩阵
# 注意:您的相关性表必须与丰度表有相同数量的分类。丰度表中不应有空的(全零)分类向量。
# 即使您输入了自定义的相关性表,持续性阈值也会被应用
use.custom.cors <- F
########### 计算内聚力 ########################
# 读取数据集(每行是一个样本)
b <- read.csv("data.csv", header = T, row.names = 1)
# 若使用自定义相关矩阵,请读取并检查维度
if(use.custom.cors == T) {
custom.cor.mat <- read.csv("data.csv", header = T, row.names = 1)
custom.cor.mat <- as.matrix(custom.cor.mat)
print(dim(b)[2] == dim(custom.cor.mat)[2])
}
# 重新格式化数据,去除空样本和分类
c <- as.matrix(b)
c <- c[rowSums(c) > 0, colSums(c) > 0]
# 保存原始样本的总个体数
rowsums.orig <- rowSums(c)
# 根据持续性阈值确定分类零的数量阈值
zero.cutoff <- ceiling(pers.cutoff * dim(c)[1])
# 删除低于持续性阈值的分类
d <- c[ , apply(c, 2, zero) < (dim(c)[1]-zero.cutoff) ]
# 删除没有个体的样本
d <- d[rowSums(d) > 0, ]
# 如果使用自定义相关矩阵,更新相关矩阵
if(use.custom.cors == T){
custom.cor.mat.sub <- custom.cor.mat[apply(c, 2, zero) < (dim(c)[1]-zero.cutoff), apply(c, 2, zero) < (dim(c)[1]-zero.cutoff)]
}
# 创建相对丰度矩阵
rel.d <- d / rowsums.orig
# 查看保留的社区比例
hist(rowSums(rel.d))
# 计算观察到的相关矩阵
cor.mat.true <- cor(rel.d)
# 保存每个分类的中位数相关性
med.tax.cors <- vector()
# 计算虚拟模型的预期相关性
# 如果使用自定义相关矩阵,则跳过虚拟模型
if(use.custom.cors == F) {
if(tax.shuffle) {
for(which.taxon in 1:dim(rel.d)[2]){
# 保存每次置换的相关性
perm.cor.vec.mat <- vector()
for(i in 1:iter){
# 创建与 rel.d 维度相同的空矩阵
perm.rel.d <- matrix(numeric(0), dim(rel.d)[1], dim(rel.d)[2])
rownames(perm.rel.d) <- rownames(rel.d)
colnames(perm.rel.d) <- colnames(rel.d)
# 对每个分类进行洗牌
for(j in 1:dim(rel.d)[2]){
perm.rel.d[, j ] <- sample(rel.d[ ,j ])
}
# 保持焦点列不变
perm.rel.d[, which.taxon] <- rel.d[ , which.taxon]
# 计算置换矩阵的相关性矩阵
cor.mat.null <- cor(perm.rel.d)
# 保存焦点分类的相关性
perm.cor.vec.mat <- cbind(perm.cor.vec.mat, cor.mat.null[, which.taxon])
}
# 保存中位数相关性
med.tax.cors <- cbind(med.tax.cors, apply(perm.cor.vec.mat, 1, median))
if(which.taxon %% 20 == 0){print(which.taxon)}
}
} else {
for(which.taxon in 1:dim(rel.d)[2]){
# 保存每次置换的相关性
perm.cor.vec.mat <- vector()
for(i in 1:iter){
# 复制矩阵以进行丰度洗牌
perm.rel.d <- rel.d
# 对每个样本进行洗牌
for(j in 1:dim(rel.d)[1]){
which.replace <- which(rel.d[j, ] > 0 )
which.replace.nonfocal <- which.replace[!(which.replace %in% which.taxon)]
# 置换分类向量
perm.rel.d[j, which.replace.nonfocal] <- sample(rel.d[ j, which.replace.nonfocal])
}
# 计算置换矩阵的相关性矩阵
cor.mat.null <- cor(perm.rel.d)
# 保存焦点分类的相关性
perm.cor.vec.mat <- cbind(perm.cor.vec.mat, cor.mat.null[, which.taxon])
}
# 保存中位数相关性
med.tax.cors <- cbind(med.tax.cors, apply(perm.cor.vec.mat, 1, median))
if(which.taxon %% 20 == 0){print(which.taxon)}
}
}
}
# 计算观察到的减去预期的相关性
if(use.custom.cors == T) {
obs.exp.cors.mat <- custom.cor.mat.sub
} else {
obs.exp.cors.mat <- cor.mat.true - med.tax.cors
}
diag(obs.exp.cors.mat) <- 0
####
#### 生成连通度和内聚度向量
# 计算连通度(正负相关性平均值)
connectedness.pos <- apply(obs.exp.cors.mat, 2, pos.mean)
connectedness.neg <- apply(obs.exp.cors.mat, 2, neg.mean)
# 计算内聚度(相对丰度与连通度相乘)
cohesion.pos <- rel.d %*% connectedness.pos
cohesion.neg <- rel.d %*% connectedness.neg
####
#### 输出结果
output <- list(connectedness.neg, connectedness.pos, cohesion.neg, cohesion.pos)
names(output) <- c("Negative Connectedness", "Positive Connectedness", "Negative Cohesion", "Positive Cohesion")
print(output)
#####输出Connectedness数据矩阵############
# 提取要合并的矩阵或向量
connectedness_data <- list(
"Negative Connectedness" = output[["Negative Connectedness"]],
"Positive Connectedness" = output[["Positive Connectedness"]]
)
# 转换为数据框,并确保行数相同
connectedness_df <- as.data.frame(do.call(cbind, connectedness_data))
# 为每列设置名称
colnames(connectedness_df) <- names(connectedness_data)
# 写入 CSV 文件
write.csv(connectedness_df, file = "connectedness.csv", row.names = TRUE)
###############输出Cohesion数据###########
# 提取要合并的矩阵或向量
cohesion_data <- list(
"Negative Cohesion" = output[["Negative Cohesion"]],
"Positive Cohesion" = output[["Positive Cohesion"]]
)
# 转换为数据框,并确保行数相同
cohesion_df <- as.data.frame(do.call(cbind, cohesion_data))
# 为每列设置名称
colnames(cohesion_df) <- names(cohesion_data)
# 写入 CSV 文件
write.csv(cohesion_df, file = "cohesion.csv", row.names = TRUE)
输出结果
connectedness.csv 连通性表
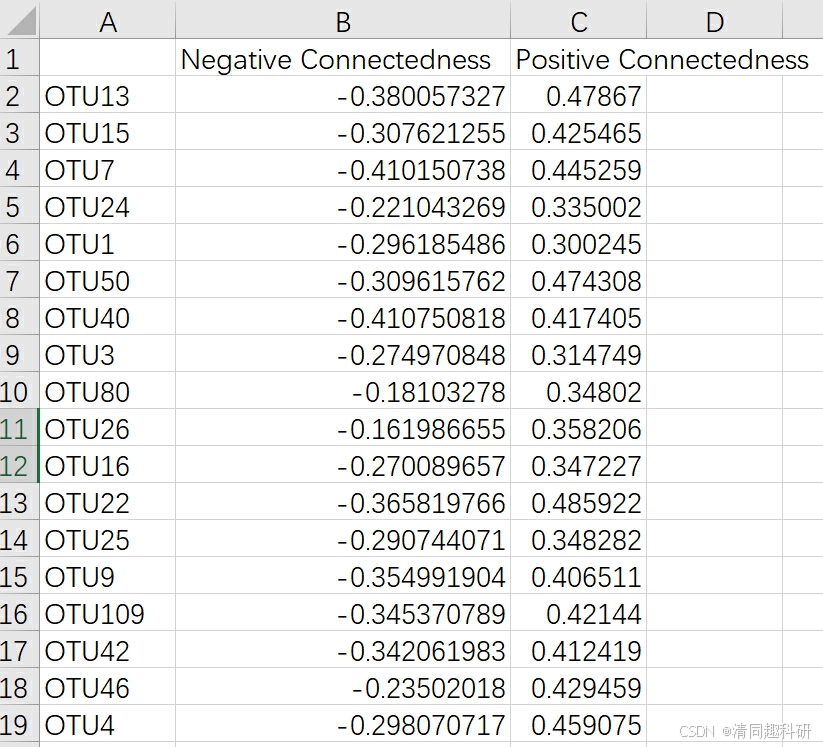
cohesion.csv 内聚力表
六、参考文献
Cristina M Herren, Katherine D McMahon, Cohesion: a method for quantifying the connectivity of microbial communities, The ISME Journal, Volume 11, Issue 11, November 2017, Pages 2426–2438,
Yuan, M.M., Guo, X., Wu, L. et al. Climate warming enhances microbial network complexity and stability. Nat. Clim. Chang. 11, 343–348 (2021).
Zhao, Y., Liu, Z., Zhang, B. et al. Inter-bacterial mutualism promoted by public goods in a system characterized by deterministic temperature variation. Nat Commun 14, 5394 (2023).
Li, C., Chen, X., Jia, Z. et al. Meta-analysis reveals the effects of microbial inoculants on the biomass and diversity of soil microbial communities. Nat Ecol Evol 8, 1270–1284 (2024).
七、相关信息
!!!本文内容由小编总结互联网和文献内容总结整理,如若侵权,联系立即删除!
!!!有需要的小伙伴评论区获取今天的测试代码和实例数据。
📌示例代码中提供了数据和代码,小编已经测试,可直接运行。
以上就是本节全部内容。
如果这篇文章对您有用,请帮忙一键三连(点赞、收藏、评论、分享),让该文章帮助到更多的小伙伴。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结