您现在的位置是:首页 >技术交流 >【AI论文】SynthDetoxM:现代大型语言模型(LLMs)是少样本并行去毒数据标注器网站首页技术交流
【AI论文】SynthDetoxM:现代大型语言模型(LLMs)是少样本并行去毒数据标注器
简介【AI论文】SynthDetoxM:现代大型语言模型(LLMs)是少样本并行去毒数据标注器
摘要:当前的多语言文本去毒方法因缺乏平行的多语言数据集而受到阻碍。在本文中,我们介绍了一种用于生成多语言平行去毒数据的管道。我们还推出了SynthDetoxM,这是一个手动收集和合成生成的多语言平行文本去毒数据集,包含德语、法语、西班牙语和俄语四种语言的16,000对高质量去毒句子对。这些数据来源于不同的毒性评估数据集,然后在少样本设置下,使用九个现代的开源大型语言模型(LLMs)进行重写。我们的实验表明,即使在数据有限的情况下,使用生成的合成数据集训练的模型性能也优于使用人工标注的MultiParaDetox数据集训练的模型。在少样本设置下,使用SynthDetoxM训练的模型表现优于所有评估的大型语言模型。我们公开了数据集和代码,以助力多语言文本去毒领域的进一步研究。Huggingface链接:Paper page ,论文链接:2502.06394
一、引言与背景
- 在线毒性问题的严重性:
- 随着社交网络和基于文本的互联网媒体的普及,在线毒性和仇恨言论问题日益凸显。这不仅为用户创造了不愉快的环境,还可能吓退广告商,进而影响这些平台的经济可行性(Saha et al., 2019; Fortuna and Nunes, 2018)。
- 毒性言论的示例包括侮辱、歧视、仇恨和攻击性语言,这些言论可能对个人和社会造成负面影响。
- 文本去毒的需求:
- 文本去毒是文本风格迁移(Text Style Transfer, TST)的一个子任务,旨在通过改写文本,在保留其原始意义的同时改变其毒性风格(Fu et al., 2018; Lai et al., 2021)。
- 尽管在单语言TST和去毒方面取得了显著进展,但多语言文本去毒仍然是一个亟待解决的问题,主要原因是缺乏跨语言的平行去毒数据以及无监督方法在跨语言设置中的性能不佳(Dementieva et al., 2023)。
- 研究动机:
- 人工或众包数据收集是一项具有挑战性且成本高昂的任务(Rao and Tetreault, 2018; Reid and Artetxe, 2023; Konovalov et al., 2016b)。
- 本文提出利用现代大型语言模型(LLMs)在少样本设置下生成多语言平行去毒数据,以解决数据稀缺性问题。
二、相关工作
- 文本风格迁移:
- TST任务涉及在目标风格下重写文本,同时保留其语义内容和流畅性,已引起自然语言处理社区的广泛关注(Fu et al., 2018)。
- TST的子任务包括正式性风格迁移(Wang et al., 2020; Lai et al., 2021)、情感风格迁移(Yu et al., 2021)和作者风格迁移(Horvitz et al., 2024; Liu et al., 2024)等。
- 文本去毒:
- 文本去毒作为TST的一个子任务,旨在将识别为有毒的输入文本x_i改写为非毒性的文本y_i,同时保持语义相似性和流畅性(Logacheva et al., 2022)。
- 由于缺乏并行训练数据,早期研究主要集中于无监督去毒方法(dos Santos et al., 2018; Dale et al., 2021; Hallinan et al., 2023; Pour et al., 2023)。
- 多语言文本风格迁移:
- 多语言TST领域的高质量平行多语言去毒数据稀缺,是一个主要挑战(Dementieva et al., 2024)。
- 尽管已有一些非英语平行数据集被引入,但它们的规模和语言覆盖范围仍然有限(Mukherjee et al., 2023; Briakou et al., 2021)。
三、数据集与方法论
- SynthDetoxM数据集:
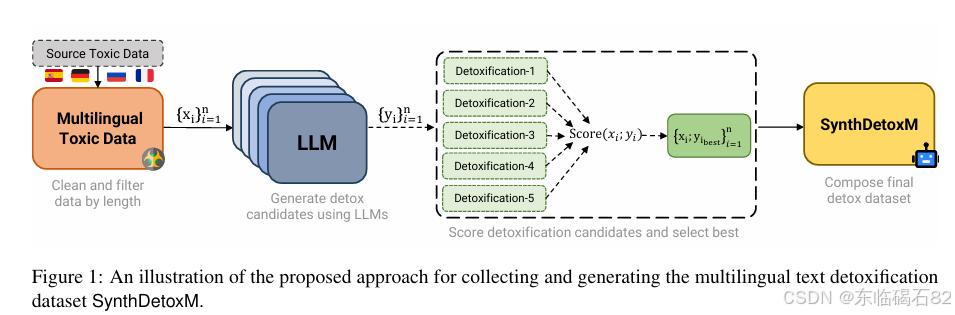
- 本文介绍了一个名为SynthDetoxM的大型多语言平行文本去毒数据集,包含德语、法语、西班牙语和俄语四种语言的16,000对高质量去毒句子对。
- 数据来源于不同的毒性评估数据集,并通过九个现代的开源LLMs在少样本设置下进行重写。
- 数据收集与处理:
- 从公开可用的毒性识别数据集中选择了几千条非平行毒性文本,聚焦于德语、法语、西班牙语和俄语。
- 应用了样本级过滤和数据增强技术,如使用Perspective API进行毒性评分和毒性跨度检测,以提高数据质量。
- 平行数据生成管道:
- 使用各种开源LLMs在少样本生成设置下生成平行去毒数据。
- 通过计算STA(Style Transfer Accuracy)和SIM(Content Similarity)指标来选择最佳的毒性和非毒性对。
- 少样本示例挖掘:
- 对于俄语、德语和西班牙语,从多语言毒性检测数据集中计算STA和SIM指标,并基于这些指标选择用于少样本提示的最佳示例。
- 对于法语,由于其在MultiParaDetox数据集中没有表示,因此使用人类注释员对随机选择的非平行数据进行去毒。
四、实验与评估
- 数据质量测试:
- 训练了一系列序列到序列模型来评估SynthDetoxM数据集的有效性,并与人类标注的MultiParaDetox数据集进行比较。
- 结果表明,即使在数据有限的情况下,使用SynthDetoxM训练的模型性能也优于使用MultiParaDetox训练的模型。
- 毒性和相似性评估:
- 使用Perspective API计算了俄语、德语、西班牙语和法语的STA和SIM分数,以进一步评估生成数据的质量。
- 结果表明,法语子集的自动指标分数与其他语言相当,表明使用SynthDetoxM训练的法语去毒模型将具有相似性能。
- 自动评估设置:
- 遵循Dementieva et al. (2024)的评估管道,使用STA、SIM和FL(Fluency)三个指标来评估模型性能。
- 联合分数J通过结合这三个指标来最终排名模型。
- 基线模型:
- 采用了MultiParaDetox中描述的多语言去毒基线模型,包括Duplicate、Delete和Backtranslation等。
- 训练配置:
- 使用mT0-XL模型进行微调,并采用了AdaFactor优化器和特定的训练参数设置。
五、实验结果与分析
- 模型性能比较:
- 实验结果表明,使用SynthDetoxM训练的mT0-XL模型在STA、SIM和J分数上均表现出色,尤其是在数据有限的情况下。
- 与使用MultiParaDetox训练的模型相比,SynthDetoxM模型在STA和J分数上表现出更优的性能。
- 少样本与多样本比较:
- 即使仅使用SynthDetoxM的一个子集(每种语言400个样本),模型的性能也优于使用整个MultiParaDetox数据集训练的模型。
- 这表明SynthDetoxM在少样本设置下的有效性。
- 人类评估:
- 通过GPT-4o进行的人类评估进一步验证了SynthDetoxM模型在去毒任务上的优越性。
- 在德语、西班牙语和俄语的比较中,SynthDetoxM模型生成的文本在大多数情况下都优于MultiParaDetox模型。
六、贡献与限制
- 主要贡献:
- 提出了一个利用少样本提示LLMs生成多语言平行去毒数据的框架。
- 引入了SynthDetoxM数据集,这是一个大型多语言平行文本去毒数据集,有助于解决去毒任务中的数据稀缺问题。
- 通过实验验证了SynthDetoxM数据集的有效性,并公开了数据集和代码以促进进一步研究。
- 限制:
- 本文仅关注显性毒性,而毒性的定义和类型在不同语言之间可能存在显著差异。
- 受计算资源限制,使用了较小和较简单的模型进行合成数据生成,这可能会影响数据的质量和多样性。
- 在某些语言中,可用的非平行毒性数据集数量有限,这限制了可能生成的合成数据量。
七、伦理考虑
- 在处理去毒任务时,我们充分认识到其涉及的伦理责任。我们的目标是使在线互动更安全、更包容,通过减少有害或冒犯性语言来实现这一目标。
- 尽管数据集旨在训练模型以检测和减少毒性语言,但仍存在被误用的风险,如创建传播有害或冒犯性内容的模型。因此,我们需要谨慎处理这些数据集,以确保其被用于积极的目的。
八、结论与未来工作
- 结论:
- 本文成功地将少样本提示去毒概念扩展到多语言环境中,并提出了一个用于生成多语言合成去毒数据的框架。
- 引入的SynthDetoxM数据集在解决去毒研究中的数据稀缺问题方面表现出了竞争力,并在实验中证明了其有效性。
- 未来工作:
- 计划将工作扩展到其他语言,如意大利语和波兰语等。
- 探索使用更大的LLMs进行合成数据生成,以提高数据的质量和多样性。
- 加强与专有模型的比较评估,以进一步验证SynthDetoxM的有效性。
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结